
# 一.概述
# 1.Java 中容器有哪些?
java 容器主要有 Collection 和 Map 两大类,还有他们的子类和实现类
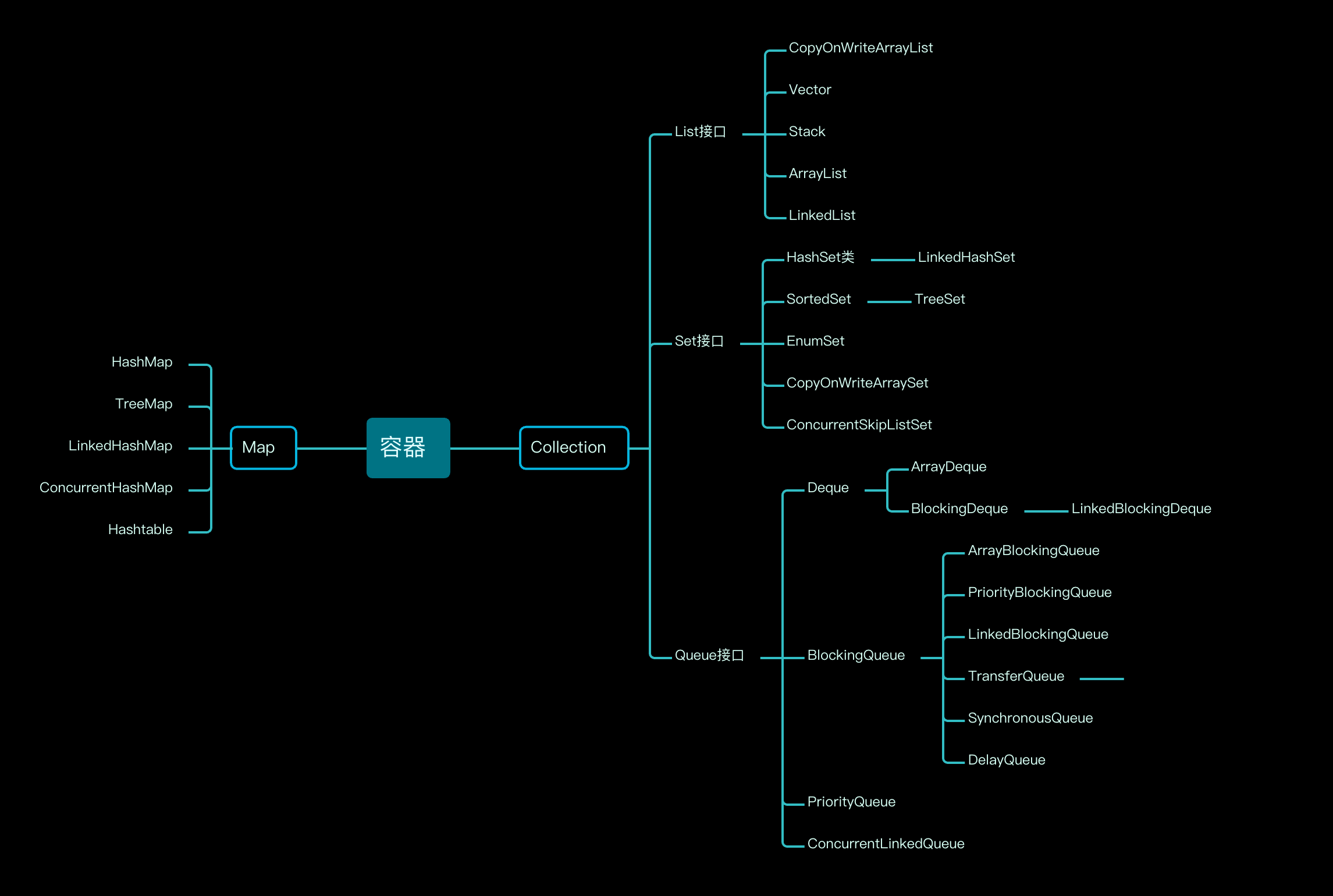
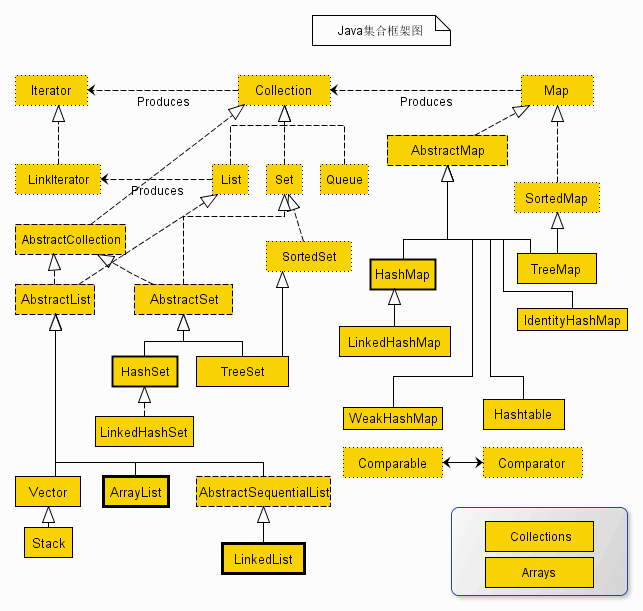
# 2.说说 List 和 Map 和 Set?
List,主要是为顺序存储诞生的,List 接口是为了存储一组不唯一的(允许重复)有序的对象。
Set,主要特性是不允许重复的集合。对象存储不可重复性,且无序。
Map,主要特征是 Key-value。Map 会维护与 Key 对应的值。
Collection
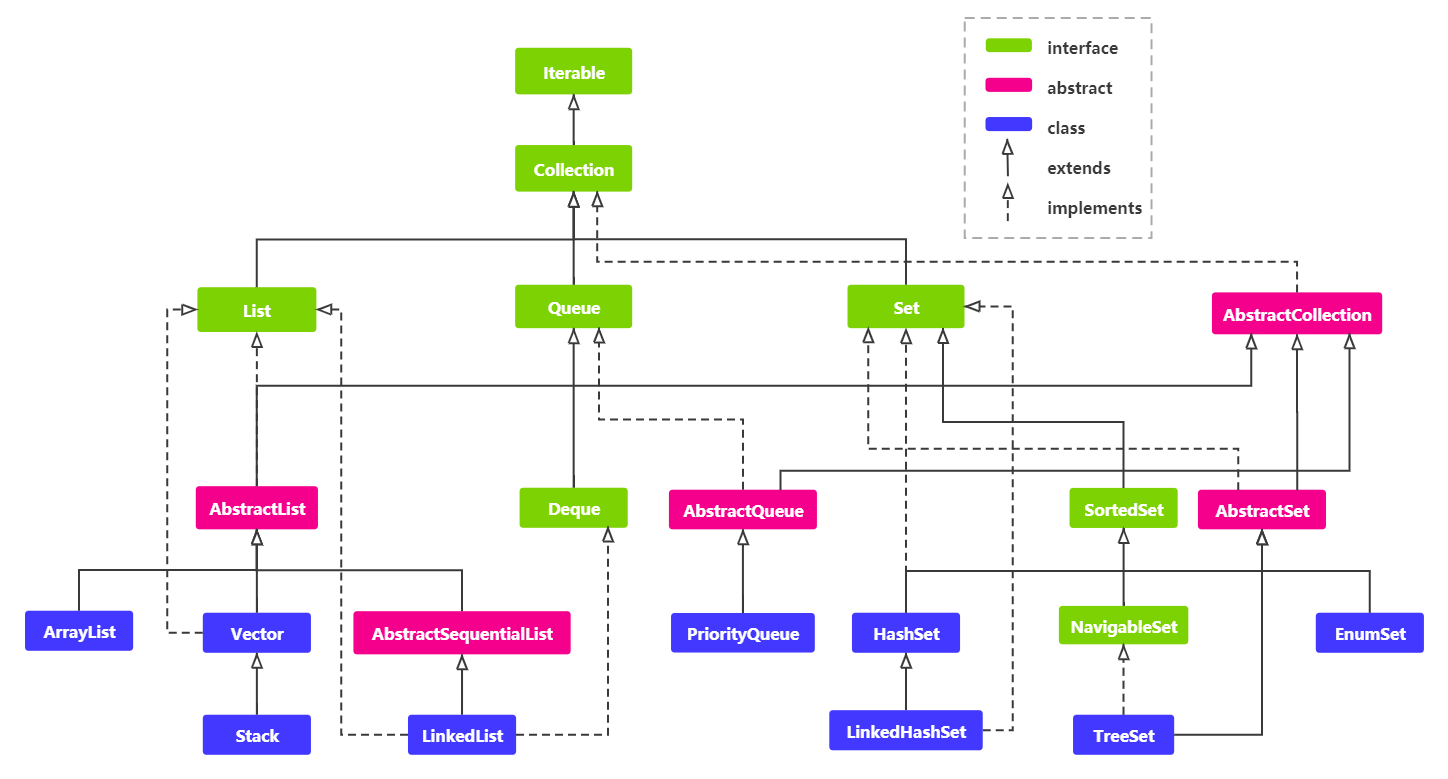
# 3.set 的类继承结构?
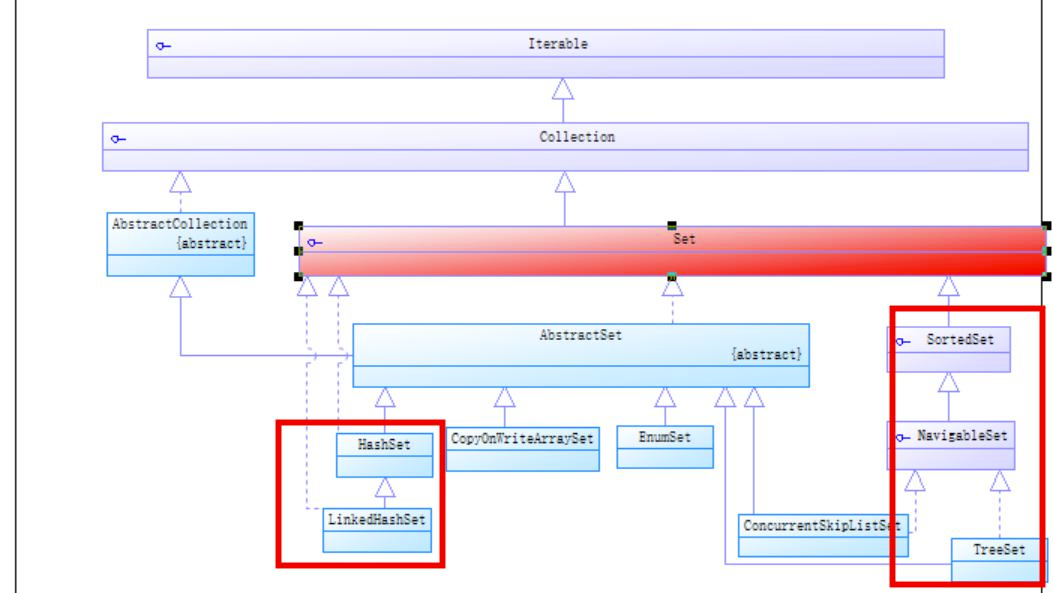
# 4.set 集合的特点?
在 Java 中,Set 是一种集合类型,它继承自 Collection 接口,表示一组不重复的元素集合。Set 中的元素没有顺序,也没有索引,因此不能通过索引来访问 Set 中的元素。Set 中的元素可以是任意类型,包括基本类型和对象类型。
Set 集合的主要特点如下:
- 不允许重复元素:Set 集合中的元素是不重复的,每个元素只会出现一次。当向 Set 集合中添加一个已经存在的元素时,添加操作会失败并返回 false。
- 无序性:Set 集合中的元素是无序的,即没有顺序,不能通过索引来访问 Set 中的元素。
- 元素可以为 null:Set 集合中的元素可以为 null,但是如果 Set 集合中已经存在 null 元素,再次添加 null 元素时会失败并返回 false。
- 遍历元素:可以使用迭代器(Iterator)或增强型 for 循环来遍历 Set 集合中的元素。
常见的 Set 集合实现类有 HashSet、TreeSet 和 LinkedHashSet。其中,HashSet 是最常用的 Set 集合实现类,它基于散列表实现,具有快速的查找和插入性能;TreeSet 是基于红黑树实现,可以对元素进行排序;LinkedHashSet 是基于散列表和链表实现的,具有插入顺序和快速查找的特点。选择不同的 Set 集合实现类,可以根据实际需求来选择最适合的集合类型。
# 5.常见的 set 集合?
HashSet 和 TreeSet 都是基于 Set 的实现类。其中 TreeSet 是 Set 接口的子接口 SortedSet 接口的实现类。
- SortedSet
- TreeSet
- HashSet
- LinkedHashSet
# 6.Arrays.copyOf()
Arrays.copyOf和System.arraycopy的区别:
//Arrays.copyOf
public static <T> T[] copyOf(T[] original, int newLength) {
return (T[]) copyOf(original, newLength, original.getClass());
}
2
3
4
//System.arraycopy
public static native void arraycopy(Object src, int srcPos,
Object dest, int destPos,
int length);
2
3
4
都是用于数组复制的方法,但它们有一些不同之处。
Arrays.copyOf(original, newLength):
Arrays.copyOf()是java.util.Arrays类的一个静态方法,用于将一个数组复制到一个新的数组,并指定新数组的长度。- 参数
value是源数组,参数newCapacity是新数组的长度。 - 如果新数组长度小于源数组长度,则只复制前
newCapacity个元素,多余的元素将被截断。 - 如果新数组长度大于源数组长度,则新数组后面的元素将用默认值填充(如 0 对于数值类型、null 对于引用类型)。
