
# 一.SDS 字符串
# 1.什么是 SDS?
Redis 没有直接使用 C 语言传统的字符串表示 (以空字符结尾的字符数组,以下简称 C 字符串),而是自己构建了 一种名为简单动态字符串(simple dynamic string,SDS)的抽象类型,并将 SDS 用作 Redis 的默认字符串表示。
存储 String 类型的 key-value 时,key 和 value 都是 SDS 类型的.字符串键值都用 SDS 表示.
redis> SET msg "hello world"
OK
2
SDS其他作用:
- 保存数据库中的字符串值;
- SDS 还被用作缓冲区(buffer);
- AOF 模块中的 AOF 缓冲区;
- 客户端状态中的输入缓冲区;
# 2.SDS 定义?
struct sdshdr{
//字节数组
char buf[];
//buf数组中已使用字节数量
int len;
//buf数组中未使用字节数量
int free;
}
2
3
4
5
6
7
8
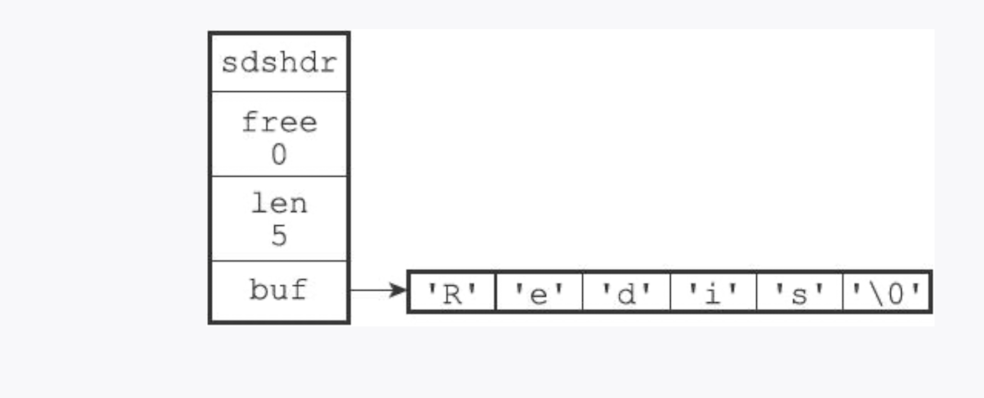
free属性的值为 0,表示这个 SDS 的空闲空间为 0。len属性的值为 5,表示这个 SDS 保存了一个五字节长的字符串。buf属性是一个 char 类型的数组,数组的前五个字节分别保存了'R'、'e'、'd'、i'、's'五个字符,而最后一个字节则保存了空字符'\0'。遵循 C 字符串的惯例,以空字符结尾.对于 SDS 使用者是透明的.
# 3.SDS 和 C 字符串的区别?
根据传统,C 语言使用长度为 N+1 的字符数组来表示长度为 N 的字符串,并且字符数组的最后一个元素总是空字符'\0'。
SDS 优点:
- 常数复杂度获取字符串长度 O(1)
- 杜绝缓冲区溢出,出现数据覆盖
- 空间预分配策略与惰性空间释放策略,减少修改字符串时带来的内存重分配次数
- 二进制安全,可以有特殊字符,SDS 通过 len 判断是否结束
- 兼容部分 C 字符串函数
# 4.什么是空间预分配?
空间预分配用于优化 SDS 的字符串增长操作:当 SDS 的 API 对一个 SDS 进行修改,并且需要对 SDS 进行空间扩展的时候,程序不仅会为 SDS 分配修改所必须要的空间,还会为 SDS 分配额外的未使用空间。
其中,额外分配的未使用空间数量由以下公式决定:
- 如果对 SDS 进行修改之后,SDS 的长度(也即是 len 属性的值)小于 1MB,那么程序分配和 len 属性同样大小的未使用空间,这时 SDS len 属性的值将和 free 属性的值相同。举个例子,如果进行修改之后,SDS 的 len 将变成 13 字节,那么程序也会分配 13 字节的未使用空间,SDS 的 buf 数组的实际长度将变成 13+13+1=27 字节(额外的一字节用于保存空字符)。
- 如果对 SDS 进行修改之后,SDS 的长度将大于等于 1MB,那么程序会分配 1MB 的未使用空间。举个例子,如果进行修改之后,SDS 的 len 将变成 30MB,那么程序会分配 1MB 的未使用空间,SDS 的 buf 数组的实际长度将为 30MB+1MB+1byte。
通过空间预分配策略,Redis 可以减少连续执行字符串增长操作所需的内存重分配次数。需要注意的是字符串最大长度为 512M。
# 5.什么是惰性空间释放?
惰性空间释放用于优化 SDS 的字符串缩短操作:当 SDS 的 API 需要缩短 SDS 保存的字符串时时,程序并不立即使用内存重分配来回收缩短后多出来的字节,而是是使用 free 属性将这些字节的数量记录起来,并等待将来使用。
通过惰性空间释放策略,SDS 避免了缩短字符串时所需的内存重分配操作,并为将来可能有的增长操作提供了优化。
与此同时,SDS 也提供了相应的 API,让我们可以在有需要时,真正地释放 SDS 的未使用空间,所以不用担心惰性空间释放策略会造成内存浪费。
# 二.数据结构
# 1.链表的结构?
链表的优点
- 链表提供了高效的节点重排能力,
- 以及顺序生的节点访问方式,
- 并且可以通过增删节点来灵活地调整链表的长度
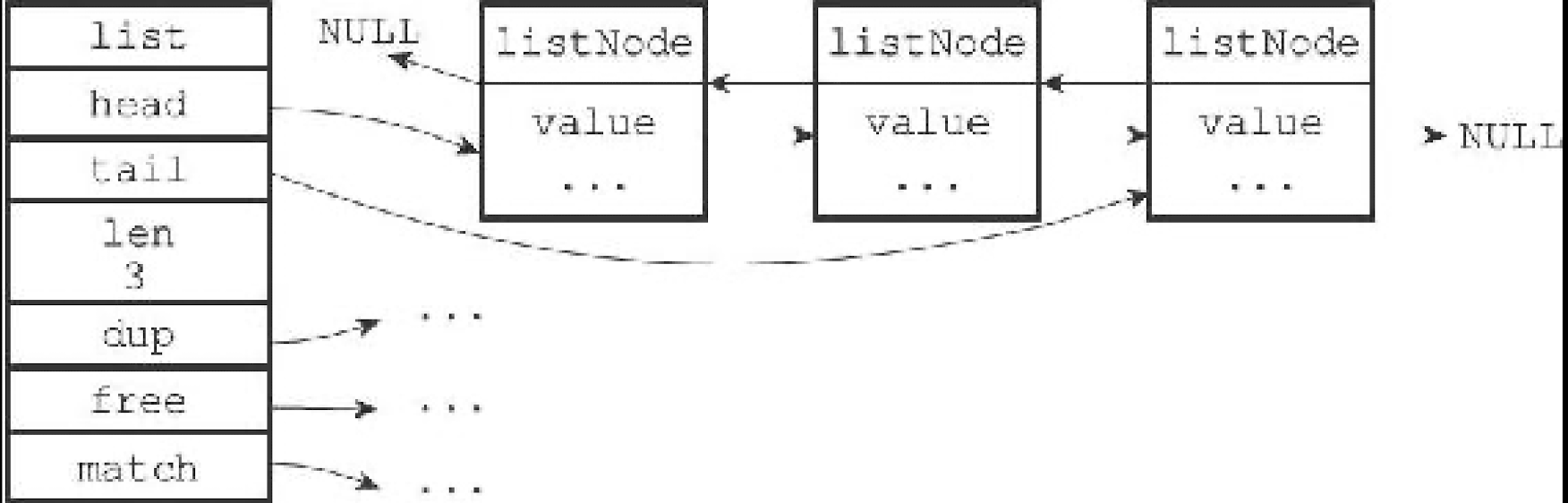
如上图所示,Redis 链表由一个 list 和任意多个 listNode 结构组成;
Redis 链表结构特点:双向,无环,具备表头和表尾指针,链表节点计算器,可保存不同类型
typedef struct listNode{
//前指针
struct listNode *prev;
//后指针
struct listNode *next;
void *value;
}ListNode;
2
3
4
5
6
7
typedef struct list{
listNode *head;//表头
listNode *tail;//表尾
unsigned long len;//节点数
void *(*dup)(void *ptr);//节点值复制函数
void (*free)(void *ptr);//节点释放函数
int (*match)(void *ptr,void *key);//节点值对比函数
}list;
2
3
4
5
6
7
8
# 2.链表实现的特性
双端:链表节点带有 prev 和 next 指针,获取某个节点的前置节点和后置节点的复杂度都是 O(1)。
无环:表头节点的 prev 指针和表尾节点的 next 指针都指向 NULL 对链表的访问以 NULL 为终点。
带表头指针和表尾指针:通过 list 结构的 head 指针和 tail 指针,程序获取链表的表头节点和表尾节点的复杂度为 O(1)。
带链表长度计数器:程序使用 list 结构的 len 属性来对 list 持有的链表节点进行计数,程序获取链表中节点数量的复杂度为 O(1)。
多态:链表节点使用 void*指针来保存节点值,并且可以通过 list 结构的 dup、free、match 三个属性为节点值设置类型特定函数,所以
链表可以用于保存各种不同类型的值。
# 3.字典
字典结构:
字典,又称为符号表(symbol table)、关联数组(associative array)或映射(map),是一种用于保存键值对(key-value pair)的抽象数据结构。
在字典中,一个键(key)可以和一个值(value)进行关联(或者说将键映射为值),这些关联的键和值就称为键值对。
字典中的每个键都是独一无二的,程序可以在字典中根据键查找与之关联的值,或者通过键来更新值,又或者根据键来删除整个键值对。
字典用哈希表做底层实现,哈希表由哈希表节点产生,每个节点保存了字典的键值对。
typedef struct dict {
//类型特定函数
dictType *type;
//私有数据
void *privdata;
//哈希表
dictht ht[2];
//rehash 索引。当rehash 不在进行时,值为-1
in trehashidx; /* rehashing not in progress if rehashidx == -1 */
} dict;
typedef struct dictType {
//计算哈希值的函数
unsigned int (*hashFunction)(const void *key);
//复制键的函数
void *(*keyDup)(void *privdata, const void *key);
//复制值的函数
void *(*valDup)(void *privdata, const void *obj);
//对比键的函数
int (*keyCompare)
(void *privdata, const void *key1, const void *key2);
//销毁键的函数
void (*keyDestructor)(void *privdata, void *key);
//销毁值的函数
void (*valDestructor)(void *privdata, void *obj);
} dictType;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
成员说明
- type 属性和 privdata 属性是针对不同类型的键值对,为创建多态字典而设置的
- type 属性是一个指向 dictType 结构的指针,每个 dictType 结构保存了一簇用于操作特定 类型键值对的函数,Redis 会为用途不同的字典设置不同的类型特定函数
- 而 privdata 属性则保存了需要传给那些类型特定函数的可选参数
- ht 属性是一个包含两个项的数组,数组中的每个项都是一个 dictht 哈希表,一般情况下, 字典只使用 ht[0]哈希表,ht[1]哈希表只会在对 ht[0]哈希表进行 rehash 时使用
- 除了 ht[1]之外,另一个和 rehash 有关的属性就是 rehashidx,它记录了 rehash 目前的进度,如果目前没有在进行 rehash,那么它的值为-1
hash 算法
当字典被用作数据库的底层实现,或者哈希键的底层实现时,Redis 使用 MurmurHash2 算法来计算键的哈希值。发生冲突时(键被分到哈希表数组同一个索引上),用拉链法解决,next 指向,新节点添加到链表表头(O (1))
#使用字典设置的哈希函数,计算键key 的哈希值hash = dict->type->hashFunction(key);
#使用哈希表的sizemask 属性和哈希值,计算出索引值
#根据情况不同,ht[x] 可以是ht[0] 或者ht[1]
index = hash & dict->ht[x].sizemask;
2
3
4
5
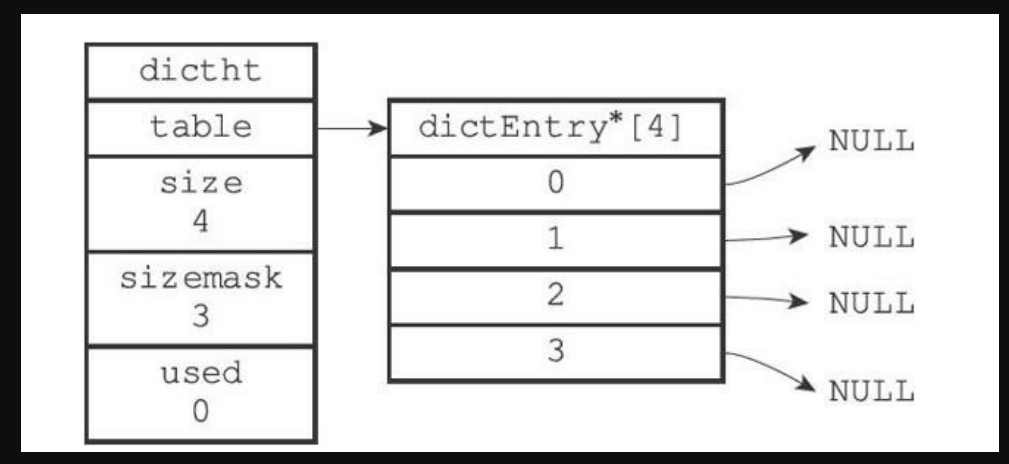
# 4.哈希表
typedef struct dictht {
//哈希表数组
dictEntry **table;
//哈希表大小
unsigned long size;
//哈希表大小掩码,用于计算索引值。总是等于size-1
unsigned long sizemask;
//该哈希表已有节点的数量
unsigned long used;
} dictht;
2
3
4
5
6
7
8
9
10
成员介绍:
- table 属性:是一个数组,数组中的每个元素都是一个指向 dict.h/dictEntry 结构的指针,每个 dictEntry 结构保存着一个键值对
- size 属性:记录了哈希表的大小,也即是 table 数组的大小
- sizemask 属性:值总是等于 size-1,这个属性和哈希值一起决定一个键应该被放到 table 数组的哪个索引上面
- used 属性:则记录了哈希表目前已有节点(键值对)的数量
table 指向 dictEntry(哈希表节点,保存键值对),size 记录大小,sizemask 则是 size-1,用于(n-1&hash)运算放到 table 的索引。
# 5.哈希表节点
typedef struct dictEntry {
//键
void *key;
//值
union{
void *val;
uint64_tu64;
int64_ts64;
} v;
//指向下个哈希表节点,形成链表
struct dictEntry *next;
} dictEntry;
2
3
4
5
6
7
8
9
10
11
12
- key 属性保存着键值对中的键,而 val 属性则保存着键值对中的值,其中键值对的值可以是一个指针,或者是一个 uint64_tu64 整数,又或者是个 int64_ts64 整数。
- next 属性是指向另一个哈希表节点的指针,这个指针可以将多个哈希值相同的键值对连接在一次,以此来解决键冲突(collision)的问题。
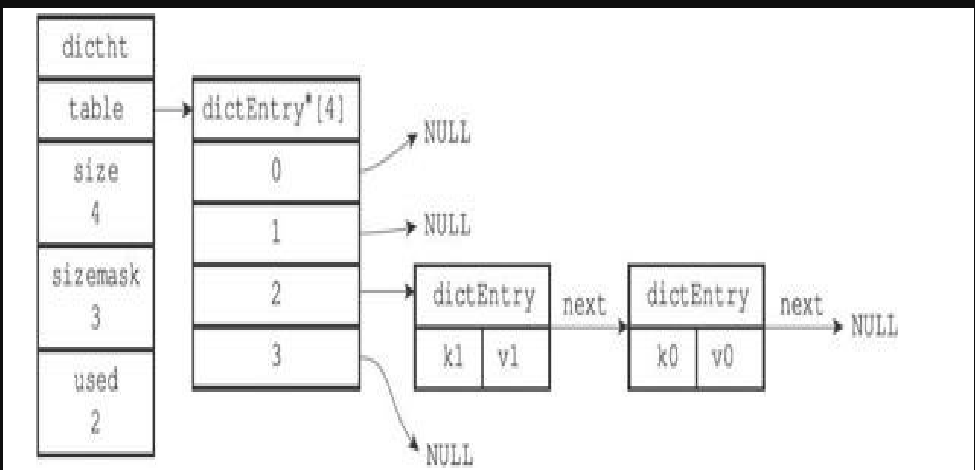
# 6.解决键冲突
- 当有两个或以上数量的键被分配到了哈希表数组的同一个索引上面时,我们称这些键发生了冲突(collision)
- Redis 的哈希表使用链地址法(separate chaining)来解决键冲突,每个哈希表节点都有 一个 next 指针,多个哈希表节点可以用 next 指针构成一个单向链表,被分配到同一个索引上 的多个节点可以用这个单向链表连接起来,这就解决了键冲突的问题
# 7.rehash 的过程?
随着操作的不断执行,哈希表保存的键值对会逐渐地增多或者减少,为了让哈希表的负载因子(loadfactor)维持在一个合理的范围之内,当哈希表保存的键值对数量太多或者太少时,程序需要对哈希表的大小进行相应的扩展或者收缩。扩展和收缩哈希表的工作可以通过执行 rehash(重新散列)操作来完成,Redis 对字典的哈希表执行 rehash 的步骤如下:
扩展操作:
- 当执行哈希表的扩展操作时,即需要将哈希表从当前大小扩展为更大的大小,Redis 会按照如下规则计算新哈希表的大小 ht[1]:
- ht[1] 的大小为第一个大于等于 ht[0].used * 2 的 2^n(2 的 n 次方幂)。
- 其中,ht[0] 是当前的原始哈希表,ht[0].used 表示当前哈希表中已使用的槽数量,而 n 是一个非负整数,使得 2^n 大于等于 ht[0].used * 2。
- 这个规则确保了新哈希表的大小足够大,能够容纳扩展后的数据,并且也有一定的冗余空间,以减少哈希冲突。
收缩操作:
- 当执行哈希表的收缩操作时,即需要将哈希表从当前大小收缩为更小的大小,Redis 会按照如下规则计算新哈希表的大小 ht[1]:
- ht[1] 的大小为第一个大于等于 ht[0].used 的 2^n(2 的 n 次方幂)。
- 同样,ht[0] 是当前的原始哈希表,ht[0].used 表示当前哈希表中已使用的槽数量,n 是一个非负整数,使得 2^n 大于等于 ht[0].used。
- 这个规则确保了新哈希表的大小足够小,能够适应收缩后的数据,避免过多的内存浪费。
rehash为渐进式:分多次渐进完成扩展收缩,因为如果键值对数量庞大,全部一次性 rehash 会停止服务,通过 rehashidx 来实现.
因为在进行渐进式 rehash 的过程中,字典会同时使用 ht[0]和 ht[1]两个哈希表,所以在渐进式 rehash 进行期间,字典的删除(delete)、查找(find)、更新(update)等操作会在两个哈希表上进行。例如,要在字典里面查找一个键的话,程序会先在 ht[0]里面进行查找,如果没找到的话,就会继续到 ht[1]里面进行查找。诸如此类。
另外,在渐进式 rehash 执行期间,新添加到字典的键值对一律会被保存到 ht[1]里面,而 ht[0]则不再进行任何添加操作,这一措施保证了 ht[0]包含的键值对数量会只减不增,并随着 rehash 操作的执行而最终变成空表。
# 8.哈希表的扩展与收缩
当以下条件中的任意一个被满足时,程序会自动开始对哈希表执行扩展操作:
- 服务器目前没有在执行 BGSAVE 命令或者 BGREWRITEAOF 命令,并且哈希表的负载因子大于等于 1。
- 服务器目前正在执行 BGSAVE 命令或者 BGREWRITEAOF 命令,并且哈希表的负载因子大于等于 5。
//负载因子的计算
load_factor=ht[0].used/ht[0].size
2
- 根据 BGSAVE 命令或 BGREWRITEAOF 命令是否正在执行,服务器执行扩展操作所需的负载因子并不相同,这是因为在执行 BGSAVE 命令或 BGREWRITEAOF 命令的过程中,Redis 需要创建当前服务器进程的子进程,而大多数操作系统都采用写时复制(copy-on-write)技 术来优化子进程的使用效率,所以在子进程存在期间,服务器会提高执行扩展操作所需的负载因子,从而尽可能地避免在子进程存在期间进行哈希表扩展操作,这可以避免不必要的内 存写入操作,最大限度地节约内存
- 另一方面,当哈希表的负载因子小于 0.1 时,程序自动开始对哈希表执行收缩操作
# 9.整数集合?
整数集合是集合键的底层实现之一。
整数集合的底层实现为数组, 这个数组以有序、无重复的方式保存集合元素, 在有需要时, 程序会根据新添加元素的类型, 改变这个数组的类型。
升级操作为整数集合带来了操作上的灵活性, 并且尽可能地节约了内存。
整数集合只支持升级操作, 不支持降级操作。
整数集合(intset):是集合键的底层实现之一,当一个集合只包含整数值元素,并且这个集合的元素数量不多时,Redis 就会使用整数集合作为集合键的底层实现。不会出现重复元素.
typedef struct intset {
// 编码方式
uint32_t encoding;
// 集合包含的元素数量
uint32_t length;
// 保存元素的数组
int8_t contents[];
} intset;
2
3
4
5
6
7
8
contents 数组是整数集合的底层实现:整数集合的每个元素都是 contents 数组的一个数组项(item),各个项在数组中按值的大小从小到大有序地排列,并且数组中不包含任何重复项。
length 属性记录了整数集合包含的元素数量,也即是 contents 数组的长度。
虽然 intset 结构将 contents 属性声明为 int8_t 类型的数组,但实际上 contents 数组并不保存任何 int8_t 类型的值,contents 数组的真正类型取决于 encoding 属性的值:
如果 encoding 属性的值为 INTSET_ENC_INT16,那么 contents 就是一个 int16_t 类型的数组,数组里的每个项都是一个 int16_t 类型的整数值(最小值为-32768,最大值为 32767)。
如果 encoding 属性的值为 INTSET_ENC_INT32,那么 contents 就是一个 int32_t 类型的数组,数组里的每个项都是一个 int32_t 类型的整数值(最小值为-2147483648,最大值为 2147483647)。
如果 encoding 属性的值为 INTSET_ENC_INT64,那么 contents 就是一个 int64_t 类型的数组,数组里的每个项都是一个 int64_t 类型的整数值(最小值为-9223372036854775808,最大值为 9223372036854775807)。
# 10.整数集合的升级?
每当我们要将一个新元素添加到整数集合里面, 并且新元素的类型比整数集合现有所有元素的类型都要长时, 整数集合需要先进行升级(upgrade), 然后才能将新元素添加到整数集合里面。
升级整数集合并添加新元素共分为三步进行:
根据新元素的类型, 扩展整数集合底层数组的空间大小, 并为新元素分配空间。
将底层数组现有的所有元素都转换成与新元素相同的类型, 并将类型转换后的元素放置到正确的位上, 而且在放置元素的过程中, 需要继续维持底层数组的有序性质不变。
将新元素添加到底层数组里面。
整数集合不支持降级操作, 一旦对数组进行了升级, 编码就会一直保持升级后的状态。
# 11.自动升级的好处
- 提升灵活性:
- 因为 C 语言是静态类型语言,为了避免类型错误,我们通常不会将两种不同类型的值放 在同一个数据结构里面
- 例如,我们一般只使用 int16_t 类型的数组来保存 int16_t 类型的值,只使用 int32_t 类型的数 组来保存 int32_t 类型的值,诸如此类
- 但是,因为整数集合可以通过自动升级底层数组来适应新元素,所以我们可以随意地将 int16_t、int32_t 或者 int64_t 类型的整数添加到集合中,而不必担心出现类型错误,这种做法非 常灵活
- 节约内存:
- 当然,要让一个数组可以同时保存 int16_t、int32_t、int64_t 三种类型的值,最简单的做法 就是直接使用 int64_t 类型的数组作为整数集合的底层实现。不过这样一来,即使添加到整数 集合里面的都是 int16_t 类型或者 int32_t 类型的值,数组都需要使用 int64_t 类型的空间去保存它 们,从而出现浪费内存的情况
- 而整数集合现在的做法既可以让集合能同时保存三种不同类型的值,又可以确保升级操 作只会在有需要的时候进行,这可以尽量节省内存
- 例如,如果我们一直只向整数集合添加 int16_t 类型的值,那么整数集合的底层实现就会 一直是 int16_t 类型的数组,只有在我们要将 int32_t 类型或者 int64_t 类型的值添加到集合时,程 序才会对数组进行升级。
# 12.跳跃表简介与应用
跳跃表(skiplist)是一种有序数据结构,它通过在每个节点中维持多个指向其他节点的指针,从而达到快速访问节点的目的。
跳跃表支持平均 O(logN)、最坏 O(N)复杂度的节点查找,还可以通过顺序性操作来批量处理节点。
在大部分情况下,跳跃表的效率可以和平衡树相媲美,并且因为跳跃表的实现比平衡树要来得更为简单,所以有不少程序都使用跳跃表来代替平衡树。
Redis 使用跳跃表作为有序集合键的底层实现之一,如果一个有序集合包含的元素数量比较多,又或者有序集合中元素的成员(member)是比较长的字符串时,Redis 就会使用跳跃表来作为有序集合键的底层实现。
跳跃表的应用
- 实现有序集合键
- 集群节点用作内部结构
# 13.跳跃表结构
跳跃表结构包含以下属性:
typedef struct zskiplist {
//head 指向跳跃表的表头节点,tail 指向跳跃表的表尾节点
struct zskiplistNode *header, *tail;
//记录跳跃表的长度,即跳跃表目前包含节点的数量,不包含头结点
unsigned long length;
//记录目前跳跃表内,层数最大的那个节点的层数
int level;
} zskiplist;
2
3
4
5
6
7
8
- header:指向跳跃表的表头节点
- tail:指向跳跃表的表尾节点
- length:记录跳跃表的长度,也即是,跳跃表目前包含节点的数量(表头节点不计算在内)
- level:记录目前跳跃表内,层数最大的那个节点的层数(表头节点的层数不计算在内)
zskiplistNode结构包含以下属性:
typedef struct zskiplistNode {
//成员对象(o1,o2,o3) 是一个指针,指向sds值
sds ele;
//分值,节点按各自所保存的分值从小到大排列 double类型
double score;
//后退指针在程序从表尾向表头遍历时使用 只有一个
struct zskiplistNode *backward;
//层数组 (每一层)
struct zskiplistLevel {
//前进指针
struct zskiplistNode *forward;
//跨度
unsigned long span;
} level[];
} zskiplistNode;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
- 层(level):节点中用 L1、L2、L3 等字样标记节点的各个层,L1 代表第一层,L2 代表 第二层,以此类推。每个层都带有两个属性:前进指针和跨度。前进指针用于访问位于表尾 方向的其他节点,而跨度则记录了前进指针所指向节点和当前节点的距离。在上面的图片 中,连线上带有数字的箭头就代表前进指针,而那个数字就是跨度。当程序从表头向表尾进 行遍历时,访问会沿着层的前进指针进行。
- 后退(backward)指针:节点中用 BW 字样标记节点的后退指针,它指向位于当前节点 的前一个节点。后退指针在程序从表尾向表头遍历时使用。
- 分值(score):各个节点中的 1.0、2.0 和 3.0 是节点所保存的分值。在跳跃表中,节点按 各自所保存的分值从小到大排列。
- 成员对象(obj):各个节点中的 o1、o2 和 o3 是节点所保存的成员对象
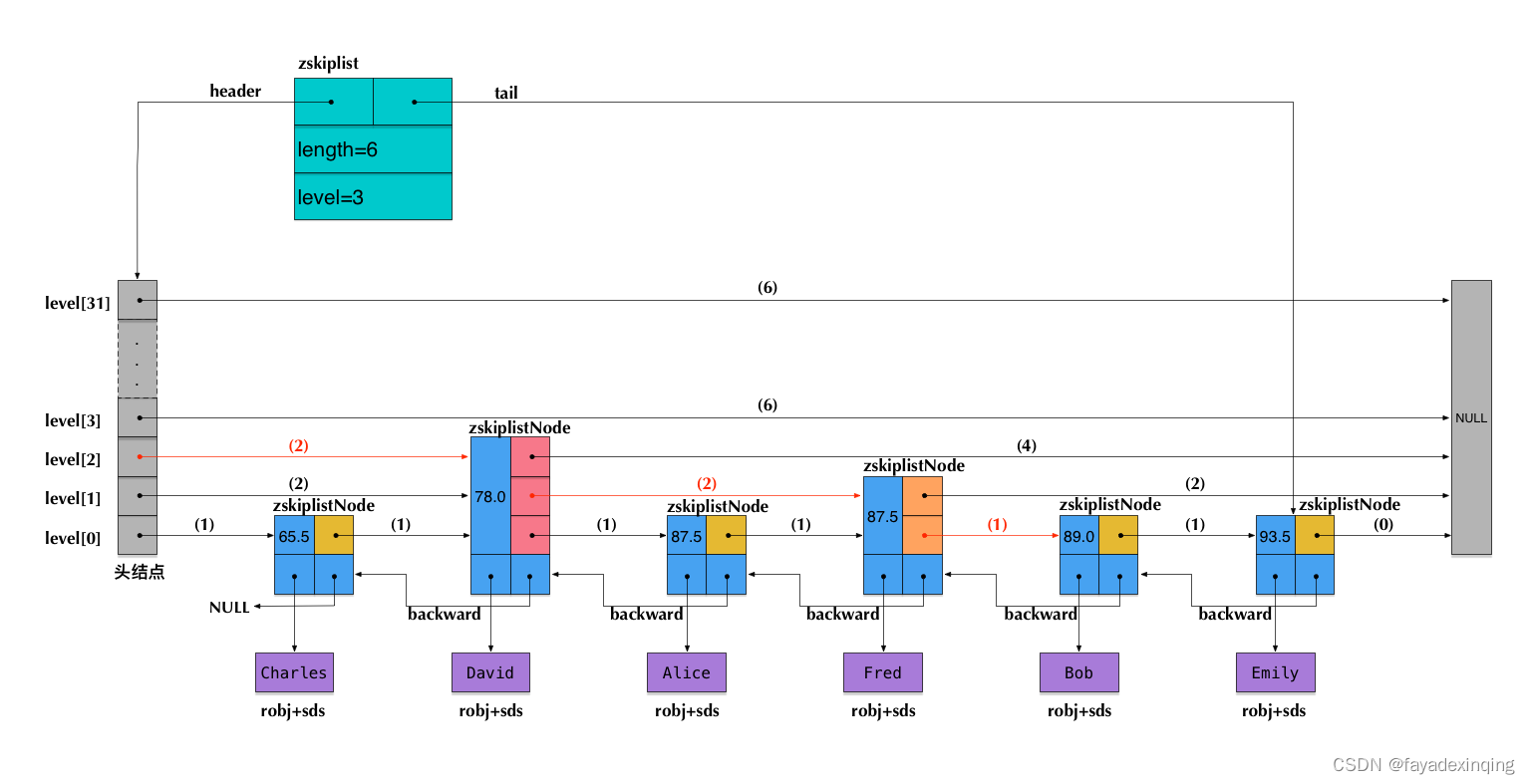
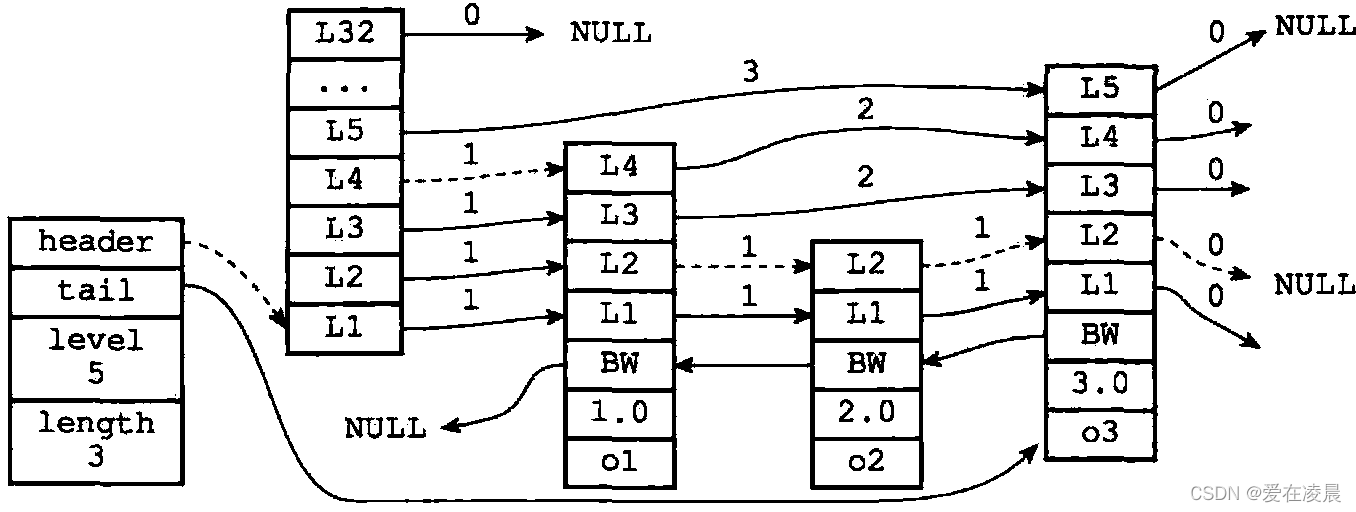
初看上去,很容易以为跨度和遍历操作有关,但实际上并不是这样,遍历操作只使用前进指针就可以完成了,跨度实际上是用来计算排位(rank)的:在查找某个节点的过程中,将沿途访问过的所有层的跨度累计起来,得到的结果就是目标节点在跳跃表中的排位.注意不要和分值 score 弄混淆了.
在同一个跳跃表中,各个节点保存的成员对象必须是唯一的,但是多个节点保存的分值却可以是相同的:分值相同的节点将按照成员对象在字典序中的大小来进行排序,成员对象较小的节点会排在前面(靠近表头的方向),而成员对象较大的节点则会排在后面(靠近表尾的方向)。
# 14.压缩列表
压缩列表(ziplist)是列表和哈希的底层实现之一。
当一个列表只包含少量列表项,并且每个列表项要么就是小整数值,要么就是长度比较短的字符串,那么 Redis 就会使用压缩列表来做列表的底层实现。
当一个哈希只包含少量键值对,比且每个键值对的键和值要么就是小整数值,要么就是长度比较短的字符串,那么 Redis 就会使用压缩列表来做哈希的底层实现。
压缩列表是 Redis 为了节约内存而开发的,是由一系列特殊编码的连续内存块组成的顺序型(sequential)数据结枃。一个压缩列表可以包含任意多个节点(entry),每个节点可以保存一个字节数组或者一个整数值,如下图。
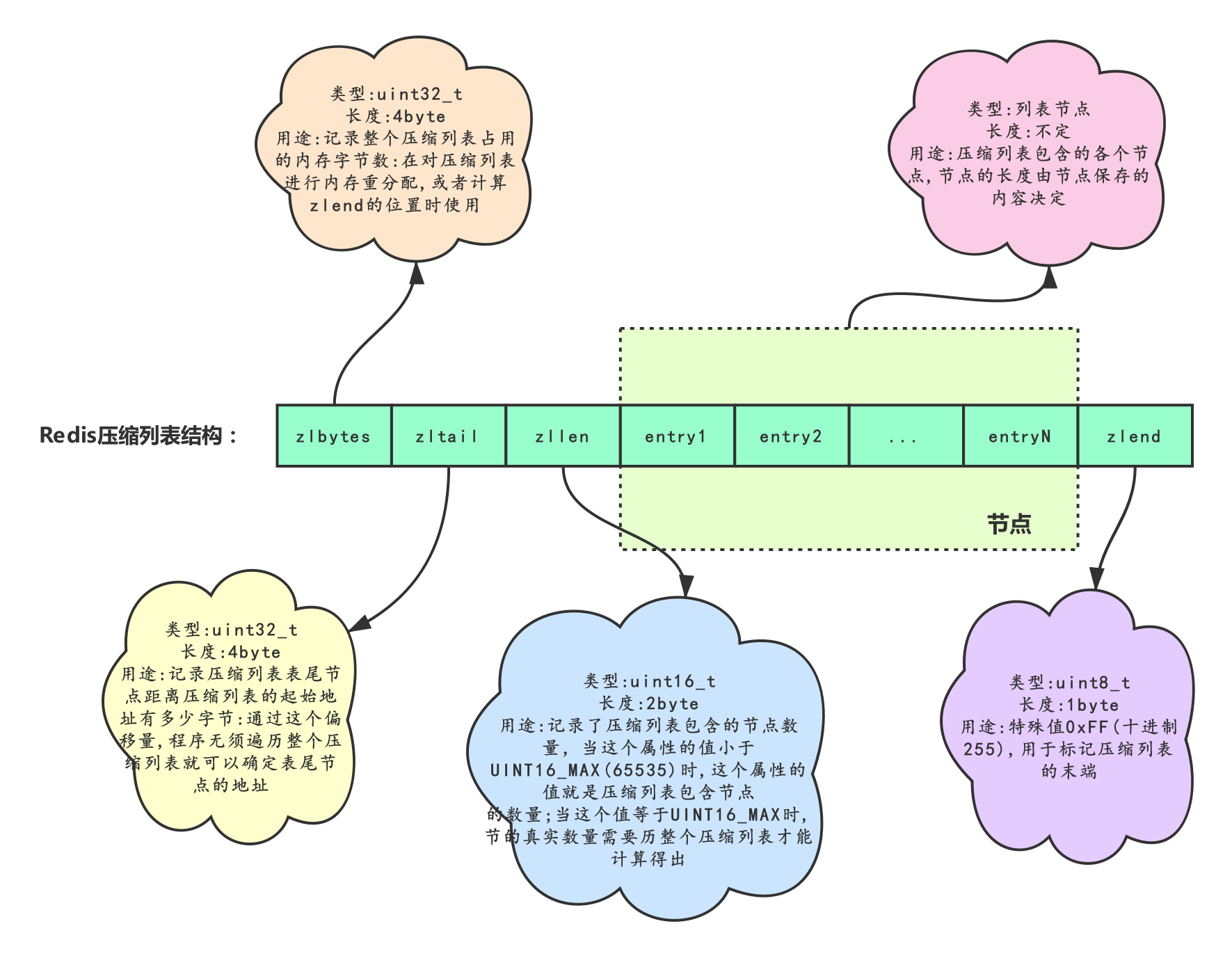
# 15.压缩列表节点构成
每个压缩列表节点可以保存一个字节数组或者一个整数值。其中,字节数组可以是以下三种长度中的一种。
长度小于等于 63(2^6-1)字节的字节数组;
长度小于等于 16383(2^14-1)字节的字节数组
长度小于等于 4294967295(2^32-1)字节的字节数组
整数值可以是以下 6 种长度中的一种
4 位长,介于 0 至 12 之间的无符号整数
1 字节长的有符号整数
3 字节长的有符号整数
int16_t 类型整数
int32_t 类型整数
int64_t 类型整数

