# 一.Nacos
# 1.什么是 Nacos?
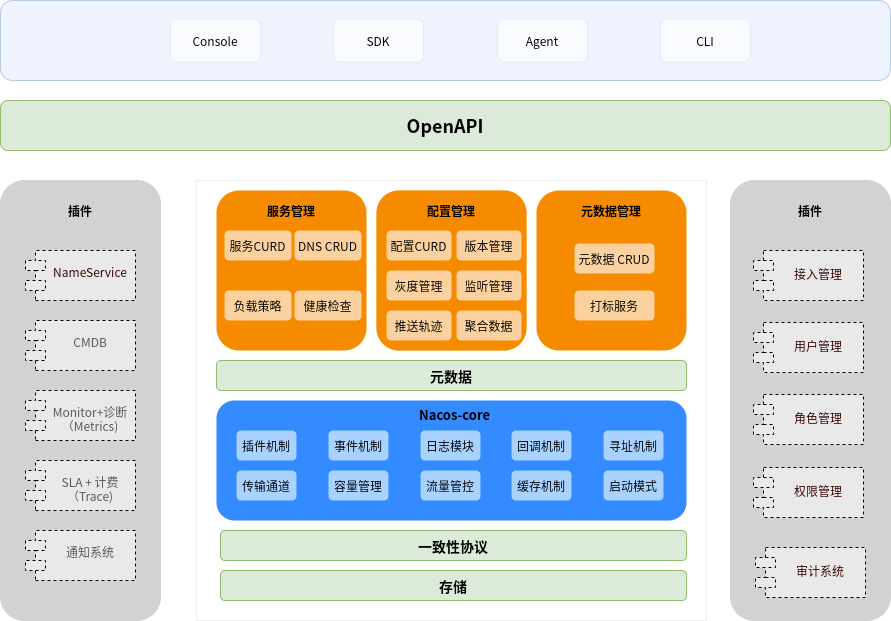
Nacos 的全称是 Dynamic Naming and Configuration Service,Na 为 naming/nameServer 即注册中心,co 为 configuration 即注册中心,service 是指该注册/配置中心都是以服务为核心。nacos 默认端口 8848。
- 服务管理:实现服务 CRUD,域名 CRUD,服务健康状态检查,服务权重管理等功能
- 配置管理:实现配置管 CRUD,版本管理,灰度管理,监听管理,推送轨迹,聚合数据等功能
- 元数据管理:提供元数据 CURD 和打标能力
- 插件机制:实现三个模块可分可合能力,实现扩展点 SPI 机制
- 事件机制:实现异步化事件通知,sdk 数据变化异步通知等逻辑
- 日志模块:管理日志分类,日志级别,日志可移植性(尤其避免冲突),日志格式,异常码+帮助文档
- 回调机制:sdk 通知数据,通过统一的模式回调用户处理。接口和数据结构需要具备可扩展性
- 寻址模式:解决 ip,域名,nameserver、广播等多种寻址模式,需要可扩展
- 推送通道:解决 server 与存储、server 间、server 与 sdk 间推送性能问题
- 容量管理:管理每个租户,分组下的容量,防止存储被写爆,影响服务可用性
- 流量管理:按照租户,分组等多个维度对请求频率,长链接个数,报文大小,请求流控进行控制
- 缓存机制:容灾目录,本地缓存,server 缓存机制。容灾目录使用需要工具
- 启动模式:按照单机模式,配置模式,服务模式,dns 模式,或者 all 模式,启动不同的程序+UI
- 一致性协议:解决不同数据,不同一致性要求情况下,不同一致性机制
- 存储模块:解决数据持久化、非持久化存储,解决数据分片问题
- Nameserver:解决 namespace 到 clusterid 的路由问题,解决用户环境与 nacos 物理环境映射问题
- CMDB:解决元数据存储,与三方 cmdb 系统对接问题,解决应用,人,资源关系
- Metrics:暴露标准 metrics 数据,方便与三方监控系统打通
- Trace:暴露标准 trace,方便与 SLA 系统打通,日志白平化,推送轨迹等能力,并且可以和计量计费系统打通
- 接入管理:相当于阿里云开通服务,分配身份、容量、权限过程
- 用户管理:解决用户管理,登录,sso 等问题
- 权限管理:解决身份识别,访问控制,角色管理等问题
- 审计系统:扩展接口方便与不同公司审计系统打通
- 通知系统:核心数据变更,或者操作,方便通过 SMS 系统打通,通知到对应人数据变更
- OpenAPI:暴露标准 Rest 风格 HTTP 接口,简单易用,方便多语言集成
- Console:易用控制台,做服务管理、配置管理等操作
- SDK:多语言 sdk
- Agent:dns-f 类似模式,或者与 mesh 等方案集成
- CLI:命令行对产品进行轻量化管理,像 git 一样好用
Nacos 采用了单一数据源,直接解决了分布式和集群部署中的一致性问题。Nacos 使用的 raft 协议,一致性相对 eureka 较高。
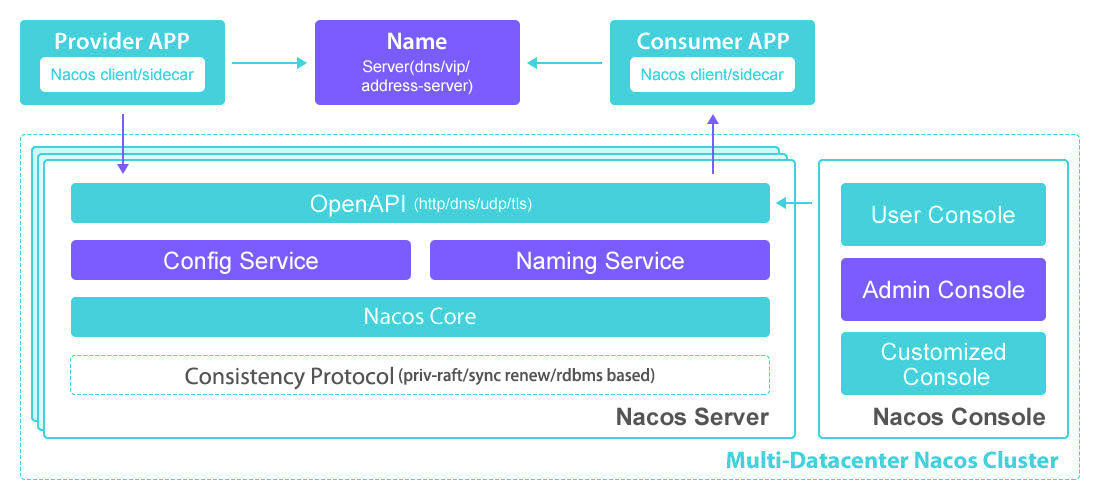
# 2.Nacos 架构图
从 nacos 的官网架构图可以看出使用了 raft 一致性算法,但是 Nacos 不是纯粹的 AP 服务,也不是纯粹的 CP 服务,而是两者同时支持。
Provider 启动时将自身的信息注册至注册中心,如果注册中心是 Zookeeper,在注册时可以选择注册临时节点或者永久节点。如果注册中心是 Eureka,服务注册只能注册临时节点。
Nacos 同时借鉴了两者的模式,如果在 Nacos 上注册临时节点,那么 Nacos 就是 AP 服务,保证高可用。如果 Nacos 上注册永久节点,那么 Nacos 就是 AP 服务,保证数据一致性。
Nacos 对这两者区分实现,通过 Distro 协议来实现 AP,通过 Raft 来实现 CP。
# 3.配置中心架构图
# 4.开源配置中心
微服务配置文件问题:
配置文件相对分散。在一个微服务架构下,配置文件会随着微服务的增多变的越来越多,而且分散在各个微服务中,不好统一配置和管理。
配置文件
无法区分环境。微服务项目可能会有多个环境,例如:测试环境、预发布环境、生产环境。每一个环境所使用的配置理论上都是不同的,一旦需要修改,就需要我们去各个微服务下手动维护,这比较困难。配置文件无法实时更新。我们修改了配置文件之后,必须重新启动微服务才能使配置生效,这对一个正在运行的项目来说是非常不友好的。
配置中心解决思路:
首先把项目中各种配置全部都放到一个集中的地方进行统一管理,并提供一套标准的接口。
当各个服务需要获取配置的时候,就来配置中心的接口拉取自己的配置。
当配置中心中的各种参数有更新的时候,也能通知到各个服务实时的过来同步最新的信息,使之动态更新。
Apollo:Apollo 是由携程开源的分布式配置中心。特点有很多,比如:配置更新之后可以实时生效,支持灰度发布功能,并且能对所有的配置进行版本管理、操作审计等功能,提供开放平台 API。并且资料也写的很详细。
Disconf:Disconf 是由百度开源的分布式配置中心。它是基于 Zookeeper 来实现配置变更后实时通知和生效的。
SpringCloud Confifig:这是 Spring Cloud 中带的配置中心组件。它和 Spring 是无缝集成,使用起来非常方便,并且它的配置存储支持 Git。不过它没有可视化的操作界面,配置的生效也不是实时的,需要重启或去刷新。
Nacos:这是 SpingCloud alibaba 技术栈中的一个组件,前面我们已经使用它做过服务注册中心。其实它也集成了服务配置的功能,我们可以直接使用它作为服务配置中心。
# 5.Config 配置中心
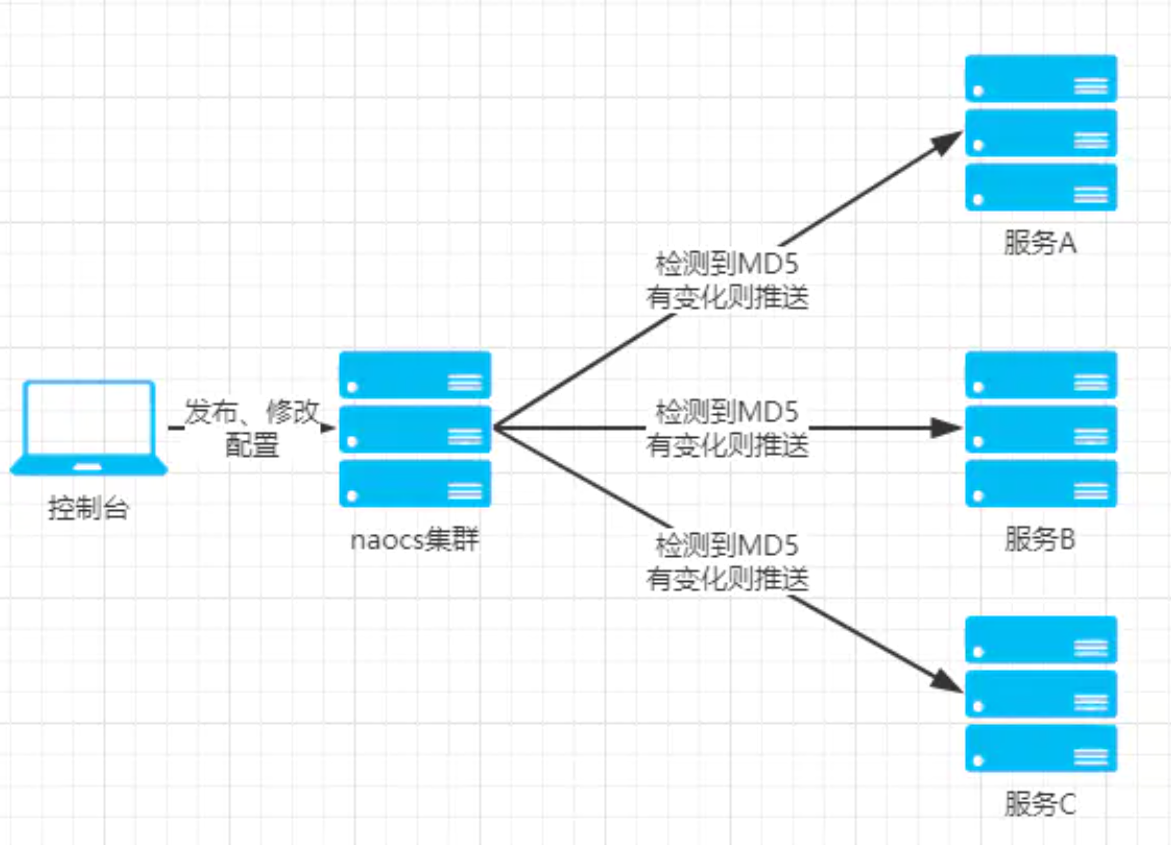
客户端启动后,每 30 秒给 Server 发送一个心跳包,Server 拿到心跳包之后,先对比一下数据版本,如果版本一样说明数据没有变化,这时 Server 不会立即将该心跳返回,Server 会一直拿着这个心跳,此时和客户端保持长连接的状态,直到数据有变化或者持有超过 29.5 秒,如果客户端感知到数据版本发生变化,就会主动请求 Server 拉取数据。
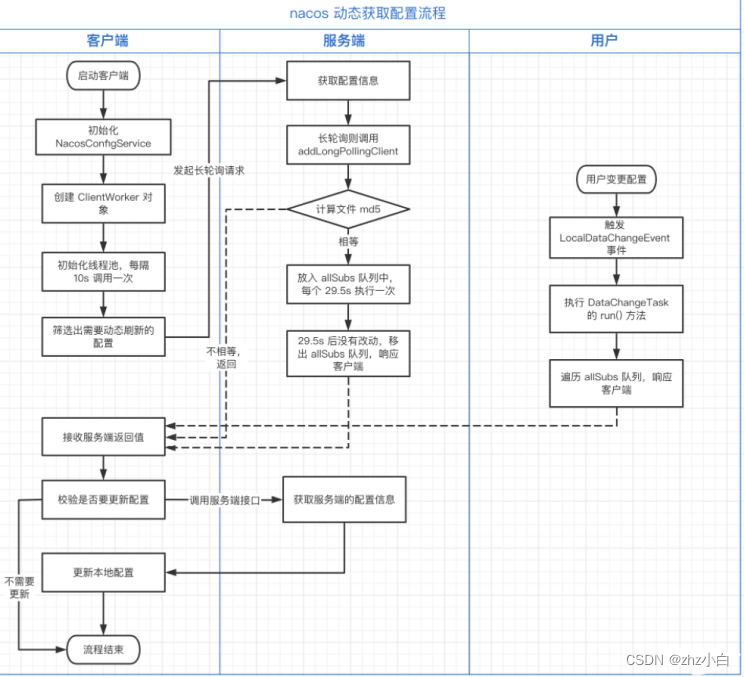
nacos动态获取配置流程:
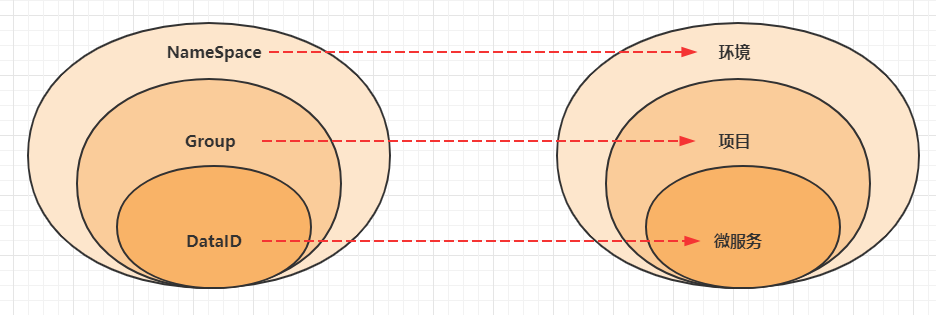
Nacos Config 主要通过命名空间和 group和 dataId 来唯一确定一条配置。
Nacos Client 从 Nacos Server 端获取数据时,调用的是此接口 ConfigService.getConfig(String dataId, String group, long timeoutMs)。
配置中心实现原理:
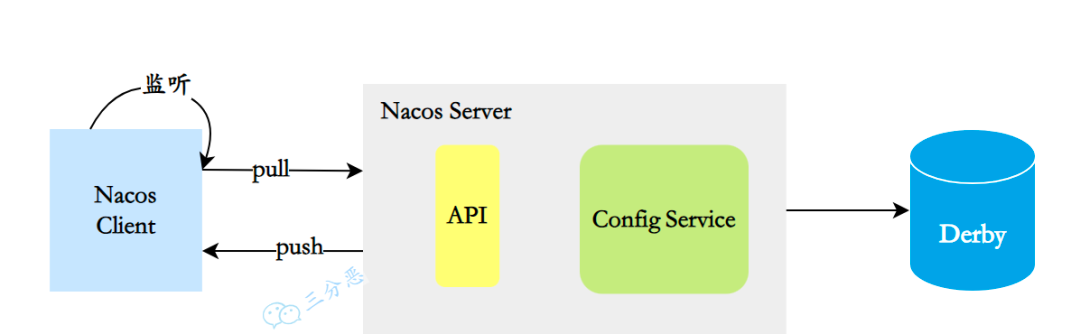
具体的实现大概可以分成这么几个部分:
- 配置信息存储:Nacos 默认使用内嵌数据库 Derby 来存储配置信息,还可以采用 MySQL 等关系型数据库。
- 注册配置信息:服务启动时,Nacos Client 会向 Nacos Server 注册自己的配置信息,这个注册过程就是把配置信息写入存储,并生成版本号。
- 获取配置信息:服务运行期间,Nacos Client 通过 API 从 Nacos Server 获取配置信息。Server 根据键查找对应的配置信息,并返回给 Client。
- 监听配置变化:Nacos Client 可以通过注册监听器的方式,实现对配置信息的监听。当配置信息发生变化时,Nacos Server 会通知已注册的监听器,并触发相应的回调方法。
# 6.配置与控制台
客户端配置
#端口号
server:
port: 18082
#断电打开
management:
endpoint:
health:
show-details: always
endpoints:
jmx:
exposure:
include: "*"
web:
exposure:
include: "*"
#spring配置
spring:
application:
name: nacos-producer
profiles:
active: dev
cloud:
nacos:
discovery:
server-addr: https://qinyingjie.top:8848 #服务注册地址
config:
server-addr: https://qinyingjie.top:8848 #配置中心地址
file-extension: yaml #文件类型
group: DEV_GROUP #组别
namespace: 64d48a25-ed26-4931-ac47-e9b85ab57e48 #命名空间
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
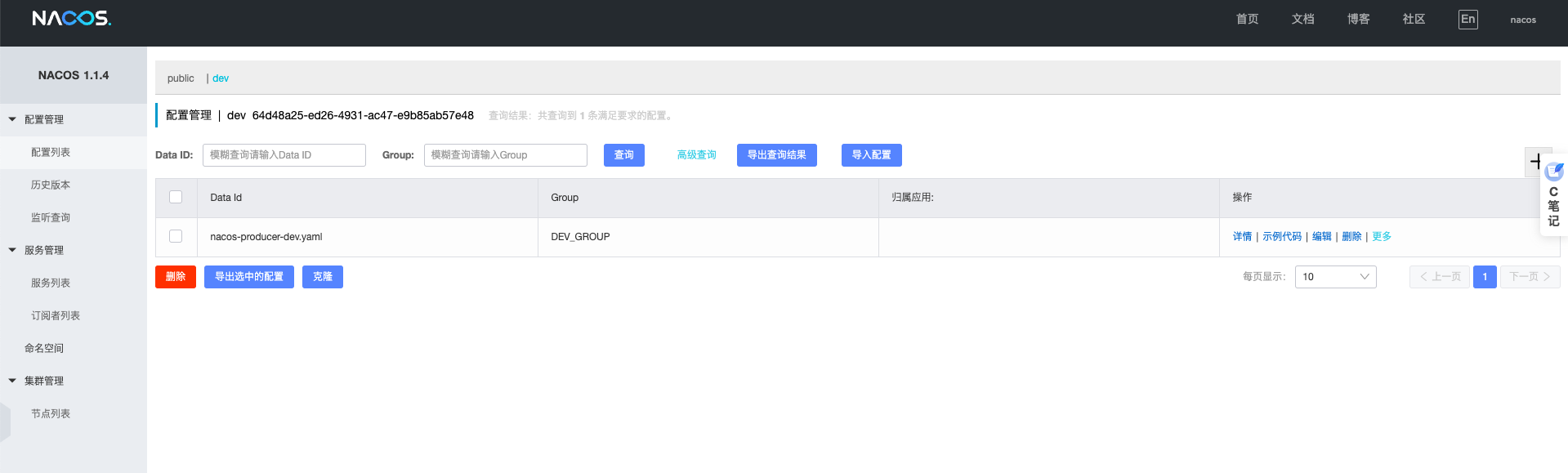
# 7.Nacos 三要素
命名空间:命名空间之间是隔离的,可以用来区分不同的环境,默认是public组别:命名空间相同,也可以用组别来区分环境,默认是DEFAULT_GROUPData Id:是微服务名称和环境的结合体
spring:
application:
name: nacos-server-consumer
profiles:
active: dev
2
3
4
5
#Data Id的取值
Data Id:nacos-server-consumer-dev
2
Data ID: Data ID 区分环境,虽然简单,但是每个项目要创建多个配置文件,随着项目的增多,都在一个命名空间下回显得很混乱,查找起来也不是很方便,而且不利于做权限控制,不方便管理。
当使用 Nacos Config 后,Profile 的配置就存储到 Data ID 下,即一个 Profile 对应一个 Data ID。
Data ID 的拼接格式:
${prefix}-${spring.profiles.active}.${file-extension}
- prefix 默认为 spring.application.name 的值,也可以通过配置项 spring.cloud.nacos.config.prefix 来配置
- spring.profiles.active 取 spring.profiles.active 的值,即为当前环境对应的 profile
- file-extension 为配置内容的数据格式,可以通过配置项 spring.cloud.nacos.config.file-extension 来配置
Group:用 Group 区分,问题也是一样的,出现很多的配置文件,不方便管理,Group 默认是 DEFAULT_GROUP,可以自定义组别,这个属性主要区分业务,比如说订单微服务一个组,用户微服务一个组,便于区分和数据管理。
Namespace:Namespace 区分环境,清晰明了,而且有利于做权限控制,方便管理配置文件。
nacos 命名空间默认是 public,可以自定义新建命名空间,主要用在区分环境,不同的环境下面使用不同的命名空间,不同命名空间的服务不能相互调用。
在配置文件配置的时候不是配置命名空间名称,应该配置命名空间的 id。
# 8.配置动态刷新
nacos config 使用长连接更新配置, 一旦配置有变动后,通知 Provider 的过程非常的迅速, 从速度上秒杀 SpringCloud 原来的 config 几条街.