- 返回一个新的数组,如果
value是基本数据类型数组,返回新数组的类型是相同的;如果value是引用类型数组,返回新数组的类型也是相同的。
System.arraycopy(src, srcPos, dest, destPos, length):
System.arraycopy()是java.lang.System类的一个静态方法,用于将一个数组的一部分复制到另一个数组的指定位置。- 参数
src是源数组,参数srcPos是源数组开始位置的索引,参数dest是目标数组,参数destPos是目标数组开始位置的索引,参数length是复制的长度。 - 这个方法会将
src中从srcPos复制length长度个元素到dest中从destPos开始的位置。 - 注意,这个方法并不会创建新的数组,它只是在已有的目标数组
dest中进行复制。因此,目标数组dest的长度必须足够容纳复制的元素。
总结:
Arrays.copyOf()用于创建一个新的数组,并将源数组的内容复制到新数组中。可以指定新数组的长度,多余部分填充默认值。System.arraycopy()用于将源数组的一部分内容复制到目标数组的指定位置,不会创建新的数组,只是在目标数组中进行复制。要确保目标数组足够大以容纳复制的元素。
# 二.ArrayList
# 1.ArrayList 的特点?
先来看一下类的声明,有一个继承(抽象类)和四个接口关系
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
{
// 源码具体内容...
}
2
3
4
5
RandomAccess是一个标志接口(Marker)只要 List 集合实现这个接口,就能支持快速随机访问(通过元素序号快速获取元素对象 ——get(int index))Cloneable:实现它就可以进行克隆(clone())java.io.Serializable:实现它意味着支持序列化,满足了序列化传输的条件
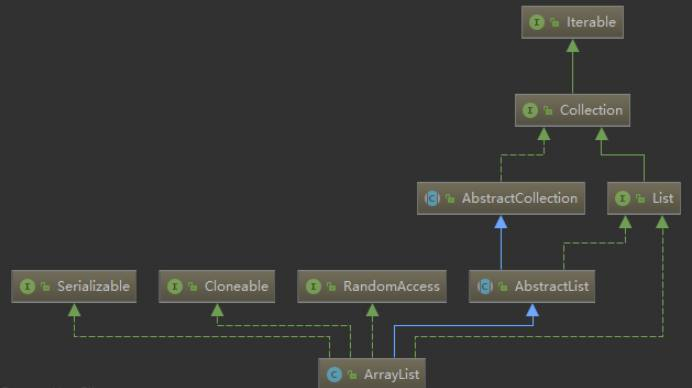
- ArrayList 底层是动态数组,实现了 list,RandomAccess, Cloneable, java.io.Serializable 接口, 并允许包含 null 元素,实现了 RandomAccess 表示支持快速访问,底层是数组实现,访问时间复杂度是 O(1),实现了 cloneable 接口,表示可以被复制,且是浅复制。实现了 java.io.Serializable 接口,支持序列化传输。
- 底层是数组实现,默认容量是 10,当超出默认容量后,会扩容 1.5 倍,即自动扩容机制。数组的扩容是新建一个大数组,将原数组元素拷贝到新数组,此操作代价很高,我们应该减少这种操作。
- 该集合是可变长度的数组,扩容时,扩容为 1.5 倍,将原数组的元素拷贝到新数组, 扩容使用的是 Arrays.copyOf 浅复制的方式进行拷贝,添加元素 add 时使用的是 System.arraycopy。
- 采用了 fail-fast 的机制,面对并发修改时,迭代器很快就会完全失败,报异常 concurrentModificationException 并发修改错误。
- remove 方法会将下标到末尾的元素向前移动一位,并把最后一位置空,为了 gc。
- 数组扩容代价很高,我们在使用时尽量指定好容量。以避免数组扩容发生,或者根据实际需求,通过调用 ensureCapacity 方法手动增加 ArrayList 实例的容量。
- ArrayList 不是线程安全的,只能在单线程下使用,多线程下,尽量使用 Collections.synchronizedList(List l)返回一个安全的 ArrayList 类,或者使用并发包下面的 CopyOnWriteArrayList 类。
- 如果是删除指定元素,可能会挪动大量的数组元素,如果是末尾元素,那么代价是最小的。
- ArrayList 不会缩容,只会扩容.