节点的 previous_entry_length属性以字节为单位,记录了压缩列表中前一个节点的长度。 previous_entry_length 属性的长度可以是 1 字节或者 5 字节。
如果前一节点的长度小于 254 字节,那么
previous_entry_length属性的长度为 1 字节,前一节点的长度就保存在这一个字节里面。如果前一节点的长度大于等于 254 字节,那么
previous_entry_length属性的长度为 5 字节:其中属性的第一字节会被设置为 0xFE(十进制值 254),而之后的四个字节则用于保存前一节点的长度.
节点的encoding属性记录了节点的 content 属性所保存数据的类型以及长度。
- 一字节、两字节或者五字节长,值的最高位为 00、01 或者 10 的是字节数组编码这种编码表示节点的 content 属性保存着字节数组,数组的长度由编码除去最高两位之后的其他位记录。
- 一字节长,值的最高位以 11 开头的是整数编码:这种编码表示节点的 content 属性保存着整数值,整数值的类型和长度由编码除去最高两位之后的其他位记录。
节点的content属性负责保存节点的值,节点值可以是一个字节数组或者整数,值的类型和长度由节点的 encoding 属性决定。
# 16.redis 开启压缩列表
Redis 是一个开源的高性能键值存储系统,其中压缩列表(ziplist)是一种内存优化的数据结构,用于存储小型的有序集合(Sorted Set)或哈希(Hash)等数据。压缩列表可以减少内存的使用,并提高性能,但在某些情况下可能会牺牲一些操作的性能。
在 Redis 中,默认情况下,Redis 会自动决定是否使用压缩列表来存储数据。然而,你也可以通过配置参数来开启或关闭压缩列表的使用。
要在 Redis 中开启压缩列表,你可以在 Redis 配置文件(通常是 redis.conf)中进行相应的设置。找到以下配置项,确保它的值为 yes:
hash-max-ziplist-entries 512
hash-max-ziplist-value 64
list-max-ziplist-entries 512
list-max-ziplist-value 64
set-max-intset-entries 512
zset-max-ziplist-entries 128
zset-max-ziplist-value 64
2
3
4
5
6
7
上述配置项分别控制了不同数据类型的压缩列表的使用。这里的值是默认值,你可以根据需要进行调整。一般来说,压缩列表对于存储小型的数据集合或哈希表非常有效,但对于大型数据集可能会导致一些性能损失。
修改完配置文件后,记得重启 Redis 服务使配置生效:
sudo service redis-server restart
请注意,Redis 的版本可能会有变化,因此具体配置项和默认值可能有所不同。在进行配置更改之前,建议查阅官方文档以获取最新的信息。
# 17.连锁更新
Redis 将这种在特殊情况下产生的连续多次空间扩展操作称之为连锁更新(cascade update)
要注意的是,尽管连锁更新的复杂度较高,但它真正造成性能问题的几率是很低的:
- 首先,压缩列表里要恰好有多个连续的长度介于
250字节至253字节之间的节点,连锁更新才有可能被引发,在实际中,这种情况并不多见; - 其次,即使出现连锁更新,但只要被更新的节点数量不多,就不会对性能造成任何影响:比如说,对三五个节点进行连锁更新是绝对不会影响性能的;
因为以上原因,ziplistPush 等命令的平均复杂度仅为 O(N),在实际中,我们可以放心地使用这些函数,而不必担心连锁更新会影响压缩列表的性能。
因为 ziplistPush、ziplistlnsert、ziplistDelete 和 ziplistDeleteRange 四个函数都有可能会引发连锁更新,所以它们的最坏复杂度都是 O(N^2^) 。
虽说如此,Redis 针对压缩列表在设计上的不足,在后来的版本中,新增设计了两种数据结构:quicklist(Redis 3.2 引入) 和 listpack(Redis 5.0 引入)。这两种数据结构的设计目标,就是尽可能地保持压缩列表节省内存的优势,同时解决压缩列表的「连锁更新」的问题。
typedef struct quicklistNode {
struct quicklistNode *prev;
struct quicklistNode *next;
unsigned char *zl;
unsigned int sz; /* ziplist size in bytes */
unsigned int count : 16; /* count of items in ziplist */
unsigned int encoding : 2; /* RAW==1 or LZF==2 */
unsigned int container : 2; /* NONE==1 or ZIPLIST==2 */
unsigned int recompress : 1; /* was this node previous compressed? */
unsigned int attempted_compress : 1; /* node can't compress; too small */
unsigned int extra : 10; /* more bits to steal for future usage */
} quicklistNode;
typedef struct quicklist {
quicklistNode *head;
quicklistNode *tail;
unsigned long count; /* total count of all entries in all ziplists */
unsigned long len; /* number of quicklistNodes */
int fill : 16; /* fill factor for individual nodes */
unsigned int compress : 16; /* depth of end nodes not to compress;0=off */
} quicklist;
typedef struct quicklistIter {
const quicklist *quicklist;
quicklistNode *current;
unsigned char *zi;
long offset; /* offset in current ziplist */
int direction;
} quicklistIter;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
可以看出:
quicklistNode 就是一个 ziplist,同时加入 prev、next 前后指针将其串联到 quicklist 中
- 每个 quicklist 中维护首尾节点
- 本质上 quicklist 和 list 结构一样,只不过每个节点是一个 ziplist
- 另外 quicklist 支持节点压缩,当 quicklist 中的节点数量超过 quicklist::compress 规定的长度时,就会将 quicklist 中的中间节点压缩,以此来节省空间;但是需要读取节点内容时,会增加一次解压的代价。
- quicklist::fill 用来控制扇出,当插入的 entry 总大小超过这个阈值时,需要新建 quicknode,这样一定程度上可以避免连锁更新
quicklist 虽然通过控制 quicklistNode 结构里的压缩列表的大小或者元素个数,来减少连锁更新带来的性能影响,但是并没有完全解决连锁更新的问题。
因为 quicklistNode 还是用了压缩列表来保存元素,压缩列表连锁更新的问题,来源于它的结构设计,所以要想彻底解决这个问题,需要设计一个新的数据结构。
于是,Redis 在 5.0 新设计一个数据结构叫 listpack,目的是替代压缩列表,它最大特点是 listpack 中每个节点不再包含前一个节点的长度了,压缩列表每个节点正因为需要保存前一个节点的长度字段,就会有连锁更新的隐患。
listpack 没有压缩列表中记录前一个节点长度的字段了,listpack 只记录当前节点的长度,当我们向 listpack 加入一个新元素的时候,不会影响其他节点的长度字段的变化,从而避免了压缩列表的连锁更新问题
# 三.Redis 对象
# 1.redis 对象?
Redis 用到的所有主要数据结构,比如简单动态字符串(SDS)、双端链表、字典、跳跃表,压缩列表、整数集合等等。Redis 并没有直接使用这些数据结构来实现键值对数据库,而是基于这些数据结构创建了一个对象系统,这个系统包含字符串对象、列表对象、哈希对象、集合对象和有序集合对象这五种类型的对象,每种对象都用到了至少一种我们前面所介绍的数据结构。
通过这五种不同类型的对象,Redis 可以在执行命令之前,根据对象的类型来判断一个对象是否可以执行给定的命令。使用对象的另一个好处是,我们可以针对不同的使用场景,为对象设置多种不同的数据结构实现,从而优化对象在不同场景下的使用效率。
除此之外,Redis 的对象系统还实现了基于引用计数技术的内存回收机制,当程序不再使用某个对象的时候,这个对象所占用的内存就会被自动释放;另外,Redis 还通过引用计数技术实现了对象共享机制,这一机制可以在适当的条件下,通过让多个数据库键共享同一个对象来节约内存。
最后,Redis 的对象带有访问时间记录信息,该信息可以用于计算数据库键的空转时长,在服务器启用了 MaxMemory 功能的情况下,空转时长较大的那些键可能会优先被服务器删除。
其中常见的键值类型包括 String、List、Hash、Set 和 Sorted Set 这五种,同时还支持 BitMap、HyperLogLog、Geo 和 Stream 这四种扩展类型
# 2.redis 对象结构?
typedef struct redisObject {
// 类型 0-string 1-list 2-set 3-zset 4-hash,在宏中定义。
unsigned type:4; // :4 是位域(位段),表示只占用4bit,2^4
// 对象编码。某些类型的对象(如字符串和哈希)可以通过多种方式在内部表示。ENCODING表明表示方式。
unsigned encoding:4;
//LRU_BITS=24,共24位,高16位存储一个分钟数级别的时间戳,低8位存储访问计数(lfu : 最近访问次数)
unsigned lru:LRU_BITS;
// 引用次数
int refcount;
// 指针指向具体数据,void * 类型,从而可以执行那六大数据结构
void *ptr;
} robj;
2
3
4
5
6
7
8
9
10
11
12
- type:type 字段表示对象的类型,占 4 个比特;当我们执行 type 命令时,便是通过读取 RedisObject 的 type 字段获得对象的类型;
- REDIS_STRING(字符串)
- REDIS_LIST (列表)
- REDIS_HASH(哈希)
- REDIS_SET(集合)
- REDIS_ZSET(有序集合)
- encoding表示对象的内部编码,占 4 个比特。对于 redis 支持的每种类型都至少有两种编码,对于字符串有 int、embstr、raw 三种 encoding 属性,redis 可以根据不同的使用场景来对对象使用不同的编码,大大提高的 redis 的灵活性和效率。
- ptr:指针指向对象的底层实现的数据结构.
以列表对象为例,有压缩列表和双端链表两种编码方式;如果列表中的元素较少, Redis 倾向于使用压缩列表进行存储,因为压缩列表占用内存更少,而且比双端链表可以更快载入;当列表对象元素较多时,压缩列表就会转化为更适合存储大量元素的双端链表。3.2 版本以后都采用 quicklist, 是压缩链表和双端链表的结合.
type
/* The actual Redis Object */
#define OBJ_STRING 0 /* String object. */
#define OBJ_LIST 1 /* List object. */
#define OBJ_SET 2 /* Set object. */
#define OBJ_ZSET 3 /* Sorted set object. */
#define OBJ_HASH 4 /* Hash object. */
2
3
4
5
6
encoding
#define OBJ_ENCODING_RAW 0 // 编码为字符串 c语言类型
#define OBJ_ENCODING_INT 1 // 编码为整数
#define OBJ_ENCODING_HT 2 // 编码为哈希表
#define OBJ_ENCODING_ZIPMAP 3 // 编码为 zipmap
#define OBJ_ENCODING_LINKEDLIST 4 /* No longer used: old list encoding. */
#define OBJ_ENCODING_ZIPLIST 5 // 编码为压缩列表
#define OBJ_ENCODING_INTSET 6 // 编码为整数集合
#define OBJ_ENCODING_SKIPLIST 7 // 编码为跳跃表
#define OBJ_ENCODING_EMBSTR 8 // 编码为SDS字符串
#define OBJ_ENCODING_QUICKLIST 9 /* 快速列表 压缩列表+链表 */
#define OBJ_ENCODING_STREAM 10 /* Encoded as a radix tree of listpacks */
2
3
4
5
6
7
8
9
10
11
# 3.Type 种类说明
Redis 是一款内存存储的数据结构服务器,支持多种数据类型,每种数据类型都有不同的操作和特性。以下是 Redis 支持的主要数据类型:
字符串(String): 最基本的数据类型,可以存储文本、整数或二进制数据。字符串类型的值最大可以达到 512MB。
哈希(Hash): 类似于关联数组或字典,存储了字段和值之间的映射关系。用于存储对象的属性和值。
列表(List): 有序的字符串元素集合,允许在列表的头部或尾部进行插入、删除和索引操作。可用于实现队列、栈等数据结构。
集合(Set): 无序的唯一元素集合,支持元素的添加、删除和判断元素是否存在等操作。可用于处理无序不重复的数据。
有序集合(Sorted Set): 类似于集合,每个元素关联一个分数(score),用于排序集合中的元素。支持根据分数范围或成员的排名来获取数据。
位图(Bitmap): 一种特殊的字符串类型,每个比特位都可以被设置为 0 或 1,支持位操作和位图计数等。
HyperLogLog: 一种用于估计集合基数(不重复元素数量)的算法,占用固定的空间,适用于大规模数据的基数统计。
地理空间(Geospatial): 存储地理位置信息的数据类型,可以用于存储经度和纬度,以及进行距离计算等操作。
流(Stream): 类似于日志的数据结构,支持按时间顺序存储消息,并且可以消费已发布的消息。
每种数据类型都有一组相应的命令来进行操作,Redis 通过这些数据类型提供了丰富的功能,使其成为一个多用途的内存数据存储系统。不同的数据类型适用于不同的应用场景,用户可以根据需要选择合适的数据类型来存储和操作数据。
常见的数据结构以及与之对应的键值类型如下
- 字符串 (sds.h/c):
String - 双向列表(adlist.h/c):
List - 压缩列表(ziplist.h/c):
List、Hash、Sorted Set - 压缩 Map(zipmap.h/c):
Hash - quickList(quicklist.h/c):
List、Hash、Sorted Set,quickList 的实现原理有点像stl中的deque - 跳表(t_zset.c):
Sorted Set - 哈希表(dict.h/c):
Hash - 位图(bitops.c): BitMap
- GeoHash(geohash.h/c、geo.h/c、geohelper.h/c):
Geo - HyperLogLog(hyperloglog.c):
HyperLogLog - 流数据(rax.h/c):
Stream
BitMap 和布隆过滤器比较
- 布隆过滤器不能确定一个值是否真的存在,而 bitmap 可以
- 布隆过滤器空间利用率比 bitmap 高,一个位可以代表多个值
- 布隆过滤器可以输入字符串,而 bitmap 必须转换为数值才可以
HyperLogLog
统计注册 IP 数
统计每日访问 IP 数
统计页面实时 UV 数
统计在线用户数
统计用户每天搜索不同词条的个数
# 4.redis 对象底层数据结构
redisObject 使用到的底层数据结构 encoding:

encoding 属性
- 记录了对象所使用的编码,也即是说这个对象使用了什么数据结构作为对象的底层实现,这个属性的值可以是下表列出的常量的其中一个
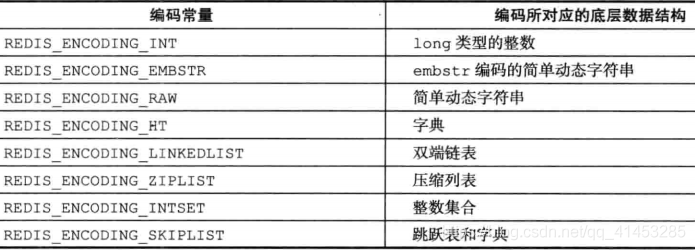
- 每种类型的对象都至少使用了两种不同的编码,下表列出了每种类型的对象可以使用的编码
OBJECT ENCODING 命令
- 可以查看一个数据库键的值对象的编码。下表列出了不同编码的对象所对应的 OBJECT ENCODING 命令输出