@RestController
public class NacosConfigController {
@Value( "${config.appName}" )
private String appName;
@GetMapping("/nacos-config-test2")
public String nacosConfingTest2(){
return(appName);
}
}
2
3
4
5
6
7
8
9
10
11
共享配置:
- 同一微服务,不同场景(namespace)下共享配置
- 不同微服务之间共享共享配置
高可用:在 nacos 服务宕机时,暂时使用本地的文件,从 CAP 架构上来说,实现了 AP,高可用架构.在 nacos 服务宕机了后,客户端还能继续访问服务端,保证业务流程不因 nacos 宕机变成完全不可用。
在长轮询模式下,客户端定时向服务端发起请求,检查配置信息是否发生变更。如果没有变更,服务端会"hold"住这个请求,即暂时不返回结果,直到配置发生变化或达到一定的超时时间。
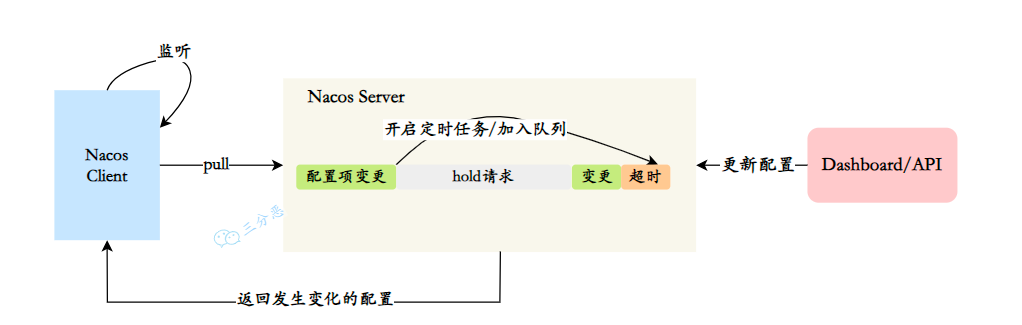
- 客户端发起 Pull 请求,服务端检查配置是否有变更。如果没有变更,则设置一个定时任务,在一段时间后执行,并将当前的客户端连接加入到等待队列中。
- 在等待期间,如果配置发生变更,服务端会立即返回结果给客户端,完成一次"推送"操作。
- 如果在等待期间没有配置变更,等待时间达到预设的超时时间后,服务端会自动返回结果给客户端,即使配置没有变更。
- 如果在等待期间,通过 Nacos Dashboard 或 API 对配置进行了修改,会触发一个事件机制,服务端会遍历等待队列,找到发生变更的配置项对应的客户端连接,并将变更的数据通过连接返回,完成一次"推送"操作。
通过长轮询的方式,Nacos 客户端能够实时感知配置的变化,并及时获取最新的配置信息。同时,这种方式也降低了服务端的压力,避免了大量的长连接占用内存资源。
# 9.Nacos 共享配置
在企业开发中,一个微服务架构的项目往往包含着很多个微服务,而各个微服务中难免有些公共重叠的配置,我们可以提取出功能的配置文件。
第一步 在 Nacos 之新建共享配置的文件 dh-shareConfig-dev.yaml 里面可以包含各个微服务的公共配置
第二步各个微服务中指定使用这个共享文件,修改各个微服务的 bootstrap.yml 文件如下:
spring:
application:
name: dh-user
cloud:
nacos:
discovery:
server-addr: 127.0.0.1:8848
group: DreamHome
config:
server-addr: 127.0.0.1:8848
file-extension: yaml
prefix: ${spring.application.name}
group: DreamHome
# 微服务共享配置
shared-configs:
- data-id: dh-shareConfig-dev.yaml
refresh: true
group: DreamHome
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
当出现多个共享配置,存在如下优先级关系:shared-configs[3] > shared-configs[2] > shared-configs[1] > shared-configs[0]。shared-configs[3]将会覆盖掉 shared-configs[0-1] 中的相同配置,不会覆盖不同配置不同种类配置之间,优先级按顺序如下:主配置 > 扩展配置(extension-configs) > 共享配置(shared-configs)
# 9.Nacos 持久化
1.默认数据库
默认持久化方式,是使用 derby 数据库。在 0.7 版本之前,在单机模式时 nacos 使用嵌入式数据库实现数据的存储,不方便观察数据存储的基本情况。0.7 版本增加了支持 mysql 数据源能力,Derby 是 Java 编写的数据库,属于 Apache 的一个开源项目。
2.修改配置
修改脚本 application.properties
### If use MySQL as datasource:
spring.datasource.platform=mysql
### Count of DB:
db.num=1
### Connect URL of DB:
db.url.0=jdbc:mysql://43.139.90.182:3306/nacos_config?characterEncoding=utf8&connectTimeout=1000&socketTimeout=3000&autoReconnect=true&useUnicode=true&useSSL=false&serverTimezone=UTC
db.user.0=root
db.password.0=xxxxxxx
2
3
4
5
6
7
8
9
10
3.执行脚本
mysql-schema.sql
4.新增配置
# 10.集群部署
Nacos Server 有两种运行模式:
standalonecluster
使用集群的模式部署 Nacos, cluster 模式启动。
在客户端配置多个节点信息,也可以用 nginx 做多个节点的负载均衡,在客户端配置 nginx 的访问节点也是可以的
#使用单机部署
sh bin/startup.sh -m standalone
#访问 默认账号和密码为:nacos nacos
http://xxxx:8848/nacos
2
3
4
5
nginx 代理 Nacos 集群,使用 nginx 作为负载均衡。
upstream nacos_server {
server 127.0.0.1:8848;
server 127.0.0.1:8847;
server 127.0.0.1:8846;
}
server {
listen 8648;
server_name localhost;
#charset koi8-r;
#access_log logs/host.access.log main;
location / {
proxy_pass http://nacos_server;
index index.html index.htm;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 11.集群选举算法
Nacos 的集群选举算法是自己实现的Raft 算法,主要是对于naming 服务,动态配置服务是没有用到这个 raft 集群心跳和数据更新的功能的。简单来说,动态配置是高可用,可以短暂使用本地配置,不影响服务调用。
Raft 算法功能主要有三点:
- leader 选举:使用 Raft 的
leaderdue时间,到期后发起选举,投票过半为leader - 心跳:
leader定时发送心跳给follower,心跳还可能打包datum信息给follower节点;follower 节点收到心跳重置选举leaderdue,避免发生选举,并且如果发现 datum 数据有变化会更新内存和本地文件缓存,数据变化 term 会增加 100,会删除 dead 的 datum。 - 数据更新:每次数据更新的时候,如果请求发送到
follower节点会转发给leader处理数据,由leader先更新本地数据,然后分别异步发送给其他follower,如果超过半数的follower更新成功那么数据就更新成功了。
注意:
- datum 指的的对于注册的服务和实例抽象包装。
- term 类似于 zookeeper 的 zxid;term 投票时会添加 1,数据更新会增加 100;zk 的是分为前 32 位和后 32 位分别累计选举年代和数据更新递增。
# 12.Nacos 2.X 的优点
Nacos 1.X 的痛点:Nacos 1.X 心跳多,无效查询多,心跳续约感知变化慢,连接消耗大,资源空耗严重。
- 心跳数量多,导致 TPS 居高不下
- 通过心跳续约感知服务变化,时延长
- UDP 推送不可靠,导致 QPS 居高不下
- 基于 HTTP 短连接模型,TIME_WAIT 状态连接过多
- 配置模块的
30 秒长轮询引起的频繁 GC
HTTP 短连接模型,每次客户端请求都会创建和销毁 TCP 链接,TCP 协议销毁的链接状态是 WAIT_TIME,完全释放还需要一定时间,当 TPS 和 QPS 较高时,服务端和客户端可能有大量的 WAIT_TIME 状态链接,从而会导致 connect time out 错误或者 Cannot assign requested address 的问题。
Nacos 2.X 的优点:
客户端不再需要定时发送实例心跳,只需要有一个维持连接可用keepalive消息即可。重复 TPS 可以大幅降低。TCP连接断开可以被快速感知到,提升反应速度。- 长连接的流式推送,比
UDP更加可靠;nio 的机制具有更高的吞吐量,而且由于可靠推送,可以加长客户端用于对账服务列表的时间,甚至删除相关的请求。重复的无效QPS可以大幅降低。 长连接避免频繁连接开销,可以大幅缓解TIME_WAIT问题。- 真实的长连接,解决配置模块 GC 问题。
- 更细粒度的同步内容,减少服务节点间的通信压力。
# 13.注册中心对比
Spring Cloud Eureka:
- AP 模型,数据最终一致性
- 客户端注册服务上报所有信息,节点多的情况下,网络,服务端压力过大,且浪费内存
- 客户端更新服务信息通过简单的轮询机制,当服务数量巨大时,服务器压力过大。
- 集群伸缩性不强,服务端集群通过广播式的复制,增加服务器压力
- Eureka2.0 闭源(Spring Cloud 最新版本还是使用的 1.X 版本的 Eureka)
Spring Cloud Zookeeper:
- CP 模型,ZAB 算法,数据强一致性
- 维护成本较高,客户端,session 状态,网络故障等问题,会导致服务异常
- 集群伸缩性限制,内存,GC 和连接
- 无控制台管理
Spring cloud Consul:
- 适用于 Service Mesh 架构,使用于 JAVA 生态
- AP 模型,Raft+Gossip 算法,数据最终一致性
- 未经大规模市场验证,无法保证可靠性
- Go 语言编写,内部异常排查困难
Spring Cloud Nacos:
- 开箱即用,适用于 dubbo,spring cloud
- AP 模型,数据最终一致性
- 注册中心,配置中心二合一,提供控制台管理
- 纯国产,久经双十一考验
# 14.Nacos 是 AP 还是 CP?
Nacos 不是纯粹的 AP 服务,也不是纯粹的 CP 服务,而是两者同时支持。
Provider 启动时将自身的信息注册至注册中心,如果注册中心是 Zookeeper,在注册时可以选择注册临时节点或者永久节点。如果注册中心是 Eureka,服务注册只能注册临时节点。
Nacos 同时借鉴了两者的模式,如果在 Nacos 上注册临时节点,那么 Nacos 就是 AP 服务,保证高可用。如果 Nacos 上注册永久节点,那么 Nacos 就是 CP 服务,保证数据一致性。
Nacos 对这两者区分实现,通过 Distro 协议来实现 AP,通过 Raft 来实现 CP。
# 15.Distro-AP
Distro 协议的主要设计思想如下:
- Nacos 每个节点都可以处理写请求,同时把数据同步到其他节点
- 每个节点只负责部分数据,定时发送自己负责数据的校验值到其他节点来保持数据一致性
- 每个节点独立处理写请求,及时从本地发出响应
其实和 Eureka 差不多,多了每个节点独立负责一部分数据这个特性
数据初始化
当新节点加入时,它会轮询所有的 Distro 节点,只要一个节点正常响应就会拉取全量数据。
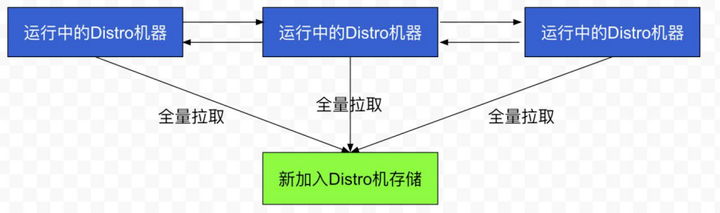
数据校验
在 Distro 集群启动后,各台机器之间会定期发送心跳,心跳信息主要为各个机器上的所有数据的元信息,这种数据校验会以心跳的形式进行,即每台机器在固定的时间间隔会向其他机器发起一次数据校验请求,一旦在数据校验过程中,某台机器发现其他机器上的数据与本地数据不一致,则会发起一次全量拉取请求,将数据补齐。

# 16.Raft-CP
Nacos 通过 Raft 来实现 CP,其流程原理大致与 Zookeeper 一致,也会有 Leader 节点选举这个东西。Nacos 已经准备用 JRaft 来替换 Raft。
# 17.心跳检测
Nacos 的心跳检测比较有特色。常规的心跳检测方式有两种,一种是客户端主动上报,服务端一段时间未收到心跳就会将客户端下线。另一种是服务端主动去调客户端的心跳接口,如果没有得到正常响应或者超时就将客户端下线。
在注册中心的场景中,客户端的数量一定是会远多于服务端的,如果让服务端去主动轮询心跳接口,会给服务端比较大的压力,所以目前的主流选择都是让客户端去主动上报。
但是 Nacos 对临时节点和永久节点分别做了处理,如果是临时节点,那么就需要临时节点主动上报,如果是永久节点,Nacos 可以主动发起 TCP 端口检查或者是 HTTP 接口检查,用来做健康检查。
在 Nacos 的定义中,临时节点都是弹性扩容之后注册的,随着访问量下来,相关服务是会被回收的,而有的永久节点是无法发起健康检查的,例如一些三方服务,只能提供出一个接口用于心跳检查。
# 15.Alibaba 和 Netflix 套件
下表是 Spring Cloud Alibaba 套件和 Spring Cloud Netflix 套件之间的大致对应关系以及功能描述:
| Spring Cloud Alibaba 套件 | Spring Cloud Netflix 套件 | 功能描述 |
|---|---|---|
| Nacos | Eureka/Consul + Config + Admin | 服务发现、配置管理、服务治理 |
| Sentinel | Hystrix + Dashboard + Turbine | 流量控制、熔断保护、监控 |
| Dubbo | Ribbon + Feign | 远程服务调用、负载均衡 |
| RocketMQ | RabbitMQ | 消息队列 |
| SchedulerX | Quartz | 分布式任务调度 |
| Seata | AT + TCC | 分布式事务解决方案 |
| AliCloud OSS | - | 阿里云对象存储服务 |
| AliCloud SLS | - | 阿里云日志服务 |
| Alibaba Cloud SMS | - | 阿里云短信服务 |
请注意,虽然 Spring Cloud Alibaba 套件中的组件在功能上与 Spring Cloud Netflix 套件中的组件有一些相似之处,但它们可能在实现细节、性能、可用性等方面存在差异。此外,Spring Cloud Alibaba 套件还引入了一些阿里云特定的服务,如 AliCloud OSS、AliCloud SLS 和 Alibaba Cloud SMS。在选择使用哪个套件时,你应该根据你的项目需求和技术栈来进行评估和选择。
# 16.注册中心对比
阿里出品的中间件都有个特点,不像一个纯粹的中间件,更像是业务锤炼出来的产物,在 RocketMQ,Nacos 上这种味道特别明显,它总是会考虑非常多的业务场景,在性能与好用性方面做一个取舍,使用阿里中间件的最大感受就是:它也许不是性能最好的,也许不是纯粹的,但是一定是最适合拿来做业务的。
| Feature | Consul | Zookeeper | Etcd | Eureka | Nacos |
|---|---|---|---|---|---|
| 服务健康检查 | 服务状态,内存,硬盘等 | (弱)长连接,keepalive | 连接心跳 | 可配支持 | 传输层 (PING 或 TCP)和应用层 (如 HTTP、MySQL、用户自定义)的健康检查 |
| 多数据中心 | 支持 | — | — | — | 支持 |
| kv 存储服务 | 支持 | 支持 | 支持 | — | 支持 |
| 一致性 | Raft | Paxos | Raft | — | Raft |
| CAP 定理 | CP | CP | CP | AP | CP: 配置中心 AP: 注册中心 |
| 使用接口(多语言能力) | 支持 http 和 dns | 客户端 | http/grpc | http(sidecar) | Nacos 支持基于 DNS 和基于 RPC 的服务发现。服务提供者使用 原生 SDK、OpenAPI、或一个独立的 Agent |
| watch 支持 | 全量/支持 long polling | 支持 | 支持 long polling | 支持 long polling/大部分增量 | 支持 long polling/大部分增量 |
| 自身监控 | metrics | — | metrics | metrics | |
| 安全 | acl /https | acl | https 支持(弱) | — | acl |
| Spring Cloud 集成 | 已支持 | 已支持 | 已支持 | 已支持 | 已支持 |
| 备注 | 可以作为 eureka 的替代使用 | 2.0 不在更新 | 1. 支持 dubbo 2. spring-cloud-alibaba 支持 |
# 二.Gateway
# 1.网关的基本功能?
- 简化客户端的工作。网关将微服务封装起来后,客户端只需同网关交互,而不必调用各个不同服务;
- 降低函数间的耦合度。 一旦服务接口修改,只需修改网关的路由策略,不必修改每个调用该函数的客户端,从而减少了程序间的耦合性。
- 解放开发人员把精力专注于业务逻辑的实现。由网关统一实现服务路由(灰度与 ABTest)、负载均衡、访问控制、流控熔断降级等非业务相关功能,而不需要每个服务 API 实现时都去考虑。
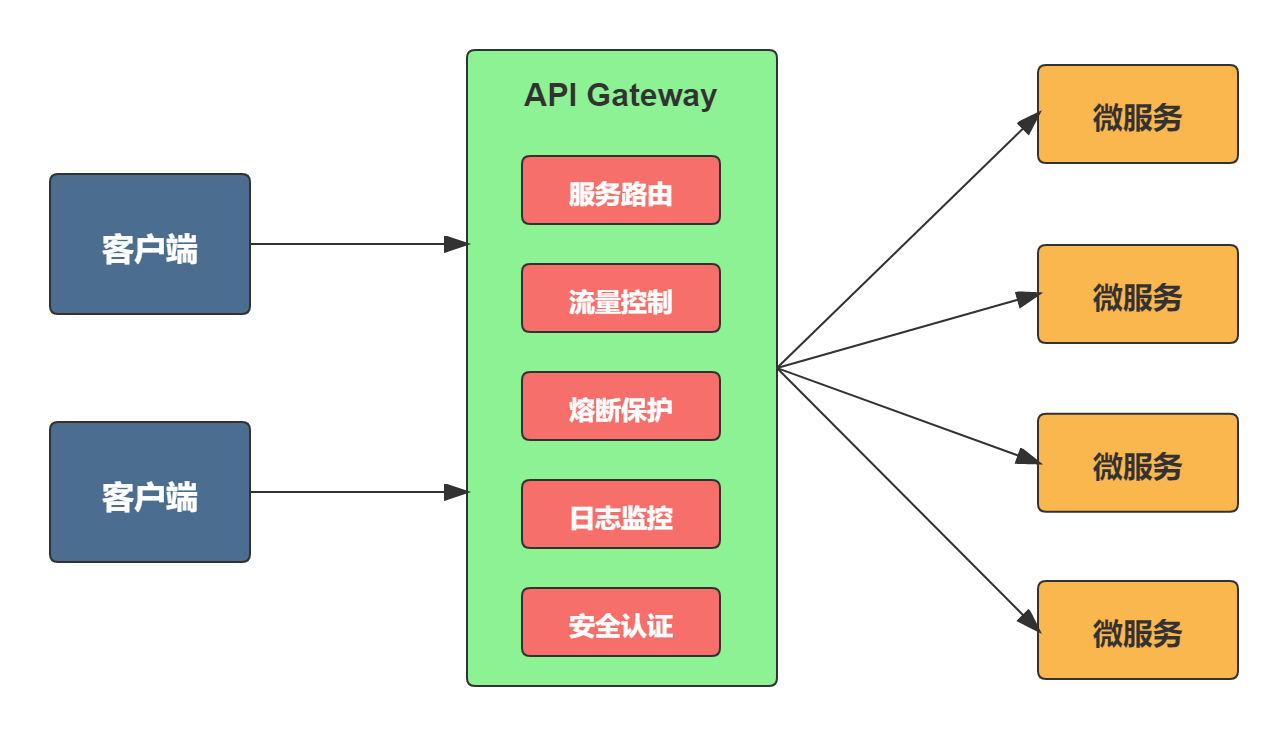
# 2.主流网关的对比?
网关(API Gateway)的设计要素:
限流:实现微服务访问流量计算,基于流量计算分析进行限流,可以定义多种限流规则。路由:路由是 API 网关很核心的模块功能,此模块实现根据请求,锁定目标微服务并将 请求进行转发。鉴权:权限身份认证。缓存:数据缓存。日志:日志记录。监控:记录请求响应数据,api 耗时分析,性能监控。灰度:线上灰度部署,可以减小风险。
简单介绍下你的网关实施方案:
- 开发语言:java + groovy,groovy 的好处是网关服务不需要重启就可以动态的添加 filter 来实 现一些功能;
- 微服务基础框架:
springboot; - 网关基础组件:
netflix zuul; - 服务注册中心:
consul; - 权限校验:
jwt; - API 监控:
prometheus + grafana; - API 统一日志收集:
logback + ELK; - 压力测试:
Jmeter; - 路由代理:
nginx
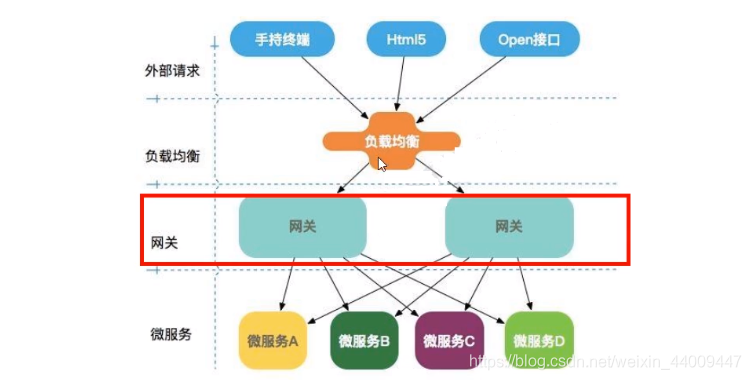
# 3.什么是 gateway?
SpringCloud 全家桶中国有个很重要的组件就是网关,在 1.x 版本中都是采用的 zuul 网关;zuul 是 netfix 开发的一个网关组件,但在 2.x 版本中,zuul 由于更新迭代的速度过慢,于是 SpringCloud 就自己推出了一个新的网关组件,那就是 gateway。
gateway 是在 spring 生态系统之上构建的 API 网关服务,基于 Spring 5,Spring Boot2 和 Project Reactor 等技术。gateway 旨在提供一种简单而有效的方式来对 API 进行路由,以及提供一些强大的过滤器功能,例如:反向代理、熔断、限流、重试等。