# 2.类成员
下面接着看一些成员属性
// 序列化自动生成的一个码,用来在正反序列化中验证版本一致性。
private static final long serialVersionUID = 8683452581122892189L;
/**
* 默认初始容量大小为10
*/
private static final int DEFAULT_CAPACITY = 10;
/**
* 指定 ArrayList 容量为0(空实例)时,返回此空数组
*/
private static final Object[] EMPTY_ELEMENTDATA = {};
/**
* 与 EMPTY_ELEMENTDATA 的区别是,它是默认返回的,而前者是用户指定容量为 0 才返回
*/
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
/**
* 具体存放元素的数组
* 保存添加到 ArrayList 中的元素数据(第一次添加元素时,会扩容到 DEFAULT_CAPACITY = 10 )
*/
transient Object[] elementData; // non-private to simplify nested class access
/**
* ArrayList 实际所含元素个数(大小)
*/
private int size;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
# 3.ArrayList 构造方法?
有三个构造方法
第一个:无参构造方法,初始容量为 10.
//默认容量为0
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
public ArrayList() {
//构造函数的默认容量为0
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
//在add方法时,会计算容量,当数组为空时,会取Math.max(最小容量,10)
private static int calculateCapacity(Object[] elementData, int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
return Math.max(DEFAULT_CAPACITY, minCapacity);
}
return minCapacity;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
第二个:构造一个包含指定元素的列表。
public ArrayList(Collection<? extends E> c) {
Object[] a = c.toArray();
if ((size = a.length) != 0) {
if (c.getClass() == ArrayList.class) {
elementData = a;
} else {
elementData = Arrays.copyOf(a, size, Object[].class);
}
} else {
// replace with empty array.
elementData = EMPTY_ELEMENTDATA;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
第三个:构造一个具有初始化容量的空列表。
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
2
3
4
5
6
7
8
9
10
我们看到代码逻辑不复杂,从代码逻辑中,可以看到, 会有 new Object[] 的操作,从这里就能印证,ArrayList 就是以数组为底层的。
构造方法:
/**
* 带参构造函数,参数为用户指定的初始容量
*/
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
// 参数大于0,创建 initialCapacity 大小的数组
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
// 参数为0,创建空数组(成员中有定义)
this.elementData = EMPTY_ELEMENTDATA;
} else {
// 其他情况,直接抛异常
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
/**
* 默认无参构造函数,初始值为 0
* 也说明 DEFAULT_CAPACITY = 10 这个容量
* 不是在构造函数初始化的时候设定的(而是在添加第一个元素的时候)
*/
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
/**
* 构造一个包含指定 collection 的元素的列表
* 这些元素是按照该 collection 的迭代器返回它们的顺序排列的。
*/
public ArrayList(Collection<? extends E> c) {
// 将给定的集合转成数组
elementData = c.toArray();
// 如果数组长度不为 0
if ((size = elementData.length) != 0) {
// elementData 如果不是 Object 类型的数据,返回的就不是 Object 类型的数组
if (elementData.getClass() != Object[].class)
// 将不是 Object 类型的 elementData 数组,赋值给一个新的 Object 类型的数组
elementData = Arrays.copyOf(elementData, size, Object[].class);
} else {
// 数组长度为 0 ,用空数组代替
this.elementData = EMPTY_ELEMENTDATA;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
# 4.final object 数组
在 ArrayList 中,为什么有 2 个静态 final 修饰的 object 数组?
- EMPTY_ELEMENTDATA
- DEFAULTCAPACITY_EMPTY_ELEMENTDATA
private static final Object[] EMPTY_ELEMENTDATA = {};
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
2
从代码可以看到,这 2 个 object 的数组基本是一样的,那么为什么要用 2 个呢?从源码可以看到只有无参构造器使用的是 DEFAULTCAPACITY_EMPTY_ELEMENTDATA,其他 2 个构造器使用的是 EMPTY_ELEMENTDATA,先说结论,这里是为了初始化容量不同而设定的。
==和 equals 是啥区别?
- ==是判断两个变量或实例是不是指向同一个内存空间,equals 是判断两个变量或实例所指向的内存空间的值是不是相同
- ==是指对内存地址进行比较 , equals()是对字符串的内容进行比较
- ==指引用是否相同, equals()指的是值是否相同

回到正题,在使用 add 方法时,
public boolean add(E e) {
// 确认容量
ensureCapacityInternal(size + 1); // Increments modCount!!
// 直接将元素添加在数组中
elementData[size++] = e;
return true;
}
private void ensureCapacityInternal(int minCapacity) {
// 进一步确认ArrayList的容量,看是否需要进行扩容
ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));
}
private static int calculateCapacity(Object[] elementData, int minCapacity) {
// 如果elementData为空,则返回默认容量和minCapacity中的最大值
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
return Math.max(DEFAULT_CAPACITY, minCapacity);
}
// 否则直接返回minCapacity
return minCapacity;
}
private void ensureExplicitCapacity(int minCapacity) {
// 修改次数自增
modCount++;
// overflow-conscious code
// 判断是否需要扩容
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
private void grow(int minCapacity) {
// overflow-conscious code
// 原容量
int oldCapacity = elementData.length;
// 扩容,相当于扩大为原来的1.5倍
int newCapacity = oldCapacity + (oldCapacity >> 1);
// 确认最终容量
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
// 将旧数据拷贝到新数组中
elementData = Arrays.copyOf(elementData, newCapacity);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
从源码可以看到,如果是 DEFAULTCAPACITY_EMPTY_ELEMENTDATA,则容量为默认的 10,如果是 EMPTY_ELEMENTDATA,则容量为 1。调用 add 方法时才为 10,不调用为 0.
关于 ArrayList 的容量
- 默认构造函数,不添加元素,容量为 0
- 默认构造函数,添加元素,容量为 10
- 初始化为 0,添加元素,容量为 1
//默认构造函数,不添加元素,容量为0
public class Basic_collection_01_ArrayList_03 {
public static void main(String[] args) throws InterruptedException, ClassNotFoundException, NoSuchFieldException, IllegalAccessException {
ArrayList arrayList = new ArrayList();
Class<?> clazz = Class.forName("java.util.ArrayList");
Field field = clazz.getDeclaredField("elementData");
field.setAccessible(true);
Object[] o = (Object[]) field.get(arrayList);
System.out.println(o.length);
}
}
// 默认构造函数,添加元素,容量为10
public class Basic_collection_01_ArrayList_04 {
public static void main(String[] args) throws InterruptedException, ClassNotFoundException, NoSuchFieldException, IllegalAccessException {
ArrayList arrayList = new ArrayList();
arrayList.add(1);
Class<?> clazz = Class.forName("java.util.ArrayList");
Field field = clazz.getDeclaredField("elementData");
field.setAccessible(true);
Object[] o = (Object[]) field.get(arrayList);
System.out.println(o.length);
}
}
// 初始化为0,添加元素,容量为1
public class Basic_collection_01_ArrayList_05 {
public static void main(String[] args) throws InterruptedException, ClassNotFoundException, NoSuchFieldException, IllegalAccessException {
ArrayList arrayList = new ArrayList(0);
arrayList.add(1);
Class<?> clazz = Class.forName("java.util.ArrayList");
Field field = clazz.getDeclaredField("elementData");
field.setAccessible(true);
Object[] o = (Object[]) field.get(arrayList);
System.out.println(o.length);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
# 5.序列化后数据会丢失?
ArrayList 中的elementData用 transient 修饰,序列化后数据会丢失吗?
源码中的全局变量,transient Object[] elementData;
隐含面试题:
1.序列化是什么?