# 5.字符串对象
字符串对象的编码可以是 int、raw 或者 embstr。
- 如果一个字符串对象保存的是整数值,并且这个整数值可以用 long 类型来表示,那么字符串对象会将整数值保存在字符串对象结构的 ptr 属性里面(将 void*转换成 long),并将字符串对象的编码设置为
int。 - 如果字符串对象保存的是一个字符串值,并且且这个字符串值的长度大于 32 字节,那么字符串对象将使用一个简单动态字符串(SDS)来保存这个字符串值,并将对象的编码设置为
raw。 - 如果字符串对象保存的是一个字符串值, 并且这个字符串值的长度小于等于 32 字节,那么字符串对象将使用
embstr编码的方式来保存这个字符串值。
embstr 编码的字符串对象在执行命令时,产生的效果和 raw 编码的字符串对象执行命令时产生的效果是相同的,但使用 embstr 编码的字符串对象来保存短字符串值有以下好处:
embstr编码是专门用于保存短字符串的一种优化编码方式,这种编码和raw编码一样,都使用redisObiect结构和sdshdr结构来表示字符串对象,但raw编码会调用两次内存分配函数来分别创建 redisObiect 结构和 sdshdr 结构,而embstr 编码则通过调用一次内存分配函数来分配一块连续的空间,空间中依次包含 redisObiect 和 sdshdr 两个结构;embstr编码将创建字符串对象所需的内存分配次数从 raw 编码的两次降低为一次。- 释放
embstr编码的字符串对象只需要调用一次内存释放函数,而释放 raw 编码的字符串对象需要调用两次内存释放函数。 - 因为
embstr编码的字符串对象的所有数据都保存在一块连续的内存里面,所以这种编码的字符串对象比起 raw 编码的字符串对象能够更好地利用缓存带来的优势。
# 6.编码转换
int 转 raw,本来是 int 类型,使用了 append 方法,会转换为 raw 类型.
embstr 没有修改的 api,默认是只读的.当修改时,先转为 raw 再进行修改.
# 7.列表对象
列表对象的编码可以是 ziplist 或者 linkedlist。
ziplist 编码的列表对象使用压缩列表作为底层实现,每个压缩列表节点(entry)保存了一个列表元素。
linkedlist 编码的列表对象使用双端链表作为底层实现,每个双端链表节点(node)都保存了一个字符串对象,而每个字符串对象都保存了一个列表元素。
编码转换
当列表对象可以同时满足以下两个条件时,列表对象使用 ziplist 编码:
列表对象保存的所有字符串元素的长度都小于64 字节;列表对象保存的元素数量小于 512 个;不能同时满足这两个条件的列表对象需要使用 linkedlist 编码;
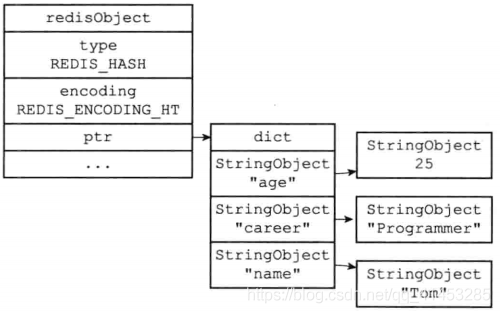
# 8.哈希对象
哈希对象的编码可以是 ziplist 或者 hashtable
ziplist 编码的哈希对象使用压缩列表作为底层实现,每当有新的键值对要加入到哈希对象时,程序会先将保存了键的压缩列表节点推入到压缩列表表尾,然后再将保存了值的压缩列表节点推入到压缩列表表尾,因此:
保存了同一键值对的两个节点总是紧挨在一起,保存键的节点在前,保存值的节点在后;
先添加到哈希对象中的键值对会被放在压缩列表的表头方向,而后来添加到哈希对象中的键值对会被放在压缩列表的表尾方向。

hashtable 编码的哈希对象使用字典作为底层实现,哈希对象中的每个键值对都使用一个字典键值对来保存
字典的每个键都是一个字符串对象,对象中保存了键值对的键;
字典的每个值都是一个字符串对象,对象中保存了键值对的值。
编码转换
当哈希对象可以同时满足以下两个条件时,哈希对象使用 ziplist 编码:
哈希对象保存的所有键值对的键和值的字符串长度都小于 64 字节;哈希对象保存的键值对时数量小于 512 个;不能满足这两个条件的哈希对象需要使用 hashta ble 编码。
# 9.集合对象
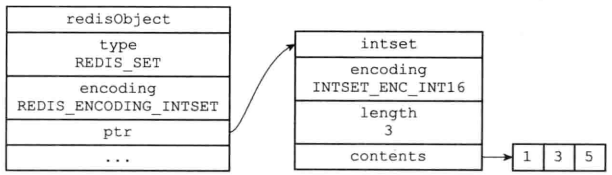
集合对象的编码可以是 intset 或者 hashtable。
- intset 编码的集合对象使用整数集合作为底层实现,集合对象包含的所有元素都被保存在整数集合里面。
hashtable编码的集合对象使用字典作为底层实现,字典的每个键都是一个字符串对象,每个字符串对象包含了一个集合元素,而字典的值则全部被设置为 NULL。
127.0.0.1:6379> sadd numbers 1 3 5
(integer) 3
127.0.0.1:6379> sadd fruits apple cherry
(integer) 2
2
3
4
整数集合方式编码
hashtable 字典方式编码

编码转换
当集合对象可以同时满足以下两个条件时,对象使用 intset 编码:
集合对象保存的所有元素都是整数值;集合对象保存的元素数量不超过 512 个。
# 10.有序集合对象
有序集合的编码可以是 ziplist 或者 skiplist。
ziplist
ziplist 编码的压缩列表对象使用压缩列表作为底层实现,每个集合元素使用两个紧挨在一起的压缩列表节点来保存,第一个节点保存元素的成员(member),而第二个元素则保存元素的分值(score).
压缩列表内的集合元素按分值从小到大进行排序,分值较小的元素被放置在靠近表头的方向,而分值较大的元素则被放置在靠近表尾的方向。
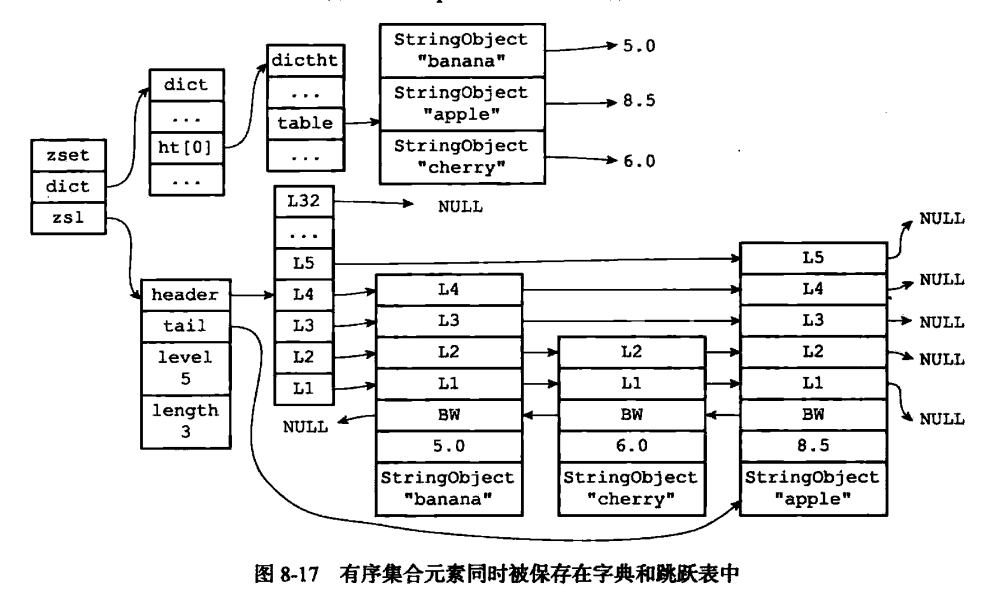
skiplist
skiplist编码的有序集合对象使用zset结构作为底层实现,一个zset结构同时包含一个字典和一个跳跃表;- zset 结构中的 zsl 跳跃表按分值从小到大保存了所有集合元素,每个跳跃表节点都保存了一个集合元素:跳跃表节点的 object 属性保存了元素的成员,而
跳跃表节点的 score 属性则保存了元素的分值。通过这个跳跃表,程序可以对有序集合进行范围型操作,比如 ZRANK、ZRANGE 等命令就是基于跳跃表 API 来实现的。 - 除此之外,zset 结构中的
dict字典为有序集合创建了一个从成员到分值的映射,字典中的每个键值对都保存了一个集合元素:字典的键保存了元素的成员,而字典的值则保存了元素的分值。通过这个字典,程序可以用 O(1)复杂度查找给定成员的分值,ZSCORE 命令就是根据这一特性实现的,而很多其他有序集合命令都在实现的内部用到了这一特性。
typedef struct zset {
dict *dict; //缓存
zskiplist *zsl; //排序结构
} zset;
2
3
4
有序集合每个元素的成员都是一个字符串对象,而每个元素的分值都是一个 double 类型的浮点数。值得一提是,虽然 zset 结构同时使用跳跃表和字典来保存有序集合元素,但这两种数据结构都会通过指针来共享相同元素的成员和分值,所以同时使用跳跃表和字典来保存集合元素不会产生任何重复成员或者分值,也不会因此而浪费额外的内存。
编码转换
当有序集合对象可以以同时满足以下两个条件中时,对象使用 ziplist 编码:
有序集合保存的所有元素成员的长度都小于64字节;有序集合保存的元素数量小于128个;
# 11.为什么需要两种数据结构?
为什么有序集合需要同时使用跳跃表和字典来实现
- 在理论上,有序集合可以单独使用字典或者跳跃表的其中一种数据结构来实现,但无论单独使用字典还是跳跃表,在
性能上对比起同时使用字典和跳跃表都会有所降低。 - 举个例子,如果我们只使用
字典来实现有序集合,那么虽然以 O(1)复杂度查找成员的分值这一特性会被保留,但是,因为字典以无序的方式来保存集合元素,所以每次在执行范围型操作--比如 ZRANK、ZRANGE 等命令时,程序都需要对字典保存的所有元素进行排序,完成这种排序需要至少O(NlogN)时间复杂度。以及额外的O(N)内存空间(因为要创建一个数组来保存排序后的元素)。 - 另一方面,如果我们只使用
跳跃表来实现有序集合,那么跳跃表执行范围型操作的所有优点都会被保留,但因为没有了字典,所以根据成员查找分值这一操作的复杂度将从 O(1)上升为 O(logN)。因为以上原因,为了让有序集合的查找和范围型操作都尽可能快地执行,Redis 选择了同时使用字典和跳跃表两种数据结构来实现有有序集合。
# 12.类型检查
类型检查通过 type 命令来实现的,Redis 中用于操作键的命令基本上可以分为两种类型。
其中一种命令可以对任何类型的键执行:
- DEL
- EXPIRE
- RENAME
- TYPE
- OBJECT
另一种命令只能对特定类型的键执行:
SET、GET、APPEND、STRLEN 等命令只能对字符串键执行;
HDEL、HSET、HGET、HLEN 等命令只能对哈希键执行;
RPUSH、LPOP、LINSERT、LLEN 等命令只能对列表键执行;
SADD、SPOP、SINTER、SCARD 等命令只能对集合键执行;
ZADD、ZCARD、ZRANK、ZSCORE 等命令只能对有序集合键执行;
# 13.内存回收
通过引用计数法来进行内存回收,底层是通过 redisObject 结构的 refcount 属性记录每个对象的引用计数信息;对象的引用计数信息会随着对象的使用状态而不断变化。
在创建一个新对象时,引用计数的值会被初始化为 1;
当对象被一个新程序使用时,它的引用计数值会被增一;
当对象不再被一个程序使用时,它的引用计数值会被减一;
当对象的引用计数值至变为 0 时,对象所占用的内存会被释放。
typedef struct redisObject {
// ...
//引用计数
int refcount;
// ...
} robj;
2
3
4
5
6
# 14.对象共享
**概念:**除了用于实现引用计数内存回收机制之外,对象的引用计数属性(refcount 属性)还带有对象共享的作用
值对象共享 整数型对象,Redis只对字符串对象进行共享,并且只对包含整数值的字符串对象进行共享
在 Redis 中,让多个键共享同一个值对象需要执行以下两个步骤:
- 将数据库键的值指针指向一个现有的值对象;
- 将被共享的值对象的引用计数增一。
REDIS_SHARED_INTEGERS
只有在共享对象和目标对象完全相同的情况下,程序才会将共享对象用作键的值对象,而一个共享对象保存的值越复杂,验证共享对象和目标对象是否相同所需的复杂度就会越高,消耗的 CPU 时间也会越多:
如果共享对象是保存整数值的字符串对象,那么验证操作的复杂度为 O(1);
如果共享对象是保存字符串值的字符串对象,那么验证操作的复杂度为 O(N);
如果共享对象是包含了多个值(或者对象的)对象,比如列表对象或者哈希对象,那么验证操作的复杂度将会是 O(N2)
因此,尽管共享更复杂的对象可以节约更多的内存,但受到 CPU 时间的限制,Redis 只对包含整数值的字符串对象进行共享。
# 15.对象的空转时长
typedef struct redisObject {
// ...
unsigned lru:22;
// ...
} robj;
2
3
4
5
redisObject 结构包含了属性为 Iru 属性,该属性记录了对象最后一次被命令程序访问的时间:
OBJECT IDLETIME 命令可以打印出给定键的空转时长,这一空转时长就是通过将当前时间减去键的值对象的 Iru 时间计算得出的:
127.0.0.1:6379> OBJECT IDLETIME msg
(integer) 295277
127.0.0.1:6379> OBJECT IDLETIME price
(integer) 10747
2
3
4
除了可以被 OBJECT IDLETIME 命令打印出来之外,键的空转时长还有另外一项作用:如果服务器打开了 max_memory 选项,并且服务器用于回收内存的算法为 volatile-Iru 或者 allkeys-Iru,那么当服务器占用的内存数超过了 maxmemory 选项所设置的上限值时,空转时长较高的那部分键会优先被服务器释放,从而回收内存。
# 16.redis 对象总结
Redis 数据库中的每个键值对的键和值都是一个对象。
Redis 共有字符串、列表、哈希、集合、有序集合五种类型的对象,每种类型的对象至少都有两种或以上的编码方式,不同的编码可以在不同的使用场景上优化对象的使用效率。
服务器在执行某些命令之前,会先检查给定键的类型能否执行指定的命令,而检查一个键的类型就是检查键的值对象的类型。
Redis 的对象系统带有
引用计数实现的内存回收机制,当一个对象不再被使用时,该对象所占用的内存就会被自动释放。Redis 会共享值为 0 到
9999的字符串对象。对象会记录自己的最后一次被访问的时间,这个时间可以用于计算对象的
空转时间。
# 四.Redis 持久化
# 1.RDB 持久化
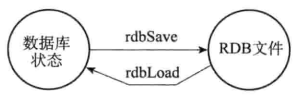
RDB 持久化功能所生成的 RDB 文件是一个经过压缩的二进制文件,通过该文件可以还原生成 RDB 文件时的数据库状态。
有两个 Redis 命令可以用于生成 RDB文件,一个是 SAVE,另一个是 BGSAVE。
SAVE命令会阻塞 Redis 服务器进程,直到 RDB 文件创建完毕为止,在服务器进程阻塞期间,服务器不能处理任何命令请求;- 和 SAVE 命令直接阻塞服务器进程的做法不同,
BGSAVE命令会派生出一个子进程,然后由子进程负责创建 RDB 文件,服务器进程(父进程)继续处理命令请求;
SAVE 命令执行时服务器的状态
- 当 SAVE 命令执行时,Redis 服务器会被阻塞,所以当 SAVE 命令正在执行时,客户端发送的所有命令请求都会被拒绝。
- 只有在服务器执行完 SAVE 命令、重新开始接受命令请求之后,客户端发送的命令才会被处理。
RDB 文件保存和载入
# 2.BGSAVE 命令
因为 BGSAVE 命令的保存工作是由子进程执行的,所以在子进程创建 RDB 文件的过程中,Redis 服务器仍然可以继续处理客户端的命令请求,但是,在 BGSAVE 命令执行期间,服务器处理 SAVE、BGSAVE、BGREWRITEAOF 三个命令的方式会和平时有所不同。
- 首先,在
BGSAVE命令执行期间,客户端发送的SAVE命令会被服务器拒绝,服务器禁止SAVE命令和 BGSAVE 命令同时执行是为了避免父进程(服务器进程)和子进程同时执行两个 rdbSave 调用,防止产生竞争条件。 - 其次,在
BGSAVE命令执行期间,客户端发送的BGSAVE命令会被服务器拒绝,因为同时执行两个BGSAVE命令也会产生竞争条件。 - 最后,
BGREWRITEAOF和BGSAVE两个命令不能同时执行:- 如果
BGSAVE命令正在执行,那么客户端发送的BGREWRITEAOF命令会被延迟到BGSAVE命令执行完毕之后执行。 - 如果
BGREWRITEAOF命令正在执行,那么客户端发送的BGSAVE命令会被服务器拒绝。
- 如果
因为 BGREWRITEAOF 和 BGSAVE 两个命令的实际工作都由子进程执行,所以这两个命令在操作方面并没有什么冲突的地方,不能同时执行它们只是一个性能方面的考虑--并发出两个子进程,并且这两个子进程都同时执行大量的磁盘写入操作,
# 3.BGSAVE 默认配置
那么只要满足以下三个条件中的任意一个,BGSAVE 命令就会被执行:
服务器在 900 秒之内,对数据库进行了至少 1 次修改。
服务器在 300 秒之内,对数据库进行了至少 10 次修改。
服务器在 60 秒之内,对数据库进行了至少 10000 次修改。
对应的配置文件信息在 saveparams 数组中
#900秒内如果超过1个key被修改,则发起快照保存
save 900 1
#300秒内容如超过10个key被修改,则发起快照保存
save 300 10
#60 秒之内,对数据库进行了至少 10000 次修改
save 60 10000
2
3
4
5
6
7
8
struct redisServer {
// ...
struct saveparam *saveparams;//记录了save保存条件的数组
// ...
};
struct saveparam {
time_t seconds;//秒数
int changes;//修改数
};
2
3
4
5
6
7
8
9
10
# 4.dirty 和 lastsave
dirty 计数器和 lastsave 属性:
除了 saveparams 数组之外,服务器状态还维持着一个 dirty 计数器,以及一个 lastsave 属性:
dirty计数器记录距离上一次成功执行SAVE命令或者BGSAVE命令之后,服务器对数据库状态(服务器中的所有数据库)进行了多少次修改(包括写入、删除、更新等操作)。lastsave属性是一个 UNIX 时间戳,记录了服务器上一次成功执行SAVE命令或者BGSAVE命令的时间。
struct redisServer {
// ...
long long dirty;//修改计数器
time_t lastsave;//上一次执行保存的时间
// ...
};
2
3
4
5
6
# 5.检查函数
Redis 的服务器周期性操作函数 serverCron 默认每隔 100 毫秒就会执行一次,该函数用于对正在运行的服务器进行维护,它的其中一项工作就是检查 save 选项所设置的保存条件是否已经满足,如果满足的话,就执行 BGSAVE 命令。
def serverCron():
# ...
# 遍历所有保存条件
for saveparam in server.saveparams:
# 计算距离上次执行保存操作有多少秒
save_interval = unixtime_now()-server.lastsave
# 如果数据库状态的修改次数超过条件所设置的次数
# 并且距离上次保存的时间超过条件所设置的时间
# 那么执行保存操作
if server.dirty >= saveparam.changes and \
save_interval > saveparam.seconds:
BGSAVE()
# ...
2
3
4
5
6
7
8
9
10
11
12
13
14
# 6.RDB 文件结构
RDB 文件为二进制格式保存,下面我们为了演示效果,采用字符串的形式演示

REDIS(常量):RDB 文件的最开头是 REDIS 部分,这个部分的长度为 5 字节,保存着“REDIS”五个字符。通过这五个字符,程序可以在载入文件时,快速检查所载入的文件是否 RDB 文件db_version(变量):长度为 4 字节,它的值是一个字符串表示的整数,这个整数记录了 RDB 文件的版本号,比如"0006"就代表 RDB 文件的版本为第六版databases(变量):databases 部分包含着零个或任意多个数据库,以及各个数据库中的键值对数据- 如果服务器的数据库状态为空(所有数据库都是空的),那么这个部分也为空,长度为 0 字节
- 如果服务器的数据库状态为非空(有至少一个数据库非空),那么这个部分也为非空,根据数据库所保存键值对的数量、类型和内容不同,这个部分的长度也会有所不同
EOF(常量):EOF 常量的长度为 1 字节,这个常量标志着 RDB 文件正文内容的结束,当读入程序遇到这个值的时候,它知道所有数据库的所有键值对都已经载入完毕了check_sum(变量):check_sum 是一个 8 字节长的无符号整数,保存着一个校验和,这个校验和是程序通过对REDIS、db_version、databases、EOF四个部分的内容进行计算得出的。服务器在载入 RDB 文件时,会将载入数据所计算出的校验和与check_sum所记录的校验和进行对比,以此来检查 RDB 文件是否有出错或者损坏的情况出现
# 7.database 结构
一个 RDB 文件的 databases 部分可以保存任意多个非空数据库。例如,如果服务器的 0 号数据库和 3 号数据库非空,那么服务器将创建一个如下图所示的 RDB 文件

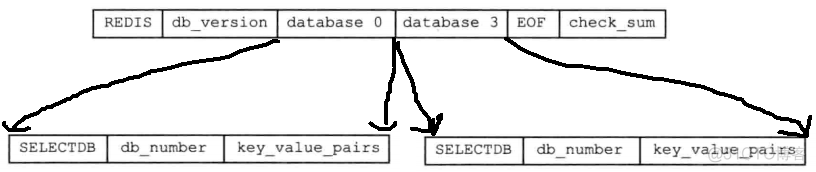
每个非空数据库在 RDB 文件中都可以保存为 SELECTDB、db_number、key_value_pairs 三个部分:
SELECTDB常量:长度为 1 字节,当读入程序遇到这个值的时候,它知道接下来要读入的将是一个数据库号码db_number:保存着一个数据库号码,根据号码的大小不同,这个部分的长度可以是 1 字节、2 字节或者 5 字节。当程序读入 db_number 部分之后,服务器会调用 SELECT 命令,根据读入的数据库号码进行数据库切换,使得之后读入的键值对可以载入到正确的数据库中key_value_pairs部分:保存了数据库中的所有键值对数据,如果键值对带有过期时间,那么过期时间也会和键值对保存在一起。根据键值对的数量、类型、内容以及是否有过期时间等条件的不同,key_value_pairs 部分的长度也会有所不同
下图则展示了一个完整的 RDB 文件,文件中包含了 0 号数据库和 3 号数据库

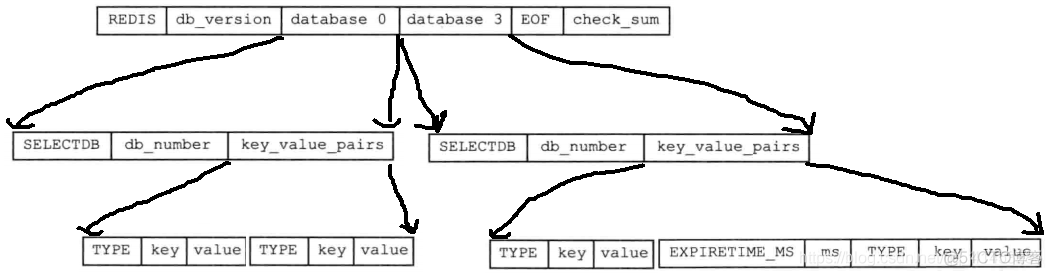
# 8.key_value_pairs 结构
key_value_pairs 都保存了一个或以上数量的键值对,如果键值对带有过期时间的话,那么键值对的过期时间也会被保存在内。
不带过期时间的键值对:在 RDB 文件中由 TYPE、key、value3 部分组成:
- TYPE:记录了 value 的类型,长度为 1 字节,值可以是以下常量的其中一个(以下列出的每个 TYPE 常量都代表了一种对象类型或者底层编码,当服务器读入 RDB 文件中的键值对数据时,程序会根据 TYPE 的值来决定如何读入和解释 value 的数据。key 和 value 分别保存了键值对的键对象和值对象):
- REDIS_RDB_TYPE_STRING
- REDIS_RDB_TYPE_LIST
- REDIS_RDB_TYPE_SET
- REDIS_RDB_TYPE_ZSET
- REDIS_RDB_TYPE_HASH
- REDIS_RDB_TYPE_LIST_ZIPLIST
- REDIS_RDB_TYPE_SET_INTSET
- REDIS_RDB_TYPE_ZSET_ZIPLIST
- REDIS_RDB_TYPE_HASH_ZIPLIST
- key:其中 key 总是一个字符串对象,它的编码方式和
REDIS_RDB_TYPE_STRING类型的 value 一样。根据内容长度的不同,key 的长度也会有所不同 - value:根据 TYPE 类型的不同,以及保存内容长度的不同,保存 value 的结构和长度也会有所不同
下图展示了一个没有过期时间的字符串键值对:

带有过期时间的键值对结构 带有过期时间的键值对在 RDB 文件中由 EXPIRETIME_MS、ms、TYPE、key、value 五部分组成:
- EXPIRETIME_MS 常量:长度为 1 字节,它告知读入程序,接下来要读入的将是一个以毫秒为单位的过期时间
- ms:是一个 8 字节长的带符号整数,记录着一个以毫秒为单位的 UNIX 时间戳,这个时间戳就是键值对的过期时间

假设 0 号数据库中有 2 个不带有过期时间的键值对,数据库 3 含有 1 个不带有过期时间的键值对和 1 个带有过期时间的键值对
# 9.TYPE 字段与 value 的编码
RDB 文件中的每个 value 部分都保存了一个值对象,每个值对象的类型都由与之对应的 TYPE 记录,根据类型的不同,value 部分的结构、长度也会有所不同
1.字符串对象
如果 TYPE 的值为 REDIS_RDB_TYPE_STRING,那么 value 保存的就是一个字符串对象,字符串对象的编码可以是 REDIS_ENCODING_INT 或者 REDIS_ENCODING_RAW ① 如果字符串对象的编码为 REDIS_ENCODING_INT:
那么说明对象中保存的是长度不超过 32 位的整数,这种编码的对象将以下图所示的结构保存
其中,ENCODING 的值可以是 REDIS_RDB_ENC_INT8、REDIS_RDB_ENC_INT16 或者 REDIS_RDB_ENC_INT32 三个常量的其中一个,它们分别代表 RDB 文件使用 8 位(bit)、16 位或者 32 位来保存整数值 integer。
② 如果字符串对象的编码为 REDIS_ENCODING_RAW:
那么说明对象所保存的是一个字符串值,根据字符串长度的不同,有压缩和不压缩两种方法来保存这个字符串:
- 如果字符串的长度小于等于 20 字节,那么这个字符串会直接被原样保存
- 如果字符串的长度大于 20 字节,那么这个字符串会被压缩之后再保存
备注:以上两个条件是在假设服务器打开了 RDB 文件压缩功能的情况下进行的,如果服务器关闭了 RDB 文件压缩功能,那么 RDB 程序总以无压缩的方式保存字符串值,对于没有被压缩的字符串,RDB 程序会以下图所示的结构来保存该字符串
- string 部分保存了字符串值本身
- len 保存了字符串值的长度
对于压缩后的字符串,RDB 程序会以下图所示的结构来保存该字符串
其中,REDIS_RDB_ENC_LZF 常量标志着字符串已经被 LZF 算法(http://liblzf.plan9.de)压缩过了,读入程序在碰到这个常量时,会根据之后的compressed_len、origin_len和compressed_string三部分,对字符串进行解压缩:其中compressed_len记录的是字符串被压缩之后的长度,而origin_len记录的是字符串原来的长度,compressed_string记录的则是被压缩之后的字符串。
2.列表对象
如果 TYPE 的值为 REDIS_RDB_TYPE_LIST,那么 value 保存的就是一个 REDIS_ENCODING_LINKEDLIST 编码的列表对象。
RDB 文件保存这种对象的结构如下图所示:

- list_length 记录了列表的长度,它记录列表保存了多少个项(item),读入程序可以通过这个长度知道自己应该读入多少个列表项
- 图中以 item 开头的部分代表列表的项,因为每个列表项都是一个字符串对象,所以程序会以处理字符串对象的方式来保存和读入列表项
示例

- 第一个列表项的长度为 5,内容为字符串"hello"。
- 第二个列表项的长度也为 5,内容为字符串"world"。
- 第三个列表项的长度为 1,内容为字符串"!"
3.集合对象
如果 TYPE 的值为 REDIS_RDB_TYPE_SET,那么 value 保存的就是一个 REDIS_ENCODING_HT 编码的集合对象,RDB 文件保存这种对象的结构如下图所示:

- set_size 是集合的大小,它记录集合保存了多少个元素,读入程序可以通过这个大小知道自己应该读入多少个集合元素。
- 以 elem 开头的部分代表集合的元素,因为每个集合元素都是一个字符串对象,所以程序会以处理字符串对象的方式来保存和读入集合元素。
4.哈希表对象
如果 TYPE 的值为 REDIS_RDB_TYPE_HASH,那么 value 保存的就是一个 REDIS_ENCODING_HT 编码的集合对象,RDB 文件保存这种对象的结构如下图所示:

- hash_size 记录了哈希表的大小,也即是这个哈希表保存了多少键值对,读入程序可以通过这个大小知道自己应该读入多少个键值对。
- 以 key_value_pair 开头的部分代表哈希表中的键值对,键值对的键和值都是字符串对象,所以程序会以处理字符串对象的方式来保存和读入键值对。
结构中的每个键值对都以键紧挨着值的方式排列在一起,如下图所示:

因此,从更详细的角度看,哈希表对象的结构可以表示为下图所示:

作为示例,下图展示了一个包含两个键值对的哈希表,第一个数字 2 记录了哈希表的键值对数量,之后跟着的是两个键值对:
- 第一个键值对的键是长度为 1 的字符串"a",值是长度为 5 的字符串"apple"
- 第二个键值对的键是长度为 1 的字符串"b",值是长度为 6 的字符串"banana"

5.有序集合对象
如果 TYPE 的值为 REDIS_RDB_TYPE_ZSET,那么 value 保存的就是一个 REDIS_ENCODING_SKIPLIST 编码的有序集合对象,RDB 文件保存这种对象的结构如下图所示:

sorted_set_size 记录了有序集合的大小,也即是这个有序集合保存了多少元素,读入程序需要根据这个值来决定应该读入多少有序集合元素。以 element 开头的部分代表有序集合中的元素,每个元素又分为成员(member)和分值(score)两部分,成员是一个字符串对象,分值则是一个 double 类型的浮点数,程序在保存 RDB 文件时会先将分值转换成字符串对象,然后再用保存字符串对象的方法将分值保存起来。
有序集合中的每个元素都以成员紧挨着分值的方式排列,下图所示:

因此,从更详细的角度看,有序集合对象的结构可以表示为下图所示:

作为示例,下图展示了一个带有两个元素的有序集合,第一个数字 2 记录了有序集合的元素数量,之后跟着的是两个有序集合元素:
- 第一个元素的成员是长度为 2 的字符串"pi",分值被转换成字符串之后变成了长度为 4 的字符串"3.14"
- 第二个元素的成员是长度为 1 的字符串"e",分值被转换成字符串之后变成了长度为 3 的字符串"2.7"

6.INTSET 编码的集合
- 如果
TYPE的值为REDIS_RDB_TYPE_SET_INTSET,那么 value 保存的就是一个整数集合对象 RDB文件保存这种对象的方法是,先将整数集合转换为字符串对象,然后将这个字符串对象保存到RDB文件里面- 如果程序在读入
RDB文件的过程中,碰到由整数集合对象转换成的字符串对象,那么程序会根据TYPE值的指示,先读入字符串对象,再将这个字符串对象转换成原来的整数集合对象
7.ZIPLIST 编码的列表、哈希表或者有序集合
- 如果
TYPE的值为REDIS_RDB_TYPE_LIST_ZIPLIST、REDIS_RDB_TYPE_HASH_ZIPLIST或者REDIS_RDB_TYPE_ZSET_ZIPLIST, - 那么 value 保存的就是一个压缩列表对象,
RDB文件保存这种对象的方法是:- 将压缩列表转换成一个字符串对象
- 将转换所得的字符串对象保存到
RDB文件。
- 如果程序在读入
RDB文件的过程中,碰到由压缩列表对象转换成的字符串对象,那么程序会根据TYPE值的指示,执行以下操作:- 读入字符串对象,并将它转换成原来的压缩列表对象
- 根据 TYPE 的值,设置压缩列表对象的类型:
- 如果 TYPE 的值为
REDIS_RDB_TYPE_LIST_ZIPLIST,那么压缩列表对象的类型为列表; - 如果 TYPE 的值为
REDIS_RDB_TYPE_HASH_ZIPLIST,那么压缩列表对象的类型为哈希表; - 如果 TYPE 的值为
REDIS_RDB_TYPE_ZSET_ZIPLIST,那么压缩列表对象的类型为有序集合; - 从这个步骤可以看出,由于 TYPE 的存在,即使列表、哈希表和有序集合三种类型都使用压缩列表来保存,RDB 读入程序也总可以将读入并转换之后得出的压缩列表设置成原来的类型
# 10.RDB 对过期处理
在执行 SAVE 命令或者 BGSAVE 命令创建一个新的 RDB 文件时,程序会对数据库中的键进行检查,已过期的键不会被保存到新创建的 RDB 文件中。
将对 RDB 文件进行载入:
- 如果服务器以主服务器模式运行,那么在载入 RDB 文件时,程序会对文件中保存的键进行检查,未过期的键会被载入到数据库中,而过期键则会被忽略,所以过期键对载入
RDB文件的主服务器不会造成影响。 - 如果服务器以从服务器模式运行,那么在载入 RDB 文件时,文件中保存的所有键,不论是否过期,都会被载入到数据库中。不过,因为主从服务器在进行数据同步的时候,从服务器的数据库就会被清空,所以一般来讲,过期键对载入 RDB 文件的从服务器也不会造成影响。
# 11.AOF 持久化
除了 RDB 持久化功能之外,Redis 还提供了 AOF(Append Only File)持久化功能。与 RDB 持久化通过保存数据库中的键值对来记录数据库状态不同,AOF 持久化是通过保存 Redis 服务器所执行的写命令来记录数据库状态的

