
# 一.关键字
# 1.like
select *
from rv.rv_schema_table
where table_name like '%tm01%';
2
3
# 2.group by
SELECT deptname, SUM(original_inv - id)
FROM kwan.tb_dept
GROUP BY deptname
;
SELECT deptname, SUM(original_inv) - SUM(id)
FROM kwan.tb_dept
GROUP BY deptname
;
2
3
4
5
6
7
8
9
# 3.distinct
select distinct name from A;
select distinct name, id from A;
--表中name去重后的数目
select count(distinct name) from A;
select count(distinct name, id) from A;
2
3
4
5
6
7
8
# 4.join
只写 join,不会报错,会产生笛卡尔积
select * from a join b;
# 5.order by
select * from stu order by age desc ,date desc,num desc
谁在前,谁先排序。后面排序的字段。只能在前面已排序的基础上进行排序
asc表示升序
desc表示降序
多字段:order by(字段一) (升序/降序),(字段二)(升序/降序),(字段n)(升序/降序)
2
3
# 6.COUNT
SELECT financial_year, financial_week, COUNT(1)
FROM `default`.xxxxx
GROUP BY financial_year, financial_week
ORDER BY financial_year, financial_week
;
2
3
4
5
# 7.列转行
列转行 sql
SELECT t4.`column_name`, t4.`column_value`, t4.`id`, t4.`name`, t4.`suject`, t4.`rv_sync_create_time`
FROM ((SELECT 'class' AS `column_name`,
t3.`class` AS `column_value`,
`column_name`,
`column_value`,
t3.`id`,
t3.`name`,
t3.`suject`,
t3.`class`,
t3.`rv_sync_create_time`
FROM `default`.`aloong_class` AS t3)) AS t4
2
3
4
5
6
7
8
9
10
11
列转行结果
列转行结果会新增 2 列,一列是被转的列名,一列是被转的列值。上述事例中是将 class 这一列转为行,并且输出的结果中是没有 class 这一列的,它变成了行值,column_name 这个新列。column_value 是原来 class 列的值。
# 8.行转列
#建表 带注释+创建时间
DROP TABLE IF EXISTS `Tmark`;
# 新建表
CREATE TABLE Tmark
(
Name VARCHAR(10),
Course VARCHAR(10),
Score INT
);
INSERT INTO Tmark
VALUES ('张三', '语文', 74);
INSERT INTO Tmark
VALUES ('张三', '数学', 83);
INSERT INTO Tmark
VALUES ('张三', '物理', 93);
INSERT INTO Tmark
VALUES ('李四', '语文', 74);
INSERT INTO Tmark
VALUES ('李四', '数学', 84);
INSERT INTO Tmark
VALUES ('李四', '物理', 94);
INSERT INTO Tmark
VALUES ('王五', '语文', 86);
INSERT INTO Tmark
VALUES ('王五', '数学', NULL);
INSERT INTO Tmark
VALUES ('王五', '物理', NULL);
SELECT *
FROM Tmark;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
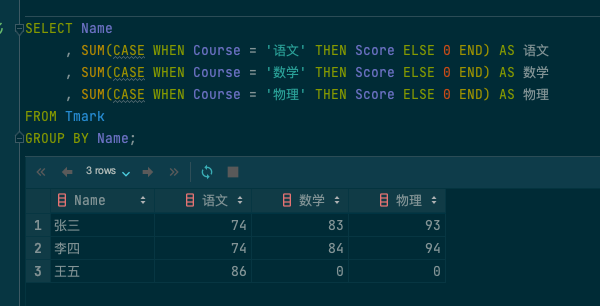
行转列 sql
SELECT Name
, SUM(CASE WHEN Course = '语文' THEN Score ELSE 0 END) AS 语文
, SUM(CASE WHEN Course = '数学' THEN Score ELSE 0 END) AS 数学
, SUM(CASE WHEN Course = '物理' THEN Score ELSE 0 END) AS 物理