我们知道对象是不能直接进行网络传输的,必须将对象转为二进制字节流进行传输。序列化就是将对象转为二进制字节流的过程。同理,反序列化就是将字节流构建对象的过程
对 java 对象来说,如果使用 jdk 的序列化实现,只需要实现 java.io.Serializable 接口。
可以使用 ObjectOutputStream 和 ObjectInputStream 对对象进行序列化和反序列化。序列化的时候会调用 writeObject 方法,把对象转为字节流。反序列化会调用 readObject 方法,把字节流转为对象。
java 在反序列化的时候会校验 serialVersionUid 与对象的 serialVersionUid 是否一致,如果不一致,会抛出 InvalidClassException 异常
官方强烈推荐序列化时指定一个 serialVersionUid,否则虚拟机会根据类的相关信息通过一个摘要算法生成,所以当我们修改类的参数的时候,虚拟机生成的 serialVersionUid 时变化的。
transient 关键字修饰的变量不会被序列化为字节流。
2.transient 关键字的具体含义?
transient 关键字修饰的变量不会被序列化为字节流。
进入正题:
从源码可以看到 elementData 就是 ArrayList 的底层数组,如果不能被序列化,那 ArrayList 就是不可用的。
我们在进行对象序列化的时候,只需要实现 java.io.Serializable 接口,ArrayList 实现了该接口,说明 ArrayList 是可以被序列化的。所有用户数据,都保存在 elementData 中,如果序列化后数据丢失,那 ArrayList 肯定是有问题的。
arraylsit 用什么巧妙的方式,既防止了 elementData 的序列化,又保证存入的元素不丢失呢?
答案很简单,不对 elementData 序列化,对 elementData 里面的元素进行循环,取出的元素单独进行序列化
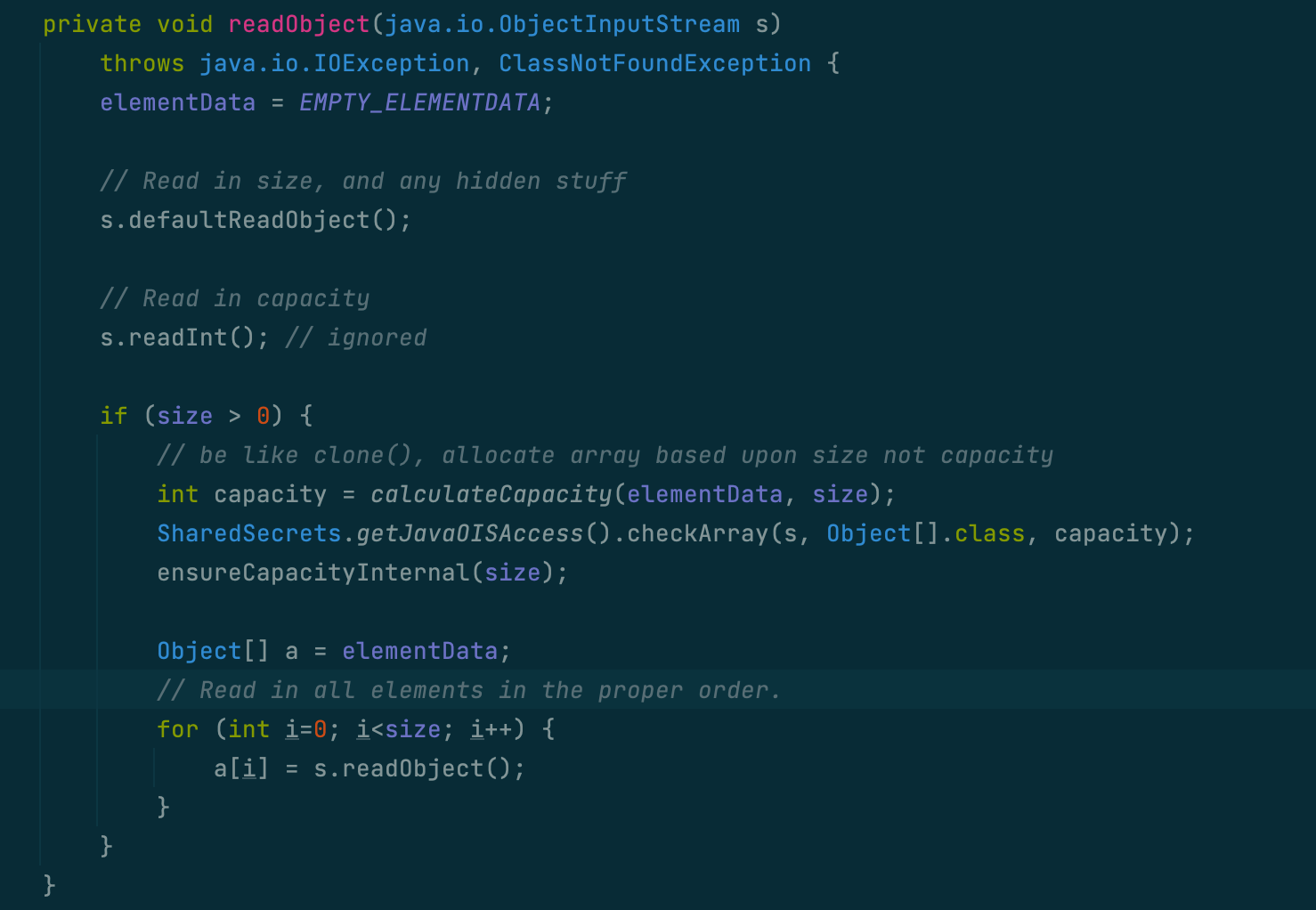

通过查看 ArrayList 源码中的 2 个方法,可以看到具体的实现 writeObject 和 readObject
# 6.为什么不直接序列化?
为什么不直接序列化 elementData?
elementData 是一个对象数组,不直接序列化这个对象,是因为绝大多数的情况下,存在没有存储任何元素的空间,这样序列化会存在空间浪费,全部序列化效率更低。
比如容量为 10,但只有一个元素,浪费了 9 个容量。
每次扩容都是原来的 1.5 倍,如果在大容量空间下比如 10 万,扩容到 15 万,将有 5 万的空间浪费。
# 7.transient 的理解?
- 一旦变量被 transient 修饰,变量将不再是对象持久化的一部分,该变量的内容在序列化后无法获得访问。
- transient 关键字只能修饰变量,不能修饰类和方法。
- 本地变量不能被 transient 关键字修饰。
- 自定义的类需要序列化,只需要实现 java.io.Serializable 接口。
- 被 transient 关键字修饰的变量不能再被序列化,静态变量不管是否被 transient 修饰,都不能被序列化。
- 使用场景,密码和银行卡不想被序列化,可以加上 transient 关键字。这个字段的生命周期仅存在于调用者的内存中,不会写到磁盘持久化。
# 8.add(E e)方法的原理?
add 方法主要执行以下逻辑:
- 确保数组已经使用的长度 size+1 之后足够存下下一个元素。
- 修改次数 modCount 自动加 1,如果当前数组的长度 size 加 1 后的长度大于当前数组的长度,则调用 grow 方法,增长数组,grow 方法会将当前数组的长度变为原数组的 1.5 倍。
- 确保新增的元素有地方存储后,新元素存储在 size 处。
- 返回添加成功的布尔值。
# 9.add(int index,E element)
ArrayList 中 add(int index,E element)有了解过吗?这个方法的优劣
public void add(int index, E element) {
// 越界检查
rangeCheckForAdd(index);
// 确认容量
ensureCapacityInternal(size + 1); // Increments modCount!!
// 将index及其之后的元素往后移动一位,将index位置空出来
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
// 在index插入元素
elementData[index] = element;
// 元素个数自增
size++;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
该方法可以按照元素的位置,指定元素的插入位置,具体流程如下:
- 确保插入的位置小于等于当前数组的长度,并且不小于 0,否则抛出异常。
- 确保数组已经使用的长度 size 加 1 后足够存下一个数据。
- 修改标识自动加 1,如果当前数组已经使用的长度 size 加 1 后大于当前数组的长度,则调用 grow 方法,增长数组。
- grow 方法会将当前数组的长度变为原来容量的 1.5 倍。
- 确保有足够的容量之后,调用System.arraycopy方法,将需要插入位置 index 后面的元素统统后移一位。
- 将新的数据存放到新的数组的指定位置 index 处。
好处:因为存在 index,可以存在指定的位置。只要 index 符合要求。
坏处:调用System.arraycopy方法,插入的时候需要移动其他元素,频繁移动,速率会打折扣。
# 10.ArrayList 的扩容原理?
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE – 8 = 2^31-1-8 ;
Integer.MAX_VALUE = 0x7fffffff = 2^31-1;
2
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);//1.5倍
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
2
3
4
5
6
7
8
9
10
11
- 老的长度等于当前 elementData 的长度。
- 新数组的长度=原数组的长度+原数组长度>>1,右移 1 是除以 2.