# 12.AOF 实现
AOF 持久化功能的实现可以分为命令追加 (append)、文件写入、 文件同步(sync)三个步骤。
命令追加:当 AOF 持久化功能处于打开状态时,服务器在执行完一个写命令之后,会以协议格式将被执行的写命令追加到服务器状态的 aof_buf 缓冲区的末尾;
文件写入:Redis 的服务器进程就是一个事件循环(loop),这个循环中的文件事件负责接收客户端的命令请求,以及向客户端发送命令回复,而时间事件则负责执行像 serverCron 函数这样需要定时运行的函数。因为服务器在处理文件事件时可能会执行写命令,使得一些内容被追加到 aof_buf 缓冲区里面,所以在服务器每次结束一个事件循环之前,它都会调用 flushAppendOnlyFile 函数,考虑是否需要将 aof_buf 缓冲区中的内容写入和保存到 AOF 文件里面.
文件同步:flushAppendOnlyFile 函数的行为由服务器配置的 appendfsync 选项的值来决定,各个不同同值产生的行为如表:
appendfsync no:当设置 appendfsync 为 no 时,Redis 不会主动调用 fsync 去将 aof 日志同步到磁盘,完全依赖于操作系统appendfsync everysec:当设置为 appendfsync 为 everysec 的时候,Redis 会默认每隔一秒进行一次 fsync 调用,将缓冲区中的数据写到磁盘。默认是这种方式.appendfsync always:当设置 appendfsync 为 always 时,每一次写操作都会调用一次 fsync,这时数据是最安全的,当然,由于每次都会执行 fsync,所以其性能也会受到影响。
系统提供了 fsync 和 fdatasync 两个同步函数,它们可以强制让操作系统立即将缓冲区中的数据写入到硬盘里面,从而确保写入数据的安全性。
appendonly yes #启用aof持久化方式
# appendfsync always #每次收到写命令就立即强制写入磁盘,最慢的,但是保证完全的持久化,不推荐使用
appendfsync everysec #每秒钟强制写入磁盘一次,在性能和持久化方面做了很好的折中,推荐
# appendfsync no #完全依赖os,性能最好,持久化没保证
2
3
4
# 13.AOF 数据还原
因为 AOF 文件里面包含了重建数据库状态所需的所有写命令,所以服务器只要读入并重新执行一遍 AOF 文件里面保存的写命令,就可以还原服务器关闭之前的数据库状态。
Redis 读取 AOF 文件并还原数据库状态的详细步骤如下:
- 创建一个不带网络连接的
伪客户端(fake client),因为 Redis 的命令只能在客户端上下文中执行,而载入 AOF 文件时所使用的命令直接来源于 AOF 文件而不是网络连接,所以服务器使用了一个没有网络连接的伪客户端来执行 AOF 文件保存的写命令,伪客户端执行命令的效果和带网络连接的客户端执行命令的效果完全一样。 - 从 AOF 文件中分析并读取出一条写命令。
- 使用伪客户端执行被读出的写命令。
- 一直执行步骤 2 和步骤 3,直到 AOF 文件中的
所有写命令都被处理完毕为止。
# 14.AOF 重写
因为 AOF 持久化是通过保存被执行的写命令来记录数据库状态的,所以随着服务器运行时间的流逝,AOF 文件中的内容会越来越多,文件的体积也会越来越大,如果不加以控制的话,体积过大的 AOF 文件很可能对 Redis 服务器、甚至整个宿主计算机造成影响,并且 AOF 文件的体积越大,使用 AOF 文件来进行数据还原所需的时间就越多。
为了解决 AOF 文件体积膨胀的问题,Redis 提供了 AOF 文件重写(rewrite)功能。通过该功能,Redis 服务器可以创建一个新的 AOF 文件来替代现有的 AOF 文件,新旧两个 AOF 文件所保存的数据库状态相同,但新 AOF 文件不会包含任何浪费空间的冗余命令,所以新 AOF 文件的体积通常会比旧 AOF 文件的体积要小得多,节省空间。
# 15.AOF 重写实现
虽然 Redis 将生成新 AOF 文件替换旧 AOF 文件的功能命名为 AOF 文件重写,但实际上,AOF 文件重写并不需要对现有的 AOF 文件进行任何读取、分析或者写入操作,这个功能是通过读取服务器当前的数据库状态来实现的。使用的是写时复制的思想,copy on write。
所有类型的键都可以用同样的方法去减少 AOF 文件中的命令数量。 首先从数据库中读取键现在的值,然后用一条命令去记录键值对, 代替之前记录这个键值对的多条命令,这就是 AOF 重写功能的实现原理。
因为 aof_rewrite 函数生成的新 AOF 文件只包含还原当前数据库状态所必须的命令,所以新 AOF 文件不会浪费任何硬盘空间。
在实际中,为了避免在执行命令时造成客户端输入缓冲区溢出,重写程序在处理列表、哈希表、集合、有序集合这四种可能会带有多个元素的键时,会先检查键所包含的元素数量,如果元素的数量超过了 redis.h/REDIS_AOF_REWRITE_ITEMS_PER_CMD 常量的值,那么重写程序将使用多条命令来记录键的值,而不单单使用一条命令。
在目前版本中,REDIS_AOF_REWRITE_ITEMS_PER_CMD 常量的值为 64,这也就是说,如果一个集合键包含了超过 64 个元素,那么重写程序会用多条 SADD 命令来记录这个集合,并且每条命令设置的元素数量也为 64 个;
为了解决服务器进程和子进程这种数据不一致问题,Redis 服务器设置了一个 AOF 重写缓冲区,这个缓冲区在服务器创建子进程之后开始使用,当 Redis 服务器执行完一个写命令之后,它会同时将这个写命令发送给 AOF 缓冲区和 AOF 重写缓冲区。
这也就是说,在子进程执行 AOF 重写期间,服务器进程需要执行以下三个工作:
执行客户端发来的命令。
将执行后的写命令追加到
AOF 缓冲区。将执行后的写命令追加到
AOF 重写缓冲区。
# 16.AOF 保存的命令
AOF 保存的命令:
- 对键值对的修改命令
- PUBSUB 命令
- SCRIPT LOAD 命令
AOF 工作原理:
AOF 重写和 rdb 创建快照一样,都是巧妙的利用了
写时复制机制。redis 调用
fork,现在有父子两个进程。根据内存中的数据库快照,往临时文件中写入重建数据库状态的命令。
父进程继续处理
client 请求,除了把写命令写入到原来的aof文件中。同时把收到的写命令缓存起来。这样就能保证如果子进程重写失败的话并不会出问题。当
子进程把快照内容以命令方式写到临时文件中后,子进程发信号通知父进程。然后父进程把缓存的写命令也写入到临时文件。现在父进程可以使用
临时文件替换老的aof 文件,并重命名,后面收到的写命令也开始往新的 aof 文件中追加。
# 17.AOF 后台重写
BGREWRITEAOF 函数实现原理
aof_rewrite 函数的缺点:AOF 重写程序 aof_rewrite 函数可以很好地完成创建一个新 AOF 文件的任务, 但是,因为这个函数会进行大量的写入操作,所以调用这个函数的线程将被长时间阻塞,因为 Redis 服务器使用单个线程来处理命令请求,所以如果由服务器直接调用 aof_rewrite 函数的话,那么在重写 AOF 文件期间,服务期将无法处理客户端发来的命令请求。
很明显,作为一种辅佐性的维护手段,Redis 不希望 AOF 重写造成服务器无法处理请求, 所以 Redis 决定将 AOF 重写程序放到子进程里执行,这样做可以同时达到两个目的:
子进程进行 AOF 重写期间,服务器进程(父进程)可以继续处理命令请求子进程带有服务器进程的数据副本,使用子进程而不是线程,可以在避免使用锁的情况 下,保证数据的安全性
# 18.AOF 对过期处理
当服务器以 AOF 持久化模式运行时,如果数据库中的某个键已经过期,但它还没有被惰性删除或者定期删除,那么 AOF 文件不会因头这个过期键而产生任何影响。
当过期键被惰性删除或者定期删除之后,程序会向 AOF 文件追加(append)一条 DEL 命令,来显式地记录该键已被删除。
# 19.RDB 和 AOF 选择
redis 使用了 2 种方式进行持久化:
Snapshotting(快照 RDB,默认方式):能够在指定的时间间隔对你的操作进程快照存储Append-only file(缩写 aof):记录每次对服务器写的操作,当服务器重启时会重新执行这些命令来恢复原始的数据
RDB 和 AOF 兼容性:
默认情况下,Redis 将数据库
快照保存在一个dump.rdb的二进制文件中。如果服务器开启了
AOF持久化功能,那么服务器会优先使用AOF文件来还原数据库状态。只有在
AOF持久化功能处于关闭状态时,服务器才会使用RDB文件来还原数据库状态。
# 20.copy-on-write 技术
写时复制(copy-on-write/COW)技术:是一个被使用在程式设计领域的优化策略。其基础的观念是,如果有多个呼叫者(callers)同时要求相同资源,他们会共同取得相同的指标指向相同的资源,直到某个呼叫者(caller)尝试修改资源时,系统才会真正复制一个副本(private copy)给该呼叫者,以避免被修改的资源被直接察觉到,这过程对其他的呼叫只都是通透的(transparently)。此作法主要的优点是如果呼叫者并没有修改该资源,就不会有副本(private copy)被建立。
这是一种简单的读写分离思想,适用于读多写少的并发场景。比如黑白名单,热点文章等等。正常情况下我们说 cow,指的是修改共享资源时,将共享资源 copy 一份,加锁后修改,再将原容器的引用指向新的容器。对于 java 来说,是有线程的 cow 容器的,比如 CopyOnWriteArrayList。另外就是 cow 保证的是最终一致性而不是强一致。
Redis 的 COW:
- Redis 创建子进程以后,根本不进行数据的 copy,
主进程与子线程是共享数据的。主进程继续对外提供读写服务。 - 虽然不 copy 数据,但是
kernel会把主进程中的所有内存页的权限都设为read-only,主进程和子进程访问数据的指针都指向同一内存地址。 - 主进程发生写操作时,因为权限已经设置为 read-only 了,所以会触发
页异常中断(page-fault)。在中断处理中,需要被写入的内存页面会复制一份,复制出来的旧数据交给子进程使用,然后主进程该干啥就干啥。 - 也就是说,在进行
IO 操作写盘的过程中(on write),对于没有改变的数据,主进程和子进程资源共享;只有在出现了需要变更的数据时(写脏的数据),才进行copy 操作。 - 在最理想的情况下,也就是生成 RDB 文件的过程中,一直没有写操作的话,就根本不会发生内存的额外占用。
# 21.混合模式
- 4.0 之后新增
混合模式,AOF 文件中保存 RDB 二进制数据+少量 AOF - 体积小,可读性差
#设置混合模式
aof-use-rdb-preamble true
2
# 五.主从复制
# 1.什么是复制?
执行 SLAVOF 命令或设置 slaveof 选项,让一个服务器去复制另外一个服务器,被复制的为主服务器,对主服务器进行复制的是从服务器。
进行复制的主从服务器双方的数据库将保存相同的数据,即数据库状态一致,简称“一致”。
复制功能分为同步和命令传播两个操作:
同步操作(sync):作用于将从服务器的数据库状态更新至主服务器当前所处的数据库状态。命令传播(command propagate):则作用于在主服务器的数据库状态被修改,导致主从服务器的数据库状态出现不一致时,让主从服务器的数据库重新回到一致状态。
# 2.说说同步过程?
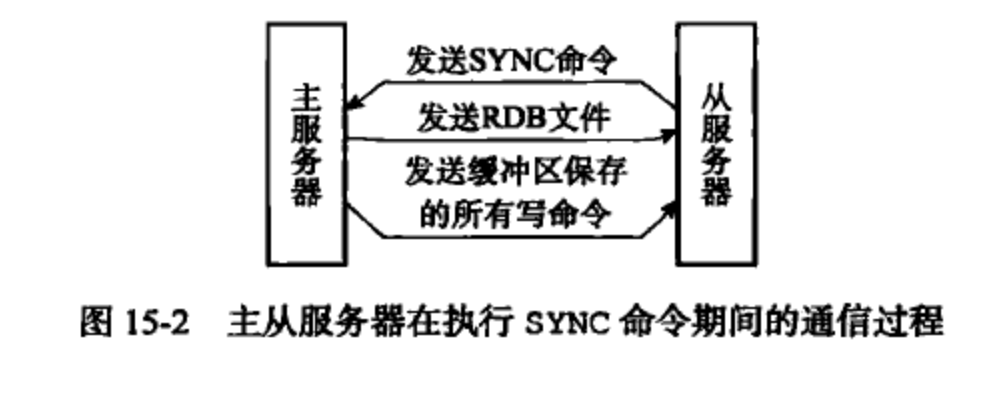
旧版复制功能(SYNC 命令):客户端向从服务器发送 SLAVEOF 命令复制主服务器时,首先从服务器执行的是同步操作,更新至主服务器当前所处的数据库状态。
实际操作是从服务器向主服务器发送 SYNC 命令:
- 从服务器向主服务器发送
SYNC命令; - 收到
SYNC命令的主服务器执行BGSAVE命令,在后台生成一个RDB文件,并使用一个缓冲区记录从现在开始执行的所有写命令; - 当
主服务器的BGSAVE命令执行完,主服务器会将BGSAVE命令生成的RDB文件发送给从服务器,从服务器收到后载入RDB文件,更新至主服务器执行BGSAVE的状态; 主服务器将记录在缓冲区里的所有写命令发送给从服务器,从服务器执行写命令,更新指服务器所处的状态;
# 3.说说命令传播
同步操作之后,主从服务器两者的数据库状态将达到一致状态,但当主服务器执行客户端的命令时,主服务器的状态可能修改,不再一致。
为了让主从服务器再一次回到一致状态,主服务器需要对从服务器执行命令传播操作:
将造成主从服务器不一致的写命令发送给从服务器执行,执行后再一次回到一致状态
# 4.旧版复制缺陷?
从服务器对主服务器的复制可以分为以下两种情况:
初次复制:从服务器没有复制过任何主服务器,或者从服务器当前要复制的主服务器和上一次复制的主服务器不同。断线后重复制:处于命令传播阶段的主从服务器因网络原因中断了复制,但从服务器通过自动重连,重新连上了主服务器,并继续复制主服务器。
初次复制使用旧版复制功能就能很好地完成任务,但是对于断线后重复制来说,旧版复制功能效率低
在命令传播阶段某个时间点断线后主服务器执行了部分命令修改了数据库状态,而从服务器还在重连,成功后是执行 SYNC 命令重新开始操作,但是实际上不是很需要的,因为主从服务器在断线之前是一致状态的
SYNC 命令:
- 主服务器执行
BGSAVE命令生成RDB文件,耗费主服务器 CPU、内存、磁盘 I/O 资源 - 发送
RDB文件耗费主从服务器大量的网络资源(带宽和流量),并对主服务器响应命令请求时间产生影响 - 从服务器需要载入
RDB文件,进入阻塞状态无法处理命令请求 - 是非常消耗资源的操作
# 5.新版复制?
使用 PSYNC 命令代替 SYNC 命令解决断线重复制的低效问题,
PSYNC 命令有完整重同步和部分重同步两种模式:
完整重同步(full resy nchronization):初次复制情况,步骤和 SYNC 命令执行步骤一致部分重同步(partial resynchronization):断线后重复制情况,主服务器将断线期间执行的写命令发送给从服务器,从服务器接收并执行,更新至服务器当前状态
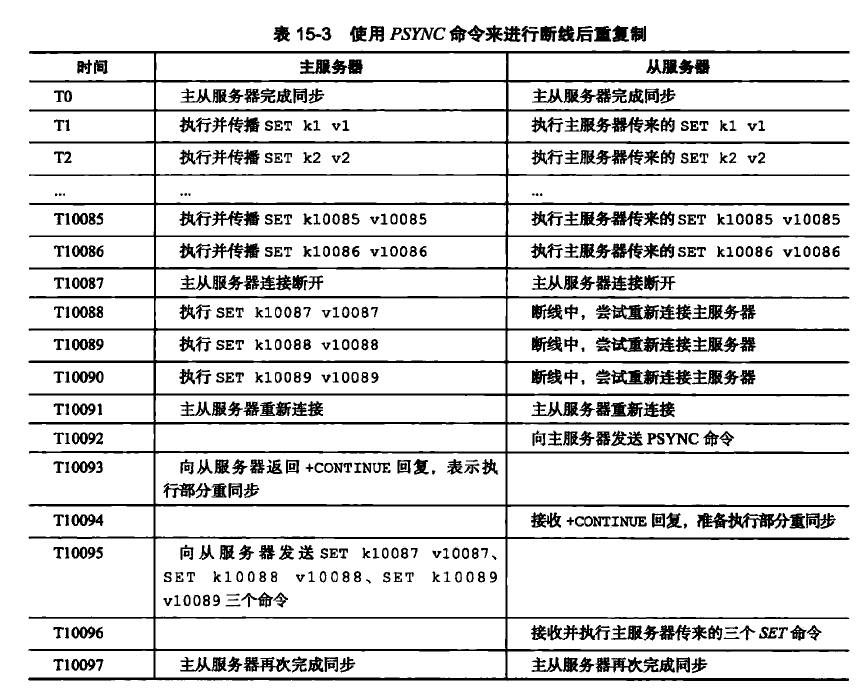
# 6.部分重同步实现
部分重同步功能由以下三个部分构成:
主服务器的复制偏移量和从服务器的复制偏移量(replication offset)- 主服务器的
复制积压缓冲区(replication backlog) 服务器的运行 ID(run ID)
复制偏移量 主服务器和从服务器会分别维护一个复制偏移量:
- 主服务器每次向从服务器传播
N 个字节的数据时,就将自己的复制偏移量的值加上N - 从服务器每次收到主服务器传播的
N 个字节数据时,就将自己的复制偏移量加上N
通过对比偏移量可以知道主从服务器是否处于一致状态。
复制积压缓冲区 复制积压缓冲区是由主服务器维护的一个固定长度(fixed-size)先进先出(FIFO)队列,默认为 1 MB,模型是滑动窗口。
当主服务器进行命令传播时,不仅会将写命令发给所有从服务器,还会将写命令入队到复制积压缓冲区里面,且队列中每个字节记录相应的复制偏移量
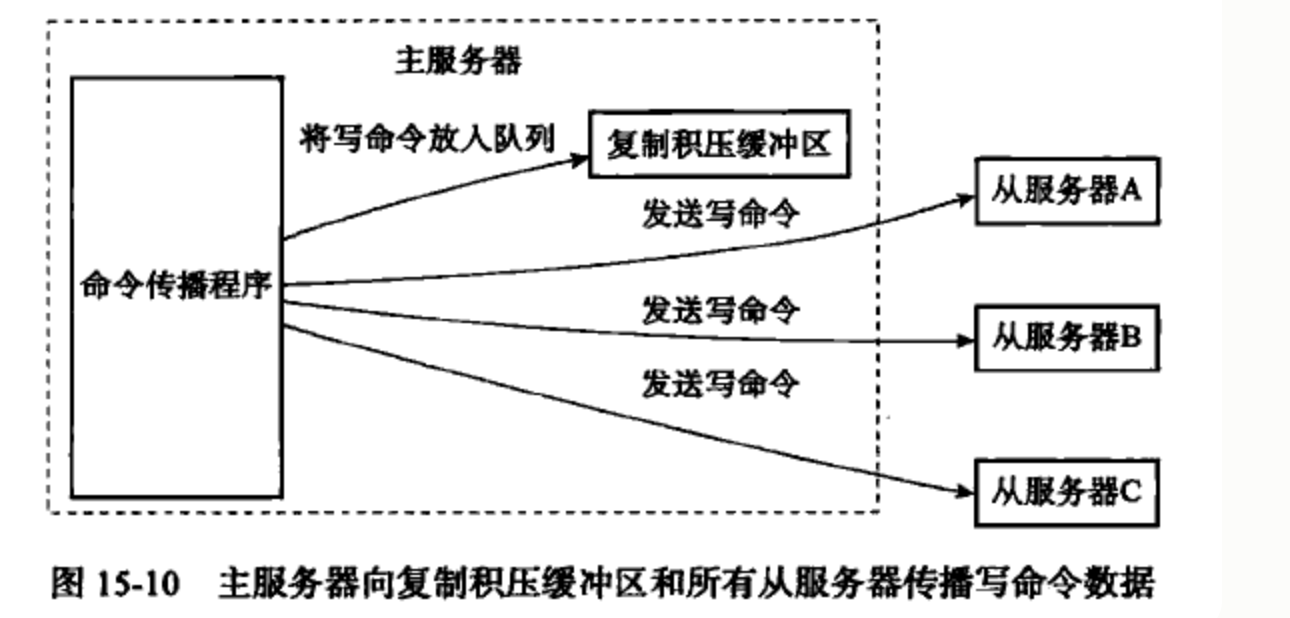
当从服务器重新连上主服务器后,从服务器会通过 PSYNC 命令将自己发复制偏移量 offset 发送给主服务器,主服务器根据此来决定对服务器执行何种同步操作:
- 如果
offset之后的数据仍在复制积压缓冲区中,则进行部分重同步操作 - 相反,如果已经不存在
复制缓冲区中则进行完整重同步操作
根据需要调整复制缓冲区大小
默认为 1 MB,最小跟由公式 second * write_size_per_second 估算
second:服务器断线后重新连上主服务器的平均时间,单位秒 write*size_per_second:服务器平均每秒产生的写命令数据量(协议格式的写命令的长度总和) 安全起见,实际大小可以设置为:2 * second _ write_size_per_second,可以保证绝大部分断线情况都能用部分重同步处理
服务器运行 ID
- 每个服务器都有自己的运行 ID
- 运行 ID 在服务器启动时自动生成,由 40 个随机的十六进制字符组成
当从服务器进行初次复制时,主服务器会将自己的运行 ID 传送给从服务器,而从服务器会将其保存,当从服务器断线并重新连上一个主服务器时,从服务器将当前连接的主服务器发送之前保存的运行 ID:
- 如果 ID 与当前连接的主服务器 ID 相同,则说明断线之前就是与这个主服务器连接,则继续尝试
部分重同步操作 - 如果 ID 不同,断线之前不是这个主服务器,执行
完整重同步操作
# 7.PSYNC 命令的实现
PSYNC 命令的实现原理涉及到 Redis 主从复制的工作流程,包括初次同步和部分同步。以下是大致的工作流程:
- 初次同步:
- 从服务器连接到主服务器,并发送一个
PSYNC命令,主要包含从服务器的复制偏移量和复制 ID。 - 主服务器根据从服务器提供的信息,决定是进行完整重同步(发送完整数据快照)还是部分同步。
- 如果需要进行完整重同步,主服务器将发送自己的完整数据快照给从服务器,从服务器会保存这个数据快照并加载到内存中。
- 如果进行部分同步,主服务器将发送从上次复制偏移量之后的所有写命令给从服务器,从服务器通过执行这些写命令来追赶主服务器。
- 从服务器连接到主服务器,并发送一个
- 部分同步:
- 从服务器定期向主服务器发送
PSYNC命令,请求从上次复制偏移量之后的数据更新。 - 主服务器根据复制偏移量,查找并发送从该偏移量开始的写命令给从服务器。
- 从服务器接收并执行这些写命令,以便保持与主服务器的数据同步。
- 从服务器定期向主服务器发送
需要注意的是,为了保证数据的一致性和可靠性,主服务器会将复制的写命令(包括数据修改操作)追加到复制缓冲区中,然后再发送给从服务器。这样即使从服务器断开连接或者数据传输出现问题,主服务器也能保持写操作的有序性。
PSYNC 命令的实现涉及主从同步的不同情况和策略,确保从服务器可以与主服务器保持数据的同步和一致性。这样可以实现数据备份、负载均衡以及容灾等重要功能。
# 8.复制的实现
SLAVEOF <master_ip> <master_port>
步骤 1:设置主服务器的地址和端口
从服务器将客户端输入的主服务器的 IP 地址和端口保存到服务器状态的 masterhost 和 masterport 属性中
SLAVEOF 是一个异步命令,完成以上两个属性的设置之后,从服务器向客户端返回 OK,表示复制指令已经被接收,但实际的复制工作将在 OK 之后才真正执行
struct redisServer {
// ...
//主服务器的地址
char *masterhost;
//主服务器的端口
int masterport;
// ...
};
2
3
4
5
6
7
8
步骤 2:建立套接字连接 根据 IP 地址和端口,从服务器创建连向主服务器的套接字连接,如果连接成功,从服务器将为此套接字关联一个专门用于处理复制工作的文件事件处理器,负责后续的工作
主服务器在接收从服务器的套接字之后为该套接字创建相应的客户端状态,并将从服务器看作一个连接到主服务器的客户端看待,此时从服务器将具有服务器和客户端两种状态:从服务器可以向主服务器发送命令请求,而主服务器则会向从服务器返回命令回复
步骤 3:发送 PING 命令 从服务器成为客户端后第一件事是向主服务器发送一个 PING 命令
虽然主从服务器成功建立起了套接字连接,但双方并未使用该套接字进行过任何通信, 通过发送 PING 命令可以检查套接字的读写状态是否正常
因为复制工作接下来的几个步骤都必须在主服务器可以正常处理命令请求的状态下才能进行,通过发送 PING 命令可以检查主服务器能否正常处理命令请求
从服务器将遇到三种情况:
- 主服务器返回命令回复,但从服务器不能在规定时间内读取命令回复的内容,则表示主从服务器之间的网络连接状态不稳定,需要从服务器断开并重新创建套接字
- 主服务器返回错误。表示主服务器无法处理从服务器命令请求,则从服务器断开并重新创建套接字
- 从服务器读到 “PONG” 回复,表示主从服务器状态正常,可以进行后续操作
步骤 4:身份验证 下一步则是决定是否身份验证:根据是否设置了 masterauth 选项
从服务器向主服务器发送了一条 AUTH 命令,参数为从服务器 masterauth 选项的值
可能遇到几种情况:
- 主服务器没有设置 requirepass 选项,从服务器也没有设置 masetrauth 选项,主服务器继续执行从服务器发送的命令
- 从服务器通过 AUTH 发送的密码和主服务器 requirepass 选项设置的密码相同,继续执行,否则则返回 invalid password 错误
- 主服务器有 requirepass 选项,从服务器无 masetrauth 选项,主服务器返回 NOAUTH 选项
- 主服务器无 requirepass 选项,从服务器有 masetrauth 选项,主服务器返回 no password is set 错误
错误情况令从服务器中止目前的复制工作,并从创建套接字重新开始,直到身份验证或者从服务器放弃执行复制
步骤 5:发送端口信息 从服务器执行 REPLCONF listening-port ,向主服务器发送从服务器的监听端口号
主服务器接收后记录在从服务器对应的客户端状态的 slave_listening_port 中,其唯一作用就是主服务器执行 INFO replication 时打印从服务器端口
typedef struct redisClient {
// ...
//从服务器的监听端口号
int slave_listening_port;
// ...
} redisClient;
2
3
4
5
6
步骤 6:同步 从服务器向主服务器发送 PSYNC 命令,执行同步操作,并将自己的数据库更新至主服务器数据库当前所处的状态,执行之后主服务器也会成为从服务器的客户端
- 如果是完整重同步,将保存在缓冲区里面的写命令发送给从服务器执行
- 如果是部分重同步,发送保存在复制积压缓冲区中的命令
正因为主服务器成为了从服务器的客户端,所以主服务器才可以通过发送写命令来改变从服务器的数据库状态,不仅同步操作需要用到这一点,这也是主服务器对从服务器执行命令传播操作的基础
步骤 7:命令传播
当完成了同步之后,主从服务器就会进入命令传播阶段,这时主服务器只要一直将自己执行的写命令发送给从服务器,而从服务器只要一直接收并执行主服务器发来的写命令,就可以保证主从服务器一直保持一致了
# 9.复制心跳检测
命令传播阶段,从服务器默认以每秒一次频率向服务器发送命令:
REPLCONF ACK <replication_offset>
replication_offset:从服务器当前的复制偏移量
三个作用:
- 检测主从服务器的网络连接状态
- 辅助实现 min-slaves 选项
- 检测命令丢失
检测主从服务器的网络连接状态 通过接受命令来检查网络连接是否正常,如果没有收到则连接出现问题
辅助实现 min-slaves 配置选项 min-slaves-to-write 和 min-slaves-max-lag 可以防止主服务器在不安全的情况下执行写命令
min-slaves-to-write 3
min-slaves-max-lag 10
2
那么在从服务器的数量少于 3 个,或者三个从服务器的延迟(lag)值都大于或等于 10 秒时,主服务器将拒绝执行写命令,这里的延迟值就是上面提到的 INFO replication 命令的 lag 值。
解决方式:只有一个从库且要去维护的时候,请先设置 最少写从库的个数为0,再去维护从库
这样解决治标不治本,还是需要解决从库挂掉的原因
config set min-slaves-to-write 0
检测命令丢失 根据两个 REPLCONF ACK 命令可以得出从服务器的写命令是否在半路丢失,从复制偏移量的比较得出
# 10.复制模式下对过期处理
当服务器运行在复制模式下时,从服务器的过期键删除动作由主服务器控制:
主服务器在删除一个过期键之后,会显式地向所有从服务器发送一个
DEL 命令,告知从服务器删除这个过期键。从服务器在执行客户端发送的读命令时,
即使碰到过期键也不会将过期键删除,而是继续像处理未过期的键一样来处理过期键。从服务器只有在接到主服务器发来的
DEL 命令之后,才会删除过期键。3.2 版本后
从库判断已过期会返回空值因为 master 无法及时提供 DEL 命令,为了解决这个问题,slave 使用了
逻辑时钟来报告 key 不存在
通过由主服务器来控制从服务器统一地删除过期键,可以保证主从服务器数据的一致性,也正是因为这个原因,当一个过期键仍然存在干主服务器的数据库时,这个过期键在从服务器里的复制品也会继续存在。
# 11.查看主从信息
#查看主从信息
info replication
2
主节点执行
> info replication
# Replication
role:master
connected_slaves:0
master_replid:32f851a0bf5ab26c5d15753d471365dad7df02bc
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
2
3
4
5
6
7
8
9
10
11
12
从节点执行
> info replication
# Replication
role:slave
connected_slaves:0
master_replid:32f851a0bf5ab26c5d15753d471365dad7df02bc
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
2
3
4
5
6
7
8
9
10
11
12
# 六.Sentinel
# 1.Sentinel 哨兵模式功能
哨兵功能:哨兵的核心功能是主节点的自动故障转移。
监控(Monitoring):哨兵会不断地检查主节点和从节点是否运作正常。自动故障转移(Automatic failover):当主节点不能正常工作时,哨兵会开始自动故障转移操作,它会将失效主节点的其中一个从节点升级为新的主节点,并让其他从节点改为复制新的主节点。配置提供者(Configuration provider):客户端在初始化时,通过连接哨兵来获得当前 Redis 服务的主节点地址。通知(Notification):哨兵可以将故障转移的结果发送给客户端。
# 2.哨兵模式架构图
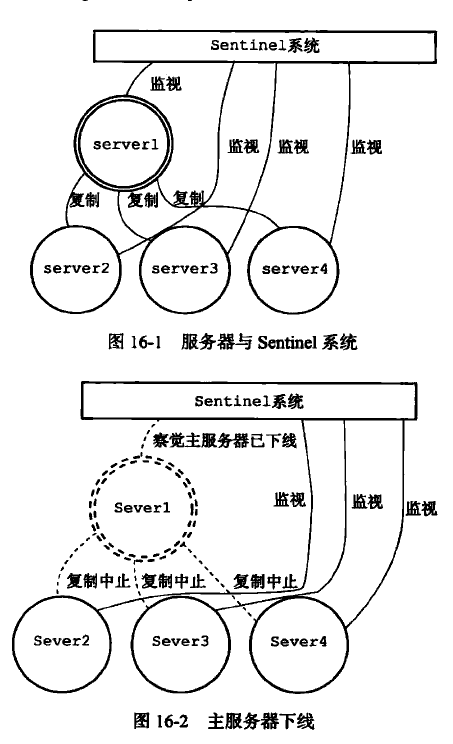
Sentinel 哨兵组成了一个 Redis 高可用性的方案:
由一个或多个 Sentinel 实例组成的 Sentinel 系统可以监视任意多个主服务器及其所有从服务器,并在主服务器下线时将其从服务器升级为新的主服务器,继续执行要求,当先前的主服务器再次上线时则成为新的从服务器
# 3.启动并初始化 Sentinel
redis-sentinel /path/to/yourt/setinel.conf
# or
redis-server /path/to/yourt/setinel.conf -- sentinel
2
3
启动时执行以下:
- 初始化服务器
- 将普通
Redis服务器使用的代码替换Sentinel专用代码 - 初始化
Sentinel代码 - 根据给定的配置文件,初始化
Sentinel的监视主服务器列表 - 创建连向主服务器的网络连接
# 4.初始化服务器
初始化 Sentinel 服务器与普通服务器的区别:
- 首先,因为
Sentinel本质上只是一个运行在特殊模式下的Redis服务器,所以启动Sentinel的第一步,就是初始化一个普通的Redis服务器。 - 不过,因为
Sentinel执行的工作和普通Redis服务器执行的工作不同,所以Sentinel的初始化过程和普通 Redis 服务器的初始化过程并不完全相同 - 例如,普通服务器在初始化时会通过载入
RDB文件或者AOF文件来还原数据库状态,但 是因为Sentinel并不使用数据库,所以初始化Sentinel时就不会载入RDB文件或者AOF文件
Sentinel 本质是一个运行在特殊模式下的 Redis 服务器,所以启动第一步也是初始化一个 Redis 服务器.
# 5.使用 Sentinel 专用代码
例如使用不同端口和不同的命令列表
#define REDIS_SERVERPORT 6379
#define REDIS_SENTINEL_PORT 26379
2
3
除此之外,普通 Redis 服务器使用 redis.c/redisCommandTable 作为服务器的命令表,而 Sentinel 则使用 sentinel.c/sentinelcmds作为服务器的命令表:
- 例如:其中的 INFO 命令会使用 Sentinel 模式下的专用实现
sentinel.c/sentinelInfoCommand函数,而不是普通 Redis 服务器使 用的实现 redis.c/infoCommand 函数 - sentinelcmds 命令表也解释了为什么在 Sentinel 模式下,Redis 服务器不能执行诸如 SET、 DBSIZE、EVAL 等等这些命令,因为服务器根本没有在命令表中载入这些命令。
Sentinel 执行的全部命令- PING
- SENTINEL
- INFO
- SUBSCRIBE
- UNSUBSCRIBE
- PSUBSCRIBE
- PUNSUBSCRIBE
struct redisCommand redisCommandTable[] = {
{"get",getCommand,2,"r",0,NULL,1,1,1,0,0},
{"set",setCommand,-3,"wm",0,noPreloadGetKeys,1,1,1,0,0},
{"setnx",setnxCommand,3,"wm",0,noPreloadGetKeys,1,1,1,0,0},
// ...
{"script",scriptCommand,-2,"ras",0,NULL,0,0,0,0,0},
{"time",timeCommand,1,"rR",0,NULL,0,0,0,0,0},
{"bitop",bitopCommand,-4,"wm",0,NULL,2,-1,1,0,0},
{"bitcount",bitcountCommand,-2,"r",0,NULL,1,1,1,0,0}
}
struct redisCommand sentinelcmds[] = {
{"ping",pingCommand,1,"",0,NULL,0,0,0,0,0},
{"sentinel",sentinelCommand,-2,"",0,NULL,0,0,0,0,0},
{"subscribe",subscribeCommand,-2,"",0,NULL,0,0,0,0,0},
{"unsubscribe",unsubscribeCommand,-1,"",0,NULL,0,0,0,0,0},
{"psubscribe",psubscribeCommand,-2,"",0,NULL,0,0,0,0,0},
{"punsubscribe",punsubscribeCommand,-1,"",0,NULL,0,0,0,0,0},
{"info",sentinelInfoCommand,-1,"",0,NULL,0,0,0,0,0}
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 6.初始化 Sentinel 状态
服务器会初始化一个 sentinel.c/sentinelState 结构,保存了服务器中 Sentinel 功能有关的状态,一般状态是
struct sentinelState {
//当前纪元,用于实现故障转移
uint64_t current_epoch;
//保存了所有被这个sentinel 监视的主服务器
//字典的键是主服务器的名字
//字典的值则是一个指向sentinelRedisInstance 结构的指针
dict *masters;
//是否进入了TILT 模式
int tilt;
//目前正在执行的脚本的数量
int running_scripts;
//进入TILT 模式的时间
mstime_t tilt_start_time;
//最后一次执行时间处理器的时间
mstime_t previous_time;
// 一个FIFO 队列,包含了所有需要执行的用户脚本
list *scripts_queue;
} sentinel;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# 7.初始化 Sentinel 状态的 master 属性
Sentinel状态中的masters字典记录了所有被Sentinel监视的主服务器的相关信息,其中:- 字典的键是被监视主服务器的名字
- 字典的值则是被监视主服务器对应的 sentinel.c/sentinelRedisInstance 结构
sentinelRedisInstance
- 每个
sentinelRedisInstance结构(后面简称“实例结构”)代表一个被 Sentinel 监视的Redis服务器实例(instance),这个实例可以是主服务器、从服务器,或者另外一个Sentinel。 - 实例结构包含的属性非常多,以下代码展示了实例结构在表示主服务器时使用的其中一 部分属性。
- addr 属性:sentinelRedisInstance.addr 属性是一个指向 sentinel.c/sentinelAddr 结构的指针,这个结构保存着实例的 IP 地址和端口号。
typedef struct sentinelRedisInstance {
//标识值,记录了实例的类型,以及该实例的当前状态
int flags;
//实例的名字
//主服务器的名字由用户在配置文件中设置
//从服务器以及Sentinel 的名字由Sentinel 自动设置
//格式为ip:port ,例如"127.0.0.1:26379"
char *name;
//实例的运行ID
char *runid;
//配置纪元,用于实现故障转移
uint64_t config_epoch;
//实例的地址
sentinelAddr *addr;
// SENTINEL down-after-milliseconds 选项设定的值
//实例无响应多少毫秒之后才会被判断为主观下线(subjectively down )
mstime_t down_after_period;
// SENTINEL monitor <master-name> <IP> <port> <quorum> 选项中的quorum 参数
//判断这个实例为客观下线(objectively down )所需的支持投票数量
int quorum;
// SENTINEL parallel-syncs <master-name> <number> 选项的值
//在执行故障转移操作时,可以同时对新的主服务器进行同步的从服务器数量
int parallel_syncs;
// SENTINEL failover-timeout <master-name> <ms> 选项的值
//刷新故障迁移状态的最大时限
mstime_t failover_timeout;
// ...
} sentinelRedisInstance;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
typedef struct sentinelAddr {
char *ip;
int port;
} sentinelAddr;
2
3
4
# 8.创建连向主服务器的网络连接
- 初始化
Sentinel的最后一步是创建连向被监视主服务器的网络连接,Sentinel 将成为主服务器的客户端,它可以向主服务器发送命令,并从命令回复中获取相关的信息 - 对于每个被
Sentinel监视的主服务器来说,Sentinel会创建两个连向主服务器的异步网络连接:- 一个是
命令连接,这个连接专门用于向主服务器发送命令,并接收命令回复 - 另一个是
订阅连接,这个连接专门用于订阅主服务器的sentinel:hello 频道
- 一个是
# 9.为什么有两个连接?
- 在 Redis 目前的发布与订阅功能中,被发送的信息都不会保存在 Redis 服务器里面, 如果在信息发送时,想要接收信息的客户端不在线或者断线,那么这个客户端就会丢失这条信息。因此,为了不丢失sentinel:hello 频道的任何信息,
Sentinel 必须专门用一个订阅连接来接收该频道的信息(MQ 就是干这个事情的,离线消息) - 另一方面,除了订阅频道之外,
Sentinel还必须向主服务器发送命令,以此来与主服务器进行通信,所以Sentinel还必须向主服务器创建命令连接
因为 Sentinel 需要与多个实例创建多个网络连接,所以 Sentinel 使用的是异步连接
下图展示了一个 Sentinel 向被它监视的两个主服务器 master1 和 master2 创建命令连接和订阅连接的例子:
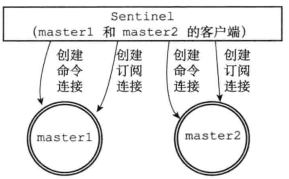
# 10.获取主服务器信息
Sentinel 会默认每 10 秒一次频率向监视的主服务器通过命令连接发送 INFO 命令,通过分析回复获取当前主服务器的信息
主服务器本身的信息:
run_id:服务器运行 IDrole 域:记录的服务器角色
主服务器从属的所有从服务器信息
- 每一个从服务器都以一个
slave字符串开头的行记录 ip:记录了从服务器的 IP 地址port:从服务器的端口号
- 每一个从服务器都以一个
根据 run_id 和 role 域,Sentinel 将对主服务器的实例结构进行更新,例如重启后的主服务器 run_id 将不同,Sentinel 检测后将会对实例结构的 run_id 进行更新
主服务器返回的从服务器信息被用于更新主服务器实例的 slave 字典
主服务器实例结构的 flags 属性的值是 SRI_MASTER,从服务器实例结构的 flags 属性的值是 SRT_SLAVE
主服务器的 name 属性是 Sentinel 配置文件设置的,从服务器实例结构的 name 属性的值是 Sentinel 根据从服务器的 IP 地址、端口号设置的。
# 11.获取从服务器信息
如果监视的主服务器有新的从服务器出现时,Sentinel 会为这个新的从服务器创建相应的实例结构外,还会创建连接到从服务器的命令连接和订阅连接
创建命令连接后,Sentinel 会以每十秒一次的频率通过命令连接向从服务器发送 INFO 命令
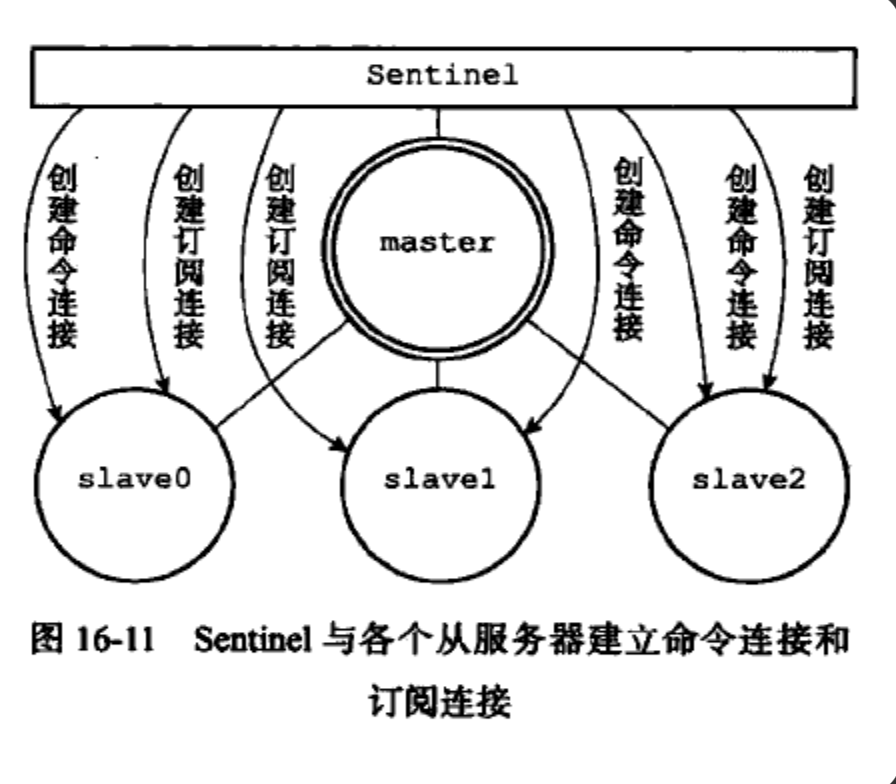
根据 INFO 命令的回复,Sentinel 会提取以下信息:
- 从服务器的
run_id - 从服务器的角色
role - 主服务器的 IP 地址
master_host,主服务器的端口号master_port - 主从服务器的连接状态
master_link_status - 从服务器的优先级
slave_priority - 从服务器的复制偏移量
slave_repl_offset
# 12.向主服务器和从服务器发送信息
默认情况下:Sentinel 会以每两秒一次的频率,通过命令连接向所有被监视的主服务器和从服务器发送以下格式的命令。
PUBLISH __sentinel__:hello "<s_ip>,<s_port>, <s_runid>,<s_epoch>,<m_name>, <m_ip>,<m_port>,<m_epoch>"
这条命令向服务器的sentinel: hello 频道发送了一条信息,信息的内容由多个参数组成:
1.其中以 s_开头的参数记录的是 Sentinel 本身的信息
2.而m_开头的参数记录的则是主服务器的信息,各个参数的意义
- 如果 Sentinel 正在监视的是主服务器,那么这些参数记录的就是主服务器的信息
- 如果 Sentinel 正在监视的是从服务器,那么这些参数记录的就是从服务器正在复制的主服务器的信息
信息中和 Senti inel 有关的参数
| 参数 | 意义 |
|---|---|
| s_ip | Sentinel 的 IP 地址 |
| s_port | Sentinel 的端端口号 |
| s_runid | Sentinel 的运运行 ID |
| s_epoch | Sentinel 当前的配置纪元 |
和主服务相关
| 参数 | 意义 |
|---|---|
| m_name | 主服务器的的名字 |
| m_ip | 主服务器的 IP 地址 |
| m_port | 主服务器的的端口号 |
| m_epoch | 主服务器当前的配置纪元 |
对于监视同一个服务器的多个 Sentinel 来说,一个 Sentinel 发送的信息会被其他 Sentinel 接收到,这些信息会被用于更新其他 Sentinel 对发送信息 Sentinel 的认知,也会被用于更新其他 Sentinel 对被监视服务器的认知。
# 13.Sentinel 接收消息
Sentinel 接收来自主服务器和从服务器的频道信息
建立订阅连接后,Sentinel 则会向服务器发送以下命令:
SUBCRIBE _sentinel_:hello
此订阅会持续到与服务器的连接断开,Sentinel 通过此连接接收和发送消息。
对于监视同一个服务器的多个 Sentinel,一个 Sentinel 发送的消息也会被其他 Sentinel 接收到,然后被用于更新对发送消息的 Sentinel 的认知,也会更新其监控的服务器的认知。
更新 sentinels 字典 Sentinel 的 sentinels 字典 同样监视这个主服务器的其他 Sentinel:
键:其他 Sentinel 的名字,格式为 ip:port
值:对应的 Sentinel 的实例结构
当一个 Sentinel 接收到其他 Sentinel 发来的信息时,目标 Sentinel 会提取出以下参数:
与 Sentinel 有关的参数:源 Sentinel 的 IP、端口、run_id、配置纪元
与主服务器有关的参数:源 Sentinel 正在监视的主服务器的名字、IP、端口、配置纪元
根据主服务器参数,目标 Sentinel 会在自己的 Sentinel 状态的 masters 字典查找对应的主服务器实例的结构,根据参数,检查主服务器实例结构的 Sentinels 字典中 Sentinel 实例结构是否存在:
- 存在则更新
- 不存在则源 Sentinel 刚开始监视主服务器,目标 Sentinel 创建新的实例结构,并添加到 sentinels 字典中
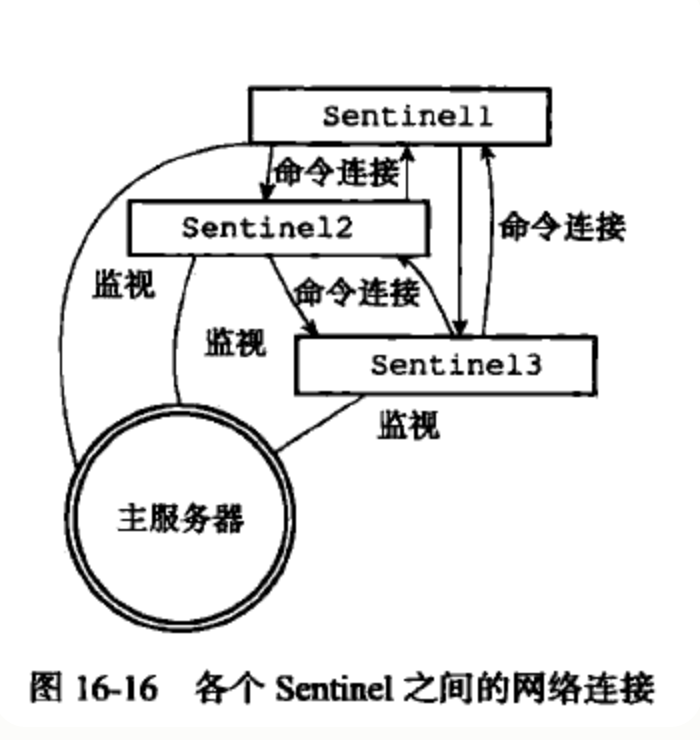
创建连向其他 Sentinel 的命令连接 当 Sentinel 通过频道信息发现新的 Sentinel 后不仅创建对应的实例结构,也会创建连向此的命令连接,最终监视同一主服务器的多个 Sentinel 将形成相互连接的网络
Sentinel 之间不会创建订阅连接
Sentinel 在连接主服务器或者从服务器时,会同时创建命令连接和订阅连接,但是在连接其他 Sentinel 时,却只会创建命令连接,而不创建订阅连接。这是因为 Sentinel 需要通过接收主服务器或者从服务器发来的频道信息来发现未知的新 Sentinel,所以才需要建立订阅连接,而相互已知的 Sentinel 只要使用命令连接来进行通信就足够了。
# 14.检测主观下线状态
默认情况下,Sentinel 会默认每秒一次的频率向所有与它创建了命令连接的实例(主服务器、从服务器、其他 Sentinel ) 发送 PING 命令,通过回复判断实例是否在线
实例对 PING 命令的回复有两种:
- 有效回复:+PONG、-LOADING、-MASTERDOWN 三种
- 无效回复:返回有效回复外的其他回复,或在指定时间内没有任何回复
Sentinel 配置文件中的 down-after-millisecond 的值为 50000 毫秒,当主服务器 master 连续 50000 毫秒内都向 Sentinel 返回无效回复,则会被标记为主观下线,对应的实例结构的 flags 被标识为 SRI_S_DOWN

down-after-millisecond 的值不仅会被 Sentinel 用来判断主服务器的主观下线状态,还会被用于判断主服务器属下的从服务器,以及所有同样监视这个主服务器的其他 Sentinel 的主观下线状态,且监视同一个主服务器的不同 Sentinel 来说,此值可能不同。
# 15.检查客观下线状态
需要特别注意的是,客观下线是主节点才有的概念;如果从节点和哨兵节点发生故障,被哨兵主观下线后,不会再有后续的客观下线和故障转移操作。
当一个主服务器被认为主观下线后,Sentinel 会询问其他监视此主服务器的 Sentinel,当接收到足够多的下线判断(主观或者客观下线)后,才会将主服务器判断为客观下线,并对主服务器执行故障转移操作。
Sentinel 使用以下命令来询问其他 Sentinel 是否同意主服务器已下线。
SENTINEL IS-master-down-by-addr <current_epoch> <run_id>

