
# 一.基础命令
# 1.列出文件
ls是最基本的列出文件和目录的命令,它以简洁的方式显示文件和目录的名称。ls 命令的输出通常是单列的文件和目录列表,每个条目占据一行。
ll实际上是 ls 命令的一个别名或缩写。在大多数 Linux 或 Unix 系统中,ll命令通常被设置为以更详细的格式显示文件和目录的列表,包括文件的权限、所有者、大小、修改日期等信息。
请注意,ll 命令并不是标准的 Unix/Linux 命令,而是一些发行版(如 Ubuntu)对 ls 命令的别名。因此,ll 命令的可用性可能会因不同的系统而有所差异。如果你的系统上没有 ll 命令,你可以使用 ls 命令的其他选项来实现类似的效果,比如ls -l。
# 简略列出文件和文件夹
ls
# 详细列出文件和文件夹
ll
# 模糊匹配列出
ll *_eval_*
2
3
4
5
6
7
8

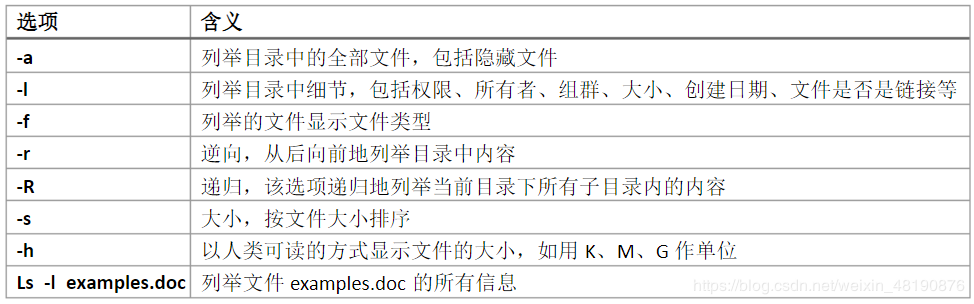
- 第一列:文件类型和权限信息。
- 第二列:链接数(硬链接数)。
- 第三列:所有者。
- 第四列:所属组。
- 第五列:文件大小(以字节为单位)。
- 第六列:最后修改时间。
- 第七列:文件或目录的名称。
列出文件:
# 显示全部文件
ls -al
# 人类可读的大小
ls -alh
# 查看文件类型
file start.sh
2
3
4
5
6
7
8
# 大小反序
ls -sS
# 大小反序
ls -lS
# 大小正序
ls -lSr
# recursive,递归显示子目录
ls -R
# (大写)按照文件大小排序
ls -S
# 按照最后修改时间排序
ls -t
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 2.创建文件
#touch
touch log.out
#vim
vim log.out
#cp
cp log1.out log.out
#> 覆盖原文件
#>> 追加在原文件的末尾
>> log.out
#创建文件
ls > log.out
#追加在末尾
ps -ef |grep java >> log.out
echo $PATH >> log.out
cat >> log.out
#追加11111到文件末尾
echo '11111' >> index.html
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
创建文件可以通过以下方式来完成。
- >:标准重定向符允许我们创建一个 0KB 的空文件。
- touch:如果文件不存在的话,touch 命令将会创建一个 0KB 的空文件。
- echo:通过一个参数显示文本的某行。
- printf:用于显示在终端给定的文本。
- cat:它串联并打印文件到标准输出。
- vi/vim:Vim 是一个向上兼容 Vi 的文本编辑器。它常用于编辑各种类型的纯文本。
- nano:是一个简小且用户友好的编辑器。它复制了 pico 的外观和优点,但它是自由软件。
- head:用于打印一个文件开头的一部分。
- tail:用于打印一个文件的最后一部分。
- truncate:用于缩小或者扩展文件的尺寸到指定大小。
# 3.创建文件夹
#创建文件夹
mkdir /home/ds
#创建多级文件夹
mkdir -p project/App
#没有使用“-p”这个参数的情况下
mkdir project project/App
#打印创建细节
mkdir -v home
2
3
4
5
6
7
8
9
10
11
# 4.删除文件
# 删除空目录
rm -d kwan
# 递归删除
rm -r /var
# 删除确认
rm -i /var
# 删除文件
rm access.txt
# 模糊删除
rm *_eval_*
# 强制删除文件
rm -f /var/log/httpd/access.log
# 强制递归删除文件夹
rm -rf /var
# 批量删除以test开头的文件,并自动确认
yes | rm test*.txt
# 删除文件夹
rmdir redis
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# 5.复制文件