- 若扩容 1.5 倍后仍不够用,则 newCapacity=minCapacity
- 如果 newCapacity 比 MAX_ARRAY_SIZE 还大,则调用 hugeCapacity 方法。
- 老数据拷贝到新数组中。
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}
2
3
4
5
6
7
如果 MAX_ARRAY_SIZE 达不到要求,则赋值 Integer.MAX_VALUE,理论上 ArrayList 的最大容量为 Integer.MAX_VALUE
# 11.数组在 jvm 中的构造
在 JVM 中,数组是作为对象来处理的,每个数组都有一个 Class 对象,用于描述数组的类型信息。当定义一个数组时,JVM 会在堆上为数组对象分配内存空间,并初始化数组元素的值,根据数组的类型不同,初始化的方式也不同。
对于基本数据类型的数组,例如 int[]、char[]等,JVM 会使用默认值来初始化数组元素。例如,int 类型的数组元素默认值为 0,char 类型的数组元素默认值为'\u0000'。JVM 在为数组对象分配内存空间时,会根据数组元素的个数和类型计算出所需的空间大小,并在内存中分配连续的空间存储数组元素。
对于对象数组,例如 String[]、Object[]等,JVM 会在堆上为数组对象分配内存空间,并使用 null 值来初始化数组元素。在数组元素的类型为引用类型时,JVM 只会为每个引用分配 4 个字节的空间,用于存储对象的地址,而不会为每个对象分配独立的空间。因此,在数组元素类型为引用类型时,数组对象只是存储了对象的地址,而不是对象本身。
需要注意的是,数组的大小在创建时就已经确定,并且无法改变。如果需要动态增加或减少数组大小,可以使用 Java 中提供的 List 接口及其实现类,例如 ArrayList、LinkedList 等。这些集合类可以根据需要动态调整集合大小,并且可以方便地添加、删除和访问集合元素。
# 12.最大容量是?
为什么 MAX_ARRAY_SIZE 是 Integer.MAX_VALUE 减去 8,而不是别的数字?
- 数组在 java 中是一种特殊的数据类型,既不是基本类型也不是引用类型。
- 在 jvm 中获取数组的长度使用 arrayLength 这个专门的字节码指令,在数组的对象头中有一个_length 字段,记录数组的长度,只需要去读_length 字段就可以了
- 所以这个减去 8 字节就是存了数组_length 字段
# 13.说说 remove 方法?
ArrayList 的 remove 方法有了解过吗?如果长度为 1 的 ArrayList,移除后是如何进行垃圾回收的?
public E remove(int index) {
// 越界检查
rangeCheck(index);
// 修改次数自增
modCount++;
// 获取对应index上的元素
E oldValue = elementData(index);
// 判断index是否在最后一个位置
int numMoved = size - index - 1;
// 如果不是,则需要将index之后的元素往前移动一位
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
// 将最后一个元素删除,帮助GC
elementData[--size] = null; // clear to let GC do its work
return oldValue;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
- 移除元素后,会改变 modCount,并且是++操作
- 判断是否是移除最后一个元素,如果不是,则进行拷贝操作,如果是最后一个,则将最后一个元素设置为 null,为 gc 做准备。这个设计非常细节。
# 14.contains 方法?
ArrayList 中的 contains 方法的时间复杂度?知道值如何知道值在不在集合中?
在 ArrayList 中,contains 方法的时间复杂度为 O(n),其中 n 为 ArrayList 中元素的个数。contains 方法的实现是遍历 ArrayList 中的元素,逐个比较元素值,直到找到匹配的元素或遍历完所有元素。因此,当 ArrayList 中的元素个数增加时,contains 方法的时间复杂度也会相应增加。
需要注意的是,当 ArrayList 中的元素类型为基本数据类型时,contains 方法会先将基本数据类型的值装箱为对应的包装类对象,然后再进行比较,这可能会导致额外的性能开销。如果需要更高效的元素查找,可以考虑使用基于哈希表实现的集合类,例如 HashSet 或 HashMap。这些集合类的 contains 方法的时间复杂度为 O(1),可以快速地判断元素是否存在。
public boolean contains(Object o) {
return indexOf(o) >= 0;
}
/**
* Returns the index of the first occurrence of the specified element
* in this list, or -1 if this list does not contain the element.
* More formally, returns the lowest index <tt>i</tt> such that
* <tt>(o==null ? get(i)==null : o.equals(get(i)))</tt>,
* or -1 if there is no such index.
*/
public int indexOf(Object o) {
if (o == null) {
for (int i = 0; i < size; i++)
if (elementData[i]==null)
return i;
} else {
for (int i = 0; i < size; i++)
if (o.equals(elementData[i]))
return i;
}
return -1;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# 15.和 LinkedList 区别?
ArrayList 和 LinkedList 都是 Java 中的集合类,都实现了 List 接口,可以存储一组有序的元素。它们之间的区别主要体现在底层数据结构、访问速度、插入删除操作的效率等方面。
- 底层数据结构:ArrayList 是通过数组实现的,它在内存中开辟了一块连续的空间存储元素,因此可以通过索引快速访问元素。LinkedList 是通过双向链表实现的,每个节点包含了元素值、前驱节点和后继节点的引用,因此访问元素时需要从头或尾开始遍历链表。
- 访问速度:ArrayList 的访问速度比 LinkedList 快,因为它可以通过索引直接访问元素,而不需要遍历链表。LinkedList 的访问速度相对较慢,因为它需要遍历链表来查找元素。
- 插入删除操作效率:LinkedList 的插入删除操作效率比 ArrayList 高,因为它只需要改变相邻节点的引用,而不需要移动其他元素。而 ArrayList 的插入删除操作效率较低,因为它需要移动其他元素来保证数组的连续性。
- 空间占用:LinkedList 的每个节点都包含了元素值、前驱节点和后继节点的引用,因此占用的内存空间相对较大。而 ArrayList 只需要占用连续的内存空间,因此占用的内存空间相对较小。
根据上述特点,可以通过对 ArrayList 和 LinkedList 的选择来提高代码的效率。如果需要快速地访问集合中的元素,可以使用 ArrayList;如果需要频繁地插入删除元素,可以使用 LinkedList。在实际开发中,也可以根据具体的需求和场景来选择最适合的集合类型。
# 16.fail-fast 原理?
ArrayList 的 fail-fast 机制是什么原理?
采用了 fail-fast 机制,面对并发修改时,会立即失败,报 concurrentModificationException 并发修改异常。
ArrayList 的父类 abstractlist 中有一个类属性,这个属性代表了 list 被结构性修改的次数。
protected transient int modCount = 0;
结构性修改是指:改变了 list 的 size 大小。
这个字段用于迭代器和列表迭代器的实现类中,由迭代器和列表迭代器的方法返回。如果这个值被意外修改,就会抛出 ConcurrentModificationException 异常。
在迭代过程中,它提供了 fail-fast 机制,而不是不确定的行为来处理并发修改。子类使用这个字段是可选的, 如果子类希望提供 fail-fast 迭代器,它仅仅需要在 add(int, E),remove(int)方法(或者它重写的其他任何 会结构性修改这个列表的方法)中添加这个字段。调用一次 add(int,E)或者 remove(int)方法时必须且仅仅给这个字段加 1,否则迭代器会抛出伪装的 ConcurrentModificationExceptions 错误。如果一个实现类 不希望提供 fail-fast 迭代器,则可以忽略这个字段。
- expectedModCount 初始值是 modCount。
- hasnext 的判断条件是 cursor!=size,当前迭代位置不是数组的最大容量值就返回 true。
- next 和 remove 操作之前都会调用 checkForComodification 来检查 expectedModCount 和 modCount 是否相等。
如果没 checkForComodification 去检查 expectedModCount 与 modCount 相等,这个程序肯定会报越界异常
ArrayIndexOutOfBoundsException 因为有 modCount 的存在,在使用多线程对非线程安全的集合进行操作时,使用迭代器循环会产生 modCount != expectedModCount 的情况,会抛出异常。
private void fastRemove(int index) {
modCount++;
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // clear to let GC do its work
}
// 删除元素后,遍历下一个元素会先校验,不通过,报错
public E next() {
checkForComodification();
int i = cursor;
if (i >= SubList.this.size)
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
if (offset + i >= elementData.length)
throw new ConcurrentModificationException();
cursor = i + 1;
return (E) elementData[offset + (lastRet = i)];
}
//校验修改值
final void checkForComodification() {
if (expectedModCount != ArrayList.this.modCount)
throw new ConcurrentModificationException();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
总结
- foreach 遍历,iterator 遍历都不能在遍历的过程中使用 list.remove 或 list.add 操作,会报并发修改异常,遍历删除后加个 break 即可解决