FROM Tmark
GROUP BY Name;
2
3
4
5
6
# 9.合并行
合并行 sql
select t4.`name`,
t4.`classes`,
t4.`rv_sync_create_time`,
t4.`subject`,
t4.`fraction`,
t4.`hobby`
from ((
SELECT t1.`name`,
t1.`classes`,
t1.`rv_sync_create_time`,
NULL as `subject`,
NULL as `fraction`,
NULL as `hobby`
FROM `wy_class` as t1)
union all
(
SELECT t3.`name`,
NULL as `classes`,
t3.`rv_sync_create_time`,
t3.`subject`,
t3.`fraction`,
t3.`hobby`
FROM `wy_pivot_hobby` as t3))
as t4
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
合并行结果
wy_class 表有 3 个字段,wy_pivot_hobby 表有 5 个字段,2 个表有 2 个相同的字段 name 和 rv_sync_create_time,
输出结果是 6 个字段name,classes,rv_sync_create_time,subject,hobby,fraction。
使用 union 和 union all 必须保证各个 select 集合的结果有相同个数的列,并且每个列的类型是一样的。但列名则不一定需要相同,oracle 会将第一个结果的列名作为结果集的列名。上述输出 6 个不是必须的,也可以用 name 对应 classes,只需要输出的列个数一致即可,不够的(不存在的)字段需要用 null 替换。
UNION 和 UNION ALL 对比
1.对重复结果的处理:UNION 会去掉重复记录,UNION ALL 不会;
2.对排序的处理:UNION 会排序,UNION ALL 只是简单地将两个结果集合并;
3.效率方面的区别:因为 UNION 会做去重和排序处理,因此效率比 UNION ALL 慢很多;
# 10.case when 加入 in
SELECT
IFNULL( COUNT( CASE WHEN T.state IN ( 1, 2, 3, 4, 5, 6 ) THEN 1 END), 0 ) exception,
IFNULL( COUNT( CASE T.state WHEN 1 THEN 1 END ), 0 ) deal,
IFNULL( COUNT( CASE T.state WHEN 2 THEN 1 END ), 0 ) audit,
IFNULL( COUNT( CASE T.state WHEN 4 THEN 1 END ), 0 ) finish
FROM
o_alert T
WHERE
T.is_deleted = 0
;
2
3
4
5
6
7
8
9
10
# 11.变量
SET @flag := 'test0';
SELECT * from kwan.user where name =@flag;
2
# 12.CTE(with 写法)
mysql 在 8.0 开始支持 with 的写法
with tmp as(
SELECT * from kwan.t_employee
)
SELECT * from tmp;
2
3
4
公用表表达式(Common Table Expression,CTE)是一种在 SQL 中定义临时结果集的方法,可以在查询中多次引用。CTE 可以让查询更加简洁易懂,同时也可以提高查询的性能。
CTE 的语法如下:
WITH cte_name AS (
SELECT column1, column2, ...
FROM table_name
WHERE condition
)
SELECT column1, column2, ...
FROM cte_name
WHERE condition;
2
3
4
5
6
7
8
其中,cte_name 是 CTE 的名称,后面紧跟着的是一个查询语句,用于定义 CTE 的结果集。在查询中,可以使用 cte_name 引用 CTE,从而避免重复编写查询语句。
需要注意的是,CTE 定义的结果集只能在定义它的查询语句中使用,不能在其他查询语句中使用。另外,CTE 可以递归定义,用于处理树形结构等问题。
# 13.项目常用 SQL
#降序查询
SELECT * from kwan.chatbot order by id desc;
#更新行数据
UPDATE kwan.chatbot SET is_delete=0 WHERE is_delete=1;
#查询总数
SELECT COUNT(1) from kwan.chatbot;
#查看mysql的线程连接数
show status like 'Threads_connected';