接收 SENTIENL is-master-down-by-addr 命令
目标 Sentinel 接收到源 Sentinel 发来的命令后,目标会分析提取参数,根据主服务器 IP 和端口检查主服务器是否已下线,然后向源返回一个包含三个参数的 Multi Bulk作为回复。
- <down_state>
- <leader_runid>
- <leader_epoch>

接收 SENTIENL is-master-down-by-addr 命令的回复
根据其他 Sentinel 发回的命令回复,统计同意已下线的数量,达到配置的数量则判断为客观下线,flags 标志为 SRI_O_DOWN,表示客观下线。

Sentinel配置的quorum参数判断的标志,大于等于quorum则被认为是客观下线不同的
Sentinel此参数的配置不同,即对主服务器的客观下线判断不同
flags:
- SRI_MASTER
- SRI_S_DOWN
- SRI_O_DOWN
# 16.flags 标志
在 Redis 中,这些标志(flags)与 Sentinel(哨兵)系统相关,用于监控和管理 Redis 实例的状态。Sentinel 是 Redis 的一个高可用性解决方案,用于监视 Redis 实例的健康状况,并在主从切换等情况下自动进行故障转移。
以下是这些标志的中文解释和含义:
SRI_MASTER(主节点标志): 表示一个 Redis 实例被 Sentinel 标识为主节点。主节点负责处理写操作,并管理一个或多个从节点。
SRI_S_DOWN(主节点下线标志): 当 Sentinel 认为主节点不可达时,将设置这个标志。这可能是由于网络问题、实例崩溃等引起的。
SRI_O_DOWN(主节点主观下线标志): 当 Sentinel 多个实例都认为主节点不可达时,将设置这个标志。这表示多个 Sentinel 实例都主观地认为主节点不可用。
在 Sentinel 系统中,主节点的状态由多个 Sentinel 实例共同决定,SRI_MASTER 和 SRI_S_DOWN 标志通常是在这个过程中使用的标志。一旦主节点被认为不可达,Sentinel 会根据配置的故障转移策略,选择一个合适的从节点升级为新的主节点,以保持高可用性。
需要注意的是,Sentinel 是一个独立于 Redis 服务器的系统,用于监控和管理 Redis 实例的状态。以上标志是 Sentinel 在管理 Redis 高可用性方案中使用的一部分标志,用于标识实例状态以及判断是否需要执行故障转移等操作。
# 17.选举领头 Sentinel
领头 Sentinel 对下线主服务器进行故障转移操作,需要先选举领头 Sentinel。
选举领头 Sentinel :
- 每个监视同一主服务器的
Sentinel都有资格成为领头 - 每次选举后不论成功失败,每个 Sentinel 的配置
纪元增加 1 - 一个配置纪元里,所有
Sentinel都有一次机会将某个Sentinel设置为局部领头,且设置后在此纪元不会更改 - 每个发现主服务器进入客观下线状态的
Sentinel都会要求其他将自己设置为局部领头。 - 源 Sentinel 向目标 Sentinel 发送 SENTIENL is-master-down-by-addr 命令且 runid 参数不是 * 而是自己的 runid 时表示要目标设置源为它的局部领头 Sentinel
- 设置
局部领头的规则是先到先得,后来的都被拒绝。 - 目标接收后将向源回复,其中的
leader_runid和leader_epoch记录目标的局部领头的 runid 和配置纪元 - 源接收命令的回复后取出参数,如果和自己相同则表示自己成为目标的局部领头
- 如果某个
Sentinel被半数以上设置为局部领头,则他成为领头Sentinel - 因为需要半数以上支持且只能设置一次局部领头,则领头
Sentinel只有一个 - 在指定时间内没有选出领头
Sentinel,则在一段时间后再进行选择,直到选出
# 18.哨兵模式故障转移
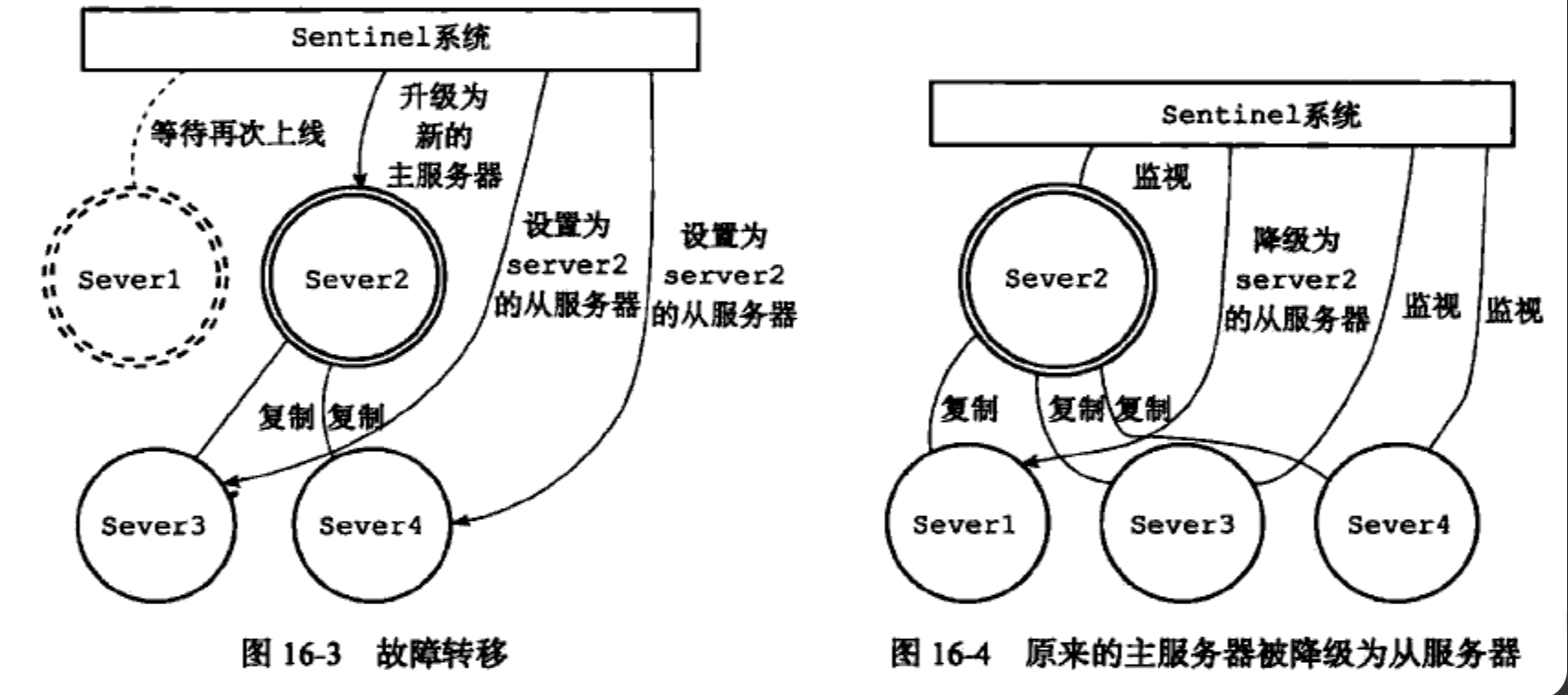
三个步骤:
选出新的主服务器: 在已下线的
主服务器的从服务器中选出一个从服务器,成为新的主服务器修改从服务器的复制目标: 让其他
从服务器改为复制新的主服务器**将旧主服务器变为从服务器:**将已下线的
主服务器设置为新的主服务器的从服务器,当重新上线时自动成为主服务器的从服务器
选出新的主服务器
挑选一个状态良好、数据完整的从服务器,发送 SLAVEOF no one 成为主服务器,领头 Sentinel 将所有属于的从服务器保存在列表中,然后按照以下规则过滤
- 删除下线或断线服务器
- 删除最近 5 秒没有回复领头 Sentinel 的 INFO 命令的服务器
- 删除与已下线主服务器连接断开超过 down-after-milliseconds * 10 毫秒的服务器
- 根据服务器的优先级排序,选出
- 如果优先级一致,选出复制偏移量最大的
- 再一致选出运行 ID 最小的
修改从服务器的复制目标 让其他从服务器复制新的主服务器,领头 Sentinel 发送 SLAVEOF 命令
将旧主服务器变为从服务器 领头 Sentinel 发送命令
# 19.哨兵模式注意事项
哨兵节点的数量应不止一个,一方面增加哨兵节点的冗余,避免哨兵本身成为高可用的瓶颈;另一方面减少对下线的误判。此外,这些不同的哨兵节点应部署在不同的物理机上。
哨兵节点的数量应该是
奇数,便于哨兵通过投票做出“决策”:领导者选举的决策、客观下线的决策等。各个哨兵节点的
配置应一致,包括硬件、参数等;此外,所有节点都应该使用 ntp 或类似服务,保证时间准确、一致。哨兵的配置提供者和通知客户端功能,需要客户端的支持才能实现,如前文所说的 Jedis;如果开发者使用的库未提供相应支持,则可能需要开发者自己实现。
当哨兵系统中的节点在 docker(或其他可能进行端口映射的软件)中部署时,应特别注意端口映射可能会导致
哨兵系统无法正常工作,因为哨兵的工作基于与其他节点的通信,而 docker 的端口映射可能导致哨兵无法连接到其他节点。例如,哨兵之间互相发现,依赖于它们对外宣称的IP和port,如果某个哨兵 A 部署在做了端口映射的docker中,那么其他哨兵使用 A 宣称的port无法连接到 A。
# 七.集群
# 1.什么是 redis 集群?
Redis 集群是一个用于分布式存储和管理数据的解决方案,它基于 Redis 数据库的开源项目。Redis 是一个内存数据库,常用于缓存、会话管理和实时分析等场景。在某些情况下,单个 Redis 服务器可能无法满足高并发和大规模数据存储的需求,这就引入了 Redis 集群。
Redis 集群通过将数据分布到多个节点(服务器)上,从而实现了数据的水平扩展和负载均衡。每个节点负责管理其中一部分数据,而整个集群则负责管理全部数据。它具有以下特点:
- 分片: Redis 集群将数据分成
多个槽(slot),每个槽可以存储一个键值对。每个节点负责管理一部分槽,使得数据在整个集群中分布均匀。 - 高可用性: Redis 集群提供了主从复制机制,每个主节点都有多个从节点。如果一个主节点发生故障,其一个从节点会被自动提升为新的主节点,从而保持数据的
可用性。 - 自动分区: 集群会自动管理数据的分区和迁移,当节点动态增加或减少时,数据会被重新分布,从而实现了自动的数据平衡。
- 客户端支持: Redis 客户端库可以自动识别集群的拓扑结构,并将请求发送到正确的节点,从而使得客户端无需手动管理多个节点。
使用 Redis 集群可以提供更高的性能、可扩展性和高可用性,适用于需要处理大量数据和高并发访问的应用场景。不过,在使用 Redis 集群之前,需要仔细考虑数据分片、容量规划、数据迁移等方面的设计和配置。
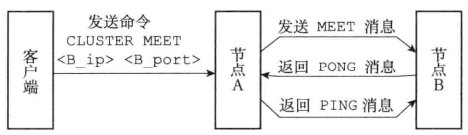
# 2.节点加入集群
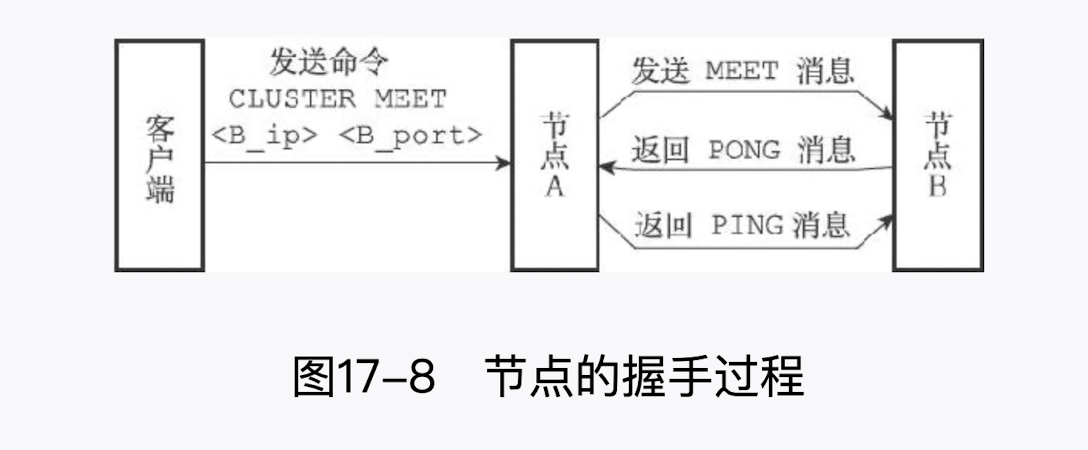
通过向节点 A 发送 CLUSTER MEET 命令,客户端可以让接收命令的节点 A 将另一个节点 B 添加到节点 A 当前所在的集群里面:
#ip和port是要被要入的节点
CLUSTER MEET <ip> <port>
2
收到命令的节点 A 将与节点 B 进行握手(hand shake),以此来确认彼此的存在,并为将来的进一步通信打好基础:
- 节点 A 会为节点 B 创建一个
clusterNode结构,并将该结构添加到自己的clusterState.nodes字典里面。 - 之后,节点 A 将根据
CLUSTER MEET命令给定的 IP 地址和端口号,向节点 B 发送一条 MEET 消息(message) - 如果一切顺利,节点 B 将接收到节点 A 发送的 MEET 消息,节点 B 会为节点 A 创建一个
clusterNode结构,并将该结构添加到自己的clusterState.nodes字典里面。 - 之后,节点 B 将向节点 A 返回一条
PONG消息。 - 如果一切顺利,节点 A 将接收到节点 B 返回的
PONG消息,通过这条PONG消息节点 A 可以知道节点 B 已经成功地接收到了自己发送的MEET消息。 - 之后,节点 A 将向节点 B 返回一条
PING消息。 - 如果一切顺利,节点 B 将接收到节点 A 返回的
PING消息,通过这条PING消息节点 B 可以知道节点 A 已经成功地接收到了自己返回的PONG消息,握手完成。
之后,节点 A 会将节点 B 的信息通过 Gossip 协议传播给集群中的其他节点,让其他节点也与节点 B 进行握手,最终,经过一段时间之后,节点 B 会被集群中的所有节点认识。
节点加入到集群
# 3.启动节点
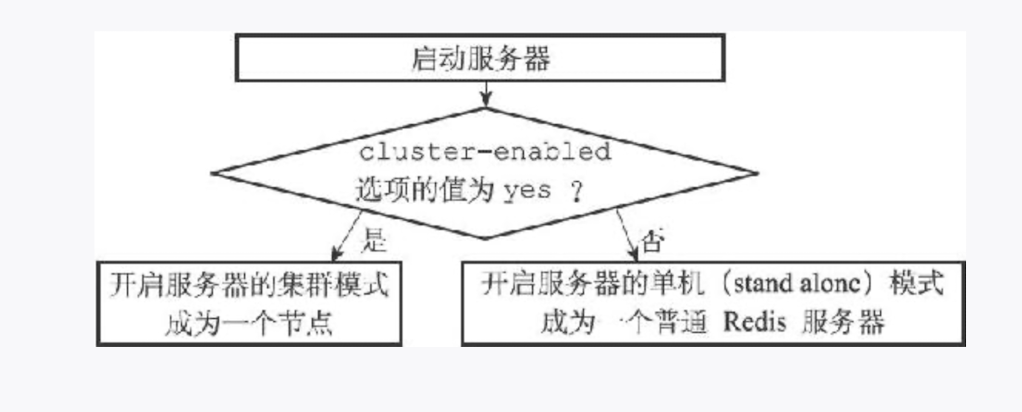
一个节点就是一个运行在集群模式下的 Redis 服务器,Redis 服务器在启动时会根据 cluster-enabled 配置选项是否为 yes 来决定是否开启服务器的集群模式
# 4.redis 节点的功能
节点会继续使用文件事件处理器来处理命令设请求和返回命令回复。
节点会继续使用时间事件处理器来执行
serverCron函数,而serverCron函数又会调用集群模式特有的clusterCron函数。clusterCron函数负责执行在集群模式下需要执行的常规操作,例如,向集群中的其他节点发送Gossip消息,检查节点是否断线,或者检查是否需要对下线节点进行自动故障转移等。节点会继续使用数据库来保存键值对数据,键值对依然会是各种不同类型的对象。
节点会继续使用
RDB持久化模块和AOF持久化模块来执行持久化工作。节点会继续使用发布与订阅模块来执行
PUBLISH、SUBSCRIBE等命令。节点会继续使用复制模块来进行节点的复制工作。
节点会继续使用
Lua脚本环境来执行客户端输入的Lua脚本。
# 5.集群数据结构
clusterNode结构保存了一个节点的当前状态,比如节点的创建时间、节点的名字、节点当前的配置纪元、节点的IP 地址和端口号等等。每个节点都会使用一个
clusterNode结构来记录自己的状态,并为集群中的所有其他节点(包括主节点和从节点)都创建一个相应的clusterNode结构,以此来记录其他节点的状态;
typedef struct clusterNode {
mstime_t ctime; /* Node object creation time. */
char name[REDIS_CLUSTER_NAMELEN]; /* Node name, hex string, sha1-size */
int flags; /* REDIS_NODE_... */
uint64_t configEpoch; /* Last configEpoch observed for this node */
unsigned char slots[REDIS_CLUSTER_SLOTS/8]; /* slots handled by this node */
int numslots; /* Number of slots handled by this node */
int numslaves; /* Number of slave nodes, if this is a master */
struct clusterNode **slaves; /* pointers to slave nodes */
struct clusterNode *slaveof; /* pointer to the master node */
mstime_t ping_sent; /* Unix time we sent latest ping */
mstime_t pong_received; /* Unix time we received the pong */
mstime_t fail_time; /* Unix time when FAIL flag was set */
mstime_t voted_time; /* Last time we voted for a slave of this master */
mstime_t repl_offset_time; /* Unix time we received offset for this node */
PORT_LONGLONG repl_offset; /* Last known repl offset for this node. */
char ip[REDIS_IP_STR_LEN]; /* Latest known IP address of this node */
int port; /* Latest known port of this node */
clusterLink *link; /* TCP/IP link with this node */
list *fail_reports; /* List of nodes signaling this as failing */
} clusterNode;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
clusterNode 结构的 link 属性是一个 clusterLink 结构,该结构保存了连接节点所需的有关信息,比如套接字描述符,输入缓冲区和输出缓冲区。
# 6.clusterLink 结构
clusterNode 结构的 link 属性是一个 clusterLink 结构,该结构保存了连接节点所需的有关信息,比如套接字描述符,输入缓冲区和输出缓冲区。
typedef struct clusterLink {
//连接的创建时间
mstime_t ctime;
// TCP 套接字描述符, file descriptor 文件描述符
int fd;
//输出缓冲区,保存着等待发送给其他节点的消息(message )。
sds sndbuf;
//输入缓冲区,保存着从其他节点接收到的消息。
sds rcvbuf;
//与这个连接相关联的节点,如果没有的话就为NULL
struct clusterNode *node;
} clusterLink;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
redisClient 结构和 clusterLink 结构的相同和不同
redisClient 结构和 clusterLink 结构都有自己的套接字描述符和输入、输出缓冲区,这两个结构的区别在于,redisClient 结构中的套接字和缓冲区是用于连接客户端的,而 clusterlink 结构中的套接字和缓冲区则是用于连接节点的。
# 7.clusterState 结构
每个节点都保存着一个 clusterState 结构, 这个结构记录了在当前节点的视角下,集群目前所处的状态,例如集群是在线还是下线,集群包含多少个节点,集群当前的配置纪元,诸如此类:
typedef struct clusterState {
//指向当前节点的指针
clusterNode *myself;
//集群当前的配置纪元,用于实现故障转移
uint64_t currentEpoch;
//集群当前的状态:是在线还是下线
int state;
//集群中至少处理着一个槽的节点的数量
int size;
//集群节点名单(包括myself 节点)
//字典的键为节点的名字,字典的值为节点对应的clusterNode 结构
dict *nodes;
// ...
} clusterState;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18

# 8.集群槽介绍
在 Redis 集群中,槽(slots)是数据分片的基本单位。Redis 集群将整个数据集划分为一定数量的槽,每个槽可以容纳一个键值对。这种数据分片方式可以让集群中的多个节点共同管理和存储数据,实现水平扩展和负载均衡。以下是关于 Redis 集群槽的一些重要信息:
- 槽的数量: Redis 集群中默认有 16384 个槽。这个数量是固定的,不会随着集群的扩展而改变。
- 数据分布: 每个槽都有一个唯一的整数标识,从 0 到 16383。在集群中,每个
节点负责管理一定数量的槽。当数据被存储到集群中时,Redis 根据键的哈希值将数据映射到相应的槽中。 - 节点间数据迁移: 当节点被添加到集群中或从集群中移除时,槽的分布可能会发生变化。Redis 集群会自动进行数据迁移,将槽从一个节点迁移到另一个节点,以保持数据的平衡。这个过程是自动的,不需要手动干预。
- 槽的状态: 槽可以有不同的状态,包括未分配、已分配但未加载、已加载等。未分配的槽表示没有节点负责管理它们。已分配但未加载的槽表示有节点负责管理它们,但数据尚未被加载到节点的内存中。已加载的槽表示数据已经在节点的内存中就绪,可以被访问。
- 槽的查询和管理: 在使用 Redis 集群时,客户端可以通过查询节点的槽信息来了解数据的分布情况。Redis 命令
CLUSTER SLOTS可以用于获取有关集群节点和槽的详细信息。
# 9.集群槽指派
通过向节点发送 CLUSTER ADDSLOTS 命令,我们可以将一个或多个槽指派(assign) 给节点负责:
127.0.0.1:7000> CLUSTER ADDSLOTS 0 1 2 3 4... 5000
OK
127.0.0.1:7000> CLUSTER NODES
2
3
记录指派信息
struct clusterNode {
//一个槽占8个二进制位
unsigned char slots[16384/8];
//负责处理槽的数量,也就是二进制1的个数,会用bitmap计算
int numslots;
// ...
};
2
3
4
5
6
7
clusterNode 结构的 slots 属性和 numslot 属性记录了节点负责处理哪些槽。
· 属性是一个二进制位数组(bit array),这个数组的长度为 16384/8=2048 个字节,共包含 16384 个二进制位。
Redis 以 0 为起始索引,16383 为终止索引,对 slots 数组中的 16384 个二进制位进行编号,并根据索引 i 上的二进制位的值来判断节点是否负责处理槽 i:
- 如果
slots数组在索引 i 上的二进制位的值为1,那么表示节点负责处理槽 i。 - 如果
slots数组在索引 i 上的二进制位的值为0,那么表示节点不负责处理槽 i。
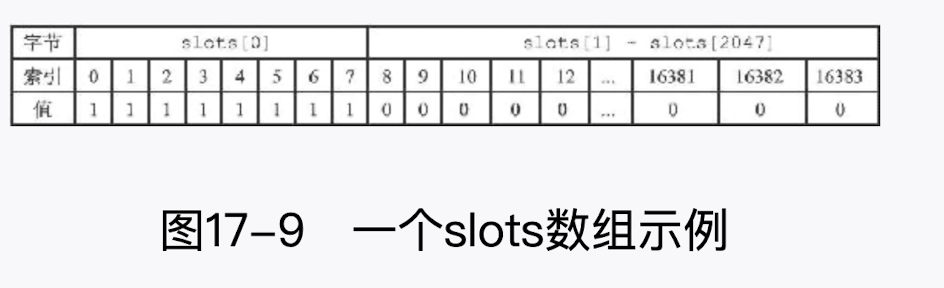
图 17-9 展示了一个 slots 数组示例,这个数组索引 0 至索引 7 上的二进制位的值都为 1,其余所有二进制位的值都为 0,这表示该节点负责处理槽 0 至槽 7。
因为取出和设置 slots 数组中的任意一个二进制位的值的复杂度仅为O(1),所以对于一个给定节点的 slots 数组来说,程序检查节点是否负责处理某个槽,又或者将某个槽指派给节点负责,这两个动作的复杂度都是 O (1)
至于 numslots 属性则记录节点负责处理的槽的数量,也即是 slots 数组中值为 1 的二进制位的数量。
传播节点的槽指派信息
一个节点除了会将自己负责处理的槽记录在 clusterNode 结构的 slots 属性和 numslots 属性之外,它还会将自己的 slots 数组通过消息发送给集群中的其他节点,以此来告知其他节点自己目前负责处理哪些槽。
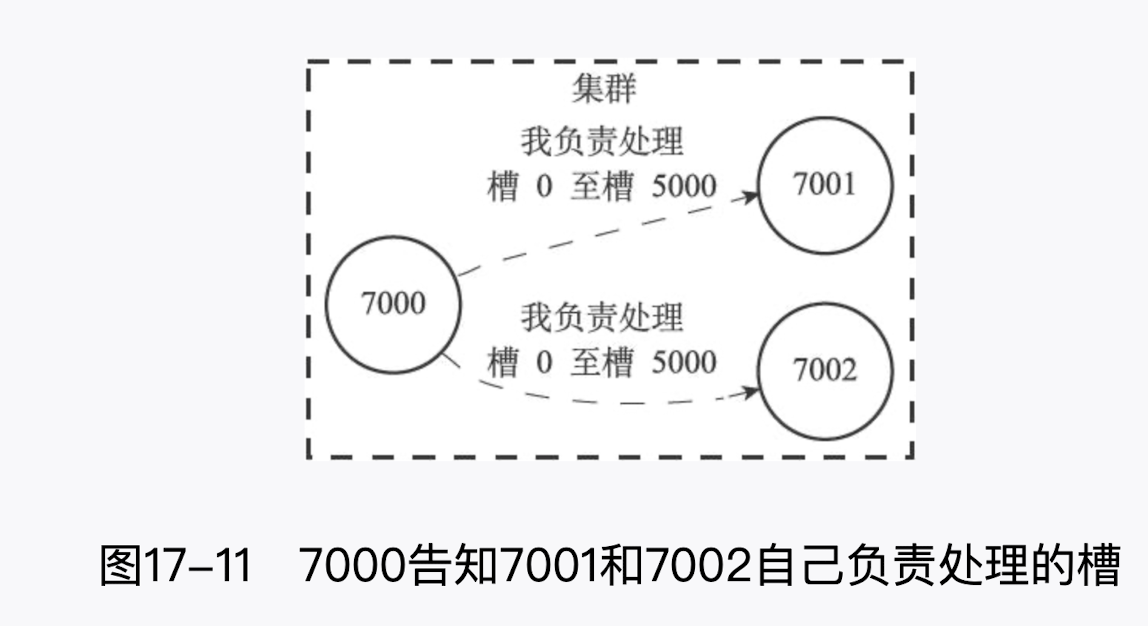
当节点 A 通过消息从节点 B 那里接收到节点 B 的 slots 数组时,节点 A 会在自己的 clusterState.nodes 字典中查找节点 B 对应的 clusterNode 结构,并对结构中的 slots 数组进行保存或者更新。
因为集群中的每个节点都会将自己的 slots 数组通过消息发送给集群中的其他节点,并且每个接收到 slots 数组的节点都会将数组保存到相应节点的 clusterNode 结构里面,因此,集群中的每个节点都会知道数据库中的 16384 个槽分别被指派给了集群中的哪些节点。
记录集群所有槽的指派信息
typedef struct clusterState {
// ...
clusterNode *slots[16384];
// ...
} clusterState;
2
3
4
5
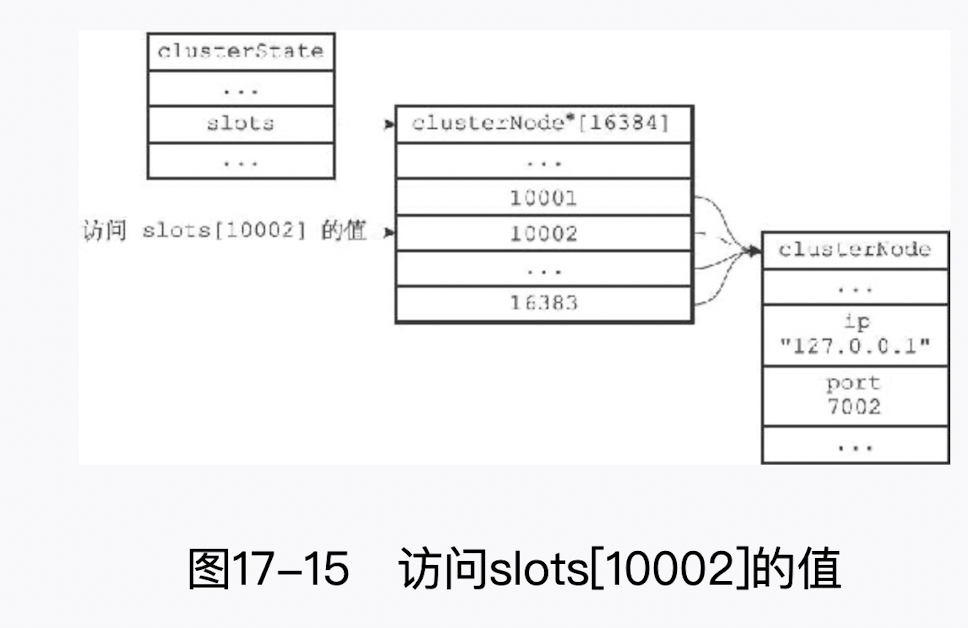
clusterState 结构中的 slots 数组记录了集群中所有 16384 个槽的指派信息;
slots 数组包含 16384 个项,每个数组项都是一个指向 clusterNode 结构的指针:
- 如果 slots[i]指针指向 NULL, 那么表示槽 i 尚未指派给任何节点。
- 如果 slots[i]指针指向一个
clusterNode结构,那么表示槽 i 已经指派给了clusterNode结构所代表的节点。
如果只将槽指派信息保存在各个节点的 clusterNode slots 数组里,会出现一些无法高效地解决的问题,而 clusterState.slots 数组 的存在解决了这些问题:
如果节点只使用 clusterNode slots 数组来记录槽的指派信息,那么为了知道槽 i 是否已经被指派,或者槽 i 被指派给了哪个节点,程序需要遍历clusterState.nodes 字典中的所有 clusterNode 结构,检查这些结构的 slots 数组,直到找到负责处理槽 i 的节点为止,这个过程的复杂度为 O (N),其中 N 为 clusterState.nodes 字典保存的 clusterNode 结构的数量。而通过将所有槽的指派信息保存在 clusterState.slots 数组里面,程序要检查槽 i 是否已经被指派,又或者取得负责处理槽 i 的节点,只需要访问 clusterState. slots[i]的值即可,这个操作的复杂度仅为 O(1)