- iterator 遍历过程中如果需要删除可以使用 iterator 提供的 remove()方法
- 遍历根据元素索引删除是可行的
原因是先判断 next,然后判断 check,发现修改值变了,对应不上
# 17.fail-fast 和 fail-safe 对比?
| 对比项 | fail-fast | fail-safe |
|---|---|---|
| Throw ConcurrentModification Exception | 会 | 不会 |
| Clone | 不会 | 会 |
| Memory Overhead | 不会 | 会 |
| Examples | HashMap Vector ArrayList HashSet | CopyOnWriteArrayList |
fail-safe 也是得具体情况具体分析的。
- 如果是 CopyOnWriteArrayList 或者 CopyOnWriteArraySet ,就属于 复制原来的集合,然后在复制出来的集合上进行操作 的情况 ,所以是不会抛出这个 ConcurrentModificationException 的 。
- 如果是这个 ConcurrentHashMap 的,就比较硬核了~ 😄 它直接操作底层,调用 UNSAFE.getObjectVolatile ,直接 强制从主存中获取属性值,也是不会抛出这个 ConcurrentModificationException 的 。
- 并发下,无法保证遍历时拿到的是最新的值
# 18.避开 fail-fast 机制?
ArrayList 如果在循环中删除一个元素,有什么办法避开 fail-fast 机制?
// 普通循环删除
public class Basic_08_foreach_03 {
public static void main(String[] args) throws InterruptedException {
ArrayList<String> list = new ArrayList<>();
list.add("111");
list.add("222");
list.add("333");
System.out.println(list.toString());
for (int i = 0; i <list.size(); i++) {
list.remove("222");
}
System.out.println(list.toString());
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
//迭代器删除
public class Basic_08_foreach_05 {
public static void main(String[] args) throws InterruptedException {
ArrayList<String> list = new ArrayList<>();
list.add("111");
list.add("222");
list.add("333");
System.out.println(list.toString());
Iterator<String> it = list.iterator();
while (it.hasNext()) {
String next = it.next();
//if外使用list的remove方法还是会报错的
if (next.equals("222")) {
it.remove();//这里使用的是迭代器里面的remove()方法,
}
}
System.out.println(list.toString());
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
使用迭代器和普通 for 循环都是可行的,使用增强 for 循环不行。
增强 for 循环底层还是用的迭代器,迭代器的内部实现如下,三个属性非常重要,理解三个字段在 next 和 remove 的变化过程很关键.
private class Itr implements Iterator<E> {
int cursor; // 指向下一个元素的索引,默认初始化为 0
int lastRet = -1; // 指向已被迭代过的元素,默认初始化为-1.
int expectedModCount = modCount;// 赋值为 modCount,删除元素后重新赋值
Itr() {}
public boolean hasNext() {
return cursor != size;
}
@SuppressWarnings("unchecked")
public E next() {
checkForComodification();
int i = cursor;
if (i >= size)
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length)
throw new ConcurrentModificationException();
//cursor更新
cursor = i + 1;
return (E) elementData[lastRet = i]; //lastRet更新
}
public void remove() {
//说明没有被迭代过,没有迭代过不允许删除
if (lastRet < 0)
throw new IllegalStateException();
checkForComodification();
try {
ArrayList.this.remove(lastRet);
//因为cursor比lastRet大1,删除元素的时候cursor需要减去1
cursor = lastRet;
lastRet = -1;
expectedModCount = modCount;
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}
// 检查并发修改异常
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
@Override
@SuppressWarnings("unchecked")
public void forEachRemaining(Consumer<? super E> consumer) {
Objects.requireNonNull(consumer);
final int size = ArrayList.this.size;
int i = cursor;
if (i >= size) {
return;
}
final Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length) {
throw new ConcurrentModificationException();
}
while (i != size && modCount == expectedModCount) {
consumer.accept((E) elementData[i++]);
}
// update once at end of iteration to reduce heap write traffic
cursor = i;
lastRet = i - 1;
checkForComodification();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
每调用一次 next 方法,cursor=i+1 ,指向下一个元素。lastRet 指向刚刚被迭代过的元素 ,lastRet=i。我们可以看到,多数情况下,lastRet 与 cursor 的角标是连续的,只差 1。
lastRet<0. 代表 lastRet 没有被 i 赋值,说明是初始值-1. 说明没有被迭代过,没有被迭代过就删除,这是不允许的。也就是说,iterator 是靠 lastRet 的值来判断是否可以进行 remove 操作的。
如果 lastRet > 0,说明已经被迭代过,可以删除,这时候 cursor 的角标需要减去 1,cursor - 1= lastRet,所以对 cursor 进行 lastRet 的赋值操作,lastRet 的位置被成功的 remove 了,自己的位置被 cursor 替代了。把自己置成 初始值-1,等待下次的赋值删除操作。
# 三.LinkedList
# 1.LinkedList 数据结构?
如图所示,LinkedList 底层使用的双向链表结构,有一个头结点和一个尾结点,双向链表意味着我们可以从头开始正向遍历,或者是从尾开始逆向遍历,并且可以针对头部和尾部进行相应的操作。
- LinkedList 底层数据结构为双向链表,实现了 List 和 Deque 两个接口。
- LinkedList 允许 null 值。
- 由于双向链表,顺序访问效率高,而随机访问效率较低。

public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
{
transient int size = 0;
transient Node<E> first;
transient Node<E> last;
public LinkedList() {
}
}
2
3
4
5
6
7
8
9
10
# 2.add()和 offer()区别?
offer()直接调用了 add()方法
public boolean offer(E e) {
return add(e);
}
public boolean add(E e) {
linkLast(e);
return true;
}
2
3
4
5
6
7
8
add 方法:在不违背队列的容量限制的情况,往队列中添加一个元素,如果添加成功则返回 true。
如果因为容量限制添加失败了,则抛出 IllegalStateException 异常
offer 方法:在不违背容量限制的情况,往队列中添加一个元素,如果添加元素成功,返回 true,
如果因为空间限制,无法添加元素则,返回 false;
- 在有容量限制的队列中,这个 offer 方法优于 add 方法。
- 因为抛异常处理更加耗时,offer 直接返回 false 的方式更好
# 3.offerLast 与 addLast()
offerLast()将元素链接到队列尾并返回 true。
所以能看出 offerLast()和 add()效果又是一样的。
public void addLast(E e) {
linkLast(e);
}
public boolean offerLast(E e) {
addLast(e);
return true;
}
2
3
4
5
6
7
# 4.addLast()与 add()区别
- addLast()仅仅将元素链接到队列尾部。
- 然而 add()不仅将元素链接到队列尾部,还返回 true。
- 底层都是调用了 linkLast(e)方法
public void addLast(E e) {
linkLast(e);
}
public boolean add(E e) {
linkLast(e);
return true;
}
//addFirst()仅将元素链接到队列首。
public void addFirst(E e) {
linkFirst(e);
}
2
3
4
5
6
7
8
9
10
11
# 5.pollFirst 和 removeFirst
removeFirst:删除并返回队列首元素,若队列为空则抛出 Exception ! 这是 1.2 的版本,由于抛出异常处理起来较为麻烦。所以在 1.6 版本中推出了 poll 家族
pollFirst:删除并返回队列首元素,若队列为空则返回 null。 处理起来友善很多。