#复制单个文件
cp 111.txt /target
#打印复制细节
cp -v 111.txt /target
#提醒确认
cp -i 111.txt /target
#复制所有文件
cp -r /home/packageA/* /home/cp/packageB/
#如果目标位置有这个文件,则文件内容会被覆盖
cp 111.txt /target
#强制复制,先删除再复制
cp -f 111.txt /target
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 6.重命名文件
将 abc 改为 1234
mv abc.txt 1234.txt
# 7.移动文件
#移动单个文件
mv 111.txt /target
#移动所有文件
mv /kwan/blog/blog/docs/.vuepress/public/* /kwan/blogImg
#backup,为目标路径下的重名文件生成备份文件
mv -b 111.txt /target
#force,强制覆盖目标路径下的重名文件
mv -f 111.txt /target
#interactive,覆盖前询问用户
mv -i 111.txt /target
#no-clobber,不覆盖已经存在的文件
mv -n 111.txt /target
#verbose,显示详细的移动过程
mv -v 111.txt /target
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 8.解压缩
-z或--gzip或--ungzip:通过 gzip 算法解压文件-x或--extract或--get:解压文件-c:压缩文件-v或--verbose:详尽列出-f:指定文件名称
#解压缩
tar -zxvf xxxx.zip
#压缩
tar -cvf 1.tar 1.txt
2
3
4
5
# 二.进阶命令
# 1.查看文件大小
Size 表示的是文件大小,这个也是大多数人看到的大小;
Blocks 表示的是物理实际占用空间
linux 中 ll 命令显示 的大小 是以“字节”为单位的。
ll 显示的是字节,可以使用-h 参数来提高文件大小的可读性,另外 ll 不是命令,是 ls -l 的别名
1G=1024M=1024x1024KB=1024x1024x1024B
#查看文件的具体信息
stat testfile
#以字节单位显示文件或者文件夹大小
ls -al
#查看文件大小
ll -alh
ll -bh
ll -kbh
2
3
4
5
6
7
8
9
10


# 2.文件类型
ll 命令共显示了七列信息,从左至右依次为:
权限、文件数、归属用户、归属群组、文件大小、创建日期、文件名称
| 文件颜色 | 含义 |
|---|---|
| 红色 | 压缩文件或者包文件 |
| 蓝色 | 目录 |
| 绿色 | 可执行文件,可执行的程序 |
| 白色 | 一般文件,如文本文件,配置文件,源码文件等 |
| 浅蓝色 | 链接文件,主要是使用 ln 命令建立的文件 |
| 红色闪烁 | 表示链接的文件有问题 |
| 黄色 | 表示设备文件 |
| 灰色 | 表示其他文件 |
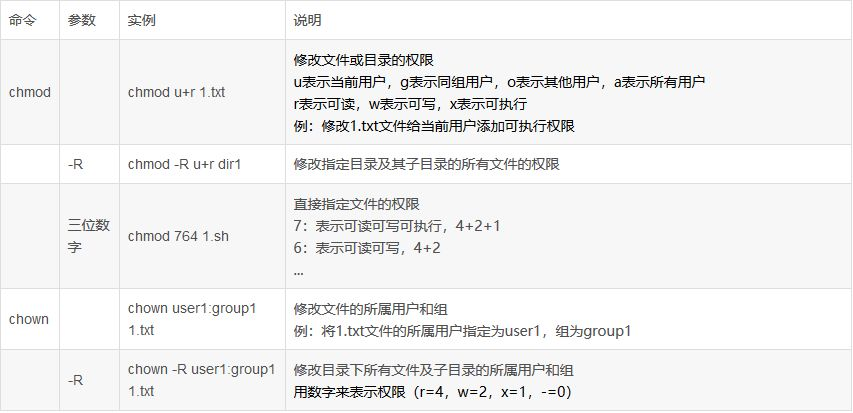
# 3.文件权限说明
文件权限说明:
- linux 文件权限的描述格式解读

- r 可读权限,w 可写权限,x 可执行权限(也可以用二进制表示 111 110 100 --> 764)
- 第 1 位:文件类型(d 目录,- 普通文件,l 链接文件)
- 第 2-4 位:所属用户权限,用 u(user)表示
- 第 5-7 位:所属组权限,用 g(group)表示
- 第 8-10 位:其他用户权限,用 o(other)表示
- 第 2-10 位:表示所有的权限,用 a(all)表示
# 4.文件授权
#给文件添加可执行权限
chmod 744 eureka_server.sh
#给多个文件添加可执行权限
chmod 744 main-kill.sh worknode.sh worknode-kill.sh