SpringCloud Gateway 是基于WebFlux框架实现的,而 WebFlux 框架底层则使用了高性能的Reactor模式通信框架Netty。
# 4.gateway 特性?
动态路由,能够匹配任何请求属性;- 可以对路由
指定 Predicate(断言)和Filter(过滤器),且易于编写; - 集成
Hystrix的断路器功能; - 集成 SpringCloud
服务发现功能; - 请求
限流功能; - 支持路径
重写。
Spring Cloud Gateway 的目标,不仅提供统一的路由方式,并且基于 Filter 链的方式提供了网关基本的功能,例如:安全,监控/指标,和限流。
提前声明:Spring Cloud Gateway 底层使用了高性能的通信框架 Netty。
# 5.三大核心概念
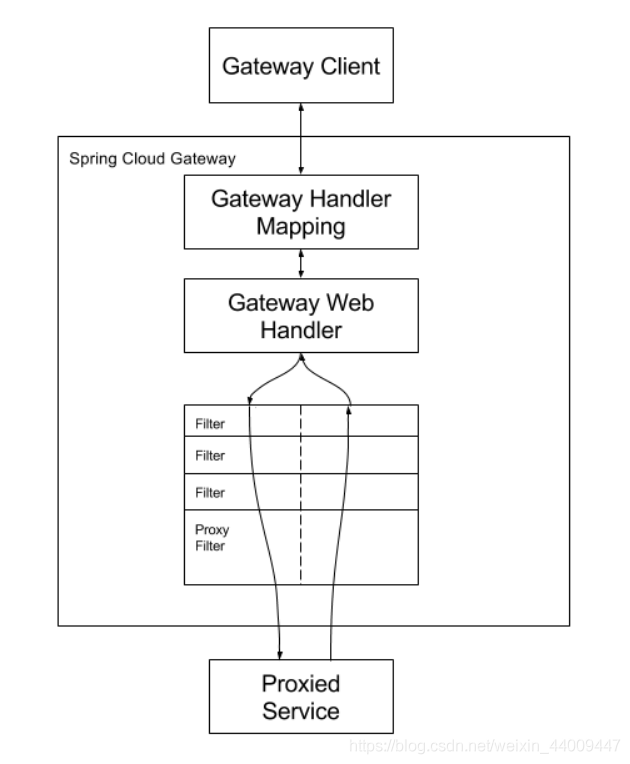
Route(路由):路由是构建网关的基本模块,它有 ID,目标 URI,一系列的断言和过滤器组成,如果请求与断言相匹配则进行路由。Predicate(断言):参考的是 java8 的 java.util.function.Predicate,开发人员可以匹配 HTTP 请求中的所有内容(例如请求头或请求参数),如果请求与断言相匹配则进行路由。Filter(过滤):指的是 Spring 框架中GatewayFilter的实例,使用过滤器,可以在请求被路由前或者之后对请求进行修改。
predicate 就是我们发的匹配条件;而 filter,就可以理解为一个无所不能的拦截器,有了这两个元素,再加上目标 uri,就可以实现一个具体的路由了。
# 6.路由 Route
Route 主要由路由 id、目标 uri、断言集合和过滤器集合组成,那我们简单看看这些属性到底有什么作用。
id:路由标识,要求唯一,名称任意(默认值 uuid,一般不用,需要自定义)uri:请求最终被转发到的目标地址order: 路由优先级,数字越小,优先级越高predicates:断言数组,即判断条件,如果返回值是 boolean,则转发请求到 uri 属性指定的服务中filters:过滤器数组,在请求传递过程中,对请求做一些修改
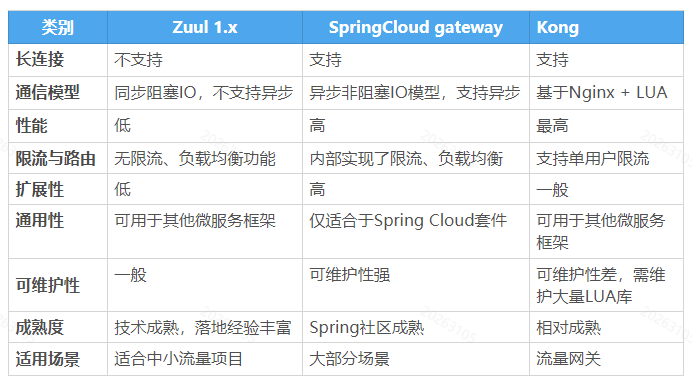
# 7.gateway 与 zuul 的区别
在 SpringCloud Finchley 正式版之前,Spring Cloud 推荐的网关是 Netflix 提供的 Zuul:
- Zuul 1.x,是一个基于阻塞 I/O 的 API Gateway
- Zuul1.x 基于 Servet2.5 使用阻塞架构它
不支持任何长连接(如 WebSocket) Zuul 的设计模式和 Nginx 较像,每次 I/0 操作都是从工作线程中选择一个执行,请求线程被阻塞到工作线程完成,但是差别是 Nginx 用 C++ 实现,Zuul 用 Java 实现,而 JVM 本身会有第一次加载较慢的情况,使得Zuul的性能相对较差。 - Zuul 2.x 理念更先进,想基于 Netty 非阳塞和支持长连接,但 SpringCloud 目前还没有整合。Zuul 2.x 的性能较 Zuul 1.x 有较大提升在性能方面,根据官方提供的基准测试,Spring Cloud Gateway 的 QPS (每秒请求数)是 Zuul1.x 的 1.6 倍。
Spring Cloud Gateway建立在 Spring Framework 5 和 Project Reactor 和 Spring Boot 2 之上,使用非阻塞APl。Spring Cloud Gateway还支持WebSocket,并且与 Spring 紧密集成拥有更好的开发体验。
# 8.zuul 模型的缺点
SpringCloud 中所集成的 Zuul 版本,采用的是 Tomcat 容器,使用的是传统的 Servlet IO 处理模型。
Servlet 的生命周期?
servlet由 servlet container 进行生命周期管理.container 启动时构造 servlet 对象并调用 servlet init()进行初始化container运行时接受请求,并为每个请求分配一个线程(一般从线程池中获取空闲线程)然后调用 service()container关闭时调用 servlet destory()销毁 servlet;

上述模式的缺点:
servlet 是一人简单的网络 IO 模型,当请求进入 servlet container 时,servet container 就会为其绑定一个线程,在并发不高的场是下这种模型易适用的。但是一旦高并发(化如抽风用 jemeter 压),线程数量就会上涨,而线程资源代价是昂贵的(上线文切换,内存消耗大)严重影响请求的处理时间。在一些简单业务场展下,不希望为每个 reguest 分配一个线程,只需要 1 个或几个线程就能应对极大并发的请求,这种业务场下 servlet 模型没有优势
所以 Zuul 1.X 是基于 servlet 之上的一个阻塞式处理模型,即 spring 实现了处理所有 request 请求的一个 servlet (DispatcherServlet)并由该 servlet 阻塞式处理。所以 Springcloud Zuul 无法摆脱 servlet 模型的弊端。
# 9.有哪些谓词?
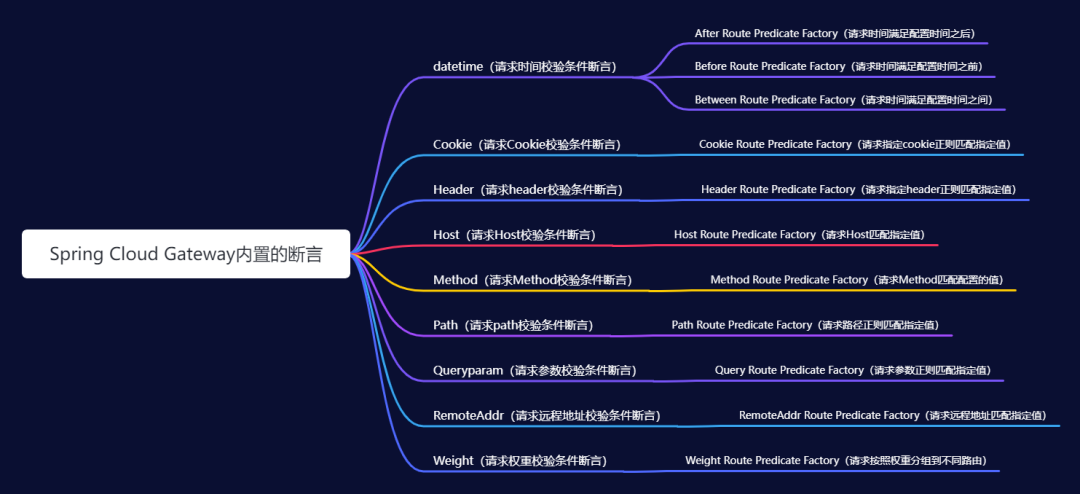
Path:指定路由,支持*号Datetime:请求时间校验条件断言After:在指定时间之后Before:在指定时间之前Between:在指定时间之间,可以用于抢购时间的区间设定
Cookie:带 cookie 请求,可以支持正则表达式Header:带指定 header,可以支持正则表达式Host:带指定 host 请求,可以支持通配符Method:指定 method 的请求类型,比如严禁 delete 类型Query:带指定查询参数,可以支持正则表达式RemoteAddr:来源地址的 list,匹配则通行Weight:权重路由

# 10.过滤器 filter
Gateway 过滤器的生命周期:
PRE:这种过滤器在请求被路由之前调用。我们可利用这种过滤器实现身份验证、在集群中选择请求的微服务、记录调试信息等。POST:这种过滤器在路由到微服务以后执行。这种过滤器可用来为响应添加标准的 HTTP Header、收集统计信息和指标、将响应从微服务发送给客户端等。
Gateway 过滤器从作用范围可分为两种:
GatewayFilter:应用到单个路由或者一个分组的路由上(需要在配置文件中配置)GlobalFilter:应用到所有的路由上(无需配置,全局生效)
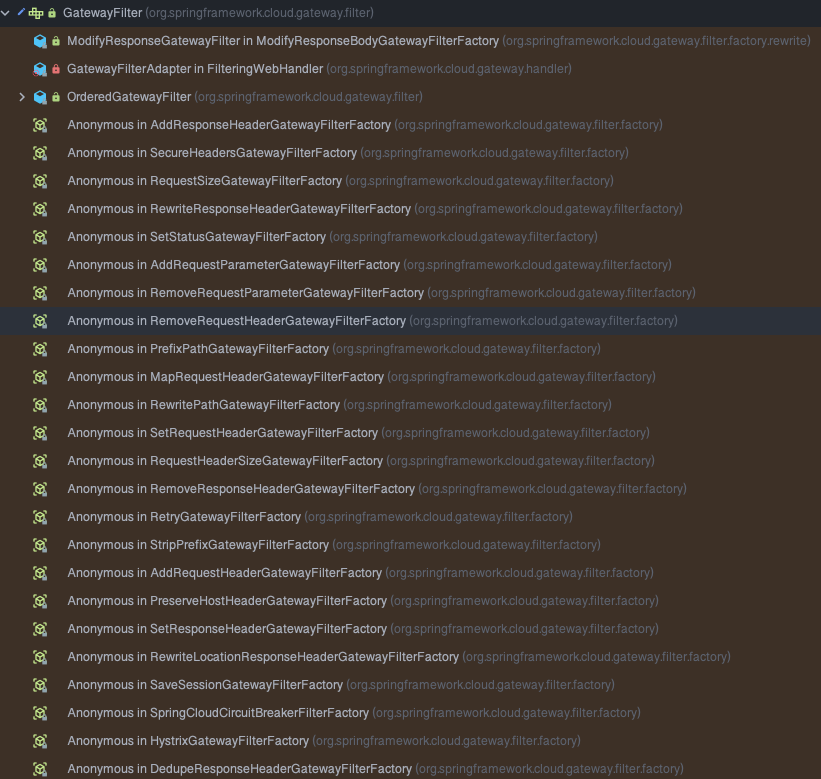
# 11.GatewayFilter
Spring Cloud Gateway 中内置了许多的局部过滤器,如下图:
局部过滤器需要在指定路由配置才能生效,默认是不生效的。
filters:
- AddResponseHeader=X-Response-Foo, Bar
# StripPrefix:去除原始请求路径中的前1级路径,即/gateway
- StripPrefix=1
2
3
4
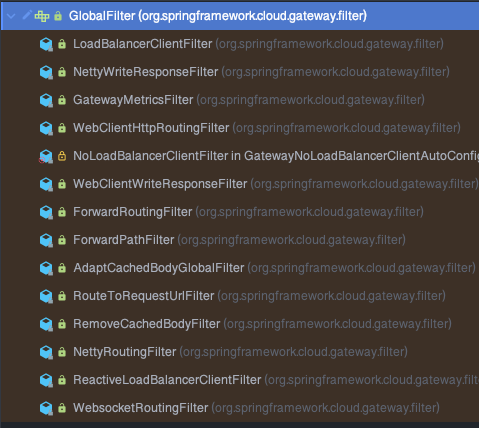
# 12.GlobalFilter
全局过滤器应用在全部路由上,无需开发者配置,Spring Cloud Gateway 也内置了一些全局过滤器,如下图:
GlobalFilter 的功能其实和 GatewayFilter 是相同的,只是 GlobalFilter 的作用域是所有的路由配置,而不是绑定在指定的路由配置上。多个 GlobalFilter 可以通过 @Order 或者 getOrder() 方法指定执行顺序,order 值越小,执行的优先级越高。
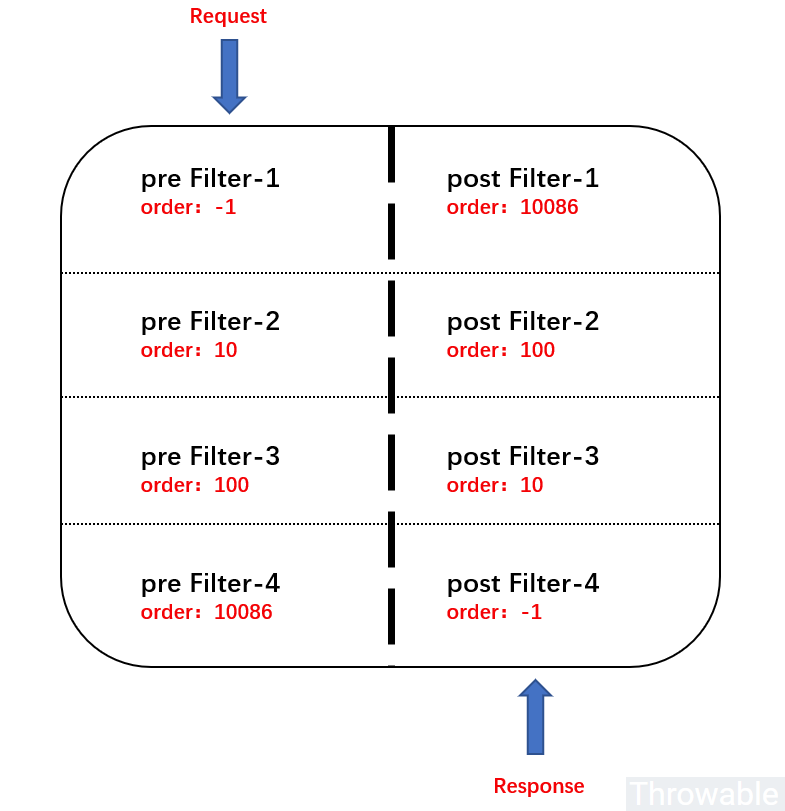
# 13.order 顺序
注意,由于过滤器有 pre 和 post 两种类型,pre 类型过滤器如果 order 值越小,那么它就应该在 pre 过滤器链的顶层,post 类型过滤器如果 order 值越小,那么它就应该在 post 过滤器链的底层。示意图如下:
# 14.高级使用
熔断降级:- 直接使用 sentinel,在 sentinel 进行对网关的熔断降级
- 通过 filer 配置,使用 hystrix 进行熔断降级
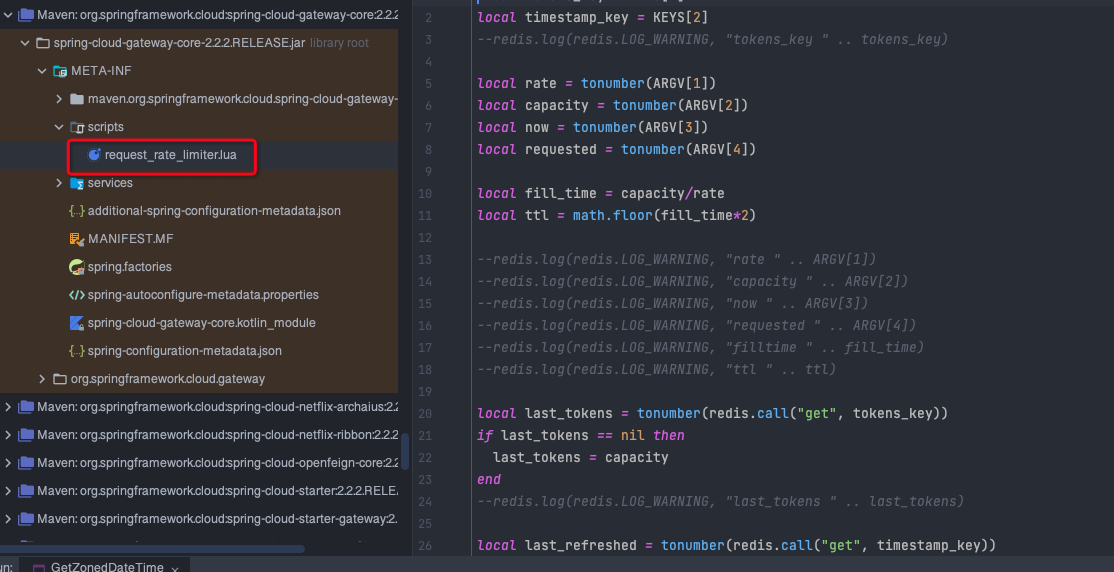
分布式限流:- 令牌桶原理,redis 和 lua 脚本结合使用
filters:
- StripPrefix=1
- name: Hystrix
args:
name: fallbackCmdA
fallbackUri: forward:/fallbackA
hystrix.command.fallbackCmdA.execution.isolation.thread.timeoutInMilliseconds: 5000
2
3
4
5
6
7
8
这里的配置,使用了两个过滤器:
过滤器
StripPrefix,作用是去掉请求路径的最前面 n 个部分截取掉。StripPrefix=1 就代表截取路径的个数为 1,比如前端过来请求/test/good/1/view,匹配成功后,路由到后端的请求路径就会变成 http://localhost:8888/good/1/view。过滤器
Hystrix,作用是通过Hystrix进行熔断降级。当上游的请求,进入了Hystrix熔断降级机制时,就会调用fallbackUri配置的降级地址。需要注意的是,还需要单独设置 Hystrix 的commandKey的超时时间。
@RestController
public class FallbackController {
@GetMapping("/fallbackA")
public Response fallbackA() {
Response response = new Response();
response.setCode("100");
response.setMessage("服务暂时不可用");
return response;
}
}
2
3
4
5
6
7
8
9
10
11
lua 脚本分布式限流源码
# 15.自定义断言工厂
新建一个类,继承 AbstractRoutePredicateFactory 类,这个类的泛型是自定义断言工厂的一个内部类叫做 Config 是一个固定的名字,在 Config 类中定义自定义断言需要的一些属性,并且自定义断言工厂使用 @Component 注解,交给 spring 容器创建。
我们来设定一个场景: 假设我们的应用仅仅让 age 在(min,max)之间的人来访问
@Component
public class AgeRoutePredicateFactory extends AbstractRoutePredicateFactory<AgeRoutePredicateFactory.Config> {
public AgeRoutePredicateFactory() {
super(AgeRoutePredicateFactory.Config.class);
}
//读取配置文件中的内容并配置给配置类中的属性
@Override
public List<String> shortcutFieldOrder() {
return Arrays.asList("minAge","maxAge");
}
@Override
public Predicate<ServerWebExchange> apply(Config config) {
return exchange -> {
// 获取请求参数中的 age 属性
String age = exchange.getRequest().getQueryParams().getFirst("age");
if(StringUtils.isNotEmpty(age)) {
try {
int a = Integer.parseInt(age);
boolean res = a >= config.minAge && a <= config.maxAge;
return res;
} catch (Exception e) {
System.out.println("输入的参数不是数字格式");
}
}
return false;
};
}
@Validated
public static class Config {
private Integer minAge;
private Integer maxAge;
public Integer getMinAge() {
return minAge;
}
public void setMinAge(Integer minAge) {
this.minAge = minAge;
}
public Integer getMaxage() {
return maxAge;
}
public void setMaxage(Integer maxage) {
this.maxAge = maxage;
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
# 16.源码分析
HandlerMapping:SG 构建的 HandlerMapping 实例是 RoutePredicatehandlerMappingWebHandler:构建的 WebHandler 为 FilteringWebHandler,它接收 GlobalFilter 的集合作为参数Route:路由构建由 RouteDefinitionRouteLocator 实例来处理,它基于路由配置(即上面的配置文件)来构建 Route 实例
RoutePredicateHandlerMapping 是 HandlerMapping 的一个实例,HandlerMapping 归属于 SpringWebFlux。
断言功能基于 Spring WebFlux 的 HandlerMapping 实现的,是通过断言工厂实现的,如:AfterRoutePredicateFactory、PathRoutePredicateFactory 及 HostRoutePredicateFactory 等,这些工厂均继承至抽象类 AbstractRoutePredicateFactory,而这个抽象类则实现了 RoutePredicateFactory 接口,这是一种抽象化思想,尽量做到解耦合和更好拓展性,而具体的断言判别逻辑则是在各自工厂的 apply 方法中,通过 GatewayPredicate 路由断言接口的 test 方法判别实现。
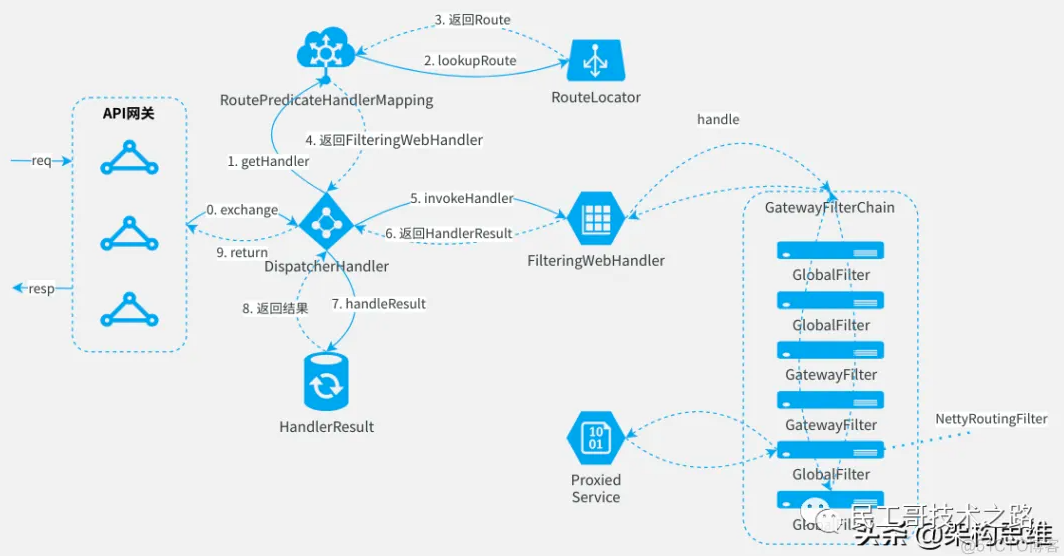
处理流程
我们知道,Gateway 的工作流程是这样的:客户端请求->A:Gateway Handler Mapping 接收请求参数并做相关断言处理->B:Web Handler Mapping->GlobalFilter->各种自定义 Filter 逻辑->目标服务接口调度,其中 A->B 的流转是通过代理 GatewayFilter 来实现的,进而流转到各种 FilterChain 链。
Spring WebFlux 的 HandlerMapping 负责获取当前请求的各种参数,并下发到各种子处理 HandlerMapping 中,这里与断言直接相关的是 RoutePredicateHandlerMapping,该类继承至抽象类 AbstractHandlerMapping,而这个抽象类又实现了 HandlerMapping 接口。
当前请求到来会调取 RoutePredicateHandlerMapping 类的 getHandlerInternal 方法,进而通过 RouteDefinitionRouteLocator(该类实现了接口 RouteLocator)实现类中的 getRoutes 获取已配置的 predicates,同时在该方法中转换封装好需要的 Route 实体返回,而具体的断言拦截功能通过 Route 中的 AsyncPredicate 的 apply 方法中再调取 Predicate 的 test 方法实现断言功能的,这就是从源码层面分析得到的断言工作流程。
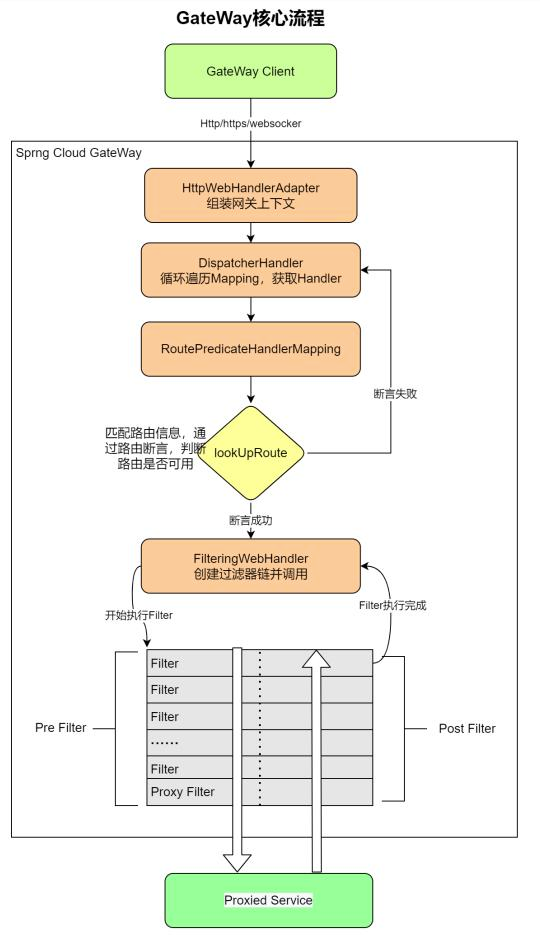
# 三.Sentinel
# 1.基本概念
响应时间(RT):响应时间是指系统对请求作出响应的时间。往往也需要对每个或每组功能讨论其平均响应时间和最大响应时间。响应时间是一个合理且准确的性能指标。响应时间的绝对值并不能直接反映软件的性能的高低,软件性能的高低实际上取决于用户对该响应时间的接受程度。
吞吐量(Throughput):吞吐量是指系统在单位时间内处理请求的数量。对于无并发的应用系统而言,吞吐量与响应时间成严格的反比关系,实际上此时吞吐量就是响应时间的倒数。
并发用户数:并发用户数是指系统可以同时承载的正常使用系统功能的用户的数量。与吞吐量相比,并发用户数是一个更直观但也更笼统的性能指标。
QPS每秒查询率(Query Per Second):每秒查询率 QPS 是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准,在因特网上,作为域名系统服务器的机器的性能经常用每秒查询率来衡量。对应 fetches/sec,即每秒的响应请求数,也即是最大吞吐能力。
衡量系统稳定性的指标:
- TPS(Transactions Per Second):每秒钟处理的事务数。
- RT(Response Time):响应时间,即从发送请求到接收到响应的时间。
- Error Rate:错误率,即发生错误的请求次数占总请求数的比例。
# 2.容错设计?
流控:即流量控制,根据流量、并发线程数、响应时间等指标,把随机到来的流量调整成合适的形状,即流量塑性,保证系统在流量突增情况下的可用性,避免系统被瞬时的流量高峰冲垮,一旦达到阈值则进行拒绝服务、排队等降级操作。熔断:当下游服务发生一定数量的失败后,打开熔断器,后续请求就快速失败。一段时间过后再判断下游服务是否已恢复正常,从而决定是否重置熔断器。降级:当访问量剧增、服务出现异常或者非核心服务影响到核心流程时,暂时牺牲掉一些东西,以保障整个系统的平稳运行。隔离:将系统或资源分隔开,保证系统故障时,能限定传播范围和影响范围,防止滚雪球效应,保证只有出问题的服务不可用,服务间的相互不影响。常见的隔离手段:资源隔离、线程隔离、进程隔离、集群隔离、机房隔离、读写隔离、快慢隔离、动静隔离等。超时:相当多的服务不可用问题,都是客户端超时机制不合理导致的,当服务端发生抖动时,如果超时时间过长,客户端一直处于占用连接等待响应的阶段,耗尽服务端资源,最终导致服务端集群雪崩;如果超时时间设置过短又会造成调用服务未完成而返回,所以一个健康的服务,一定要有超时机制,根据业务场景选择恰当的超时阈值。幂等:当用户多次请求同一事件时,得到的结果永远是同一个
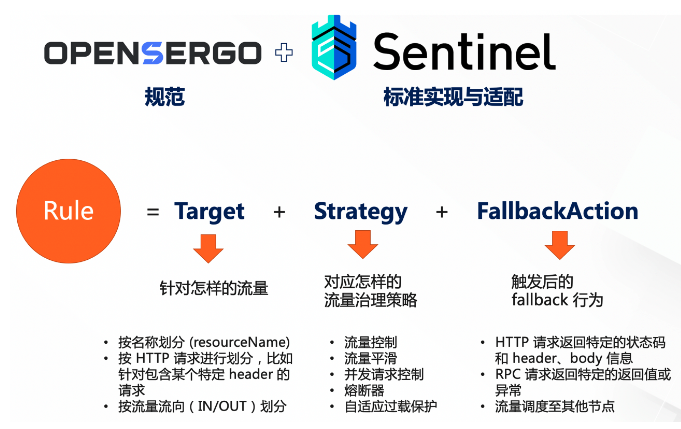
# 3.Sentinel 简介
随着微服务的流行,服务和服务之间的稳定性变得越来越重要。Sentinel 是面向分布式、多语言异构化服务架构的流量治理组件,主要以流量为切入点,从流量路由、流量控制、流量整形、熔断降级、系统自适应过载保护、热点流量防护等多个维度来帮助开发者保障微服务的稳定性。
Sentinel 是一个限流框架,而对于限流来说现在都有多种的限流算法,比如滑动时间窗口算法,漏桶算法,令牌桶算法等,Sentinel 对这几种算法都有具体的实现,在 sentinel 的 dashboard 中,假如我们对某一个资源设置了一个流控规则,并且选择的流控模式是“快速失败”,那么 sentinel 就会采用滑动时间窗口算法来作为该资源的限流算法。
# 4.Sentinel 特征
Sentinel 具有以下特征:
- 丰富的应用场景:
Sentinel承接了阿里巴巴近 10 年的双十一大促流量的核心场景,例如秒杀(即突发流量控制在系统容量可以承受的范围)、消息削峰填谷、集群流量控制、实时熔断下游不可用应用等。 - 完备的实时监控:
Sentinel同时提供实时的监控功能。您可以在控制台中看到接入应用的单台机器秒级数据,甚至 500 台以下规模的集群的汇总运行情况。 - 广泛的开源生态:Sentinel 提供开箱即用的与其它开源框架/库的整合模块,例如与 Spring Cloud、Apache Dubbo、gRPC、Quarkus 的整合。您只需要引入相应的依赖并进行简单的配置即可快速地接入 Sentinel。同时 Sentinel 提供 Java/Go/C++ 等多语言的原生实现。
- 完善的 SPI 扩展机制:
Sentinel提供简单易用、完善的 SPI 扩展接口。您可以通过实现扩展接口来快速地定制逻辑。例如定制规则管理、适配动态数据源等。
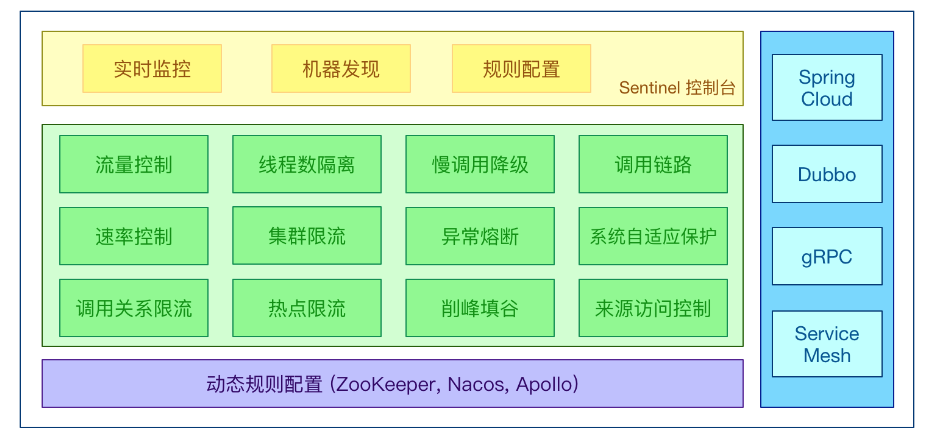
# 5.Sentinel 分为两部分
- 核心库 Java 客户端,不依赖任何框架/库,能够运行于所有 Java 运行时环境,同时对 Dubbo / Spring Cloud 等框架也有较好的支持。
- 控制台(Dashboard)基于 Spring Boot 开发,打包后可以直接运行,不需要额外的 Tomcat 等应用容器。
控制台功能
| 功能 | 功能 | 功能 |
|---|---|---|
| 实时监控 | 族点链路 | 流控规则 |
| 熔断规则 | 热点规则 | 系统规则 |
| 授权规则 | 集群流控 | 机器列表 |
# 6.Sentinel 的基本概念
资源:资源是 Sentinel 的关键概念。它可以是 Java 应用程序中的任何内容,例如,由应用程序提供的服务,或由应用程序调用的其它应用提供的服务,甚至可以是一段代码。在接下来的文档中,我们都会用资源来描述代码块。只要通过 Sentinel API 定义的代码,就是资源,能够被 Sentinel 保护起来。大部分情况下,可以使用方法签名,URL,甚至服务名称作为资源名来标示资源。
规则:围绕资源的实时状态设定的规则,可以包括流量控制规则、熔断降级规则以及系统保护规则。所有规则可以动态实时调整。
资源定义 2 种方式
- Sentinel API 定义的代码
- @SentinelResource 注解
# 7.@SentinelResource
@SentinelResource 注解用于定义资源埋点,但不支持 private 方法。默认情况下,Sentinel 对控制资源的保护处理是直接抛出异常,这样对用户不友好,所以我们需要通过可选的异常处理 blockHandler 和 fallback 配置项处理一下异常信息
@SentinelResource 属性:
value:资源名称,必需项,不能为空blockHandler / blockHandlerClass: blockHandler 对应处理 BlockException 的函数名称,可选项。blockHandler 函数访问范围需要是 public,返回类型需要与原方法相匹配,参数类型需要和原方法相匹配并且最后加一个额外的参数,类型为 BlockException。blockHandler 函数默认需要和原方法在同一个类中。若希望使用其他类的函数,则可以指定 blockHandlerClass 为对应的类的 Class 对象,注意对应的函数必需为 static 函数,否则无法解析。fallback / fallbackClass:fallback 函数名称,可选项,用于在抛出异常的时候提供 fallback 处理逻辑。fallback 函数可以针对所有类型的异常(除了 exceptionsToIgnore 里面排除掉的异常类型)进行处理。fallback 函数签名和位置要求:- 返回值类型必须与原函数返回值类型一致;
- 方法参数列表需要和原函数一致,或者可以额外多一个 Throwable 类型的参数用于接收对应的异常。
- fallback 函数默认需要和原方法在同一个类中。若希望使用其他类的函数,则可以指定 fallbackClass 为对应的类的 Class 对象,注意对应的函数必需为 static 函数,否则无法解析。
defaultFallback:默认的 fallback 函数名称,可选项,通常用于通用的 fallback 逻辑(即可以用于很多服务或方法)。默认 fallback 函数可以针对所有类型的异常(除了 exceptionsToIgnore 里面排除掉的异常类型)进行处理。若同时配置了 fallback 和 defaultFallback,则只有 fallback 会生效。defaultFallback 函数签名要求:- 返回值类型必须与原函数返回值类型一致;
- 方法参数列表需要为空,或者可以额外多一个 Throwable 类型的参数用于接收对应的异常。
- defaultFallback 函数默认需要和原方法在同一个类中。若希望使用其他类的函数,则可以指定 fallbackClass 为对应的类的 Class 对象,注意对应的函数必需为 static 函数,否则无法解析。
exceptionsToIgnore:用于指定哪些异常被排除掉,不会计入异常统计中,也不会进入 fallback 逻辑中,而是会原样抛出。
blockHandler 自定义异常
@GetMapping("/testHotKey")
@SentinelResource(value = "testHotKey", blockHandler = "dealHandler_testHotKey")
public String testHotKey(@RequestParam(value = "p1", required = false) String p1,
@RequestParam(value = "p2", required = false) String p2) {
log.info("testE 热点参数");
return "------testHotKey";
}
public String dealHandler_testHotKey(String p1, String p2, BlockException exception) {
// 默认 Blocked by Sentinel (flow limiting)
return "-----dealHandler_testHotKey";
}
2
3
4
5
6
7
8
9
10
11
12
Sentinel常见异常:
- FlowException 限流异常
- DegradeException 降级熔断异常
- ParamFlowException 热点参数异常
- SystemBlockException 系统异常
- AuthorityException 授权,鉴权异常
# 8.流控规则设计理念?
流量控制有以下几个角度:
- 资源的调用关系,例如资源的调用链路,资源和资源之间的关系;
- 运行指标,例如 QPS、线程池、系统负载等;
- 控制的效果,例如直接限流、冷启动、排队等。
Sentinel 的设计理念是让您自由选择控制的角度,并进行灵活组合,从而达到想要的效果。
# 9.流控规则实现?
FlowRule 流控规则:同一个资源可以创建多条限流规则。FlowSlot 会对该资源的所有限流规则依次遍历,直到有规则触发限流或者所有规则遍历完毕。
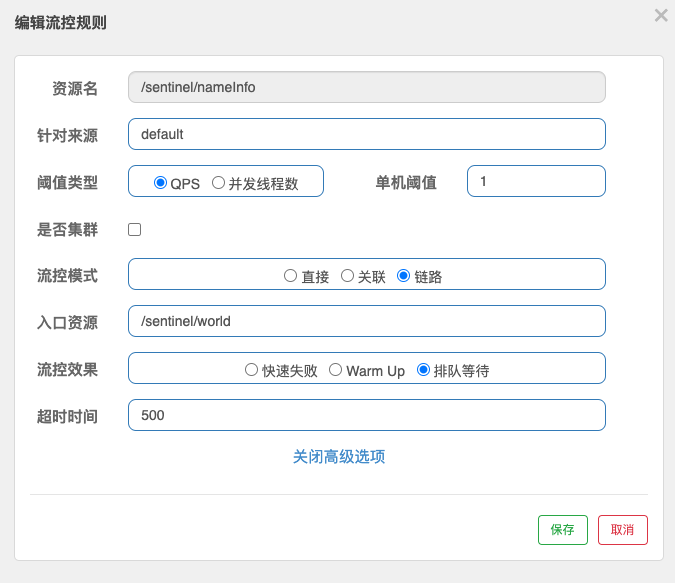
resource:资源名,即限流规则的作用对象,唯一,默认请求路径。针对来源:针对调用者进行限流,填写微服务名,若为 default 则不区分调用来源。- 阈值类型
QPS(每秒钟的请求数量):当调用该 resource 的 QPS 达到阈值的时候进行限流。线程数:当调用该 resource 的线程数达到阈值的时候进行限流。
- 单机阈值:阈值
- 流控模式
直接:达到限流条件直接限流。关联:当关联的资源达到阈值时,就限流自己。链路:当从入口资源进来的流量达到阈值,就对指定资源进行限流。
- 流控效果:
快速失败:直接失败,抛出异常。Warm Up:根据 codeFactor(冷加载因子,默认为 3)的值,从阈值/codeFactor,经过设定的预热时长,逐渐到达设置的 QPS 阈值。排队等待:匀速排队,让请求以匀速通过,阈值类型必须设置为 QPS,否则无效。
# 10.关联和链路的区别
说明
- 关联: A 资源关联 B 资源, 当 B 资源到达阈值时, 限流 A 资源
- 链路: A 资源入口资源为 B 资源, 当 A 资源到达阈值时, 限流 B 资源
其实关联和链路是有本质区别的
直接: 单个接口的限流关联: 平级接口的限流- 高优先级资源触发阈值,对低优先级资源限流。
链路: 上下级接口的限流- 资源阈值统计时,只统计从指定资源进入当前资源的请求,是对请求来源的限流
举个例子
关联:“查询订单” 关联 “下单” 接口, 当"下单"到达阈值, 限流"查询订单"接口链路:“查询订单的 service” 入口资源 “查询订单”, 当"查询订单的 service"到达阈值时, 限流"查询订单”
# 11.Warm Up(预热)
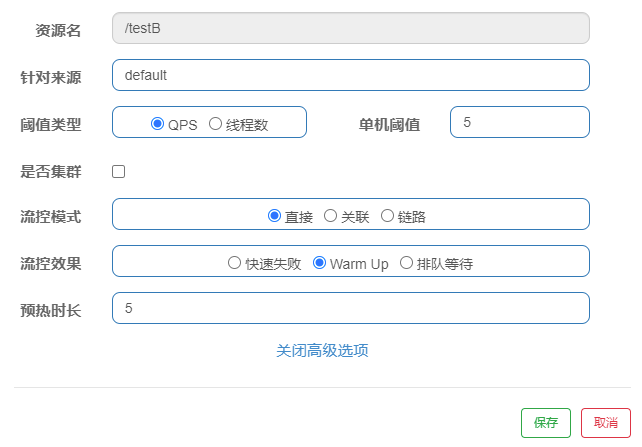
Warm Up 方式:即预热/冷启动方式。当系统长期处于低水位的情况下,当流量突然增加时,直接把系统拉升到高水位可能瞬间把系统压垮。通过"冷启动",让通过的流量缓慢增加,在一定时间内逐渐增加到阈值上限,给冷系统一个预热的时间,避免冷系统被压垮。如秒杀系统在开启瞬间,会有很多流量上来,很可能把系统打死,预热方式就是为了保护系统,可慢慢的把流量放进来,慢慢的把阈值增长到设置的阈值。
主要原理是它会根据 codeFactor(冷加载因子,默认为 3)的值,开始只能接受(阈值/codeFactor)流量,经过设定的预热时长,逐渐到达设置的 QPS 阈值。
例如:我们配置资源/testB,使用阈值类型为 QPS,单机阈值设置为 5,流控效果选择 Warm Up,其它默认,此设置的含义为:开始只能每秒接受 5/codeFactor 个请求,经过设定的预热时长(5 秒),逐渐到达设置的 QPS 阈值 5,效果为:开始访问 http://localhost:8401/testB 时每秒请求别超过 5/3 个才能正常访问,5 秒后可以接受的请求可以达到每秒 5 次。
# 12.排队等待
注意:匀速排队模式暂时不支持 QPS > 1000 的场景。
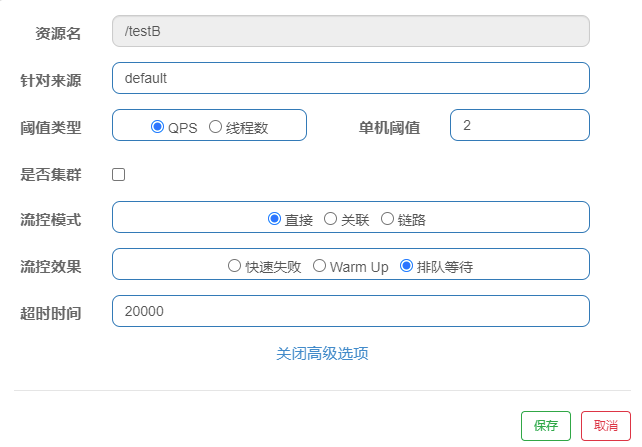
匀速排队方式会严格控制请求通过的间隔时间,也即是让请求以均匀的速度通过,对应的是漏桶算法,阈值类型必须设置为 QPS,否则无效。
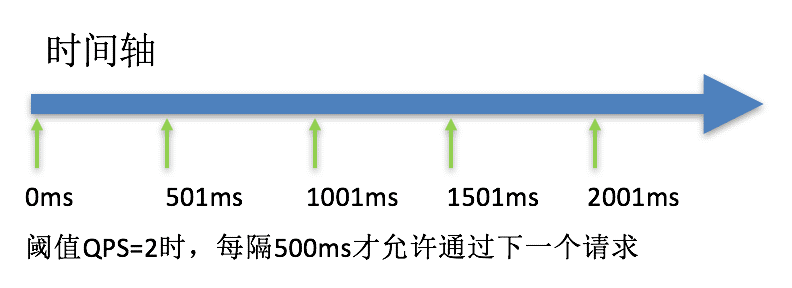
例如:我们配置资源/testB,使用阈值类型为 QPS,单机阈值设置为 2,流控效果选择排队等待,超时时间设置为 20000ms(20 秒),其它默认,此设置的含义为:代表一秒匀速的通过 2 个请求,也就是每个请求平均间隔恒定为 1000 / 2 = 500 ms,每一个请求的最长等待时间为 20s。
# 13.熔断降级设计理念
在限制的手段上,Sentinel 和 Hystrix 采取了完全不一样的方法。Hystrix 通过线程池隔离的方式,来对依赖(在 Sentinel 的概念中对应资源)进行了隔离。这样做的好处是资源和资源之间做到了最彻底的隔离。缺点是除了增加了线程切换的成本(过多的线程池导致线程数目过多),还需要预先给各个资源做线程池大小的分配。
Sentinel 对这个问题采取了两种手段:
通过并发线程数进行限制:和资源池隔离的方法不同,Sentinel 通过限制资源并发线程的数量,来减少不稳定资源对其它资源的影响。这样不但没有线程切换的损耗,也不需要您预先分配线程池的大小。当某个资源出现不稳定的情况下,例如响应时间变长,对资源的直接影响就是会造成线程数的逐步堆积。当线程数在特定资源上堆积到一定的数量之后,对该资源的新请求就会被拒绝。堆积的线程完成任务后才开始继续接收请求。
通过响应时间对资源进行降级:除了对并发线程数进行控制以外,Sentinel 还可以通过响应时间来快速降级不稳定的资源。当依赖的资源出现响应时间过长后,所有对该资源的访问都会被直接拒绝,直到过了指定的时间窗口之后才重新恢复。