public E pollFirst() {
final Node<E> f = first;
return (f == null) ? null : unlinkFirst(f);
}
public E removeFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return unlinkFirst(f);
}
2
3
4
5
6
7
8
9
10
11
# 6.poll 和 pop 的区别
poll 是队列数据结构实现类的方法,从队首获取元素,同时获取的这个元素将从原队列删除;
pop 是栈结构的实现类的方法,表示返回栈顶的元素,同时该元素从栈中删除,当栈中没有元素时,调用该方法会发生异常
# 7.LinkedList 变种
- LinkedList 继承了 AbstractSequentialList 类。
- LinkedList 实现了 Queue 接口,可作为队列使用。
- LinkedList 继承了 AbstractQueue 抽象类,具有队列的功能。
- LinkedList 实现了 List 接口,可进行列表的相关操作。
- LinkedList 实现了 Deque 接口,可作为双向队列使用。
- LinkedList 实现了 Cloneable 接口,可实现克隆。
- LinkedList 实现了 java.io.Serializable 接口,即可支持序列化,能通过序列化去传输。
# 8.LinkedList 使用总结
- 需要链接元素到队列尾时优先用
offer() - 查看元素优先使用
peek() - 删除元素优先使用
poll()
特别情况:
- 想要在指定索引位置链接元素可以使用 add(int index, E element)
- 获取指定索引的元素可以使用 get(int index)
- 修改指定索引的元素可以使用 set(int index, E newElement)
# 四.CopyOnWriteArrayList
# 1.什么是 CopyOnWriteArrayList
CopyOnWriteArrayList 是 Java 中的一个线程安全的 List 实现类,它是 ArrayList 的线程安全版本。CopyOnWriteArrayList 允许多个线程同时读取 List 中的元素,而不需要进行额外的同步操作。当有写操作时,CopyOnWriteArrayList 会将 List 中的元素复制一份,然后进行修改,修改完成后再将新的 List 替换原来的 List。
# 2.CopyOnWriteArrayList 特点
CopyOnWriteArrayList 的主要特点如下:
- 线程安全:
CopyOnWriteArrayList是线程安全的,可以在多线程环境中安全地使用。 - 读操作不锁定:
CopyOnWriteArrayList的读操作不需要进行锁定,因此读操作的性能很高。 - 写操作复制数组:
CopyOnWriteArrayList的写操作会将 List 中的元素复制一份,然后进行修改,修改完成后再将新的 List 替换原来的 List。因此,写操作的性能较低,而且会消耗更多的内存。
特点:
- 写操作在一个复制的数组上进行,读操作还是在原始数组中进行,读写分离,互不影响。
- 写操作需要加锁,防止并发写入时导致写入数据丢失。
- 写操作结束之后需要把原始数组指向新的复制数组。
- 在写操作的同时允许读操作,大大提高了读操作的性能,因此很适合读多写少的应用场景。
- 内存占用:在写操作时需要复制一个新的数组,使得内存占用为原来的两倍左右。
- 数据不一致:读操作不能读取实时性的数据,因为部分写操作的数据还未同步到读数组中。
- 写入也不会阻塞读取操作,只有写入和写入之间需要进行同步等待,读操作的性能得到大幅度提升。
# 3.CopyOnWriteArrayList 使用场景
CopyOnWriteArrayList 的使用场景主要是在读操作远远多于写操作的情况下,例如缓存和事件监听器列表等。
CopyOnWriteArrayList 为 ArrayList 的线程安全版本,俗称写时复制,此思想在多种中间件中都有使用,比如 nacos,sentinel 等中间件.空间换时间,保证读的最大效率,牺牲一点写的性能.多使用在都多写少的场景下.由于读操作根本不会修改原有的数据,因此如果每次读取都进行加锁操作,其实是一种资源浪费。我们应该允许多个线程同时访问 List 的内部数据,毕竟读操作是线程安全的。
CopyOnWriteArrayList 其底层数据结构也是数组,但是在写操作的时候都会拷贝一份数据进行修改,修改完后替换掉老数据,从而保证只阻塞写操作,读操作不会阻塞,实现读写分离。
# 4.CopyOnWriteArrayList 简介
- CopyOnWriteArrayList 线程安全,默认容量为长度为 1 的 Object 数组,允许元素为 null。
- 使用 ReentrantLock 可重入锁,保证写操作的线程安全。
- 在写操作时,都需要拷贝一份数组,然后在拷贝的数组中进行相应的操作,最后再替换旧数组。
- 采用读写分离的实现,写操作加锁,读操作不加锁,而且写操作会占用较多空间,因此适用于读多写少的场景。
- CopyOnWriteArrayList 能保证最终一致性,但是不保证实时一致性,因为在写操作未完,而进行读操作时,由于写操作在新数组中操作,并不会影响到读操作,这是造成数据不一致性。
- CopyOnWriteArrayList 返回迭代器不会抛出 ConcurrentModificationException 异常,即它不是 fail-fast 机制的
# 5.CopyOnWriteArrayList 原理
CopyOnWriteArrayList 默认容量是数组长度为 1 的 Object 类型数组。
操作 array 底层数组,都是通过 setArray 和 getArray 来进行的。
/** The lock protecting all mutators */
// 使用可重入锁进行加锁,保证线程安全
final transient ReentrantLock lock = new ReentrantLock();
/** The array, accessed only via getArray/setArray. */
// 底层数据结构,注意这里用volatile修饰,确定了多线程情况下的可见性
private transient volatile Object[] array;
2
3
4
5
6
7
CopyOnWriteArrayList原理:
- CopyOnWriteArrayList 实现了 List 接口,因此它是一个队列。
- CopyOnWriteArrayList 包含了成员 lock。每一个 CopyOnWriteArrayList 都和一个监视器锁 lock 绑定,通过 lock,实现了对 CopyOnWriteArrayList 的互斥访问。
- CopyOnWriteArrayList 包含了成员 array 数组,这说明 CopyOnWriteArrayList 本质上通过数组实现的。
- CopyOnWriteArrayList 的“动态数组”机制 --
它内部有个“volatile 数组”(array)来保持数据。在“添加/修改/删除”数据时,都会新建一个数组,并将更新后的数据拷贝到新建的数组中,最后再将该数组赋值给“volatile 数组”。这就是它叫做 CopyOnWriteArrayList 的原因!CopyOnWriteArrayList 就是通过这种方式实现的动态数组;不过正由于它在“添加/修改/删除”数据时,都会新建数组,所以涉及到修改数据的操作,CopyOnWriteArrayList 效率很 低;但是单单只是进行遍历查找的话,效率比较高。 - CopyOnWriteArrayList 的“线程安全”机制 -- 是通过 volatile 和 ReentrantLock 来实现的。
- CopyOnWriteArrayList 是通过“volatile 数组”来保存数据的。一个线程读取 volatile 数组时,总能看到其它线程对该 volatile 变量最后的写入;就这样,通过 volatile 提供了“读取到的数据总是最新的”这个机制的 保证。
- CopyOnWriteArrayList 通过监视器锁 ReentrantLock 来保护数据。在“添加/修改/删除”数据时,会先“获取监视器锁”,再修改完毕之后,先将数据更新到“volatile 数组”中,然后再“释放互斥锁”;这样,就达到了保护数据的目的。
# 6.CopyOnWriteArrayList 的 add 方法
add 操作是加了锁的,利用了 ReentrantLock 进行加锁,注意使用该方式进行加锁,需要手动释放。
整个过程是新建了一个新的数组(数组长度加 1),然后将新元素放在最后一位,最后替换掉旧数组
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
// 注意这里将数组长度加1
Object[] newElements = Arrays.copyOf(elements, len + 1);
// 新元素放在最后一位
newElements[len] = e;
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 7.写时复制的缺点?
内存占用问题:
- 因为 CopyOnWrite 的写时复制机制,所以在进行写操作的时候,内存里会同时驻扎两个对象的内存,这一点会占用额外的内存空间。
- 在元素较多或者复杂的情况下,复制的开销很大
- 复制过程不仅会占用双倍内存,还需要消耗 CPU 等资源,会降低整体性能。
数据一致性问题:由于 CopyOnWrite 容器的修改是先修改副本,所以这次修改对于其他线程来说,并不是实时能看到的,只有在修改完之后才能体现出来。如果你希望写入的的数据马上能被其他线程看到,CopyOnWrite 容器是不适用的。volatile 关键字,数据可见性
private transient volatile Object[] array;
# 五.常见 Set 集合
# 1.说说 HashSet 的特点?
- 不能保证元素的排列顺序,顺序可能发生变化。
- 集合元素可以是 null,但只能有一个。
当向 HashSet 存入一个值时,需要计算 key 的 hashCode,并通过 hashCode 得到的结果再进行(length-1)&hash 得到 index 的位置,判断是否重复是通过 hashCode 和 equals 方法。存入数据是通过 key-value 方式,value 是初始化好的 new object。
# 2.HashSet 的底层原理?
底层是依赖 HashMap 实现的,通过 HashSet 的构造参数可以知道,用 HashMap 来初始化成员变量。所以 HashSet 的初始容量也是 1<<4 即 16,加载因子为 0.75f。
//构造函数
public HashSet() {
map = new HashMap<>();
}
2
3
4

# 3.如何判断元素重复的?
HashSet 通过元素的 hashCode 和 equals 方法判断元素重复。
HashSet 的 add 方法,其实是 HashMap 的 put 方法,第一个参数 e 代表了存入的元素,第二个参数 present 代表初始化好的 new object 对象,这样 HashSet 在存入一个值的时候就可以很好的利用 HashMap 的 put 方法 key-value 结构。
// 初始化好的对象
private static final Object PRESENT = new Object();