2
3
4
5
#颜色变绿,可执行
chmod +x main-kill.sh worknode.sh worknode-kill.sh
rwx |数字 权限组合
----+-----------
001 | 1 x 执行
010 | 2 w 写入
100 | 4 r 读取
101 | 5 rx 读取和执行
110 | 6 rw 读取和写入
111 | 7 rwx 读取和写入和执行
#方法一:777代表三个维度的权限 创建人、创建组、其他
chmod 777 file_name
#方法二: a-all u-用户 g-组 o-其他 +代表给权限 -删权限
chmod g+x a.txt # 所有组添加执行权限
chmod g-w o-w a.txt # 禁止同组和其他用户修改
chmod a+rwx a.txt # 所有用户可读可写可执行
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
取消执行权限
chmod 755 image
# 5.显示行号
#在编辑模式下
vim 111.text
#显式行号
:set nu
#去除行号
:set nonu
2
3
4
5
6
7
8
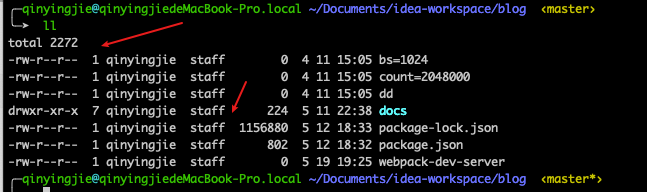
# 6.区分文件文件夹
使用 ll 命令,查看文件
- d 表示文件夹
- -表示文件
- l 表示链接
#查看文件命令 d表示文件夹 l表示链接 -表示文件
ll
2
# 7.linux 目录
| 目录 | 含义 |
|---|---|
| bin | 存放二进制可执行文件 |
| sbin | 存放二进制可执行文件,只有 root 才能访问 |
| etc | 存放系统配置文件 |
| usr | 用于存放共享的系统资源 |
| home | 存放用户文件的根目录 |
| root | 超级用户目录 |
| dev | 用于存放设备文件 |
| lib | 存放跟文件系统中的程序运行所需要的共享库及内核模块 |
| mnt | 系统管理员安装临时文件系统的安装点 |
| boot | 存放用于系统引导时使用的各种文件 |
| tmp | 用于存放各种临时文件 |
| var | 用于存放运行时需要改变数据的文件 |
# 8.tmp 文件
linux 中 tmp 指的是一个存储临时文件的文件夹,该文件夹包含系统和用户创建的临时文件;
/tmp:目录默认清理 10 天未用的文件,系统重启会清理目录
/var/tmp:目录默认清理 30 天未用的文件。
# 9.chown 和 chmod 的区别
chown 和 chmod 是两个在类 Unix 系统中常用的命令,它们都与文件权限管理有关,但用途和作用不同:
chown:
- 用途:改变文件或目录的所有者(owner)和/或所属组(group)。
- 作用:
chown命令用于修改文件或目录的所有权。它可以改变文件的用户所有者和/或用户组。这对于权限管理非常重要,因为不同的用户和组可能需要对文件或目录有不同的访问权限。 - 语法:
chown [options] owner[:group] file...或chown [options] :group file...
chmod:
- 用途:改变文件或目录的访问权限。
- 作用:
chmod命令用于修改文件或目录的权限。它允许你设置文件的读(r)、写(w)和执行(x)权限,这些权限可以应用于文件的所有者、所属组和其他用户。 - 语法:
chmod [options] mode file...或chmod [options] reference file...
区别:
- 对象不同:
chown改变的是文件的所有者和组,而chmod改变的是文件的访问权限。 - 权限级别:
chown不涉及文件的读、写、执行权限,而chmod正是用于设置这些权限。 - 使用场景:如果你需要改变谁可以拥有这个文件或谁可以对文件进行操作,你会使用
chown。如果你需要改变文件的读、写、执行权限,你会使用chmod。