# 10.两个 slots 的区别?
clusterState 和 clusterNode 的 slots 的区别
要说明的一点是,虽然 clusterState.slots 数组记录了集群中所有槽的指派信息,但使用 clusterNode 结构的 slots 数组来记录单个节点的槽指派信息仍然是有必要的。
因为当程序需要将某个节点的槽指派信息通过消息发送给其他节点时,程序只需要将相应节点的 clusterNode.slots 数组整个发送出去就可以了。 另一方面,如果 Redis 不使用 clusterNode.slots 数组,而单独使用 clusterState.slots 数组的话,那么每次要将节点 A 的槽指派信息传播给其他节点时,程序必须先遍历整个 clusterState.slots 数组,记录节点 A 负责处理哪些槽,然后才能发送节点 A 的槽指派信息,这比直接发送 clusterNode.slots 数组要麻烦和低效得多。clusterState.slots 数组记录了集群中所有槽的指派信息,而 clusterNode.slots 数组只记录了 clusterNode 结构所代表的节点的槽指派信息,这是两个 slots 数组的关键区别所在。
# 11.CLUSTER ADDSLOTS
CLUSTER ADDSLOTS 命令接受一个或多个槽作为参数,并将所有输入的槽指派给接收该命令的节点负责;
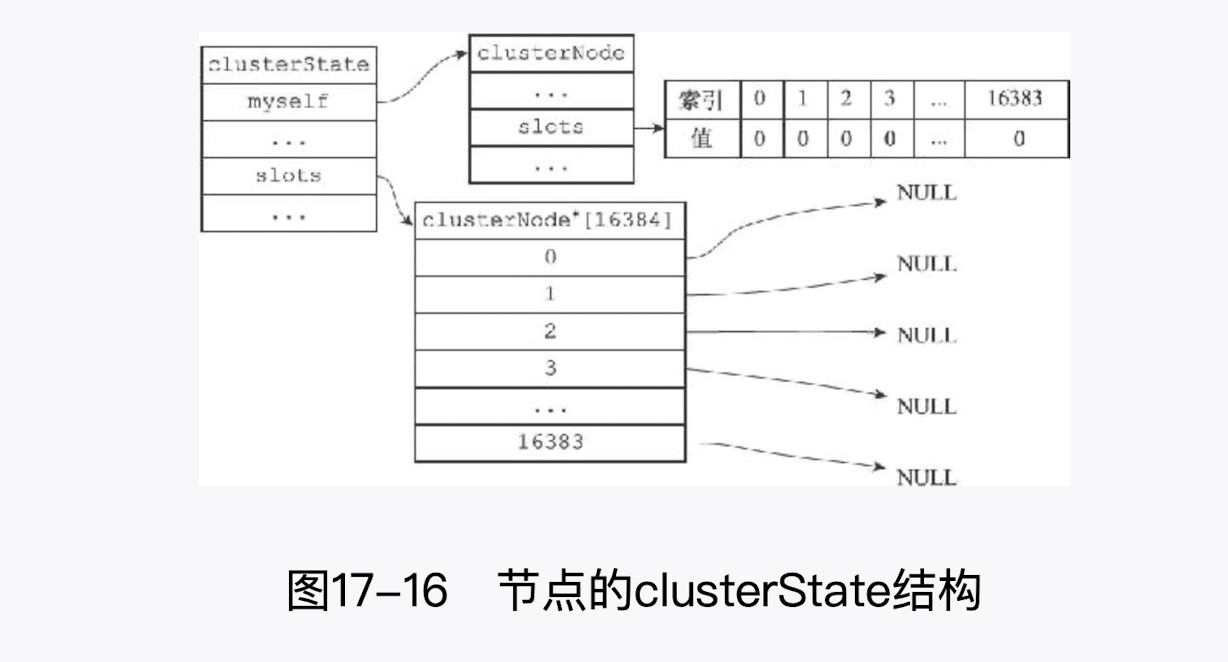
对 1,2 执行命令后
clusterState.slots数组在索引 1 和索引 2 上的指针指向了代表当前节点的clusterNode结构。- 并且
clusterNode.slots数组在索引 1 和索引 2.上的位被设置成了 1。 - 最后,在
CLUSTER ADDSLOTS命令执行完毕之后,节点会通过发送消息告知集群中的其他节点,自己目前正在负责处理哪些槽。
# 12.客户端执行命令
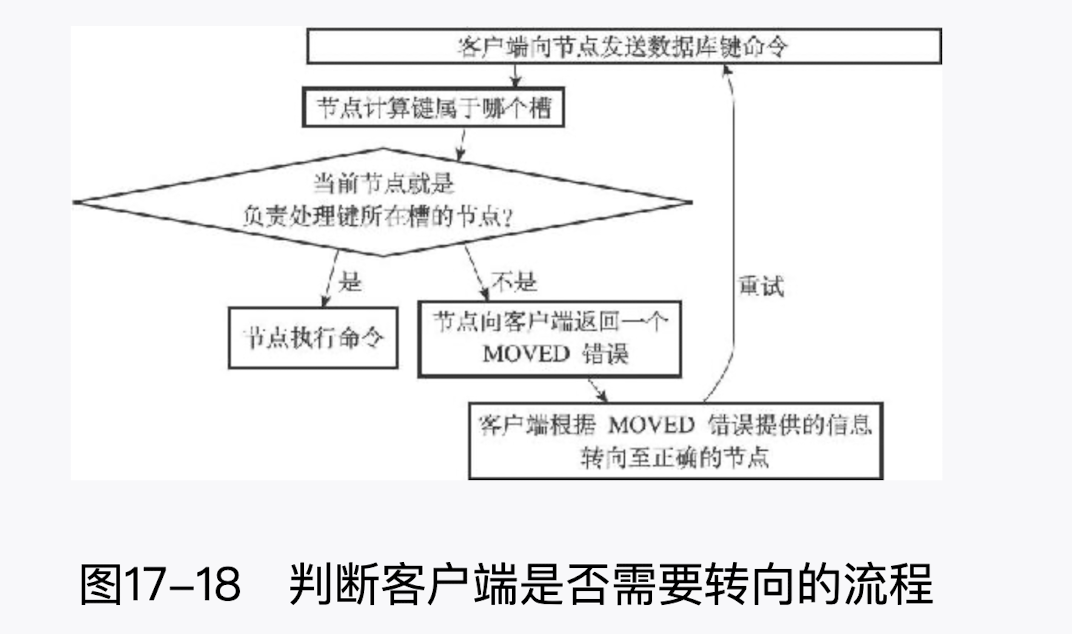
在对数据库中的 16384 个槽都进行了指派之后,集群就会进入上线状态,这时客户端就可以向集群中的节点发送数据命令了。当客户端向节点发送与数据库键有关的命令时,接收命令的节点会计算出命令要处理的数据库键属于哪个槽,并检查这个槽是否指派给了自己。
- 如果键所在的槽正好就指派给了当前节点,那么节点直接执行这个命令。
- 如果键所在的槽并没有指派给当前节点,那么节点会向客户端返回一个
MOVED错误,指引客户端转向(redirect)至正确的节点,并再次发送之前想要执行的命令。
# 13.key 与槽的关系
edis 集群中有 16384 个槽,如果 key 的数量多于 16384 是如何存储的?
在 Redis 集群中,每个节点负责管理一部分槽(slots),总共有 16384 个槽。当 key 的数量多于 16384 时,Redis 集群会使用哈希槽(hash slot)来确定 key 属于哪个槽,并将数据存储在相应的节点上。
具体来说,Redis 使用 CRC16 校验和算法来将 key 映射到一个 0 到 16383 的槽编号。这样,无论 key 的数量有多少,它们都会被映射到这些槽中。每个节点都会维护一部分槽的信息,这些槽可能分布在不同的节点上。
当一个节点需要获取一个 key 的值时,它会首先计算该 key 属于哪个槽,然后查找负责该槽的节点,并从该节点获取数据。这就实现了分布式存储和访问,使得 Redis 集群能够扩展到更大规模。
需要注意的是,当 Redis 集群中的节点数量发生变化(节点的添加、删除等),槽的分配会根据一定的策略进行重新平衡,以保证数据在集群中的均匀分布。
即使 key 的数量多于 16384,Redis 集群仍然可以通过哈希槽的映射机制来将数据分布在不同的节点上,实现高可用性和横向扩展。
# 14.计算键所属槽
节点使用以下算法来计算给定键 key 属于哪个槽:
def slot_ number(key):
return CRC16(key) & 16383
2
其中 CRC16 (key) 语句用于计算键 key 的 CRC-16 校验和,而&16383 语句则用于计算出一个介于 0 至 16383 之间的整数作为键 key 的槽号。使用命令可以查看一个给定键属于哪个槽:
CLUSTER KEYSLOT <key>
判断槽节点是否自己负责
当节点计算出键所属的槽 i 之后,节点就会检查自己在clusterState.slots 数组中的项 i,判断键所在的槽是否由自己负责:
- 如果 clusterState.slots[i]等于 clusterState.myself,那么说明槽 i 由当前节点负责,节点可以执行客户端发送的命令。
- 如果 clusterState.slots[i]不等 于 clusterState.myself,那么说明槽 i 并非由当前节点负责,节点会根据 clusterState.slots[i]指向的 clusterNode 结构所记录的节点 IP 和端口号,向客户端返回
MOVED错误,指引客户端转向至正在处理槽 i 的节点。
moved 错误
- 相当于 web 中的重定向
- 集群模式下是隐藏的,可以打印跳转信息,看不见错误
- 单机模式会抛出
moved错误
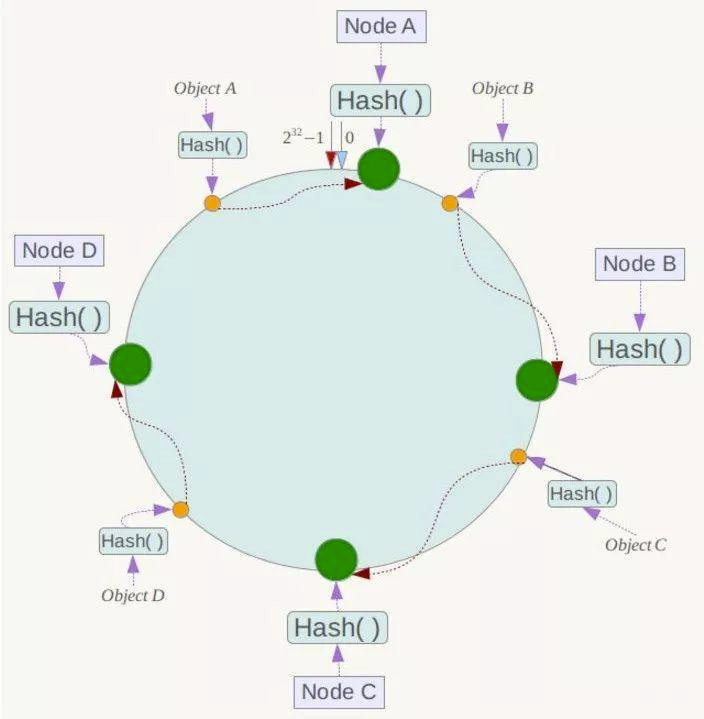
# 15.一致性哈希算法
一致性哈希算法为的就是解决分布式缓存的问题。
在一致性哈希算法中,整个哈希空间是一个虚拟圆环。
- 对于各个 Object,它所真正的存储位置是按顺时针找到的第一个存储节点。例如 Object A 顺时针找到的第一个节点是 Node A,所以 Node A 负责存储 Object A,Object B 存储在 Node B。
- 假设 Node C 节点挂掉了,Object C 的存储丢失,那么它顺时针找到的最新节点是 Node D。也就是说 Node C 挂掉了,受影响仅仅包括 Node B 到 Node C 区间的数据,并且这些数据会转移到 Node D 进行存储。
- 一致性哈希算法对于容错性和扩展性有非常好的支持。但一致性哈希算法也有一个严重的问题,就是数据倾斜
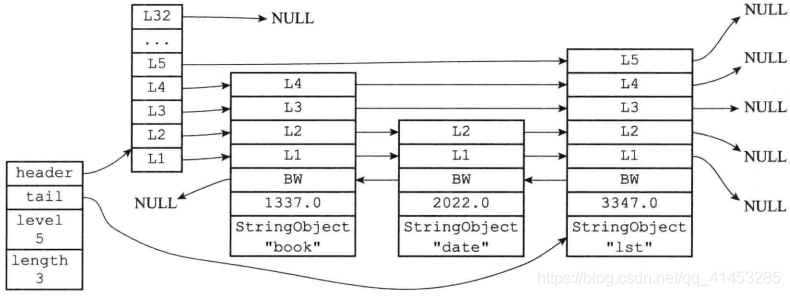
# 16.节点数据库
- 集群节点只能使用
0 号数据库 - 另外,除了将键值对保存在数据库里面之外,节点还会用 clusterState 结构中的
slots_to_keys跳跃表来保存槽和键之间的关系。 - 键的分值和槽的关系(相对应)
typedef struct clusterState {
/***/
zskiplist *slots_to_keys;
/***/
} clusterState;
2
3
4
5
slots_to_keys 跳跃表每个节点的分值(score)都是一个槽号,而每个节点的成员(member)都是一个数据库键:
- 每当节点往数据库中添加一个新的键值对时,节点就会将这个键以及键的槽号关联到
slots_to_keys跳跃表。 - 当节点删除数据库中的某个键值对时,节点就会在
slots_to_keys跳跃表解除被删除键与槽号的关联。
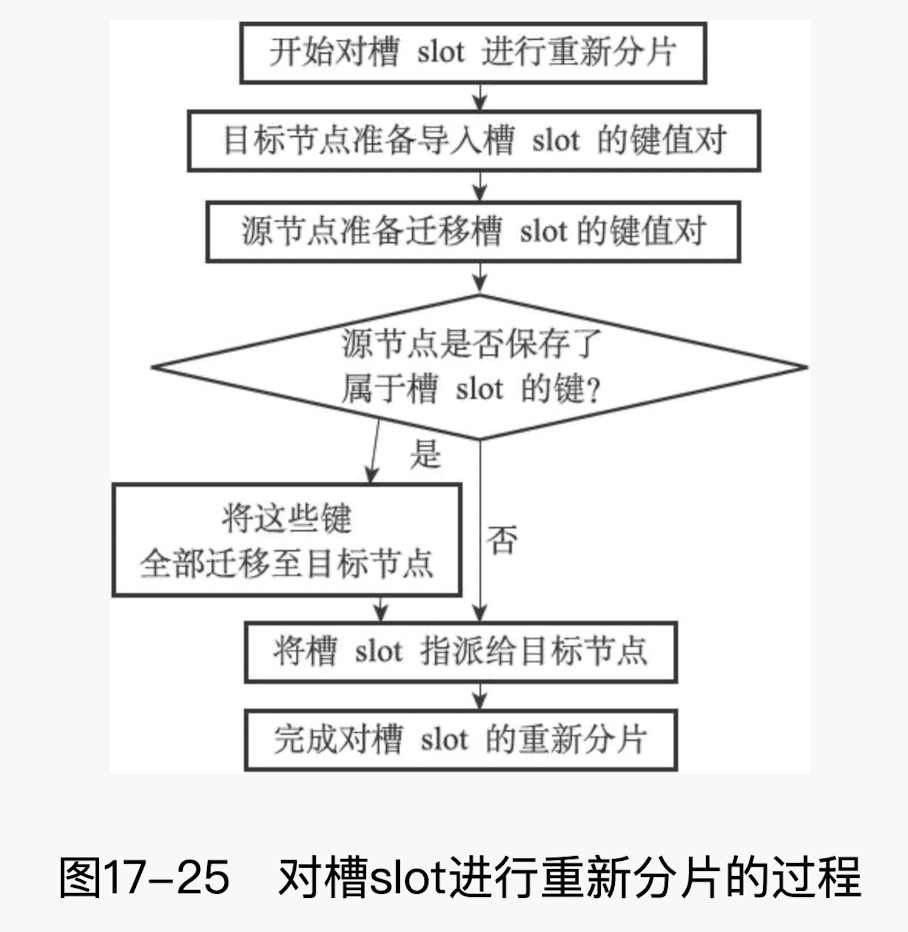
# 17.重新分片
Redis 集群的重新分片操作可以将任意数量已经指派给某个节点(源节点)的槽改为指派给另一个节点(目标节点) ,并且相关槽所属的键值对也会从源节点被移动到目标节点。
重新分片操作可以在线(online) 进行,在重新分片的过程中,集群不需要下线,并且源节点和目标节点都可以继续处理命令请求。
重新分片原理
Redis 集群的重新分片操作是由 Redis 的集群管理软件 redis-trib 负责执行的,Redis 提供了进行重新分片所需的所有命令,而 redis-trib 则通过向源节点和目标节点发送命令来进行重新分片操作。
redis-trib 対集群的単个槽 slot 迸行重新分片的歩驟如下:
- redis-trib 対
目标节点发送 CLUSTER SETSLOTIMPORTING<source_id/> 命令,让目标节点准备好从源节点导入(import) 属于槽 slot 的键値対 。 - redis-trib 対
源节点发送 CLUSTE R SETSLOTMIGRATING<target_id/> 命令,沚源节点准备好将属于槽 slot 的鍵値対迁移(migrate) 至目标节点。 - redis-trib 向源节点发送 CLUSTER GETKEYSINSLOT
命令,获得最多 count 个属于槽 slot 的鍵値対的鍵名(key name)。 - 対于歩驟 3 获得的毎个键名,redis-trib 都向源节点发送一个 MIGRATE<target* ip/><target_port <key* name/>0
命令,將被选中的键原子地从源节点迁移至目标节点。
# 18.ASK 错误
ASKING 命令功能:唯一要做的就是打开发送该命令的客户端的 REDIS_ASKING 标识
在进行重新分片期间,源节点向目标节点迁移一个槽的过程中,可能会出现这样一种情况,属于被迁移槽的一部分键值对保存在源节点里面,而另一部分键值对则保存在目标节点里面。
当客户端向源节点发送一个与数据库键有关的命令,并且命令要处理的数据库键恰好就属于正在被迁移的槽时:
源节点会先在自己的数据库里面查找指定的键,如果找到的话,就直接执行客户端发送的命令。
相反地,如果源节点没能在自己的数据库里面找到指定的键,那么这个键有可能已经被迁移到了目标节点,源节点将向客户端返回一个 ASK 错误,指引客户端转向正在导入槽的目标节点,并再次发送之前想要执行的命令。
# 19.ASK 和 MOVED 的区别
ASK 错误和 MOVED 错误都会导致客户端转向,它们的区别在于:
MOVED错误代表槽的负责权已经从一个节点转移到了另一个节点:在客户端收到关于槽 i 的 MOVED 错误之后,客户端每次遇到关于槽 i 的命令请求时,都可以直接将命令请求发送至 MOVED 错误所指向的节点,因为该节点就是目前负责槽 i 的节点。- 与此相反,
ASK错误只是两个节点在迁移槽的过程中使用的一种临时措施:在客户端收到关于槽 i 的ASK错误之后,客户端只会在接下来的一次命令请求中将关于槽 i 的命令请求发送至ASK错误所指示的节点,但这种转向不会对客户端今后发送关于槽 i 的命令请求产生任何影响,客户端仍然会将关于槽 i 的命令请求发送至目前负责处理槽 i 的节点,除非ASK错误再次出现。
# 20.集群的复制
Redis 集群中的节点分为主节点(master)和从节点(slave) ,其中主节点用于处理槽,而从节点则用于复制某个主节点,并在被复制的主节点下线时,代替下线主节点继续处理命令请求。
设置从节点
CLUSTER REPLICATE <node_ id>
可以让接收命令的节点成为 node_id 所指定节点的从节点,并开始对主节点进行复制:
接收到该命令的节点首先会在自己的 clusterState.nodes 字典中找到
node_id所对应节点的 clusterNode 结构,并将自己的 clusterState.myself. slaveof 指针指向这个结构,以此来记录这个节点正在复制的主节点。然后节点会修改自己在 clusterState.myself.flags 中的属性,关闭原本的
REDIS_NODE_MASTER标识,打开REDIS_NODE_SLAVE标识,表示这个节点已经由原来的主节点变成了从节点。最后,节点会调用复制代码,并根据 clusterState.myself.slaveof 指向的
clusterNode结构所保存的 IP 地址和端口号,对主节点进行复制。因为节点的复制功能和单机 Redis 服务器的复制功能使用了相同的代码,所以让从节点复制主节点相当于向从节点发送命令SLAVEOF。
# 21.复制信息的传递
- 概念:一个节点成为从节点,并开始复制某个主节点这一信息会通过消息发送给
集群中的其他节点,最终集群中的所有节点都会知道某个从节点正在复制某个主节点。 - 集群中的所有节点都会在代表主节点的
clusterNode结构的slaves属性和numslaves属性中记录正在复制这个主节点的从节点名单。
struct clusterNode {
// ...
//正在复制这个主节点的从节点数量
int numslaves;
// 一个数组
//每个数组项指向一个正在复制这个主节点的从节点的clusterNode 结构
struct clusterNode **slaves;
// ...
};
2
3
4
5
6
7
8
9
10
# 22.集群故障转移
故障检查
集群中的每个节点都会定期地向集群中的其他节点发送 PING 消息,以此来检测对方是否在线,如果接收 PING 消息的节点没有在规定的时间内,向发送 PING 消息的节点返回 PONG 消息,那么发送 PING 消息的节点就会将接收 PING 消息的节点标记为疑似下线(probable fail, PFAIL )
- REDIS NODE MASTER 标识 master 节点
- REDIS NODE PFAIL 标识节点下线