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
2
3
4
5
6
# 4.contains()时间复杂度?
HashSet 和 ArrayList 的查找方法 contains()时间复杂度分析
ArrayList 本质就是通过数组实现的,查找一个元素是否包含要用到遍历,时间复杂度是 O(N)
HashSet 的查找是通过 HashMap 的 containsKey 来实现的,判断是否包含某个元素的实现,时间复杂度是 O(1)
//ArrayList判断是否包含某个元素的源码实现:
public boolean contains(Object o) {
return indexOf(o) >= 0;
}
public int indexOf(Object o) {
if (o == null) {
for (int i = 0; i < size; i++)
if (elementData[i]==null)
return i;
} else {
for (int i = 0; i < size; i++) //从头遍历
if (o.equals(elementData[i]))
return i;
}
return -1;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
//HashSet判断是否包含某个元素的源码实现:
public boolean contains(Object o) {
return map.containsKey(o);
}
public boolean containsKey(Object key) {
return getNode(hash(key), key) != null;
}
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) { //直接通过hash确定元素位置,不用从头遍历
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
if ((e = first.next) != null) {
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))//部分情况下可能会继续遍历链表定位
return e;
} while ((e = e.next) != null);
}
}
return null;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
# 5.LinkedHashSet 特点?
//定义
public class LinkedHashSet<E>
extends HashSet<E>
implements Set<E>, Cloneable, java.io.Serializable {
}
2
3
4
5
LinkedHashSet 是 Java 中的一个集合类,它是 HashSet 的一个子类,具有 HashSet 的所有特性,同时还保证了元素的顺序。
LinkedHashSet 使用哈希表来存储元素,与 HashSet 类似,它也是基于散列值来快速查找元素。但是,与 HashSet 不同的是,LinkedHashSet 还使用了一个双向链表来维护元素的插入顺序,从而保证了元素的顺序。因此,LinkedHashSet 中的元素是按照插入顺序进行排序的。
LinkedHashSet的主要特点如下:
- 元素唯一:LinkedHashSet 中的元素是唯一的,每个元素只会出现一次。
- 有序性:LinkedHashSet 中的元素是有序的,按照插入顺序进行排序。
- 性能:LinkedHashSet 的性能与 HashSet 类似,具有快速的查找和插入性能。
使用 LinkedHashSet 可以方便地维护元素的顺序,同时又具有 HashSet 的高效性能,因此在需要维护元素顺序的场景中,可以使用 LinkedHashSet 来代替 HashSet。
# 6.LinkedHashSet 源码?
HashSet 是依赖 HashMap,但是不是继承关系,是构造器时 new 的 HashMap。
//LinkedHashSet继承了HashSet
public class LinkedHashSet<E>
extends HashSet<E>
implements Set<E>, Cloneable, java.io.Serializable {
}
2
3
4
5
//HashSet其中一个构造器
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
2
3
4
分析 HashSet 的构造函数可以知道 只有一个 default 修饰的走了 LinkedHashMap,也就是专门为 LinkedHashSet 准备的。default 修饰的同包才能访问。其他的构造函数都是 new 的 HashMap 的构造函数。
# 7.说说 TreeSet?
TreeSet 是 Java 中的一个集合类,它实现了 Set 接口,可以存储一组唯一的元素,并且按照升序或自定义排序顺序来进行排序。它是基于红黑树(Red-Black Tree)数据结构来实现的,因此可以在 O(log n)的时间复杂度内完成插入、删除和查找等操作。
# 8.TreeSet 特点?
TreeSet的特点包括:
- 无重复元素:TreeSet 中不允许重复的元素,即集合中的元素是唯一的。
- 自动排序:TreeSet 会根据元素的自然顺序(如果元素实现了 Comparable 接口)或者自定义的比较器(通过构造函数指定)来对元素进行排序。在默认情况下,元素必须实现 Comparable 接口,否则在添加元素时可能会抛出 ClassCastException。
- 高效的查找:由于 TreeSet 使用红黑树作为底层数据结构,它能够在 O(log n)的时间复杂度内进行插入、删除和查找操作,使得它在处理大量数据时具有良好的性能。
需要注意的是,由于 TreeSet 是有序集合,因此它不适合用于需要保持元素插入顺序的场景。如果您需要保留插入顺序,请考虑使用 LinkedHashSet。
# 9.TreeSet 和 TreeMap?
与 HashSet 和 LinkedHashSet 一个套路,TreeSet 其实是使用了 TreeMap 的结构
TreeMap 也是 key-value 的结构,TreeSet 和 TreeMap 并没有继承关系,只是构造的时候使用了 TreeMap 构造函数。
//定义
public class TreeSet<E> extends AbstractSet<E>
implements NavigableSet<E>, Cloneable, java.io.Serializable
{
............
}
2
3
4
5
6
// TreeSet的构造器
public TreeSet() {
this(new TreeMap<E,Object>());
}
public TreeSet(Comparator<? super E> comparator) {
this(new TreeMap<>(comparator));
}
public TreeSet(Collection<? extends E> c) {
this();
addAll(c);
}
public TreeSet(SortedSet<E> s) {
this(s.comparator());
addAll(s);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 六.不可变集合
# 1.unmodifiableCollection
unmodifiableCollection()方法的功能:返回的 collection 是不可修改的视图
unmodifiableCollection()方法语法:
#参数说明:
#co:设置不可修改视图的对象
public static List unmodifiableCollection(Collection co)
2
3
注意事项:
- unmodifiableCollection()方法在 java.util 包中可用
- unmodifiableCollection()方法用于获取给定的不可修改视图
- unmodifiableCollection()方法是一个静态方法,可以通过类名进行访问,如果我们尝试使用类对象访问该方法,那么我们也不会收到任何错误
- unmodifiableCollection()方法在修改给定集合时可能会引发异常
- UnsupportedOperationException:当我们尝试修改给定的集合时,可能会抛出此异常
@Slf4j
public class Basic_25_unmodifiable {
public static void main(String[] args) {
//实例化链接列表对象
List<Integer> list = new LinkedList();
//通过使用add()方法是添加
//链表中的对象
list.add(88);
list.add(99);
list.add(22);
list.add(123);
list.add(2322);
//显示链接列表
System.out.println("LinkedList: " + list);
//通过使用unmodifiableCollection()方法是
list = (List<Integer>) Collections.unmodifiableCollection(list);
list.add(888);/*此处会发生异常*/
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 2.unmodifiableSet
public class Basic_01_unmodifiable {
public static void main(String[] args) {
//实例化链接列表对象
Set<Integer> list = new HashSet<>();
//通过使用add()方法是添加
//链表中的对象
list.add(88);
list.add(99);
list.add(22);
list.add(123);
list.add(2322);
//显示链接列表
System.out.println("LinkedList: " + list);
//通过使用unmodifiableCollection()方法是
list = (Set<Integer>) Collections.unmodifiableSet(list);
list.add(888);/*此处会发生异常*/
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 3.unmodifiableNavigableSet
此方法将返回给定 Navigable 集的不可修改视图。
用法:
public static <T> NavigableSet<T> unmodifiableSortedSet(SortedSet<T> data)
其中,数据是在不可修改的视图中返回的可导航集。
public class Basic_03_unmodifiableNavigableSet {
public static void main(String[] args) {
//实例化链接列表对象
NavigableSet<Integer> set = new TreeSet<>();
//通过使用add()方法是添加
//链表中的对象
set.add(88);
set.add(99);
set.add(22);
set.add(123);
set.add(2322);
//显示链接列表
System.out.println("LinkedList: " + set);
set = Collections.unmodifiableNavigableSet(set);
set.add(888);/*此处会发生异常*/
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 4.unmodifiableMap
public class Basic_04_unmodifiableMap {
public static void main(String[] args) {
//实例化链接列表对象
Map<Integer, Integer> map = new HashMap<>();
//通过使用add()方法是添加
//链表中的对象
map.put(2, 88);
map.put(1, 99);
map.put(1, 22);
map.put(1, 123);
map.put(1, 2322);
//显示链接列表
System.out.println("HashMap: " + map);
map = Collections.unmodifiableMap(map);
map.put(888, 888);/*此处会发生异常*/
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 5.unmodifiableNavigableMap
public class Basic_05_unmodifiableNavigableMap {
public static void main(String[] args) {
//实例化链接列表对象
NavigableMap<Integer, Integer> map = new TreeMap<>();
//通过使用add()方法是添加
//链表中的对象
map.put(2, 88);
map.put(1, 99);
map.put(1, 22);
map.put(1, 123);
map.put(1, 2322);
//显示链接列表
System.out.println("HashMap: " + map);
map = Collections.unmodifiableNavigableMap(map);
map.put(888, 888);/*此处会发生异常*/
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
← 04-泛型 06-队列Queue →