例如,如果你想要将一个文件的所有权转给用户 bob,你可以使用 chown bob filename。如果你想要给所有用户读和执行权限,但只给文件所有者写权限,你可以使用 chmod 755 filename。
# 三.高阶文件命令
# 1.nano 编辑文件
#进入文件
nano 111.txt;
#直接修改文件,默认进入插入模式
#保存
Ctrl+O
#Enter确认
#退出
Ctrl+X
#Enter确认
2
3
4
5
6
7
8
9
10
11
12
13
14
# 2.文件传输
sftp:
#上传 mac 本地文件至 Linux 服务器
put localfiledirectory remotefiledirectory
#下载 Linux 服务器文件至 mac 本地
get remotefiledirectory localfiledirectory
2
3
4
5
scp:
#上传 mac 本地文件至 Linux 服务器
scp localfiledirectory root@ip:remotefiledirectory
#下载 Linux 服务器文件至 mac 本地
scp root@ip:remotefiledirectory localfiledirectory
2
3
4
5
#上传文件到服务器
scp /Users/qinyingjie/Downloads/sentinel-dashboard-1.8.6.jar root@43.139.90.182:/kwan/software
#从服务器下载文件夹 -r 表示移动子文件下的文件
scp -r root@43.139.90.182:/opt/nacos/ /Users/qinyingjie/Downloads/
2
3
4
5
服务器之间:
scp -r /data/images/mysql.tar /data/images/redis-6-alpine.tar root@39.107.53.15:/data/
# 3.上传下载
rz、sz 是 Linux/Unix 同Windows进行 ZModem 文件传输的命令行工具。
优点:就是不用再开一个 sftp 工具登录上去上传下载文件。
sz(下载):将选定的文件发送(send)到本地机器
rz(上传):运行该命令会弹出一个文件选择窗口,从本地选择文件上传到 Linux 服务器
# 4.重复 uniq
删除文件中的重复内容。【注意】它只能去除连续重复的行数。
基础语法
# 去除name.txt重复的行数,并打印到屏幕上
uniq name.txt
# 把去除重复后的文件保存为 uniq_name.txt
uniq name.txt uniq_name.txt
2
3
4
5
常用参数
-c统计重复行数,uniq -c name.txt;-d只显示重复的行数,uniq -d name.txt。
# 5.创建一个大文件
创建一个 5G 的文件
dd if=/dev/zero of=/test.wm bs=100M count=50
# 6.strace
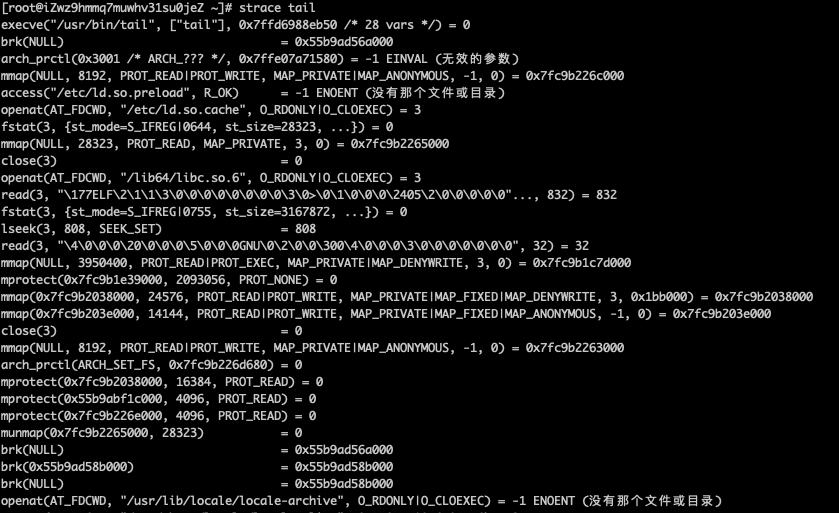
追踪命令
strace tail
# 7.替换
# 示例,将1111全部替换为2222
:%s/1111/2222/g
2
# 四.find 命令
# 1. find命令简介
find命令是 Unix 和类 Unix 操作系统中用于搜索文件的命令行工具。它可以在指定目录及其子目录下,根据文件名、类型、大小、修改时间等条件来查找文件。
# 2. 基本语法
find命令的基本语法如下:
find [搜索路径] [搜索条件] [执行动作]
- 搜索路径:指定
find命令开始搜索的目录。如果不指定,默认为当前目录。 - 搜索条件:定义搜索文件的规则,如文件名、类型、大小、修改日期等。
- 执行动作:对找到的文件执行的操作,如打印文件名、执行命令等。
# 3. 根据文件名搜索
在实际使用中,我们经常需要根据文件名来搜索文件。find命令提供了-name选项来实现这一功能。例如,要搜索当前目录下所有包含nltk的文件,可以使用以下命令:
find . -name "*nltk*"
这里的*是一个通配符,代表任意数量的任意字符。
-name
#在当前目录下搜索名为 `file.txt` 的文件:
find . -name "file.txt"
#查找etc文件夹下名字中带有pro的文件
find /etc -name pro*
#查询到打印出来
find . -name "数据结构与算法2.md" -print
#忽略名称大小写
find . -iname t.txt
2
3
4
5
6
7
8
9
10
11
# 4. 使用通配符
通配符是find命令中非常重要的一个概念。除了上面提到的*,还有以下几种常用的通配符:
?:匹配任意单个字符。[abc]:匹配 a、b 或 c 中的任意一个字符。[!abc]:匹配除了 a、b、c 之外的任意单个字符。
# 5. 搜索特定类型的文件
除了根据文件名搜索,find命令还可以根据文件类型进行搜索。例如,使用-type选项可以搜索特定类型的文件:
f:普通文件d:目录l:符号链接
例如,搜索当前目录下所有的目录:
find . -type d
-type
#当前目录下的文件夹以及子文件夹
find . -type d
#当前目录下的普通文件以及子目录下的文件
find . -type f
#当前目录下的符号链接以及子目录下的符号链接
find . -type l
#拥有可执行权限
find / -type f -executable
2
3
4
5
6
7
8
9
10
11
# 6. 搜索特定大小的文件
使用-size选项可以搜索特定大小的文件。例如,搜索当前目录下所有大于 10MB 的文件:
find . -size +10M
-size
#小于1M的文件
find . -size -1M
#大于1M的文件
find . -size +1M
#在 `/home` 目录下搜索大小为 1MB 的文件
find /home -size 1M
2
3
4
5
6
7
8
# 7. 搜索特定修改时间的文件
使用-mtime选项可以搜索特定修改时间的文件。例如,搜索当前目录下最近 7 天内被修改过的文件:
find . -mtime -7
时间
#最近7天内修改过的文件
find . -mtime -7
#最近7天修改过
find /var/log -mtime -7
#7天之前修改过的文件
find . -mtime +7
2
3
4
5
6
7
8

三种时间
| 简称 | 全称 | 说明 |
|---|---|---|
| a | Access time | 访问时间 |
| m | Modify time | 修改时间(内容) |
| c | change time | 变更时间(状态) |
# 8.根据权限查找
-user
#拥有 `root` 用户权限
find /home -user root
#拥有 `root` 组权限
find /home -group root
2
3
4
5
# 9. 对找到的文件执行命令
find命令可以对找到的文件执行特定的命令。使用-exec选项可以实现这一点。例如,对所有找到的 Python 文件执行grep命令,搜索包含import的行:
find . -name "*.py" -exec grep "import" {} \;
这里的{}代表当前找到的文件名,\;表示命令的结束。
# 10.根目录查找
find / -name cacert.pem
# 五.awk 命令
# 1.文本三剑客
三剑客:awk、grep、sed
grep常用于查找sed常用于取行和替换awk常用于运算
# 2.awk 介绍
awk 是一个强大的文本处理工具,通常用于处理结构化文本数据,例如日志文件、CSV 文件等。它允许你从文本中提取、转换和格式化数据,还可以进行数学运算和逻辑操作。AWK 是一种强大的文本处理工具,它起源于 Unix 系统,用于模式扫描和处理语言。AWK 的名称来源于其创始人 Alfred Aho、Peter Weinberger 和 Brian Kernighan 的姓氏首字母。AWK 特别适合于处理结构化数据,如 CSV 或 TSV 文件,以及任何行和列的文本数据。
# 3.基本语法
awk 的基本语法如下:
awk 'pattern { action }' input_file
pattern定义了匹配的条件。action是要执行的动作。input_file是要处理的输入文件。