# 14.熔断规则?
除了流量控制以外,及时对调用链路中的不稳定因素进行熔断也是 Sentinel 的使命之一。由于调用关系的复杂性,如果调用链路中的某个资源出现了不稳定,可能会导致请求发生堆积,进而导致级联错误。
Sentinel 和 Hystrix 的原则是一致的: 当检测到调用链路中某个资源出现不稳定的表现,例如请求响应时间长或异常比例升高的时候,则对这个资源的调用进行限制,让请求快速失败,避免影响到其它的资源而导致级联故障。
DegradeRule 熔断规则
| Field | 说明 | 默认值 |
|---|---|---|
resource | 资源名,即规则的作用对象 | |
grade | 熔断策略,支持慢调用比例/异常比例/异常数策略 | 慢调用比例 |
count | 慢调用比例模式下为慢调用临界 RT(超出该值计为慢调用);异常比例/异常数模式下为对应的阈值 | |
timeWindow | 熔断时长,单位为 s | |
minRequestAmount | 熔断触发的最小请求数,请求数小于该值时即使异常比率超出阈值也不会熔断(1.7.0 引入 | 5 |
statIntervalMs | 统计时长(单位为 ms),如 60*1000 代表分钟级(1.8.0 引入) | 1000ms |
slowRatioThreshold | 慢调用比例阈值,仅慢调用比例模式有效(1.8.0 引入) |
# 15.熔断策略
Sentinel 提供以下几种熔断策略:
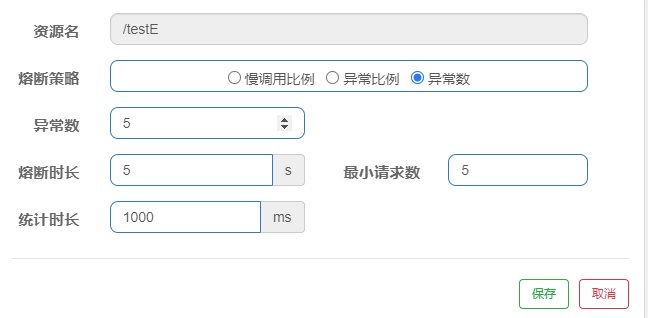
慢调用比例 (SLOW_REQUEST_RATIO):选择以慢调用比例作为阈值,需要设置允许的慢调用 RT(即最大的响应时间),请求的响应时间大于该值则统计为慢调用。当单位统计时长(statIntervalMs)内请求数目大于设置的最小请求数目,并且慢调用的比例大于阈值,则接下来的熔断时长内请求会自动被熔断。经过熔断时长后熔断器会进入探测恢复状态(HALF-OPEN 状态),若接下来的一个请求响应时间小于设置的慢调用 RT 则结束熔断,若大于设置的慢调用 RT 则会再次被熔断。异常比例 (ERROR_RATIO):当单位统计时长(statIntervalMs)内请求数目大于设置的最小请求数目,并且异常的比例大于阈值,则接下来的熔断时长内请求会自动被熔断。经过熔断时长后熔断器会进入探测恢复状态(HALF-OPEN 状态),若接下来的一个请求成功完成(没有错误)则结束熔断,否则会再次被熔断。异常比率的阈值范围是 [0.0, 1.0],代表 0% - 100%。异常数 (ERROR_COUNT):当单位统计时长内的异常数目超过阈值之后会自动进行熔断。经过熔断时长后熔断器会进入探测恢复状态(HALF-OPEN 状态),若接下来的一个请求成功完成(没有错误)则结束熔断,否则会再次被熔断。
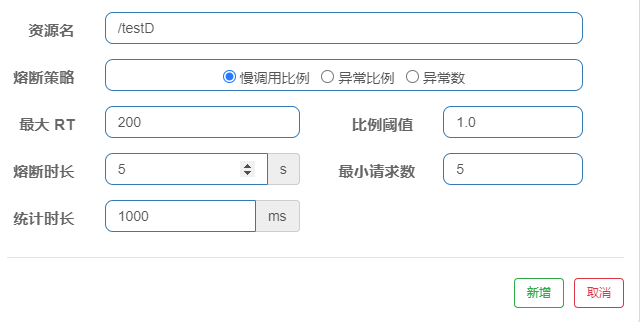
# 16.慢调用比例
例如:如果 1 秒内持续进入大于等于 5 个请求,并且请求响应的时间大于 200ms 时,这个请求即为慢调用,当慢调用的比例大于 1 时会触发降级,直到 5 秒后新的请求的响应时间小于 200ms 时,才结束熔断。
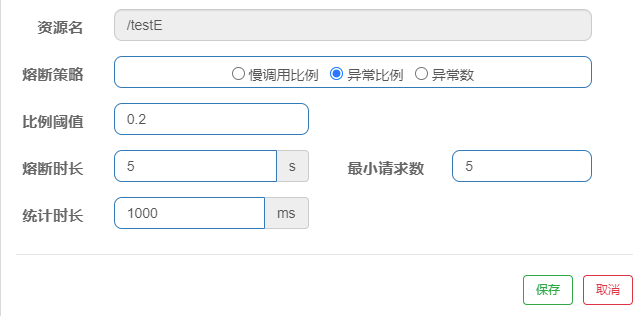
# 17.异常比例
例如:如果 1 秒内持续进入大于等于 5 个请求,并且请求中报异常的比例超过 0.2 则触发降级(降级时间持续 5 秒),5 秒后,新的请求若正常返回,才结束熔断。
# 18.异常数
例如:如果 1 秒内持续进入大于等于 5 个请求,并且请求异常数超过 5 时,会触发降级(降级时间持续 5 秒),5 秒后,新的请求若正常返回,才结束熔断。
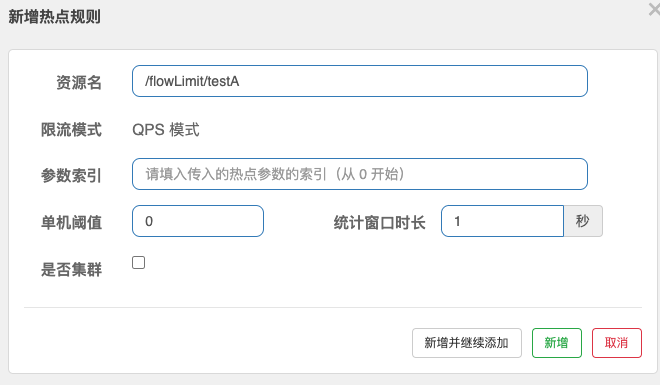
# 19.热点规则
热点规则(ParamFlowRule):热点即经常访问的数据。很多时候我们希望统计某个热点数据中访问频次最高的 Top K 数据,并对其访问进行限制。比如:
- 商品 ID 为参数,统计一段时间内最常购买的商品 ID 并进行限制
- 用户 ID 为参数,针对一段时间内频繁访问的用户 ID 进行限制
热点参数限流会统计传入参数中的热点参数,并根据配置的限流阈值与模式,对包含热点参数的资源调用进行限流。热点参数限流可以看做是一种特殊的流量控制,仅对包含热点参数的资源调用生效。
# 20.热点规则示例
@GetMapping("/testHotKey")
@SentinelResource(value = "testHotKey")
public String testHotKey(@RequestParam(value = "p1", required = false) String p1,
@RequestParam(value = "p2", required = false) String p2) {
return "------testHotKey";
}
2
3
4
5
6
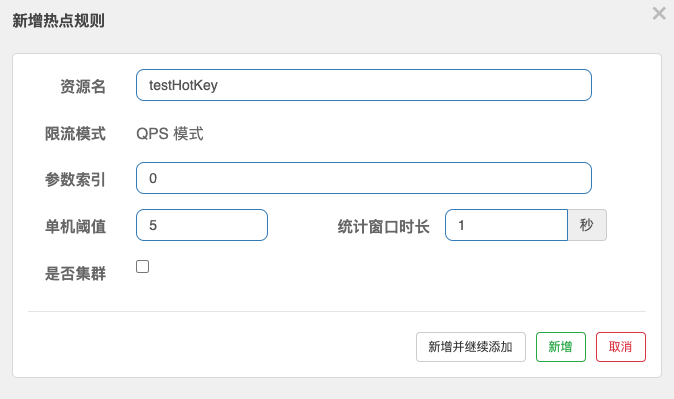
说明:当携带第一个参数(p1)访问/testHotKey 的请求量超过 1 秒 5 个时进行降级,携带第二个参数访问永远不会触发降级。因为参数索引设置的是 0。
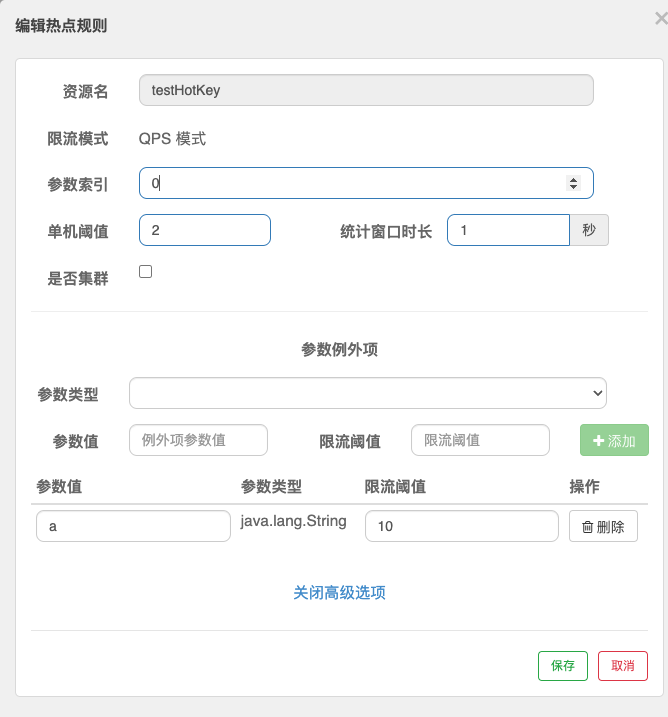
# 21.参数例外项
当携带第一个参数(p1)访问/testHotKey 的请求量超过 1 秒 5 个时进行降级,特殊的当传的参数为 a 时,请求量超过 1 秒 100 才进行降级。
# 22.授权规则
AuthorityRule:很多时候,我们需要根据调用方来限制资源是否通过,这时候可以使用 Sentinel 的访问控制(黑白名单)的功能。黑白名单根据资源的请求来源(origin)限制资源是否通过,若配置白名单则只有请求来源位于白名单内时才可通过;若配置黑名单则请求来源位于黑名单时不通过,其余的请求通过。
resource:资源名,即限流规则的作用对象limitApp:对应的黑名单/白名单,不同 origin 用 , 分隔,如 appA,appBstrategy:限制模式,AUTHORITY_WHITE 为白名单模式,AUTHORITY_BLACK 为黑名单模式,默认为白名单模式 比如我们希望控制对资源 test 的访问设置白名单,只有来源为 appA 和 appB 的请求才可通过,则可以配置如下白名单规则:
AuthorityRule rule = new AuthorityRule();
rule.setResource("test");
rule.setStrategy(RuleConstant.AUTHORITY_WHITE);
rule.setLimitApp("appA,appB");
AuthorityRuleManager.loadRules(Collections.singletonList(rule));
2
3
4
5
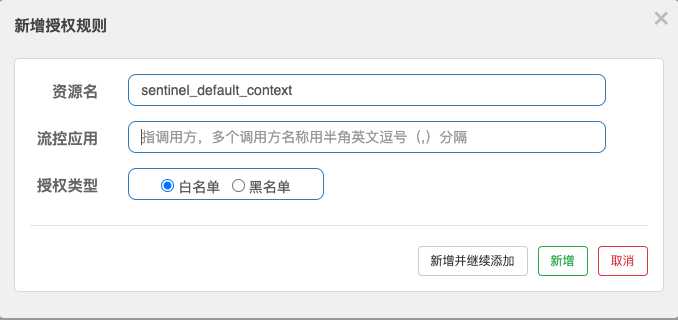
# 23.系统规则
系统保护规则是从应用级别的入口流量进行控制,从单台机器的总体 Load、RT、入口 QPS 、CPU 使用率和线程数五个维度监控应用数据,让系统尽可能跑在最大吞吐量的同时保证系统整体的稳定性。 系统保护规则是应用整体维度的,而不是资源维度的,并且仅对入口流量 (进入应用的流量) 生效。
Load 自适应(仅对 Linux/Unix-like 机器生效):系统的 load1 作为启发指标,进行自适应系统保护。当系统 load1 超过设定的启发值,且系统当前的并发线程数超过估算的系统容量时才会触发系统保护(BBR 阶段)。系统容量由系统的 maxQps_minRt 估算得出。设定参考值一般是 CPU cores_2.5。CPU 使用率:当单台机器上所有入口流量的 CPU 使用率达到阈值即触发系统保护平均 RT:当单台机器上所有入口流量的平均 RT 达到阈值即触发系统保护,单位是毫秒。并发线程数:当单台机器上所有入口流量的并发线程数达到阈值即触发系统保护。入口 QPS:当单台机器上所有入口流量的 QPS 达到阈值即触发系统保护。
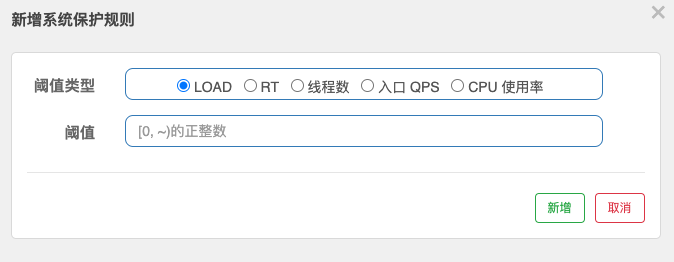
# 24.工作原理
在 Sentinel 里面,所有的资源都对应一个资源名称(resourceName),每次资源调用都会创建一个 Entry 对象。Entry 可以通过对主流框架的适配自动创建,也可以通过注解的方式或调用 SphU API显式创建。Entry 创建的时候,同时也会创建一系列功能插槽(slot chain),这些插槽有不同的职责,例如:
NodeSelectorSlot: 负责收集资源的路径,并将这些资源的调用路径,以树状结构存储起来,用于根据调用路径来限流降级;ClusterBuilderSlot: 则用于存储资源的统计信息以及调用者信息,例如该资源的 RT, QPS, thread count 等等,这些信息将用作为多维度限流,降级的依据;StatisticSlot: 则用于记录、统计不同纬度的runtime指标监控信息;滑动窗口是其实现;FlowSlot: 则用于根据预设的限流规则以及前面 slot 统计的状态,来进行流量控制;AuthoritySlot: 则根据配置的黑白名单和调用来源信息,来做黑白名单控制;DegradeSlot: 则通过统计信息以及预设的规则,来做熔断降级;SystemSlot: 则通过系统的状态,例如 load1 等,来控制总的入口流量;
每个 Slot 执行完业务逻辑处理后,会调用fireEntry()方法,该方法将会触发下一个节点的 entry 方法,下一个节点又会调用他的 fireEntry,以此类推直到最后一个 Slot,由此就形成了 sentinel 的责任链。
# 25.插槽 Slot
Sentinel 将 ProcessorSlot 作为 SPI 接口进行扩展(1.7.2 版本以前 SlotChainBuilder 作为 SPI),使得 Slot Chain 具备了扩展的能力。您可以自行加入自定义的 slot 并编排 slot 之间的顺序,从而可以给 Sentinel 添加自定义的功能。
Sentinel 的工作流程就是围绕着一个个插槽所组成的插槽链来展开的。默认的各个插槽之间的顺序是固定的,因为有的插槽需要依赖其他的插槽计算出来的结果才能进行工作。
Sentinel 通过 SlotChainBuilder 作为 SPI 接口,使得 Slot Chain 具备了扩展的能力。我们可以通过实现 SlotsChainBuilder 接口加入自定义的 slot 并自定义编排各个 slot 之间的顺序,从而可以给 sentinel 添加自定义的功能。
@Spi(isDefault = true)
public class DefaultSlotChainBuilder implements SlotChainBuilder {
@Override
public ProcessorSlotChain build() {
ProcessorSlotChain chain = new DefaultProcessorSlotChain();
List<ProcessorSlot> sortedSlotList = SpiLoader.of(ProcessorSlot.class).loadInstanceListSorted();
for (ProcessorSlot slot : sortedSlotList) {
if (!(slot instanceof AbstractLinkedProcessorSlot)) {
RecordLog.warn("The ProcessorSlot(" + slot.getClass().getCanonicalName() + ") is not an instance of AbstractLinkedProcessorSlot, can't be added into ProcessorSlotChain");
continue;
}
chain.addLast((AbstractLinkedProcessorSlot<?>) slot);
}
return chain;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
总结:sentinel 的限流降级等功能,主要是通过一个 SlotChain 实现的。在链式插槽中,有 7 个核心的 Slot,这些 Slot 各司其职,可以分为以下几种类型:
进行资源调用路径构造的
NodeSelectorSlot和ClusterBuilderSlot进行资源的实时状态统计的
StatisticsSlot进行系统保护,限流,降级等规则校验的
SystemSlot、AuthoritySlot、FlowSlot、DegradeSlot
后面几个 Slot 依赖于前面几个 Slot 统计的结果。
# 26.插槽 Slot
slot 是另一个 sentinel 中非常重要的概念,sentinel 的工作流程就是围绕着一个个插槽所组成的插槽链来展开的。需要注意的是每个插槽都有自己的职责,他们各司其职完好的配合,通过一定的编排顺序,来达到最终的限流降级的目的。默认的各个插槽之间的顺序是固定的,因为有的插槽需要依赖其他的插槽计算出来的结果才能进行工作。
但是这并不意味着我们只能按照框架的定义来,sentinel 通过 SlotChainBuilder 作为 SPI 接口,使得 Slot Chain 具备了扩展的能力。我们可以通过实现 SlotsChainBuilder 接口加入自定义的 slot 并自定义编排各个 slot 之间的顺序,从而可以给 sentinel 添加自定义的功能。
那 SlotChain 是在哪创建的呢?是在 CtSph.lookProcessChain() 方法中创建的,并且该方法会根据当前请求的资源先去一个静态的 HashMap 中获取,如果获取不到才会创建,创建后会保存到 HashMap 中。这就意味着,同一个资源会全局共享一个 SlotChain。默认生成 ProcessorSlotChain 为:
public ProcessorSlotChain build() {
ProcessorSlotChain chain = new DefaultProcessorSlotChain();