故障转移
当一个从节点发现自己正在复制的主节点进入了已下线状态时,从节点将开始对下线主节点进行故障转移,以下是故障转移的执行步骤:
- 在复制下线主节点的所有从节点里面,会有一个
从节点被选中。 - 被选中的从节点会执行
SLAVEOF no one命令, 成为新的主节点。 - 新的主节点会撤销所有对已下线主节点的
槽指派,并将这些槽全部指派给自己。 - 新的主节点向集群广播一条
PONG消息,这条PONG消息可以让集群中的其他节点立即知道这个节点已经由从节点变成了主节点,并且这个主节点已经接管了原本由已下线节点负责处理的槽。 新的主节点开始接收和自己负责处理的槽有关的命令请求,故障转移完成。
# 23.选举新的主节点
新的主节点是通过选举产生的,Redis 中是通过 currentEpoch 和 configEpoch 来解决这些信息更新问题,epoch 的概念与 raft 协议中的 epoch 类似,表示逻辑时钟,每次集群状态更新之后,epoch 都会+1,谁的 epoch 大,谁的 gossip 消息就可信。
currentEpoch 表示当前集群的 epoch,configEpoch 表示当前节点看到的其他节点的 epoch。
以下是集群选举新的主节点的方法:
- 集群的
配置纪元是一个自增计数器,它的初始值为0 - 当集群里的某个节点开始一次故障转移操作时,集群配置纪元的值会被增一
- 对于每个配置纪元,集群里每个负责处理槽的主节点都有一次投票的机会,而第一个向主节点要求投票的从节点将获得主节点的投票
- 当从节点发现自己正在复制的主节点进入已下线状态时,从节点会向集群广播一条消息, 要求所有收到这条消息、并且具有投票权的主节点向这个从节点投票,
CLUSTERMSG_TYPE_FAILOVER_AUTH_REQUEST消息 - 如果一个主节点具有投票权(它正在负责处理槽),并且这个主节点尚未投票给其他从节点,那么主节点将向要求投票的从节点返回一条
CLUSTERMSG_TYPE_FAILOVER_AUTH_ACK消息,表示这个主节点支持从节点成为新的主节点 - 每个参与选举的
从节点都会接收CLUSTERMSG_TYPE_FAILOVER_AUTH_ACK消息,并根据自己收到了多少条这种消息来统计自己获得了多少主节点的支持 - 如果集群里有 N 个具有投票权的
主节点,那么当一个从节点收集到大于等于N/2+1张 支持票时,这个从节点就会当选为新的主节点 - 因为在每一个配置纪元里面,每个具有投票权的
主节点只能投一次票,所以如果有N 个主节点进行投票,那么具有大于等于 N/2+1 张支持票的从节点只会有一个,这确保了新的 主节点只会有一个 - 如果在一个配置纪元里面没有从节点能收集到足够多的支持票,那么集群进入一个
新的配置纪元,并再次进行选举,直到选出新的主节点为止
这个选举新主节点的方法和前面文章介绍的选举领头 Sentinel 的方法非常相似,因为两者都是基于 Raft 算法的领头选举(leader election)方法来实现的
# 24.redis 消息
集群中的各个节点通过发送和接收消息(message) 来进行通信,我们称发送消息的节点为发送者(sender), 接收消息的节点为接收者(receiver),节点中的消息分为 5 种,消息有消息头和正文组成:
- MEET 消息:当发送者接到客户端发送的 CLUSTER MEET 命令时,发送者会向接收者 发送 MEET 消息,请求接收者加入到发送者当前所处的集群里面
- PING 消息:集群里的每个节点默认每隔一秒钟就会从已知节点列表中随机选出五个节 点,然后对这五个节点中最长时间没有发送过 PING 消息的节点发送 PING 消息,以此来检测 被选中的节点是否在线。除此之外,如果节点 A 最后一次收到节点 B 发送的 PONG 消息的时 间,距离当前时间已经超过了节点 A 的 cluster-node-timeout 选项设置时长的一半,那么节点 A 也会向节点 B 发送 PING 消息,这可以防止节点 A 因为长时间没有随机选中节点 B 作为 PING 消 息的发送对象而导致对节点 B 的信息更新滞后
- PONG 消息:当接收者收到发送者发来的 MEET 消息或者 PING 消息时,为了向发送者 确认这条 MEET 消息或者 PING 消息已到达,接收者会向发送者返回一条 PONG 消息。另外, 一个节点也可以通过向集群广播自己的 PONG 消息来让集群中的其他节点立即刷新关于这个 节点的认识,例如当一次故障转移操作成功执行之后,新的主节点会向集群广播一条 PONG 消息,以此来让集群中的其他节点立即知道这个节点已经变成了主节点,并且接管了已下线 节点负责的槽
- FAIL 消息:当一个主节点 A 判断另一个主节点 B 已经进入 FAIL 状态时,节点 A 会向集群 广播一条关于节点 B 的 FAIL 消息,所有收到这条消息的节点都会立即将节点 B 标记为已下线
- PUBLISH 消息:当节点接收到一个 PUBLISH 命令时,节点会执行这个命令,并向集群 广播一条 PUBLISH 消息,所有接收到这条 PUBLISH 消息的节点都会执行相同的 PUBLISH 命 令
一条消息由**消息头(header)和消息正文(data)**组成
消息头(struct clusterMsg)
- 节点发送的所有消息都由一个消息头包裹,消息头除了包含消息正文之外,还记录了消息发送者自身的一些信息,因为这些信息也会被消息接收者用到,所以严格来讲,我们可以 认为消息头本身也是消息的一部分
- 每个消息头都由一个 cluster.h/clusterMsg 结构
typedef struct {
//消息的长度(包括这个消息头的长度和消息正文的长度)
uint32_t totlen;
//消息的类型
uint16_t type;
//消息正文包含的节点信息数量
//只在发送MEET 、PING 、PONG 这三种Gossip 协议消息时使用
uint16_t count;
//发送者所处的配置纪元
uint64_t currentEpoch;
//如果发送者是一个主节点,那么这里记录的是发送者的配置纪元
//如果发送者是一个从节点,那么这里记录的是发送者正在复制的主节点的配置纪元
uint64_t configEpoch;
//发送者的名字(ID )
char sender[REDIS_CLUSTER_NAMELEN];
//发送者目前的槽指派信息
unsigned char myslots[REDIS_CLUSTER_SLOTS/8];
//如果发送者是一个从节点,那么这里记录的是发送者正在复制的主节点的名字
//如果发送者是一个主节点,那么这里记录的是REDIS_NODE_NULL_NAME
//(一个40 字节长,值全为0 的字节数组)
char slaveof[REDIS_CLUSTER_NAMELEN];
//发送者的端口号
uint16_t port;
//发送者的标识值
uint16_t flags;
//发送者所处集群的状态
unsigned char state;
//消息的正文(或者说,内容)
union clusterMsgData data;
} clusterMsg;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
消息正文:
union clusterMsgData {
// MEET 、PING 、PONG 消息的正文
struct {
//每条MEET 、PING 、PONG 消息都包含两个
// clusterMsgDataGossip 结构
clusterMsgDataGossip gossip[1];
} ping;
// FAIL 消息的正文
struct {
clusterMsgDataFail about;
} fail;
// PUBLISH 消息的正文
struct {
clusterMsgDataPublish msg;
} publish;
//其他消息的正文...
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 25.gossip 协议
gossip 过程是由种子节点发起,当一个种子节点有状态需要更新到网络中的其他节点时,它会随机的选择周围几个节点散播消息,收到消息的节点也会重复该过程,直至最终网络中所有的节点都收到了消息。这个过程可能需要一定的时间,由于不能保证某个时刻所有的节点都收到消息,但是能够保证最终所有节点都会收到消息,因此它是一个最终一致性协议。``gossip 协议使用 PING、PONG 类型的消息。`
在 Redis 集群中,Gossip 协议用于节点之间的信息交换和集群拓扑的维护。Gossip 协议是一种去中心化的协议,每个节点都周期性地与其他节点交换信息,从而在整个集群中传播状态更新和拓扑信息。这有助于确保集群的高可用性、数据一致性和节点自动发现。
以下是 Gossip 协议在 Redis 集群中的作用:
拓扑维护: Gossip 协议使得每个节点都能了解其他节点的存在和状态。当有新节点加入或节点离开集群时,通过 Gossip 协议,其他节点会得知这些变化,从而保持集群拓扑的最新状态。
节点自动发现: 新加入的节点可以通过 Gossip 协议从集群中的其他节点获取信息,了解集群的结构和状态,而不需要人工干预来配置节点信息。
状态传播: Redis 集群中的节点会周期性地交换关于节点自身以及其他节点状态的信息。这包括节点的健康状况、槽的分配情况、主从关系等。通过 Gossip 协议,这些信息在集群中传播,帮助节点了解整个集群的状态。
高可用性: 当一个节点发现另一个节点不可达时,它可以将这个信息通过 Gossip 协议传播给其他节点。这有助于识别出故障节点,触发故障转移操作以保证高可用性。
状态同步: 当一个节点重新加入集群或者它的状态发生变化时,Gossip 协议可以帮助其他节点了解这些变化,确保集群中的节点拥有一致的视图。
Gossip 协议在 Redis 集群中扮演了关键角色,它通过节点之间的信息交换和状态传播,保持集群的拓扑、状态和数据的一致性,从而实现高可用性和自动化管理。
# 26.多数据库对比
下面是使用表格展示 Redis 高可用方案的特点,以及相关缺陷:
| 高可用方案 | 特点 | 缺陷 |
|---|---|---|
| 复制 | - 数据备份和读负载均衡 - 简单的故障恢复 | - 故障恢复需要手动干预 - 写操作无法实现负载均衡 - 存储能力受单机限制 |
| 哨兵 | - 自动化故障恢复 - 数据备份和读负载均衡 | - 写操作无法实现负载均衡 - 存储能力受单机限制 |
| 集群 | - 自动化故障恢复 - 数据备份和读写负载均衡 - 存储能力扩展 | 无 |
# 八.面试题
# 1.Redis 应用场景
Redis 是基于内存的 nosql 数据库,可以通过新建线程的形式进行持久化,不影响 Redis 单线程的读写操作
String:
- 缓存 适合用于缓存频繁查询的数据,提高访问速度。
- 定时取消订单 需要在一段时间后自动取消的订单,避免过期。
- 模拟类似于 token 这种需要设置过期时间的场景
- 简单分布式锁 控制并发访问,保证操作的原子性和一致性。
List:
- 通过 list 取最新的 N 条数据
- 唯一 id 生成全局唯一的标识符,避免重复和冲突。
Set:
- 抽奖、随机返回元素 从一组元素中随机选择,提供随机性的功能。
- 可重复抽奖
- 不可重复抽奖
Zset:
- 排行榜 用于记录用户排名情况,提供实时的排名展示。
HyperLogLog:
- pv 统计 统计页面的访问量,加速访问速度。
- uv 统计 统计独立用户数量,加速访问速度。
# 2.Redis 为什么快?
Redis 是基于内存操作的,因此它的瓶颈可能是机器的内存或者网络带宽而并非 CPU,既然 CPU 不是瓶颈,那么自然就采用单线程的解决方案了,况且使用多线程比较麻烦。但是在 Redis 4.0 中开始支持多线程了,例如后台删除等功能。
完全基于内存:绝大部分请求是纯粹的内存操作,非常快速。数据存在内存中,类似于 HashMap,查找和操作时间复杂度为 O(1)。数据结构简单:Redis 中的数据结构是专门进行设计的,对数据操作也简单。单线程:避免了不必要的上下文切换和竞争条件,无多进程/线程导致的切换消耗,无需考虑锁问题,性能稳定。多路 I/O 复用模型:使用非阻塞 I/O 和多路 I/O 复用模型,通过单线程处理多个网络连接。多线程支持(Redis 6.0):Redis 6.0 中,多线程用于处理数据读写和协议解析,但执行命令仍然保持单线程。
简单来说,Redis4.0 之前一直采用单线程的主要原因有以下三个:
- 使用单线程模型是
Redis的开发和维护更简单,因为单线程模型方便开发和调试; - 即使使用单线程模型也可以并发的处理多客户端的请求,主要使用的是
多路复用和非阻塞 IO; - 对于 Redis 系统来说,主要的性能瓶颈是
内存或者网络带宽而并非CPU。
# 3.缓存击穿-穿透-雪崩
| 问题 | 描述 | 解决方法 |
|---|---|---|
| 缓存击穿 | 指一个热点 key 过期或被删除,导致大量请求同时访问数据库。 | 1. 设置热点数据永不过期。 2. 使用互斥锁保护数据加载流程。 |
| 缓存穿透 | 恶意请求查询多个不存在于缓存和数据库中的 key,导致请求绕过缓存直接访问数据库。 | 1. 使用布隆过滤器拦截无效请求。 2. 设置空值缓存或哨兵节点。 |
| 缓存雪崩 | 缓存中大量的 key 同时过期,导致大量请求直接访问数据库。 | 1. 设置不同过期时间,避免批量失效。 2. 使用分布式缓存。 |
# 4.什么是缓存击穿?
一个并发访问量比较大的 某个key 在某个时间过期,导致所有的请求直接打在 DB 上。
解决方案
- 加锁更新,⽐如请求查询 A,发现缓存中没有,对 A 这个 key 加锁,同时去数据库查询数据,写⼊缓存,再返回给⽤户,这样后⾯的请求就可以从缓存中拿到数据了。
- 将过期时间组合写在 value 中,通过异步的⽅式不断的刷新过期时间,防⽌此类现象。
# 5.什么是缓存穿透?
一般的缓存系统,都是按照 key 去缓存查询,如果不存在对应的 value,就应该去后端系统查找(比如 DB)。一些恶意的请求会故意查询不存在的 key,请求量很大,就会对后端系统造成很大的压力,就叫做缓存穿透。
避免
- 对查询结果
为空的情况也进行缓存,缓存时间设置短一点,或者该 key 对应的数据 insert 了之后清理缓存。 - 对一定不存在的
key进行过滤。可以把所有的可能存在的 key 放到一个大的Bitmap中,查询时通过该bitmap过滤。
# 6.什么是缓存雪崩?
当缓存服务器重启或者大量缓存集中在某一个时间段失效,这样在失效的时候,会给后端系统带来很大压力。导致系统崩溃。
避免
- 在缓存失效后,通过
加锁或者队列来控制读数据库写缓存的线程数量。比如对某个 key 只允许一个线程查询数据和写缓存,其他线程等待。 - 做
二级缓存,A1 为原始缓存,A2 为拷贝缓存;A1 失效时,可以访问 A2,A1 缓存失效时间设置为短期,A2 设置为长期 不同的 key,设置不同的过期时间,让缓存失效的时间点尽量均匀。
# 7.如何处理热点 key?
处理热点键(Hot Key)是在使用 Redis 时需要特别关注的一个重要问题,因为热点键可能导致性能问题和系统负载不均衡。下面是一些处理热点键的方法:
数据分片: 将热点键分散到多个 Redis 实例或节点中,采用分片(Sharding)的方式。这样可以将热点数据均匀分布,减轻单个实例的负载压力。
缓存预热: 在系统启动或低峰期,提前加载热点数据到缓存中,以减少高峰时期对热点键的访问压力。
设置适当的过期时间: 对于热点键,可以设置较短的过期时间,以保持数据的实时性,同时避免过期键的堆积。
缓存穿透处理: 对于热点键的访问,可以在缓存中设置一个空值标记,以避免缓存穿透问题。
分布式锁: 对于某些热点操作,可以使用分布式锁来控制对热点键的并发访问,以避免出现竞态条件。
内存淘汰策略: 配置合适的内存淘汰策略,让热点数据得以保留在缓存中,而不被淘汰出去。
使用 Redis 集群: 使用 Redis 集群可以将数据分布到多个节点中,从而减轻热点键对单个节点的压力。
缓存和持久化结合: 将热点数据同时存储在内存中的缓存层和持久化存储层,这样即使缓存失效,也可以从持久化层恢复。
限流和熔断: 当热点键的请求量过大时,可以考虑采用限流和熔断策略,以保护系统的稳定性。
使用缓存代理: 在一些情况下,使用缓存代理(如 Redis Sentinel、Twemproxy)可以帮助管理热点键的访问和负载。
# 8.排行榜功能
使用 Redis 实现排行榜功能是一种常见的应用场景,通常用于记录和展示用户或物品的排名情况。以下是一种基本的方法来使用 Redis 实现排行榜功能:
选择数据结构: Redis 提供了多种数据结构,常用的有有序集合(Sorted Set)来实现排行榜功能。有序集合可以按照分数(score)进行排序,并且每个成员(member)有唯一的标识符,这非常适合用来表示排名和分数关系。
添加数据: 将用户或物品的信息作为有序集合的成员,分数用来表示排名依据(如分数高低、积分等)。可以使用 Redis 的 ZADD 命令来添加成员和分数。
ZADD leaderboard 1000 "user1" ZADD leaderboard 800 "user2" ZADD leaderboard 1200 "user3"1
2
3查询排行: 使用 Redis 的 ZREVRANGE 命令可以查询有序集合的前 N 名或指定范围内的成员,根据分数降序排列。
ZREVRANGE leaderboard 0 9 WITHSCORES1更新分数: 当用户的分数发生变化时,可以使用 ZADD 命令来更新有序集合中的分数。
ZADD leaderboard 1100 "user1"1其他操作: Redis 提供了丰富的有序集合操作,如计算排名、查找特定范围内的成员等,可以根据实际需求进行使用。
需要注意的是,以上只是一个基本的实现方法。在实际应用中,可能需要考虑数据的持久化、分页查询、排名变化的处理、并发操作等问题。此外,如果系统的规模较大,还可以考虑使用 Redis 集群来提高性能和可用性。
另外,对于更复杂的排行榜需求,你还可以考虑使用其他技术或数据库来实现,比如使用数据库进行存储,定期更新排名,或者使用其他缓存系统结合 Redis 来实现更灵活的排行榜功能。
# 9.如何实现抽奖?
抽奖是互联网 APP 热衷的一种推广、拉新的方式,节假日没有好的策划,那就抽个奖吧!一堆用户参与进来,然后随机抽取几个幸运用户给予实物/虚拟的奖品;此时,开发人员就需要写上一个抽奖的算法,来实现幸运用户的抽取;其实我们完全可以利用 Redis 的集合(Set),就能轻松实现抽奖的功能;
功能实现需要的 API
SADD key member1 [member2]:添加一个或者多个参与用户;SRANDMEMBER KEY [count]:随机返回一个或者多个用户;SPOP key:随机返回一个或者多个用户,并删除返回的用户;
SRANDMEMBER 和 SPOP 主要用于两种不同的抽奖模式,SRANDMEMBER 适用于一个用户可中奖多次的场景(就是中奖之后,不从用户池中移除,继续参与其他奖项的抽取);而 SPOP 就适用于仅能中一次的场景(一旦中奖,就将用户从用户池中移除,后续的抽奖,就不可能再抽到该用户); 通常 SPOP 会用的会比较多。
# 10.淘汰策略
//缓存淘汰策略
#define MAXMEMORY_VOLATILE_LRU ((0<<8)|MAXMEMORY_FLAG_LRU)
#define MAXMEMORY_VOLATILE_LFU ((1<<8)|MAXMEMORY_FLAG_LFU)
#define MAXMEMORY_VOLATILE_TTL (2<<8)
#define MAXMEMORY_VOLATILE_RANDOM (3<<8)
#define MAXMEMORY_ALLKEYS_LRU ((4<<8)|MAXMEMORY_FLAG_LRU|MAXMEMORY_FLAG_ALLKEYS)
#define MAXMEMORY_ALLKEYS_LFU ((5<<8)|MAXMEMORY_FLAG_LFU|MAXMEMORY_FLAG_ALLKEYS)
#define MAXMEMORY_ALLKEYS_RANDOM ((6<<8)|MAXMEMORY_FLAG_ALLKEYS)
#define MAXMEMORY_NO_EVICTION (7<<8)
2
3
4
5
6
7
8
9
一共有 8 种:
MAXMEMORY_VOLATILE_LRU:从设置了过期时间的键中根据 LRU 淘汰MAXMEMORY_VOLATILE_LFU:从设置了过期时间的键中根据 LFU 淘汰MAXMEMORY_VOLATILE_TTL:从设置了过期时间的键中根据最长生存时间淘汰MAXMEMORY_VOLATILE_RANDOM:从设置了过期时间的键中任意选择键淘汰MAXMEMORY_FLAG_LRU:从所有键中根据 LRU 淘汰MAXMEMORY_FLAG_LFU:从所有键中根据 LFU 淘汰MAXMEMORY_ALLKEYS_RANDOM:从所有键中任意选择键淘汰MAXMEMORY_NO_EVICTION:不进行键淘汰,如果内存不够,直接 OOM
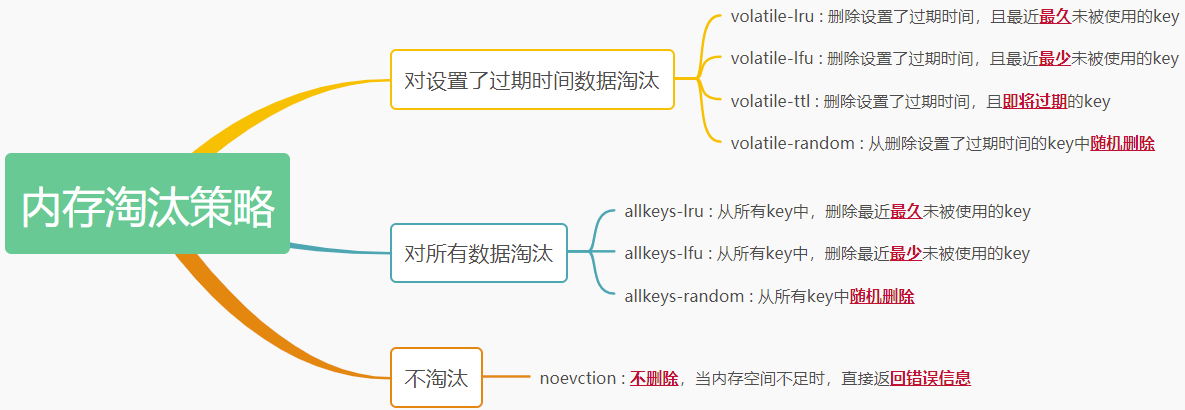
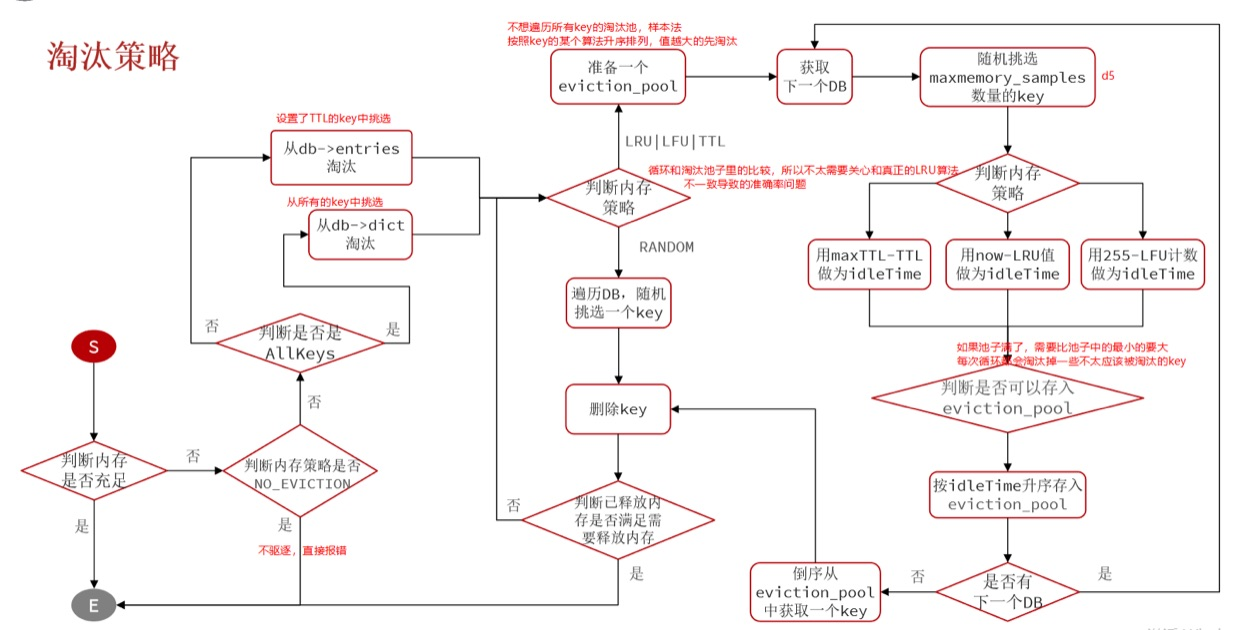
# 11.Redis 实现分布式锁?
Redis 的 SET 命令有个 NX 参数可以实现「key 不存在才插入」,所以可以用它来实现分布式锁:
- 如果 key 不存在,则显示插入成功,返回 1,可以用来表示加锁成功;
- 如果 key 存在,则会显示插入失败,返回 0,可以用来表示加锁失败。
加锁:基于 Redis 节点实现分布式锁时,对于加锁操作,我们需要满足三个条件。
- 加锁包括了读取锁变量、检查锁变量值和设置锁变量值三个操作,但需要以原子操作的方式完成,所以,我们使用 SET 命令带上 NX 选项来实现加锁;
- 锁变量需要设置过期时间,以免客户端拿到锁后发生异常,导致锁一直无法释放,所以,我们在 SET 命令执行时加上 EX/PX 选项,设置其过期时间;在
Redis 2.8版本中解决NX和PX原子性问题,这个版本加入了 set 指令的扩展参数,使得setnx 和 expire 指令可以一起执行。 - 锁变量的值需要能区分来自
不同客户端的加锁操作,以免在释放锁时,出现误释放操作,所以,我们使用 SET 命令设置锁变量值时,每个客户端设置的值是一个唯一值,用于标识客户端;
#满足这三个条件的分布式命令如下:
SET lock_key unique_value NX PX 10000
2
lock_key就是 key 键;unique_value是客户端生成的唯一的标识,区分来自不同客户端的锁操作;NX代表只在 lock_key 不存在时,才对 lock_key 进行设置操作;PX10000 表示设置 lock_key 的过期时间为 10s,这是为了避免客户端发生异常而无法释放锁。
解锁:解锁的过程就是将 lock_key 键删除(del lock_key),但不能乱删,要保证执行操作的客户端就是加锁的客户端。所以,解锁的时候,我们要先判断锁的 unique_value 是否为加锁客户端,是的话,才将 lock_key 键删除。
可以看到,解锁是有两个操作,这时就需要 Lua 脚本来保证解锁的原子性,因为 Redis 在执行 Lua 脚本时,可以以原子性的方式执行,保证了锁释放操作的原子性。
#释放锁时,先比较 unique_value 是否相等,避免锁的误释放
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end
2
3
4
5
6
这样一来,就通过使用 SETNX 命令和 Lua 脚本在 Redis 单节点上完成了分布式锁的加锁和解锁。
# 12.Redis 分布式锁有那些坑?
在使用 Redis 分布式锁时,可能会遇到一些坑和挑战,需要注意和解决。以下是一些常见的问题和坑,以及如何避免或解决它们:
竞态条件(Race Condition): 多个客户端同时尝试获取锁时,可能出现竞态条件,导致多个客户端同时获取了锁。解决方法是使用 Redis 的 SETNX(SET if Not eXists)指令或 Redlock 算法等来确保只有一个客户端获取锁。
死锁: 如果持有锁的客户端在处理过程中出现异常或崩溃,可能会导致死锁,其他客户端无法获取锁。可以设置锁的过期时间(超时机制)来避免死锁。
锁过期: 锁的过期时间需要合理设置,过期时间过长可能导致资源浪费,过期时间过短可能导致锁被提前释放。需要根据业务需求和处理时间来设置合适的过期时间。
误删锁: 客户端在释放锁时,可能因为网络问题或其他原因导致释放了其他客户端的锁。可以使用 Lua 脚本来确保原子性的解锁操作。
性能问题: 获取锁和释放锁的操作需要经过网络通信,可能会影响系统性能。可以考虑使用轻量级锁或减少锁的粒度来降低性能开销。
高并发问题: 在高并发环境下,频繁地获取和释放锁可能会导致 Redis 服务器负载过高。可以使用连接池、限流等策略来缓解高并发压力。
时钟漂移: 分布式系统中,不同节点的时钟可能存在漂移,可能会影响锁的过期时间判断。可以使用 Redis 的 Redlock 算法或基于 Redis 的其他分布式锁方案来解决时钟漂移问题。
网络问题: 在分布式环境中,网络通信可能会出现延迟、丢包等问题,影响锁的正常获取和释放。可以使用合适的重试机制来应对网络问题。
锁策略选择: 不同的业务场景可能需要选择不同的锁策略,如公平锁、非公平锁、写锁、读写锁等,需要根据具体情况进行选择。
# 13.redis 如何处理 bigkey
处理 Big Key(大键)是在使用 Redis 时需要特别注意的问题,因为大键可能会影响 Redis 的性能和内存利用率。以下是一些处理 Big Key 的方法:
数据分片: 将大键拆分成多个小键,然后存储在不同的 Redis 实例或节点中,采用分片的方式。这样可以将大键的数据均匀分布,减轻单个实例的内存负担。
分布式缓存: 使用分布式缓存解决方案,如 Redis 集群,将数据分布在多个节点上,避免单个节点过载。
分布式存储: 对于大数据,考虑将其存储在专门的分布式存储系统中,如 Hadoop、Cassandra 等,而不是全部存放在 Redis 中。
数据压缩: 使用 Redis 的压缩功能,对大键进行压缩存储,以减少内存占用。
分页查询: 对于大结果集的查询,可以考虑分页查询,避免一次性获取所有数据。
数据清理: 定期清理不再需要的大键数据,以释放内存。
使用 Hash 数据结构: 如果大键是一个哈希结构,可以将其拆分成多个小的哈希结构,以减少单个键的大小。
避免序列化大对象: 尽量避免将大对象直接序列化存储在 Redis 中,可以将大对象存储在文件系统或其他存储中,然后在 Redis 中存储对应的引用或路径。
数据迁移: 当一个键变得过大时,可以考虑将部分数据迁移到其他存储中,以减轻 Redis 的负担。
监控和优化: 定期监控 Big Key,分析其产生的原因,然后进行相应的优化策略。
# 14.Redis6.0 版的新特性
- 增加了多线程
Thread I/O - 客户端缓存
Client Side Cache - ACL 细粒度安全控制
acces control list - 增加
SSL模块 - 增加
RESP3新的通信协议