# 4.打印文件内容
最简单的 awk 命令是打印整个文件的内容:
awk '{ print }' input_file
# 5.按列处理数据
awk 默认以空格作为字段分隔符,可以按列处理数据。例如,打印文件的第一列:
awk '{ print $1 }' input_file
# 6.打印特定行
如果我们只想打印第 10 行,可以使用:
awk 'NR == 2' file.txt
NR 是一个内置变量,表示当前处理的是第几行。
# 7.模式匹配
AWK 允许使用正则表达式进行模式匹配。例如,如果我们想要匹配包含单词 "error" 的行,可以这样做:
awk '/error/' file.log
# 8.处理多个文件
AWK 可以同时处理多个文件,只需将它们作为参数传递:
awk '{print FILENAME, $0}' file1.txt file2.txt
这将打印每个文件的名称和内容。
# 9.条件处理
awk 可以根据条件选择性地处理数据行。例如,打印第一列等于 "value" 的行:
awk '$1 == "value" { print }' input_file
# 10.计算和统计
awk 具有内置的数学运算功能,可以用于计算和统计。例如,计算第二列的平均值:
awk '{ sum += $2 } END { print "Average: " sum / NR }' input_file
# 11.自定义字段分隔符
如果输入数据的字段分隔符不是空格,你可以使用 -F 选项来指定分隔符。例如,以逗号分隔的 CSV 文件:
awk -F ',' '{ print $1, $2 }' input_file
# 12.循环处理
使用 for 循环处理数据行:
awk '{ for (i = 1; i <= NF; i++) print $i }' input_file
# 13.内置变量
awk 有许多内置变量,如 NR(行号)、NF(字段数),它们可用于数据处理。
这只是 awk 的一些基本用法示例。awk 具有非常强大的功能,可以根据不同的需求进行高级文本处理和数据操作。它是一个非常有用的文本处理工具,特别适合处理大型文本文件和数据提取任务。
AWK 提供了一些内置变量,这些变量在处理文本时非常有用:
$1, $2, ...:这些变量代表当前行的字段,由 FS(字段分隔符)分隔。NF:表示当前行的字段总数。NR:表示当前处理的行号。FNR:表示当前文件的行号。FS:字段分隔符,默认为空格或制表符。RS:记录分隔符,默认为换行符。ORS:输出记录分隔符,默认为换行符。OFS:输出字段分隔符,默认为空格。

# 六.sed 命令
# 1.什么是 sed 命令
sed(Stream Editor)是一个在 Linux 和 UNIX 系统中非常有用的文本处理工具,它可以用来对文本文件进行替换、删除、插入、打印等操作。sed通过读取文本流并应用指定的编辑命令来实现这些操作,因此它适用于对大量文本数据进行批处理。
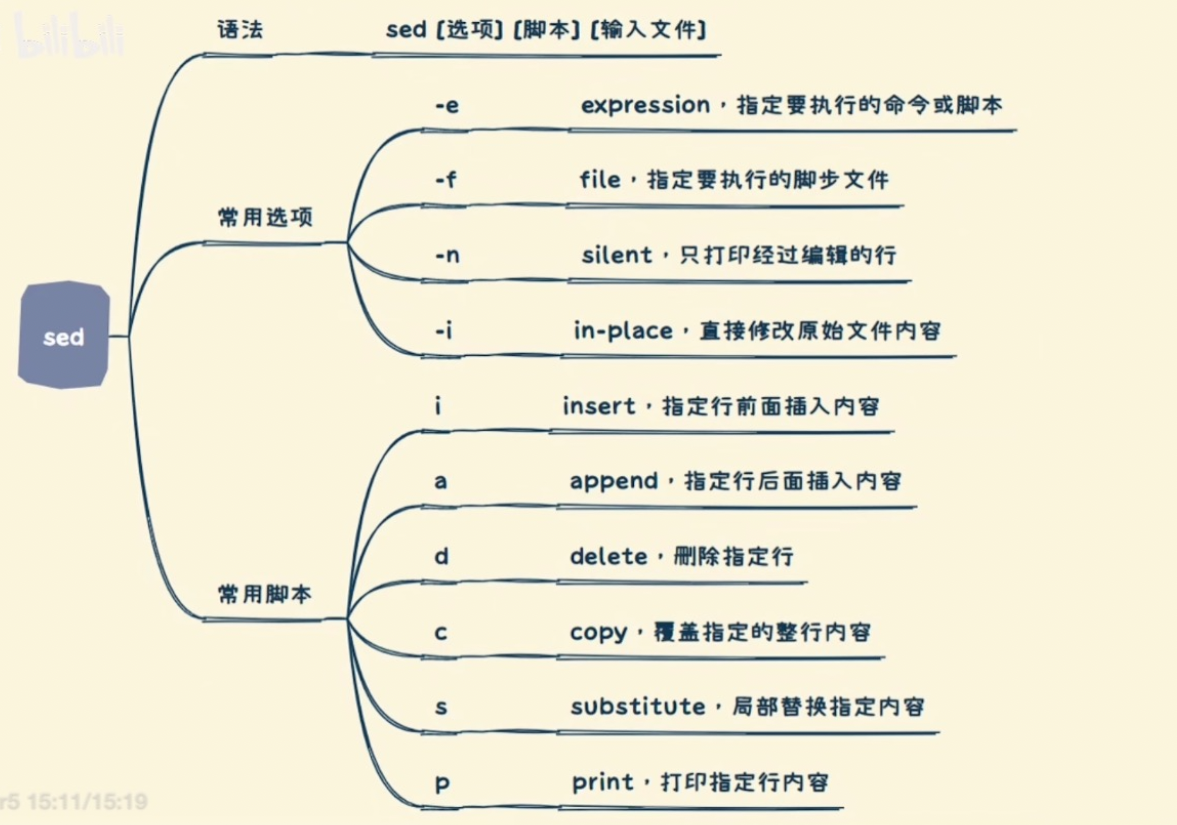
# 2.替换文本
sed 's/old_text/new_text/g' input_file > output_file
该命令将 input_file 中的所有匹配到的 old_text 替换为 new_text,并将结果输出到 output_file。
# 3.删除行
sed '/pattern/d' input_file > output_file
这会从 input_file 中删除包含匹配 pattern 的所有行,并将结果输出到 output_file。
# 4.插入和追加行
sed '3i\inserted_line' input_file > output_file
sed '$a\appended_line' input_file > output_file
2
第一个命令在 input_file 的第三行之前插入一行文本inserted_line,第二个命令在文件末尾追加一行文本appended_line。input_file文件内容不变,只是output_file的内容变了.