chain.addLast(new NodeSelectorSlot());
chain.addLast(new ClusterBuilderSlot());
chain.addLast(new LogSlot());
chain.addLast(new StatisticSlot());
chain.addLast(new SystemSlot());
chain.addLast(new AuthoritySlot());
chain.addLast(new FlowSlot());
chain.addLast(new DegradeSlot());
return chain;
}
2
3
4
5
6
7
8
9
10
11
12
13
这里大概的介绍下每种 Slot 的功能职责:
NodeSelectorSlot负责收集资源的路径,并将这些资源的调用路径,以树状结构存储起来,用于根据调用路径来限流降级;ClusterBuilderSlot则用于存储资源的统计信息以及调用者信息,例如该资源的 RT, QPS, thread count 等等,这些信息将用作为多维度限流,降级的依据;StatisticsSlot则用于记录,统计不同维度的 runtime 信息;SystemSlot则通过系统的状态,例如 load1 等,来控制总的入口流量;AuthoritySlot则根据黑白名单,来做黑白名单控制;FlowSlot则用于根据预设的限流规则,以及前面 slot 统计的状态,来进行限流;DegradeSlot则通过统计信息,以及预设的规则,来做熔断降级;
每个 Slot 执行完业务逻辑处理后,会调用 fireEntry()方法,该方法将会触发下一个节点的 entry 方法,下一个节点又会调用他的 fireEntry,以此类推直到最后一个 Slot,由此就形成了 sentinel 的责任链。
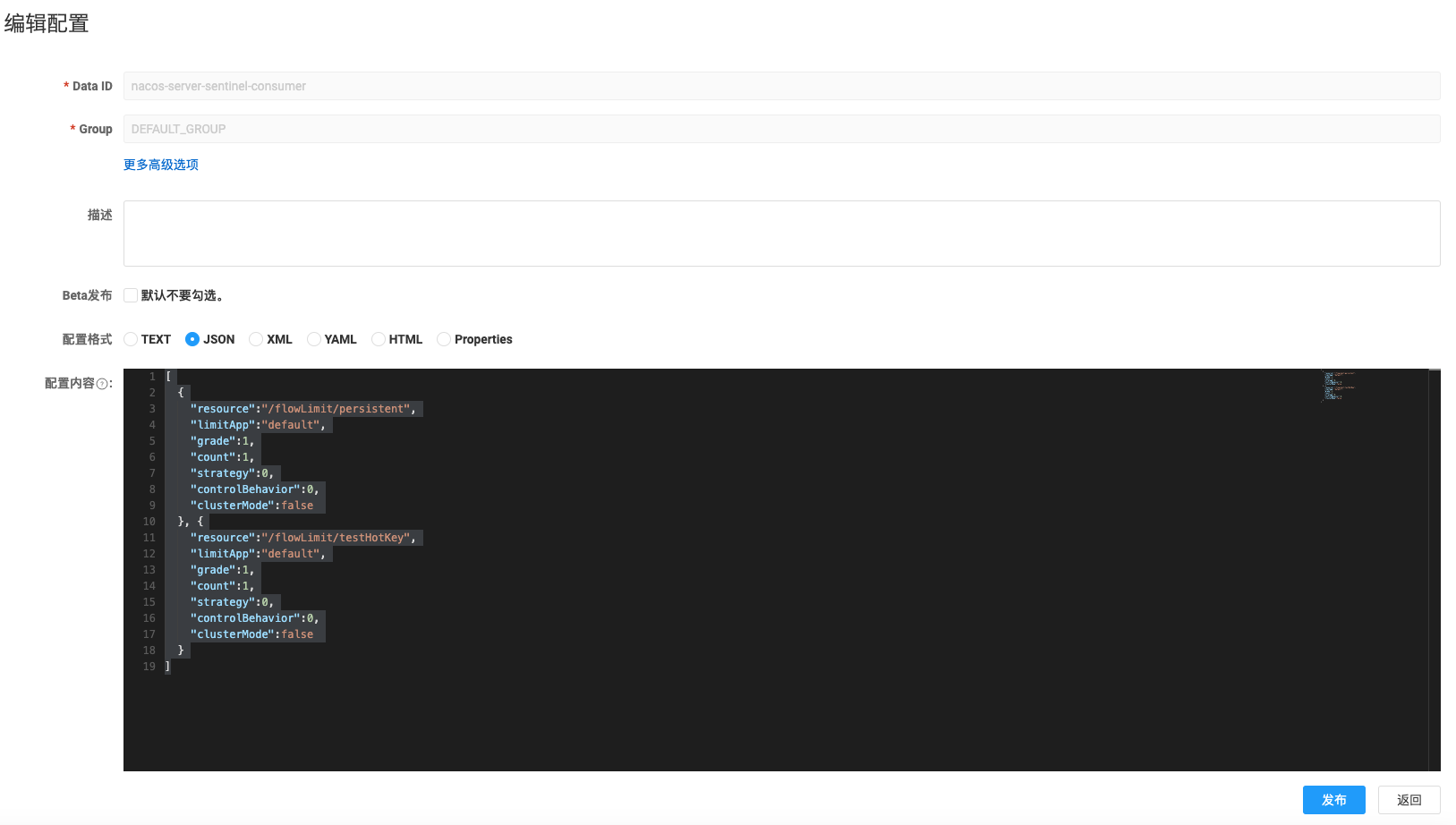
# 27.sentinel 持久化
主要分为拉模式和推模式
拉模式:持久化到本地文件推模式:持久化到 nacos 或者 mysql
每次重启项目后在 Sentinel 中配置的规则都会清空,很是麻烦,我们可以通过持久化的方式解决这个问题。
可以将规则持久化到 nacos 或者 mysql,再最新的 sentinel1.8.6 版本,更新 sentinel 控制台和 nacos 是互通的,修改任何一个位置,另一处会跟着改变,这一点还是比较人性化的,但是启动的时候还是以 nacos 的配置为准。
[
{
"resource": "/flowLimit/persistent",
"limitApp": "default",
"grade": 1,
"count": 1,
"strategy": 0,
"controlBehavior": 0,
"clusterMode": false
},
{
"resource": "/flowLimit/testHotKey",
"limitApp": "default",
"grade": 1,
"count": 1,
"strategy": 0,
"controlBehavior": 0,
"clusterMode": false
}
]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 28.Sentinel 和 hystrix
| Items | Sentinel | Hystrix | remark |
|---|---|---|---|
| 隔离策略 | 信号量隔离(并发线程数限流)(模拟信号量) | 线程池隔离/信号量隔离 | Sentinel 不创建线程依赖 tomcat 或 jetty 容器的线程池,存在的问题就是运行容器的线程数量限制了 sentinel 设置值的上限可能设置不准。比如 tomcat 线程池为 10,sentinel 设置 100 是没有意义的,同时隔离性不好 hystrix 使用自己创建的线程池,隔离性会更好 |
| 熔断降级策略 | 基于响应时间、异常比率、异常数 | 基于异常比率 | 快速失败的本质功能 |
| 实时统计实现 | 滑动窗口(LeapArray) | 滑动窗口(基于 RxJava) | |
| 动态规则配置 | 支持多种数据源 | 支持多种数据源 | |
| 扩展性 | 多个扩展点 | 插件的形式 | |
| 基于注解的支持 | 支持 | 支持 | |
| 限流 | 基于 QPS,支持基于调用关系的限流 | 有限的支持(并发线程数或信号量大小) | 快速失败的本质功能 |
| 流量整形 | 支持预热模式、匀速器模式、预热排队模式 | 不支持(排队) | 支持排队好吧 |
| 系统自适应保护 | 支持(仅对 linux 生效) | 不支持 | 所谓的自适应就是设置一个服务器最大允许处理量的阈值。(有比没有强,但是要知道最大负载量是多少。) |
| 控制台 | 提供开箱即用的控制台,可配置规则、查看秒级监控、机器发现等 | 简单的监控查看接近实时数据 | 控制台是非常有竞争力的功能,因为能集中配置限制数据更方便,但是展示数据和实时性没有 hystrix 直观。 |
| 配置持久化 | ZooKeeper, Apollo, Nacos | Git/svn/本地文件 | Sentinel 客户端采用直接链接持久化存储,应用客户端引用了更多的依赖,同样的存储链接可能有多个配置 |
| 动态配置 | 支持 | 支持 | hystrix 可能需要手动触发,sentinel 增加了额外的端口进行配置文件控制,应该也支持 spring boot 动态配置 |
| 黑白名单 | 支持 | 不支持 | 个人觉得这个功能用的不是很多 |
| springcloud 集成 | 高 | 非常高 | Spring boot 使用 hystrix 会更方便 |
| 整体优势 | 集中配置设置及监控+更细的控制规则 | 漂亮的界面+接近实时的统计结果 | 集中配置可能更有吸引力,但是配置值是多少以及让谁控制依然是很头疼的事情。运维控制可能不知道哪个应该优先哪个不优先,应该调整到多大。什么时候更适合使用 sentinel?个人认为 docker 容器化部署之后 sentinel 可能更会发挥作用,但是会有另外的竞品出现做选型。 |
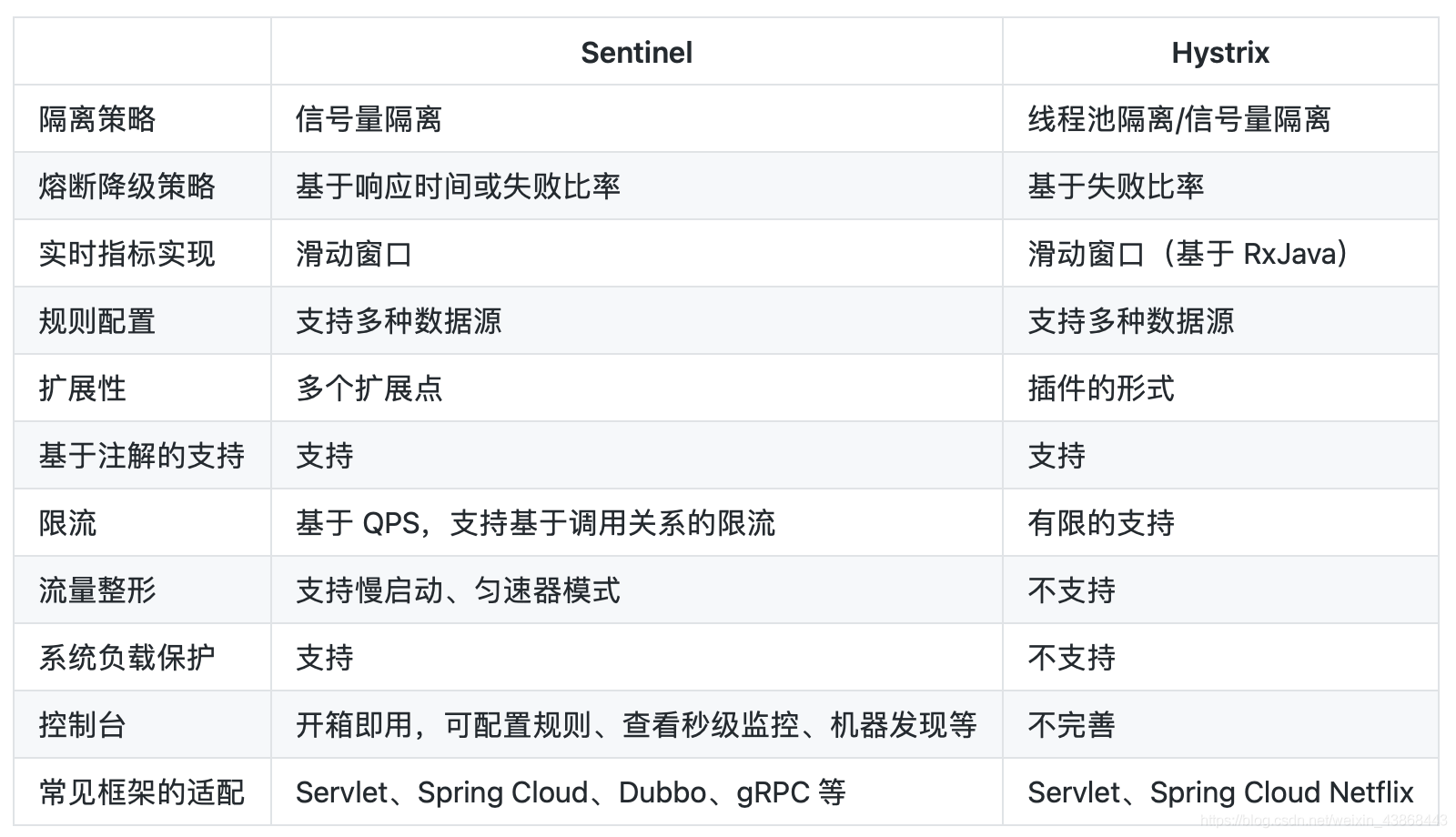
Hystrix 的资源模型设计上采用了命令模式,将对外部资源的调用和 fallback 逻辑封装成一个命令对象(HystrixCommand / HystrixObservableCommand),其底层的执行是基于 RxJava 实现的。每个 Command 创建时都要指定 commandKey 和 groupKey(用于区分资源)以及对应的隔离策略(线程池隔离 or 信号量隔离)。线程池隔离模式下需要配置线程池对应的参数(线程池名称、容量、排队超时等),然后 Command 就会在指定的线程池按照指定的容错策略执行;信号量隔离模式下需要配置最大并发数,执行 Command 时 Hystrix 就会限制其并发调用。
Sentinel 的设计则更为简单。相比 Hystrix Command 强依赖隔离规则,Sentinel 的资源定义与规则配置的耦合度更低。Hystrix 的 Command 强依赖于隔离规则配置的原因是隔离规则会直接影响 Command 的执行。在执行的时候 Hystrix 会解析 Command 的隔离规则来创建 RxJava Scheduler 并在其上调度执行,若是线程池模式则 Scheduler 底层的线程池为配置的线程池,若是信号量模式则简单包装成当前线程执行的 Scheduler。而 Sentinel 并不指定执行模型,也不关注应用是如何执行的。Sentinel 的原则非常简单:根据对应资源配置的规则来为资源执行相应的限流/降级/负载保护策略。在 Sentinel 中资源定义和规则配置是分离的。用户先通过 Sentinel API 给对应的业务逻辑定义资源(埋点),然后可以在需要的时候配置规则。埋点方式有两种:
- try-catch 方式(通过
SphU.entry(...)),用户在 catch 块中执行异常处理 / fallback - if-else 方式(通过
SphO.entry(...)),当返回 false 时执行异常处理 / fallback
从 0.1.1 版本开始,Sentinel 还支持基于注解的资源定义方式,可以通过注解参数指定异常处理函数和 fallback 函数。从 0.2.0 版本开始,Sentinel 引入异步调用链路支持,可以方便地统计异步调用资源的数据,维护异步调用链路,同时具备了适配异步框架/库的能力。
Sentinel 提供多样化的规则配置方式。除了直接通过 loadRules API 将规则注册到内存态之外,用户还可以注册各种外部数据源来提供动态的规则。用户可以根据系统当前的实时情况去动态地变更规则配置,数据源会将变更推送至 Sentinel 并即时生效。
隔离设计
隔离是 Hystrix 的核心功能之一。Hystrix 提供两种隔离策略:线程池隔离(Bulkhead Pattern)和信号量隔离,其中最推荐也是最常用的是线程池隔离。Hystrix 的线程池隔离针对不同的资源分别创建不同的线程池,不同服务调用都发生在不同的线程池中,在线程池排队、超时等阻塞情况时可以快速失败,并可以提供 fallback 机制。线程池隔离的好处是隔离度比较高,可以针对某个资源的线程池去进行处理而不影响其它资源,但是代价就是线程上下文切换的 overhead 比较大,特别是对低延时的调用有比较大的影响。
但是,实际情况下,线程池隔离并没有带来非常多的好处。首先就是过多的线程池会非常影响性能。考虑这样一个场景,在 Tomcat 之类的 Servlet 容器使用 Hystrix,本身 Tomcat 自身的线程数目就非常多了(可能到几十或一百多),如果加上 Hystrix 为各个资源创建的线程池,总共线程数目会非常多(几百个线程),这样上下文切换会有非常大的损耗。另外,线程池模式比较彻底的隔离性使得 Hystrix 可以针对不同资源线程池的排队、超时情况分别进行处理,但这其实是超时熔断和流量控制要解决的问题,如果组件具备了超时熔断和流量控制的能力,线程池隔离就显得没有那么必要了。
Hystrix 的信号量隔离限制对某个资源调用的并发数。这样的隔离非常轻量级,仅限制对某个资源调用的并发数,而不是显式地去创建线程池,所以 overhead 比较小,但是效果不错,也支持超时失败。Sentinel 可以通过并发线程数模式的流量控制来提供信号量隔离的功能。并且结合基于响应时间的熔断降级模式,可以在不稳定资源的平均响应时间比较高的时候自动降级,防止过多的慢调用占满并发数,影响整个系统。
限流方式不同::对应用服务器的请求做限制,避免因为过度请求导致服务器过载甚至宕机。限流算法常见的三种实现:滑动时间窗口、令牌桶算法、漏桶算法。
Gateway:则采用了基于 Redis 实现的令牌桶算法。
Sentinel:内部比较复杂
- 默认限流模式是基于
滑动时间窗口算法 排队等待的限流模式则基于漏桶算法热点参数限流是基于令牌桶算法
# 四.Skywalking
# 1.微服务架构
# 2.什么是 Skywalking
Skywalking 是一个国产的开源框架,2015 年由吴晟个人开源,2017 年加入 Apache 孵化器,国人开源的产品,主要开发人员来自于华为,2019 年 4 月 17 日 Apache 董事会批准 SkyWalking 成为顶级项目,支持 Java、.Net、NodeJs 等探针,数据存储支持 Mysql、Elasticsearch 等,跟 Pinpoint 一样采用字节码注入的方式实现代码的无侵入,探针采集数据粒度粗,但性能表现优秀,且对云原生支持,目前增长势头强劲,社区活跃。
Skywalking 是分布式系统的应用程序性能监视工具,专为微服务,云原生架构和基于容器(Docker,K8S,Mesos)架构而设计,它是一款优秀的 APM(Application Performance Management)工具,包括了分布式追踪,性能指标分析和服务依赖分析等。
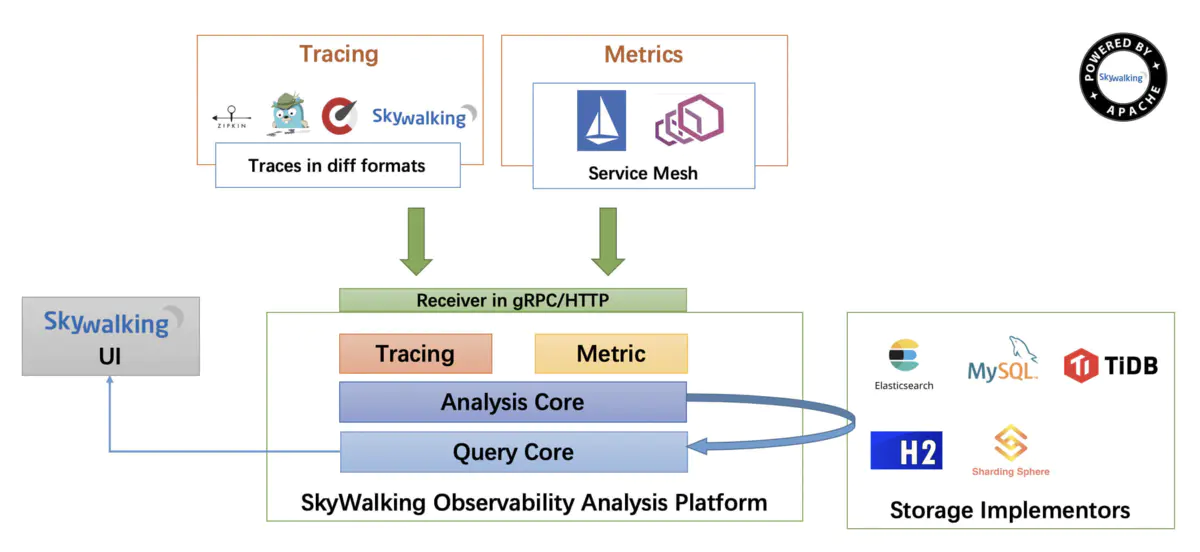
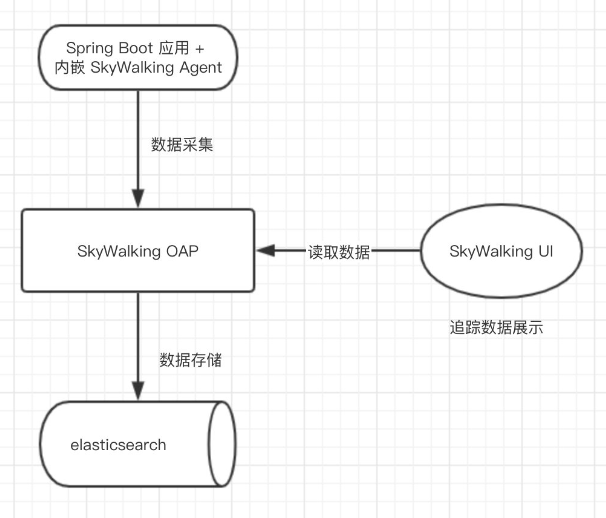
# 3.Skywalking 架构
SkyWalking 逻辑上分为四部分: 探针(节点数据采集), 平台后端(数据上报及分析), 存储(数据持久化)和用户界面(数据可视化)。
Skywalking agent和业务端绑定在一起,负责收集各种监控数据Skywalking oap service是负责处理监控数据,接受agent的数据并存储在数据库中,接受来自 UI 的请求,查询监控数据。Skywalking UI提供给用户,展现各种监控数据和告警。- 数据持久化
# 4.采集过程
完整的采集过程:
- 一个
Trace对应一次完整的调用链路。 - 一个线程内的调用对应一个
TraceSegement。 - 同一个线程内方法每调用一次就生成一个
Span,同时spanId + 1。 - 跨进程(如服务之间的调用)或跨线程(如异步调用)生成新的
TraceSegement和Sapn,并通过指针指向上游链路信息。
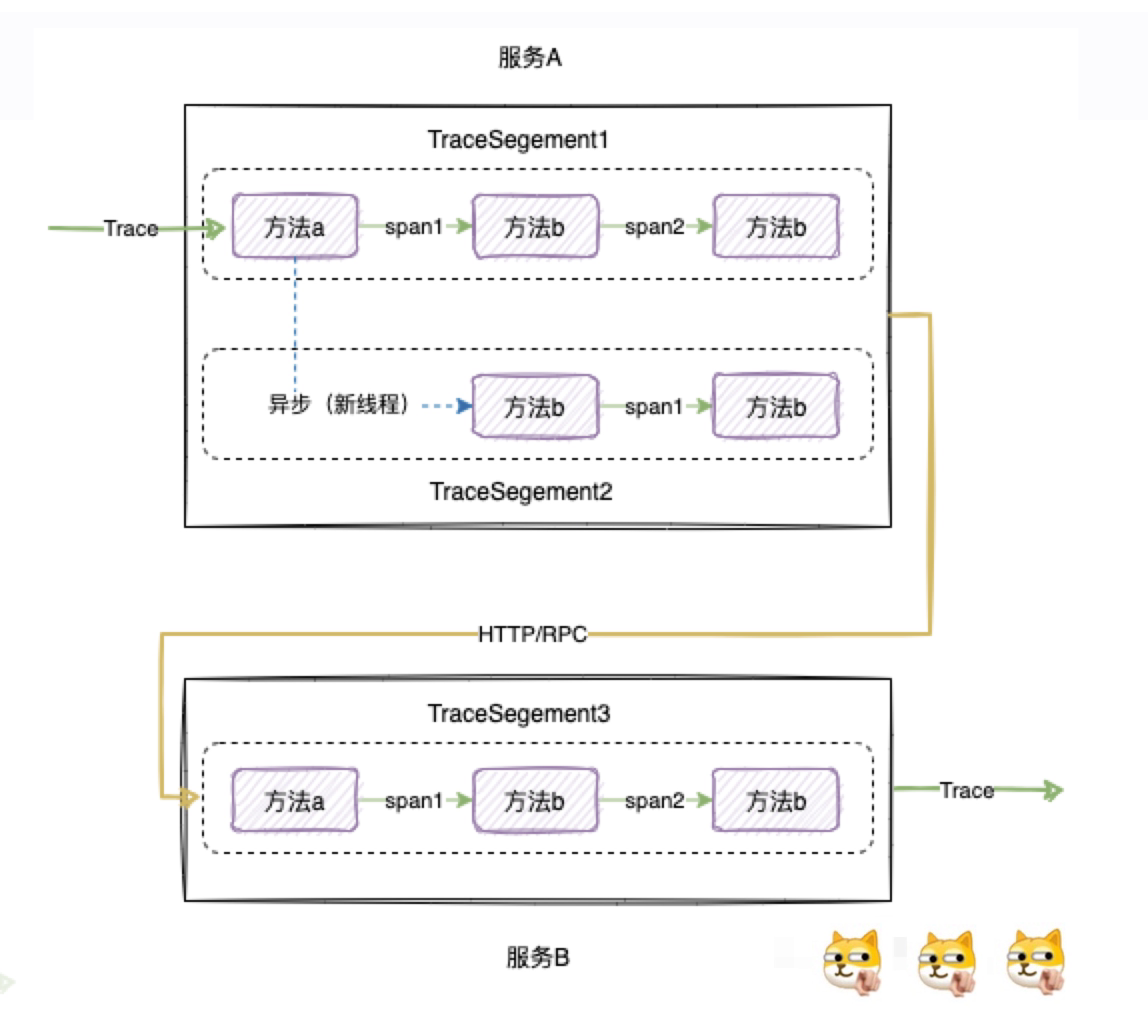
Skywalking 的链路追踪数据的采集过程其实是一个生产者-消费者模型。
生产消费全景图
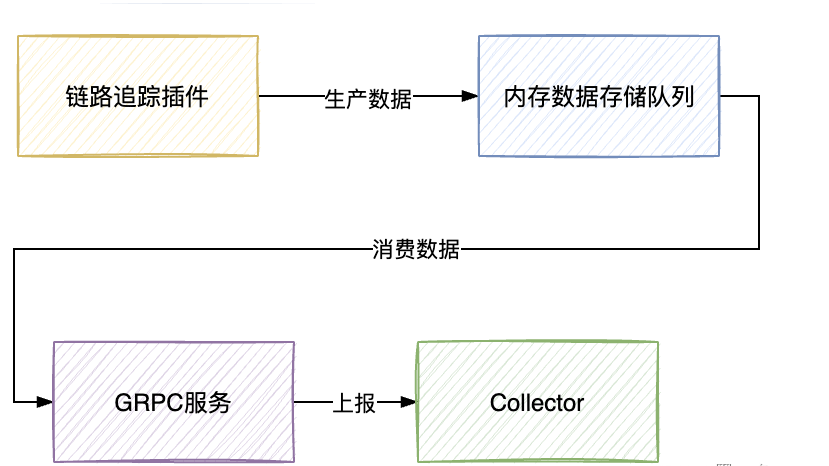
# 5.功能特性
功能:
- 服务、服务实例、端点(URI)
指标分析 分布式跟踪和上下文传播- 服务实例和端点(URI)
依赖关系分析 数据库访问指标。检测慢速数据库访问语句(包括 SQL 语句)基础设施(虚拟机、网络、磁盘等)监控根本原因分析。在运行时上分析由进程内代理和 ebpf 分析器支持的代码。- 业务拓扑图分析
- 服务和端点检测速度慢
- 性能优化
- 消息队列性能和消耗延迟监视
- 浏览器性能监控
- 跨指标、跟踪和日志的协作
- 告警
特点:
- 多语言支持,符合技术栈的 Agent 包括 net Core、PHP、NodeJS、Golang、LUA、Rust 和 c++代理,积极开发和维护。用于 C、c++、Golang 和 Rust 的 eBPF 分析器作为附加。