# 5.打印行
sed -n '5p' input_file
这将打印 input_file 中的第五行。
# 6.使用正则表达式
sed -E 's/regex_pattern/new_text/g' input_file > output_file
使用 -E 选项可以启用扩展正则表达式,然后你可以在替换命令中使用正则表达式模式。
# 7.全局替换和交互式替换
sed 's/old_text/new_text/g'
sed 's/old_text/new_text/g' input_file | tee output_file
2
第一个命令在标准输出中进行全局替换,第二个命令在替换的同时将结果输出到屏幕和文件。
# 8.在特定范围内应用命令
sed '2,5s/old_text/new_text/g' input_file > output_file
这会在第二行到第五行之间进行替换操作。
这只是 sed 的一些基本用法示例。它有许多功能强大的选项和命令,可以根据需要进行深入学习和使用。可以使用 man sed 命令在终端中查看 sed 的完整文档和帮助信息。
# 9.使用命令
sed 是 Linux 系统中一个非常强大的流编辑器,它可以用来执行文本替换、删除、插入等操作。以下是一些基本的 sed 命令用法:
替换文本:
sed 's/old/new/g' file.txt1这个命令会在
file.txt文件中将所有 "old" 替换为 "new"。替换特定行的文本:
sed '3s/old/new/' file.txt1这个命令只会替换文件的第 3 行中的 "old" 为 "new"。
删除文本:
sed 'd' file.txt1这个命令会删除文件中的每一行。
删除特定行:
sed '3d' file.txt1这个命令会删除文件的第 3 行。
插入文本:
sed 'i\new line' file.txt1这个命令会在文件的每一行之前插入 "new line"。
在特定行后插入文本:
sed '3i\new line' file.txt1这个命令会在文件的第 3 行之后插入 "new line"。
追加文本:
sed 'a\new line' file.txt1这个命令会在文件的每一行之后追加 "new line"。
在特定行后追加文本:
sed '3a\new line' file.txt1这个命令会在文件的第 3 行之后追加 "new line"。
打印行号:
sed = file.txt1这个命令会打印文件的每一行的行号。
使用正则表达式匹配:
sed '/^#/s/old/new/' file.txt1这个命令会替换以 "#" 开头的行中的 "old" 为 "new"。
使用扩展正则表达式:
sed -E 's/(old).*/\1new/' file.txt1这个命令会使用扩展正则表达式替换 "old" 及其后的所有文本为 "oldnew"。
使用多个 sed 命令:
sed -e 's/old/new/' -e 's/very/extremely/' file.txt1这个命令会先替换 "old" 为 "new",然后替换 "very" 为 "extremely"。
直接修改文件:
sed -i 's/old/new/' file.txt1这个命令会直接在文件中替换 "old" 为 "new",而不是输出到标准输出。
筛选:
sed -n '/特定字符串/p' 输入文件 > 输出文件 # 直接修改原始文件 sed -i 's/0523/0713/g' start.sh sed -n '/https:\/\/qinyingjie.top\/new-space\/kwan/p' 部署步骤.md > 部署步骤222.md1
2
3
4
5
6
7
8这个命令会查询含有特定字符串的行到新的文件。
# 七.grep 命令
# 1.忽略大小写
grep -i '111'
# 2.递归查找
grep -r /kwan
# 3.指定查找内容
grep -e '111'
# 4.启用正则
grep -E '111'
# 5.反向查找
#反向查找,只输出不匹配的行
grep -v '111'
2
# 6.匹配内容
grep -l '1111'
# 7.显示行号
#显示匹配内容的行号
grep -n '1111'
2
# 8.完全匹配
grep -w '1111'
# 9.匹配行及后 5 行
#打印匹配行的后 5 行
grep -A 5 'parttern' name.txt
2
# 10.匹配行及前 5 行
#打印匹配行的前 5 行
grep -B 5 'parttern' inputfile
2
# 11.匹配行及前后各 5 行
#打印匹配行的前后 5 行
grep -C 5 'parttern' inputfile
2
# 八.tree 命令
# 1.什么是tree命令?
tree命令是一个递归地列出目录内容的命令行工具。它可以以树状图的形式显示目录结构,包括文件和子目录。这使得用户能够快速地查看目录的层次结构和内容。
# 2.如何安装tree命令?
在大多数 Linux 发行版中,tree命令可能已经预装了。如果系统中没有安装,可以通过包管理器来安装。例如,在基于 Debian 的系统上,可以使用以下命令安装:
sudo apt-get install tree
在基于 Red Hat 的系统上,可以使用:
sudo yum install tree
# 3.命令格式
基本的tree命令格式如下:
tree [目录]
这将显示指定目录的树状结构。如果不指定目录,默认显示当前目录的树状结构。
# 4.参数说明
tree命令提供了许多选项来自定义输出的格式和内容。以下是一些常用的选项:
-a:显示所有文件,包括隐藏文件。-d:只显示目录,不显示文件。-f:在每个文件旁边显示文件名。-i:忽略大小写。-l:除了显示目录的树状结构外,还显示每个文件的详细信息,如权限、所有者等。--charset:定义输出使用的字符集。-L:指定目录树的深度。--noreport:不显示目录数、文件数和总大小的报告。
# 5.使用示例
基础使用:
tree core/_static/nltk_cache
这条命令将显示core/_static/nltk_cache目录的树状图。
高阶使用示例:
要显示包括隐藏文件在内的所有文件和目录,可以使用:
tree -a core/_static/nltk_cache
要显示每个文件的详细信息,可以使用:
tree -l core/_static/nltk_cache
# 6.定制tree命令的输出
tree命令的输出可以通过管道和其他命令组合来进一步定制。例如,使用grep命令过滤输出:
tree -f core/_static/nltk_cache | grep '.py'
这将只显示以.py结尾的文件。
# 7.tree命令的实用场景
- 快速查看目录结构:当需要快速了解目录的组织结构时。
- 文件管理:在进行文件整理或清理时,
tree命令可以帮助识别大型目录或文件。 - 脚本编写:在编写脚本时,
tree命令可以作为获取目录结构信息的工具。 - 报告生成:生成目录结构的报告,用于备份或审计。
# 九.vimdiff 命令
# 1.使用方式
vimdiff text001_副本.py text001.py
使用 vimdiff 的基本步骤如下:
打开终端并输入以下命令:
vimdiff file1 file2
其中 file1 和 file2 是要比较的两个文件的路径。
Vim 会打开一个新窗口,左侧显示 file1 的内容,右侧显示 file2 的内容。
使用 Vim 的移动光标和编辑命令来查看并编辑文件,如需保存修改,可以按下:wq保存并退出,或者:qa退出而不保存。
# 2.方向选择
# 1.水平切分
vimdiff -o test_副本.md test.md
# 2.垂直切分
默认是垂直切分
vimdiff test_副本.md test.md
vimdiff -O test_副本.md test.md
2
# 3.指定分屏个数
vimdiff 3 test_副本.md test.md
# 4.四个方向分屏
在 Vim 中,可以使用 :vsplit 命令来垂直分屏,使用 :split 命令来水平分屏。以下是使用 vimdiff 命令在四个方向进行分屏的示例:
打开终端,输入以下命令:
vimdiff file1.txt file2.txt1这将会在 Vim 中以水平分屏的方式打开
file1.txt和file2.txt,并进行比较。要在四个方向分屏,可以执行以下步骤:
- 首先,按下
Ctrl+w,然后按下v,以垂直分屏。 - 再次按下
Ctrl+w,然后按下s,以水平分屏。 - 选中其中一个分屏,切换到另一个文件,执行以下命令:
:vert diffsplit file3.txt1
这将会在当前选中的分屏右侧创建一个新的垂直分屏,显示
file3.txt,并进行比较。- 首先,按下
最后,选中任何一个分屏,执行以下命令:
:vertical res diffsplit file4.txt1这将会在当前选中的分屏下方创建一个新的水平分屏,显示
file4.txt,并进行比较。
这样就可以在 Vim 中实现四个方向的分屏,并进行文件比较。
# 3.文本编辑
# 1.基础修改
- 在 vimdiff 中,可以在左右两个窗口中进行文本编辑。
- 按
i进入插入模式编辑文本。 - 使用
Esc键退出插入模式。 - 使用
:w保存修改。
# 2.dp 命令
- 使用
:diffput <编号/缓冲区名>(简写为:dp)将当前窗口的更改推送到另一个窗口。
# 3.dg 命令
- 使用
:diffget <编号/缓冲区名>(简写为:dg)来获取左侧或右侧的更改并应用到当前窗口。
# 4.退出命令
qa
# 十.移动文件
# 1.移动所有文件
如果你想将 images 目录下的所有文件(而不是目录本身)移动到 /img/wechat/ 目录下,你应该使用以下命令:
mv images/* /img/wechat/
这里是命令的详细解释:
mv: 移动命令。images/*: 这表示images目录下的所有文件,不包括子目录。/img/wechat/: 目标目录。
执行这个命令后,images 目录下的所有文件将被移动到 /img/wechat/ 目录下,而 images 目录本身将保持不变。
# 2.包括子目录
命令 mv images/* /img/wechat/ 用于将 images 目录下的所有文件(但不包括目录)移动到 /img/wechat/ 目录下。这个命令不会递归地移动子目录,只移动文件。
如果你想要包括子目录及其内容,你需要使用递归移动命令。在大多数 Unix-like 系统中,你可以使用 cp 命令的 -r(或 --recursive)选项来递归地复制目录及其内容,然后使用 mv 来移动它们。例如:
cp -r images/* /img/wechat/
mv /img/wechat/images/* /img/wechat/
2
这里的步骤是:
cp -r images/* /img/wechat/:递归地复制images目录下的所有文件和子目录到/img/wechat/目录下,并保留原有的目录结构。mv /img/wechat/images/* /img/wechat/:移动/img/wechat/images目录下的所有文件和子目录到/img/wechat/的根目录下。
请注意,第二个命令中,我们首先复制到了 /img/wechat/images,然后再将这个 images 目录下的内容移动到 /img/wechat/ 的根目录下,这样就实现了递归移动包括子目录在内的所有内容。
# 3.包含目录
另外,如果你确定 images 目录下没有其他同名的目录或文件与目标目录 /img/wechat/ 中的内容冲突,你也可以直接使用:
mv images/ /img/wechat/
这将会把整个 images 目录及其内容移动到 /img/wechat/ 目录下。但是,如果 /img/wechat/ 中已经存在 images 目录,这个命令可能会失败或产生意外的结果。
# 4.注意点
注意:
- 确保你有足够的权限来移动这些文件。
- 如果
/img/wechat/目录不存在,你需要先创建它,否则移动操作会失败。 - 如果
/img/wechat/目录中已经存在与images目录下同名的文件,这个命令将会覆盖它们,除非你使用-n选项来防止覆盖,如下所示:mv -n images/* /img/wechat/1