- 为多种开源项目提供了插件,为 Tomcat、 HttpClient、Spring、RabbitMQ、MySQL 等常见基础设施和组件提供了自动探针。
- 微内核 + 插件的架构,模块化,可插拔,存储、集群管理、使用插件集合都可以进行自由选择。
- 优秀的可视化效果。
- 支持告警。
- 轻量高效,无需大数据平台和大量的服务器资源。
- 多种监控手段,可以通过语言探针和 service mesh 获得监控的数据。
# 6.工作原理?
Skywalking 使用“Agent”对服务进行监控,它可以把系统划分为多个请求,然后把它们彼此关联起来,并将相关信息发送到 Skywalking Collector,Collector 会把它们汇总起来,生成有用的报告和可视化图表,供用户使用。Skywalking 的还有一个 UI 界面也可以直接查看相关数据
它的工作原理很简单,首先将受监控服务组件连接到 SkywalkingCollector,然后收集操作日志,性能数据,应用的状态等信息,并将数据上送到 Skywalking Collector。Skywalking Collector 会把这些数据存储到 Elasticsearch 中,Elasticsearch 是存储搜索引擎,它会把收集的数据分析出来,然后把分析出来的数据发送到 SkywalkingUI 界面,这样用户就可以直接在 Skywalking UI 界面查看这些数据了 skywalking 还允许用户通过 Restful API 进行数据查询,以便用户可以自定义数据并获取最新数据。
要使用 SkyWalking,需要给我们的项目中绑定一个agent 探针,绑定后,SkyWalking 就会将你项目整体的监控数据反馈给 SkyWalking oap service,SkyWalking oap service 就是 SkyWalking 的服务端,oap service 会将这些监控数据做处理,然后存储到数据库中:SkyWalking 支持的数据库有很多种:ES,MysqL 等等很多都支持;然后 SkyWalking 提供了一个前端的可视化 ui 界面,我们程序员可以通过这个 ui 界面方便的查看到我们项目整体的数据,因为这个前端界面会向 oapservice 发送请求查询数据;
# 7.持久化方式?
在 application.yml 中配置持久化方式.默认的存储方式就是采用的 h2 数据库,这是一种基于内存的数据库,我们不用它,因为它基于内存,只要一重启 skywalking,这些监控数据就会消失;
- H2 内存数据库
- ElasticSearch 持久化存储,最优方案,是企业的首选方案
- MySQL 持久化存储
- ShardingSphere 持久化存储
- TiDB 持久化存储
# 8.oap service 的端口
oap service 自动暴露了两个端口,11800 端口和 12800 端口;
11800端口是 oap service 用来收集微服务监控数据的gRPC端口,12800是 oapservice 用来接收前端 ui 界面请求的HTTP端口;8080是 UI 所占用的端口
我们也可以通过 config 文件夹下的 application.yaml 来修改这些端口号;
注意:在我们自己的微服务中,要将 oapservice 的端口号告诉给我们的微服务,否则我们自己的微服务是不知道 oapservice 的端口的,就没有传递监控数据给 oapservice 了。
# 9.全链路监控目标要求?
探针的性能消:APM 组件服务的影响应该做到足够小。服务调用埋点本身会带来性能损耗,这就需要调用跟踪的低损耗,实际中还会通过配置采样率的方式,选择一部分请求去分析请求路径。在一些高度优化过的服务,即使一点点损耗也会很容易察觉到,而且有可能迫使在线服务的部署团队不得不将跟踪系统关停。
代码的侵入性:即也作为业务组件,应当尽可能少入侵或者无入侵其他业务系统,对于使用方透明,减少开发人员的负担。对于应用的程序员来说,是不需要知道有跟踪系统这回事的。如果一个跟踪系统想生效,就必须需要依赖应用的开发者主动配合,那么这个跟踪系统也太脆弱了,往往由于跟踪系统在应用中植入代码的 bug 或疏忽导致应用出问题,这样才是无法满足对跟踪系统“无所不在的部署”这个需求。
可扩展性:一个优秀的调用跟踪系统必须支持分布式部署,具备良好的可扩展性。能够支持的组件越多当然越好。或者提供便捷的插件开发 API,对于一些没有监控到的组件,应用开发者也可以自行扩展。
数据的分析:数据的分析要快 ,分析的维度尽可能多。跟踪系统能提供足够快的信息反馈,就可以对生产环境下的异常状况做出快速反应。分析的全面,能够避免二次开发。
# 10.APM 对比
目前市面上开源的 APM 系统主要有 CAT、Zipkin、Pinpoint、SkyWalking,大都是参考 Google 的 Dapper实现的
Zipkin是 Twitter 开源的调用链路分析工具,目前基于 Spingcloud sleuth 得到了广泛的应用,特点是轻量,部署简单。Pinpoint是一个韩国团队开源的产品,运用了字节码增强技术,只需要在启动时添加启动参数即可,对代码无侵入,目前支持 Java 和 PHP 语言,底层采用 HBase 来存储数据,探针收集的数据粒度非常细,但性能损耗大,因其出现的时间较长,完成度也很高,应用的公司较多Skywalking是本土开源的基于字节码注入的调用链路分析以及应用监控分析工具,特点是支持多种插件,UI 功能较强,接入端无代码侵入。CAT是由国内美团点评开源的,基于 Java 语言开发,目前提供 Java、C/C++、Node.js、Python、Go 等语言的客户端,监控数据会全量统计,国内很多公司在用,例如美团点评、携程、拼多多等,CAT 跟下边要介绍的 Zipkin 都需要在应用程序中埋点,对代码侵入性强。
| Pinpoint | Zipkin | Jaeger | SkyWalking | |
|---|---|---|---|---|
| OpenTracing 兼容 | 否 | 是 | 是 | 是 |
| 客户端支持语言 | java,php | java,c#,go,php 等 | java,c#,go,php 等 | java, .net core,nodejs,php |
| 存储 | hbase | es,mysql,Cassandra,内存 | es,mysql,Cassandra,内存 | es,h2,msyql,tidb,sharding sphere |
| 传输协议支持 | thrift | http,MQ | udp,http | gRPC,http |
| UI 丰富程度 | 高 | 低 | 中 | 中 |
| 实现方式 | 字节码注入,无侵入 | 拦截请求,侵入 | 拦截请求,侵入 | 字节码注入,无侵入 |
| 扩展性 | 低 | 高 | 高 | 中 |
| Trace 查询 | 不支持 | 支持 | 支持 | 支持 |
| 告警支持 | 支持 | 不支持 | 不支持 | 支持 |
| JVM 监控 | 支持 | 不支持 | 不支持 | 支持 |
| 性能损失 | 高 | 中 | 中 | 低 |
# 五.Seata
# 1.Seata 是什么?
Seata 是一款开源的分布式事务解决方案,致力于提供高性能和简单易用的分布式事务服务。Seata 将为用户提供了 AT、TCC、SAGA 和 XA 事务模式,为用户打造一站式的分布式解决方案。
# 2.Seata 的组成
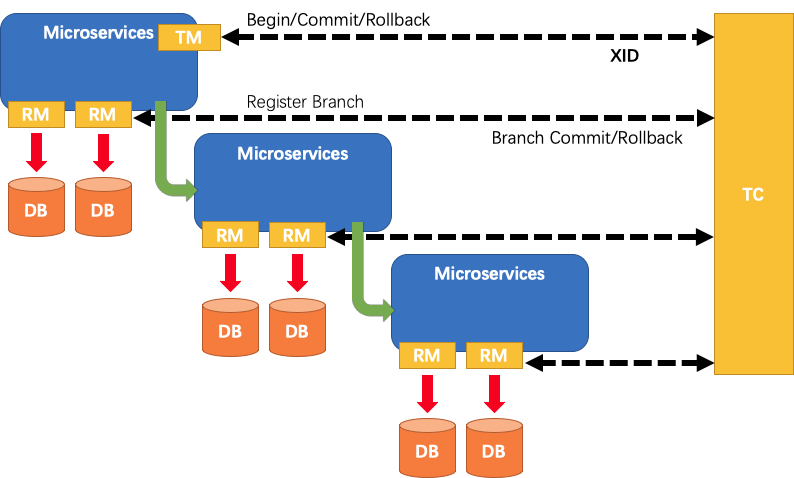
Seate 是一个典型的分布式事务处理过程,由一个 ID 和三组件模型组成
一个 ID:全局唯一的事务 ID
TC(Transaction Coordinator) - 事务协调者:维护全局和分支事务的状态,驱动全局事务提交或回滚。TM(Transaction Manager) - 事务管理器:定义全局事务的范围:开始全局事务、提交或回滚全局事务。RM(Resource Manager) - 资源管理器:管理分支事务处理的资源,与 TC 交谈以注册分支事务和报告分支事务的状态,并驱动分支事务提交或回滚。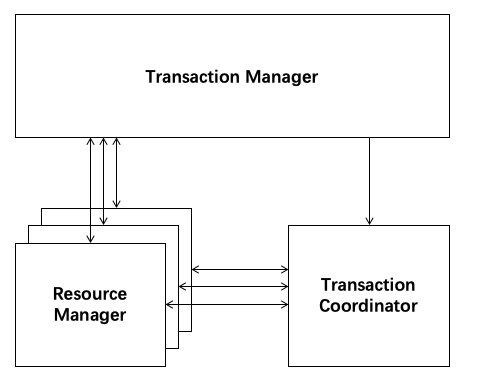
Seata的实现原理基于两阶段提交(Two-Phase Commit)协议,具体的机制如下:
- 一阶段:在事务提交的过程中,首先进行预提交阶段。事务协调器向各个资源管理器发送预提交请求,资源管理器执行相应的事务操作并返回执行结果。在此阶段,业务数据和回滚日志记录在同一个本地事务中提交,并释放本地锁和连接资源。
- 二阶段:在预提交阶段成功后,进入真正的提交阶段。此阶段主要包括提交异步化和回滚反向补偿两个步骤:
- 提交异步化:事务协调器发出真正的提交请求,各个资源管理器执行最终的提交操作。这个阶段的操作是非常快速的,以确保事务的提交效率。
- 回滚反向补偿:如果在预提交阶段中有任何一个资源管理器返回失败结果,事务协调器发出回滚请求,各个资源管理器执行回滚操作,利用一阶段的回滚日志进行反向补偿。
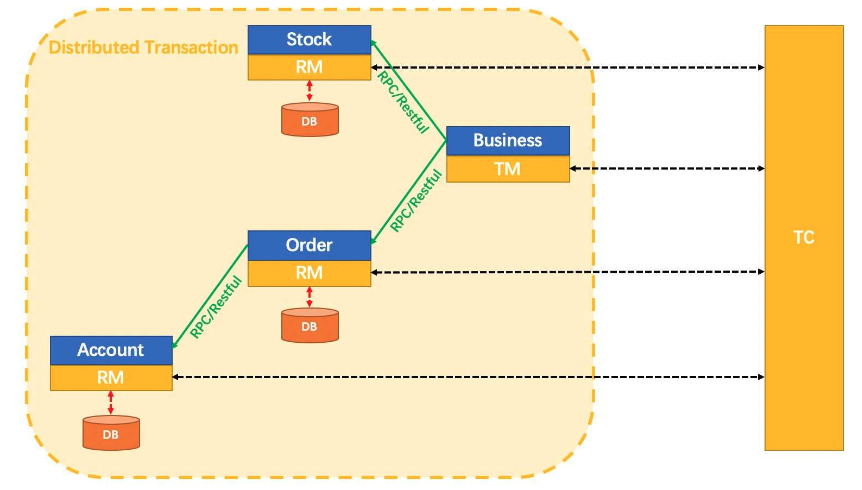
# 3.Seata 架构图
# 4.调度生命周期?
- TM 向 TC 申请开启一个
全局事务,全局事务创建成功并生成一个全局唯一的 XID; XID在微服务调用链路的上下文中传播RM向TC注册分支事务,将其纳入XID对应全局事务的管辖;TM向TC发起针对XID的全局提交或回滚决议;TC调度XID下管辖的全部分支事务完成提交或回滚请求
# 5.存储模式
因为 TC 需要进行全局事务和分支事务的记录,所以需要对应的存储。
目前,TC 有三种存储模式( store.mode):
file模式:适合单机模式,全局事务会话信息在内存中读写,并持久化本地文件 root.data,性能较高;db模式:适合集群模式,全局事务会话信息通过 db 共享,相对性能差点:redis模式:解决 db 存储的性能问题我们先采用 file 模式,最终我们部署单机 TC Server 如下图所示
# 6.Seata 的四种模式?
AT模式TCC模式Saga模式XA模式
# 7.AT 模式
AT(Atomikos)模式:AT 模式是 Seata 默认支持的模式,也是最常用的模式之一。在 AT 模式下,Seata 通过在业务代码中嵌入事务上下文,实现对分布式事务的管理。Seata 会拦截并解析业务代码中的 SQL 语句,通过对数据库连接进行拦截和代理,实现事务的管理和协调。
前提条件:
- 基于支持本地
ACID事务的关系型数据库。 - Java 应用,通过
JDBC访问数据库。
实现机制:
两阶段提交协议的演变:
- 一阶段:
业务数据和回滚日志记录在同一个本地事务中提交,释放本地锁和连接资源。 - 二阶段:
- 提交异步化,非常快速地完成。
- 回滚通过一阶段的回滚日志进行
反向补偿。
# 8.AT 模式工作机制
Seata首先要求在业务表所在的数据库中创建一个undo_log表,用于记录回滚sql。所谓回滚sql就是与所执行sql相反的sql,比如执行了一个insert语句,那么对应的undo log就是一条delete语句。业务表执行了操作后,seata 会将执行的 sql 进行解析,生成回滚 sql 并且存储到
undo_log表中本地事务提交前,会向 seata 的服务端注册分支,申请对应的业务表中对应数据行的全局锁,这时其他的事务就无法对这条数据进行更新操作。
本地事务提交,业务数据的更新和前面生成的
undo log会一起提交将本地事务的执行结果上报给 seata 服务端。也就是说 seata 服务端会记录多个服务的本地事务。同时这些本地事务因为在
seata服务端的管控之下,所以使用的事务 ID 和分支 ID 都是一样的。如果某一个本地事务发生报错,那么 seata 服务端就会发起对应分支的回滚请求
同时开启一个本地事务,然后通过
事务 ID和分支 ID去undo_log表查询到对应的回滚 sql。并且执行回滚 sql,再将执行结果上报给 seata 服务端如果没有发生报错,seata 服务端也会在对应分支发起请求,然后会
异步批量的删除 undo_log表中的记录总结一句话,为什么能实现分布式事务,就是因为
seata服务端将这些本地事务都记录下来了,同时也在每个库中记录了undo log。当有一个报错时,就找到这同一组的所有的本地事务,然后统一利用记录的undo log回退数据
undo log 表涉及的字段。其中 xid 就是事务 ID,branch_id 就是分支 ID
# 9.TCC 模式?
TCC(Try-Confirm-Cancel)模式:TCC 模式是一种基于补偿机制的分布式事务模式。在 TCC 模式中,业务逻辑需要实现 Try、Confirm 和 Cancel 三个阶段的操作。Seata 通过调用业务代码中的 Try、Confirm 和 Cancel 方法,并在每个阶段记录相关的操作日志,来实现分布式事务的一致性。
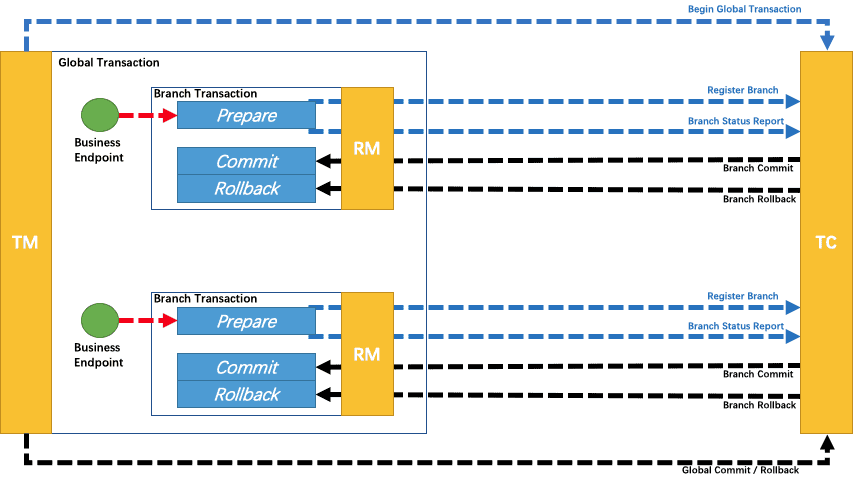
一个分布式的全局事务,整体是 两阶段提交 的模型。全局事务是由若干分支事务组成的,分支事务要满足 两阶段提交 的模型要求,即需要每个分支事务都具备自己的:
- 一阶段
prepare行为 - 二阶段
commit或rollback行为
根据两阶段行为模式的不同,我们将分支事务划分为 Automatic (Branch) Transaction Mode 和 Manual (Branch) Transaction Mode.
AT 模式支持本地 ACID 事务的关系型数据库:
- 一阶段
prepare行为:在本地事务中,一并提交业务数据更新和相应回滚日志记录。 - 二阶段
commit行为:马上成功结束,自动 异步批量清理回滚日志。 - 二阶段
rollback行为:通过回滚日志,自动 生成补偿操作,完成数据回滚。
相应的,TCC模式,不依赖于底层数据资源的事务支持:
- 一阶段
prepare行为:调用 自定义 的 prepare 逻辑。 - 二阶段
commit行为:调用 自定义 的 commit 逻辑。 - 二阶段
rollback行为:调用 自定义 的 rollback 逻辑。
所谓 TCC 模式,是指支持把 自定义 的分支事务纳入到全局事务的管理中。
//在接口上加@LocalTCC
//在实现类上加@TwoPhaseBusinessAction注解
@TwoPhaseBusinessAction(name ="reducestock", commitMethod ="commitTcc",rollbackMethod ="cancelTcc")
Product reduceStock(BusinessActionContextparameter(paramame = "productid") Integer productid,@BusinessActionContextParameter(paramName = "amount") Integer amount);
2
3
4
5
# 10.Saga 模式
SAGA 模式:SAGA 模式是一种基于事件驱动的分布式事务模式。在 SAGA 模式中,每个服务都可以发布和订阅事件,通过事件的传递和处理来实现分布式事务的一致性。Seata 提供了与 SAGA 模式兼容的 Saga 框架,用于管理和协调分布式事务的各个阶段。
Saga模式:是 SEATA 提供的长事务解决方案,在 Saga 模式中,业务流程中每个参与者都提交本地事务,当出现某一个参与者失败则补偿前面已经成功的参与者,一阶段正向服务和二阶段补偿服务都由业务开发实现。
Saga模式适用场景:
- 业务
流程长、业务流程多 - 参与者包含其它公司或遗留系统服务,无法提供 TCC 模式要求的三个接口
优势:
- 一阶段提交本地事务,无锁,高性能
- 事件驱动架构,参与者可异步执行,高吞吐
- 补偿服务易于实现
缺点:
- 不保证隔离性
# 11.XA 模式
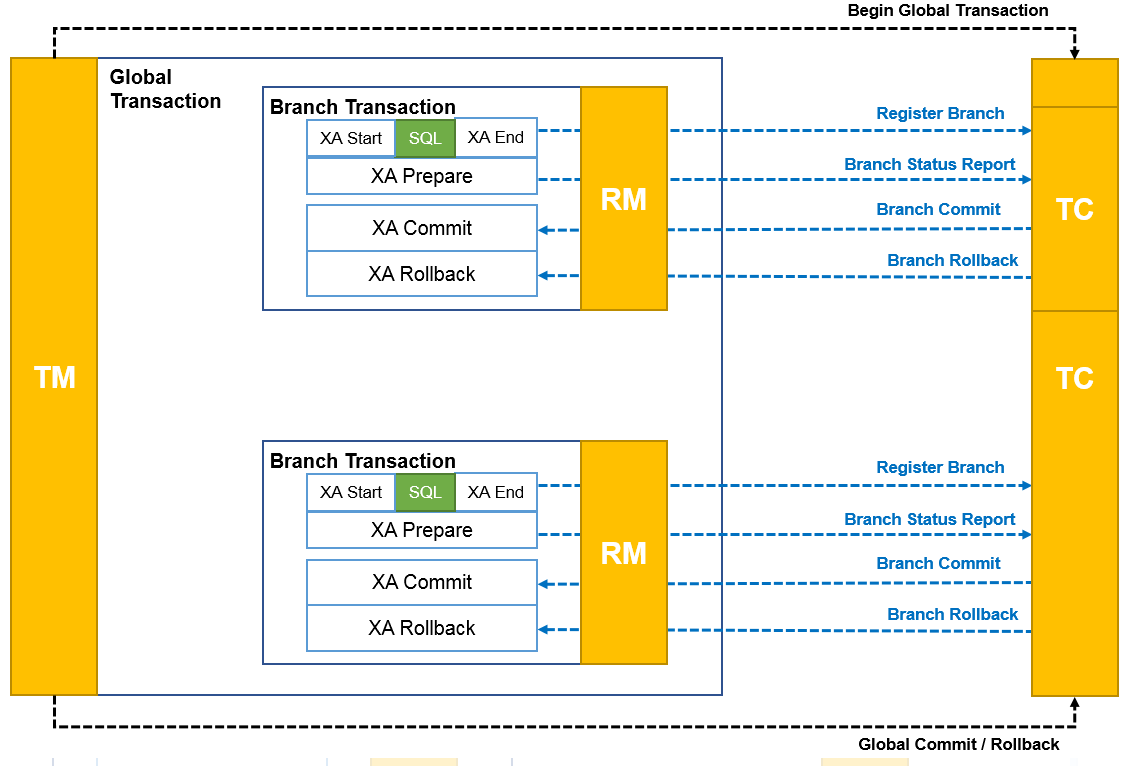
XA 模式:XA 模式是一种基于两阶段提交(Two-Phase Commit)协议的分布式事务模式。在 XA 模式中,Seata 通过与数据库的 XA 事务协议进行交互,实现对分布式事务的管理和协调。XA 模式需要数据库本身支持 XA 事务,并且需要在应用程序中配置相应的 XA 数据源。
XA 模式 RM 驱动分支事务的行为包含以下两个阶段:
执行阶段:- 向 TC 注册分支
XAStart,执行业务 SQL,XA EndXAprepare,并向 TC 上报 XA 分支的执行情况:成功或失败
完成阶段:- 收到
TC的分支提交请求,XACommit - 收到
TC的分支回滚请求,XARollback
- 收到
# 12.Seata 写隔离?
- 一阶段本地事务提交前,需要确保先拿到 全局锁 。
- 拿不到 全局锁 ,不能提交本地事务。
- 拿全局锁 的尝试被限制在一定范围内,超出范围将放弃,并回滚本地事务,释放本地锁。
以一个示例来说明:
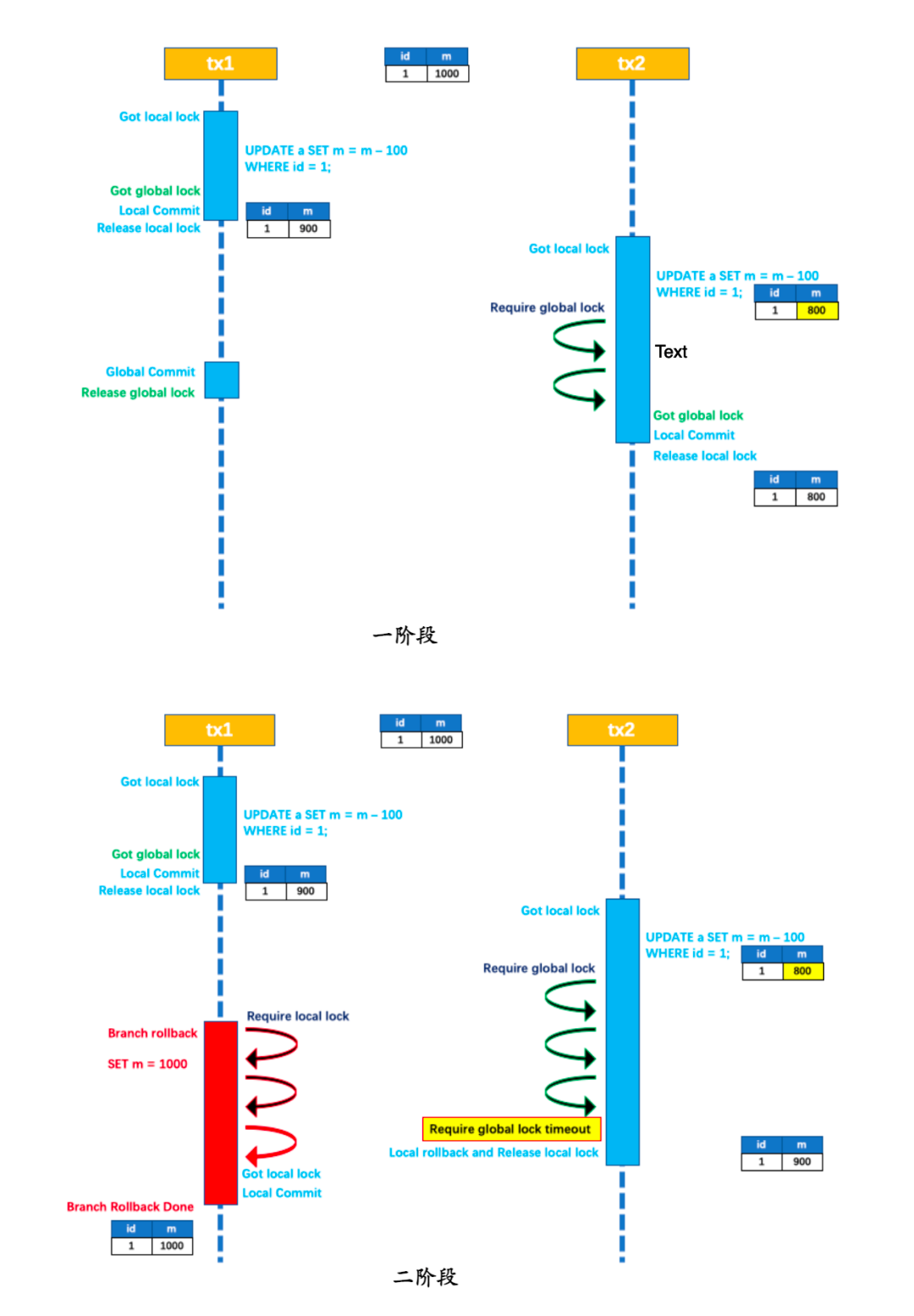
两个全局事务 tx1 和 tx2,分别对 a 表的 m 字段进行更新操作,m 的初始值 1000。
tx1 先开始,开启本地事务,拿到本地锁,更新操作 m = 1000 - 100 = 900。本地事务提交前,先拿到该记录的 全局锁 ,本地提交释放本地锁。 tx2 后开始,开启本地事务,拿到本地锁,更新操作 m = 900 - 100 = 800。本地事务提交前,尝试拿该记录的全局锁,tx1 全局提交前,该记录的全局锁被 tx1 持有,tx2 需要重试等待全局锁 。
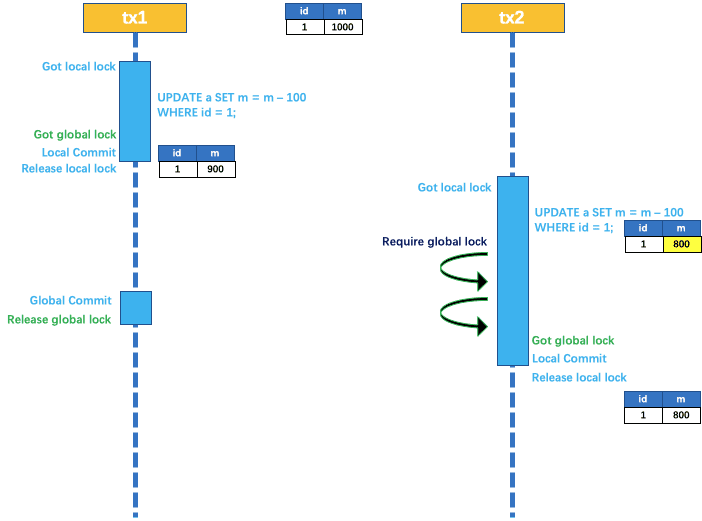
tx1 二阶段全局提交,释放 全局锁 。tx2 拿到 全局锁 提交本地事务。
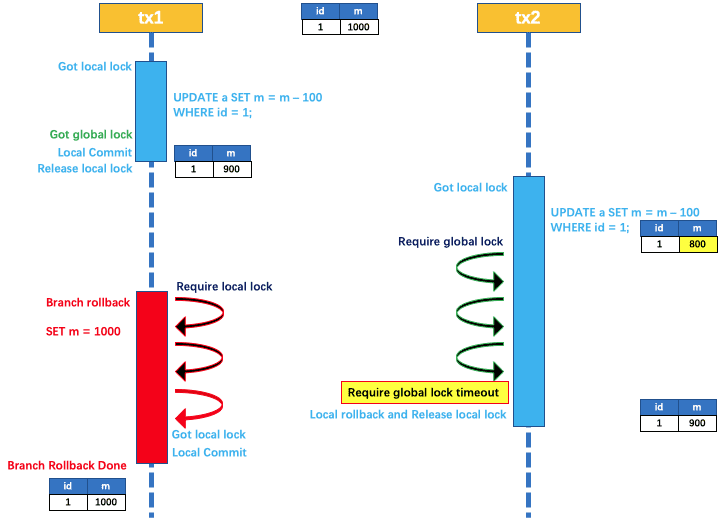
如果 tx1 的二阶段全局回滚,则 tx1 需要重新获取该数据的本地锁,进行反向补偿的更新操作,实现分支的回滚。
此时,如果 tx2 仍在等待该数据的 全局锁,同时持有本地锁,则 tx1 的分支回滚会失败。分支的回滚会一直重试,直到 tx2 的 全局锁 等锁超时,放弃 全局锁 并回滚本地事务释放本地锁,tx1 的分支回滚最终成功。
因为整个过程 全局锁 在 tx1 结束前一直是被 tx1 持有的,所以不会发生 脏写 的问题。
# 13.Seata 读隔离?
在数据库本地事务隔离级别 读已提交(Read Committed) 或以上的基础上,Seata(AT 模式)的默认全局隔离级别是 读未提交(Read Uncommitted) 。
如果应用在特定场景下,必需要求全局的 读已提交 ,目前 Seata 的方式是通过 SELECT FOR UPDATE 语句的代理。
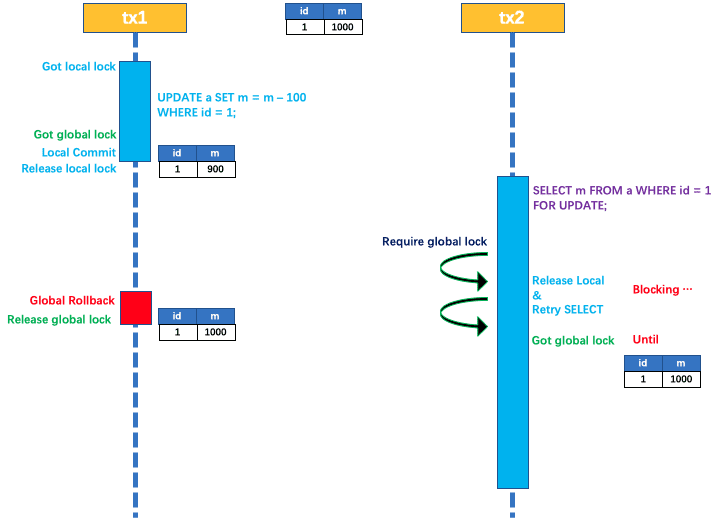
SELECT FOR UPDATE 语句的执行会申请 全局锁 ,如果 全局锁 被其他事务持有,则释放本地锁(回滚 SELECT FOR UPDATE 语句的本地执行)并重试。这个过程中,查询是被 block 住的,直到 全局锁 拿到,即读取的相关数据是 已提交 的,才返回。
出于总体性能上的考虑,Seata 目前的方案并没有对所有 SELECT 语句都进行代理,仅针对 FOR UPDATE 的 SELECT 语句。
# 14.保证事务的隔离性?
因 seata 一阶段本地事务已提交,为防止其他事务脏读脏写需要加强隔离。
- 脏读 select 语句加 for update,代理方法增加@GlobalLock+@Transactional 或
@GlobalTransactional - 脏写 必须使用
@GlobalTransactional
注:如果你查询的业务的接口没有@GlobalTransactional 包裹,也就是这个方法上压根没有分布式事务的需求,这时你可以在方法上标注@GlobalLock+@Transactional 注解,并且在查询语句上加 for update。 如果你查询的接口在事务链路上外层有@GlobalTransactional 注解,那么你查询的语句只要加 for update 就行。设计这个注解的原因是在没有这个注解之前,需要查询分布式事务读已提交的数据,但业务本身不需要分布式事务。 若使用@GlobalTransactional 注解就会增加一些没用的额外的 rpc 开销比如 begin 返回 xid,提交事务等。GlobalLock 简化了 rpc 过程,使其做到更高的性能。
# 15.undo_log 表
CREATE TABLE `undo_log` (
`id` bigint NOT NULL AUTO_INCREMENT,
`branch_id` bigint NOT NULL,
`xid` varchar(100) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci NOT NULL,
`context` varchar(128) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci NOT NULL,
`rollback_info` longblob NOT NULL,
`log_status` int NOT NULL,
`log_created` datetime NOT NULL,
`log_modified` datetime NOT NULL,
`ext` varchar(100) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE,
UNIQUE KEY `ux_undo_log` (`xid`,`branch_id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=16 DEFAULT CHARSET=utf8mb3 ROW_FORMAT=DYNAMIC;
2
3
4
5
6
7
8
9
10
11
12
13
id: 这是一个自增的大整数类型列,作为主键,用来唯一标识每一行数据。branch_id: 这是一个大整数类型列,用于标识事务分支。xid: 这是一个最大长度为 100 个字符的字符串类型列,用于存储全局事务 ID。context: 这是一个最大长度为 128 个字符的字符串类型列,可能用于存储与事务相关的上下文信息。rollback_info: 这是一个长二进制类型列,可能用于存储事务回滚信息。长二进制类型通常用于存储二进制数据,如序列化对象等。log_status: 这是一个整数类型列,用于表示日志状态。log_created: 这是一个日期时间类型列,用于表示日志创建的时间。log_modified: 这是一个日期时间类型列,用于表示日志修改的时间。ext: 这是一个最大长度为 100 个字符的字符串类型列,可能用于存储额外的信息。PRIMARY KEY: 这是用来指定主键约束的关键字,表明id列是主键。UNIQUE KEY: 这是用来指定唯一键约束的关键字,表明(xid, branch_id)列的组合是唯一的。ENGINE=InnoDB: 这是用来指定存储引擎的名称,这里使用的是 InnoDB 引擎。DEFAULT CHARSET=utf8mb3: 这是用来指定默认字符集。ROW_FORMAT=DYNAMIC: 这是用来指定行格式。
表的结构设计是为了存储与分布式事务相关的回滚日志,以保证分布式系统中的数据一致性。xid 和 branch_id 似乎用于标识全局事务和分支,rollback_info 可能用于存储回滚所需的信息,而 log_status 和日期时间列用于跟踪日志状态和操作时间。这些信息在分布式事务场景中通常是很有用的。
# 16.Seata 事务执行流程?
Seata 事务的执行流程可以简要概括为以下几个步骤:
- 事务发起方(Transaction Starter)发起全局事务:事务发起方是指发起分布式事务的应用程序或服务。它向 Seata 的事务协调器发送全局事务的开始请求,生成全局事务 ID(Global Transaction ID)。
- 事务协调器创建全局事务记录:事务协调器接收到全局事务的开始请求后,会为该事务创建相应的全局事务记录,并生成分支事务 ID(Branch Transaction ID)。
- 分支事务注册:事务发起方将全局事务 ID 和分支事务 ID 发送给各个参与者(Participant),即资源管理器。参与者将分支事务 ID 注册到本地事务管理器,并将事务的执行结果反馈给事务协调器。
- 执行业务逻辑:在分布式事务的上下文中,各个参与者执行各自的本地事务,即执行业务逻辑和数据库操作。
- 预提交阶段:事务发起方向事务协调器发送预提交请求,事务协调器将预提交请求发送给各个参与者。
- 执行本地事务确认:参与者接收到预提交请求后,执行本地事务的确认操作,并将本地事务的执行结果反馈给事务协调器。
- 全局事务提交或回滚:事务协调器根据参与者反馈的结果进行判断,如果所有参与者的本地事务都执行成功,事务协调器发送真正的提交请求给参与者,参与者执行最终的提交操作;如果有任何一个参与者的本地事务执行失败,事务协调器发送回滚请求给参与者,参与者执行回滚操作。
- 完成全局事务:事务协调器接收到参与者的提交或回滚结果后,根据结果更新全局事务的状态,并通知事务发起方全局事务的最终结果。
# 六.Apisix
# 1.什么是 Apisix?
APISIX 是一个微服务 API 网关,具有高性能、可扩展性等优点。它基于nginx(openresty)、Lua、etcd 实现功能,借鉴了 Kong 的思路。和传统的 API 网关相比,APISIX 具有较高的性能和较低的资源消耗,并且具有丰富的插件,也方便自己进行插件扩展。
作为一个脱胎于 NGINX 和 OpenResty 的软件,APISIX 人造继承了 NGINX 的性能和 OpenResty 的灵活性,因而,APISIX 的性能在一众 API 网关中都是首屈一指的。
# 2.Apisix 的优点?
具体来说,像 NGINX + Linux epoll 提供了高性能的网络 IO 基础设施,这些是 C 语言实现的,是动态的。而 OpenResty 则集成了 LuaJIT,它基于 NGINX 提供的生命周期钩子进行扩大,容许用户通过 Lua 代码对 NGINX 进行编程。而 LuaJIT 自身,得益于优良的 JIT 实现,它能够在运行时对代码进行 JIT 编译,当热门路上的内容被编译为机器码后,性能将能够与原生 C 语言相比。
没有复用 NGINX 的 location 来解决路由匹配,而是应用了基数树的形式。能够提供根本安稳的匹配速度。请求路由是通过查询 ETCD 的路由和消费方进行插件匹配,过滤得到可使用的插件后运行插件进行动态上游反向代理。
在 APISIX 中,上述配置操作过程都是齐全动静的,location 能够动静配置,upstream 和 SSL 证书这些全副都能够动静配置。这次要得益于 APISIX 应用了 etcd 作为配置核心,通过 etcd watch 机制实现了动静的更新其配置,从而不须要依赖 reload 和重启。
# 3.Apisix 架构
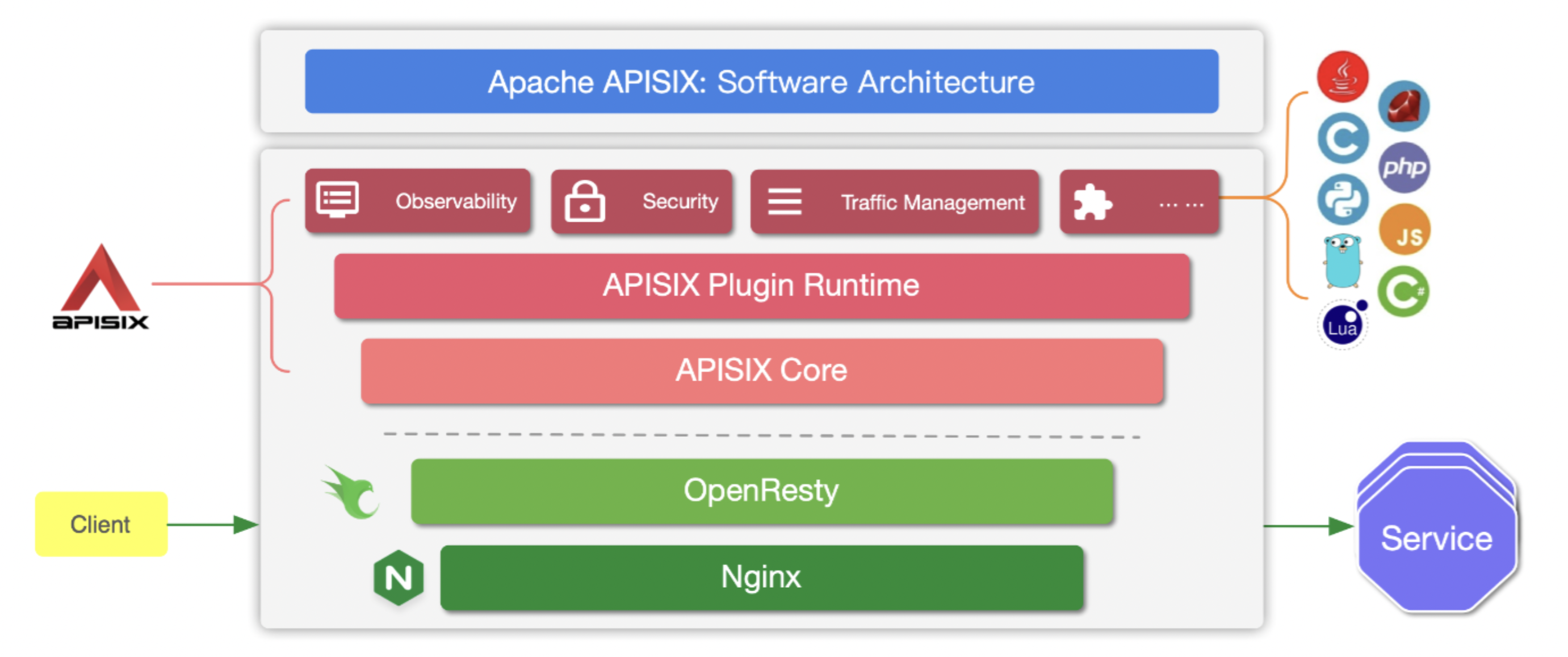
# 4.外围模块
APISIX 在外围模块中提供了很多开箱即用的性能,比方负载平衡、动静上游、灰度公布、服务熔断、身份认证、可观测性、服务发现、限流限速和日志收集等性能。
APISIX 中的很多性能都是通过插件形式进行实现的,目前 APISIX 的插件已靠近 80 个,将来还在继续扩大减少中。提到插件,不得不说 APISIX 提供的插件运行时是一个十分易于开发的插件框架,用户能够轻而易举地应用 Lua 编写本人的插件,来实现特定业务性能。如果切实不具备 Lua 的开发保护能力也能够应用内部 Plugin Runner(APISIX 多语言插件) 或者 WASM 开发插件。
# 5.基本概念
Route路由:路由是请求的入口点,它定义了客户端请求与服务之间的匹配规则,路由可以与服务(service)、上游(Upstream)关联,一个服务可以对应一组路由,一个路由可以对应一个上游对象(一组后端服务节点),因此,每个匹配到路由的请求将被网关代理到路由绑定的上游服务中。
Upstream上游服务:包含了已创建的上游服务(即后端服务),可以对上游服务的多个目标节点进行负载均衡和健康检查。
Service服务:服务由路由中公共的插件配置、上游目标信息组合而成。服务与路由、上游关联,一个服务可对应一组上游节点、可被多条路由绑定。
Consumer消费者:消费者是路由的消费方,形式包括开发者、最终用户、API 调用等。创建消费者时,需绑定至少一个认证类插件。
# 6.控制台