2
3
4
5
6
7
8
9
10
11
# 14.注释
# SELECT 2;
-- SELECT 2;
/**
* SELECT 2;
*/
2
3
4
5
6
7
# 二.特殊函数
# 1.version
#版本
select version();
2
# 2.字符串拼接
select concat("aaa","bbbb","ccccc") as str
# 3.Lag 和 lead
lag() over() 与 lead() over() 函数是跟偏移量相关的两个分析函数,通过这两个函数可以在一次查询中取出同一字段的前 N 行的数据(lag)和后 N 行的数据(lead)作为独立的列,从而更方便地进行进行数据过滤。这种操作可以代替表的自联接,并且 LAG 和 LEAD 有更高的效率。
Lag()就是取当前顺序的上一行记录。结合over就是分组统计数据的。
lead(t.create_date,1, null) over( partition by cphm order by create_date asc ) t2
over()表示 lag()与 lead()操作的数据都在 over()的范围内,他里面可以使用 partition by 语句(用于分组) order by 语句(用于排序)。partition by a order by b 表示以 a 字段进行分组,再 以 b 字段进行排序,对数据进行查询。
例如:lead(field, num, defaultvalue) field 需要查找的字段,num 往后查找的 num 行的数据,defaultvalue 没有符合条件的默认值
建表:
SHOW TABLES;
#建表 带注释+创建时间
DROP TABLE IF EXISTS `dim_bl_week_info_001`;
# 新建表
CREATE TABLE `dim_bl_week_info_001`
(
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '自增主键',
`week_start_day` date DEFAULT NULL COMMENT '周开始',
`week_end_day` date DEFAULT NULL COMMENT '周结束',
`financial_year_week` int(32) DEFAULT NULL COMMENT '第n财年周',
`financial_year` int(32) DEFAULT NULL COMMENT '财年',
PRIMARY KEY (`id`)
) ENGINE = InnoDB
DEFAULT CHARSET = utf8;
TRUNCATE TABLE dim_bl_week_info_001;
INSERT INTO dim_bl_week_info_001 (week_start_day, week_end_day, financial_year_week, financial_year)
VALUES ('2022-10-01', '2022-10-01', 1, 1)
, ('2022-10-01', '2022-10-02', 2, 2)
, ('2022-10-01', '2022-10-03', 3, 3);
SELECT *
FROM dim_bl_week_info_001;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
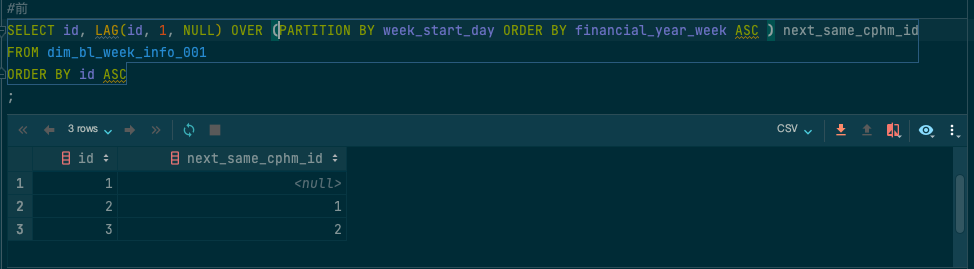
获取前一行的数据:
#前
SELECT id, LAG(id, 1, NULL) OVER (PARTITION BY week_start_day ORDER BY financial_year_week ASC ) next_same_cphm_id
FROM dim_bl_week_info_001
ORDER BY id ASC
;
2
3
4
5
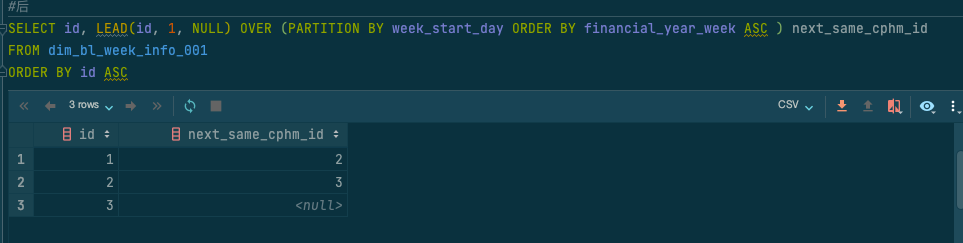
获取后一行的数据:
#后
SELECT id, LEAD(id, 1, NULL) OVER (PARTITION BY week_start_day ORDER BY financial_year_week ASC ) next_same_cphm_id
FROM dim_bl_week_info_001
ORDER BY id ASC
;
2
3
4
5
# 4.SIGN(x)
SIGN(x)返回参数的符号,x 的值为负、零或正时,返回结果依次为-1、0 或 1
select SIGN(-21), SIGN(0), SIGN(21)
返回:-1 0 1
2
# 5.字符串转 int
select truncate(cast(abs('414.55555') as decimal(15,3)),3);
# 6.查询 json 数据
sql = f"select count(*) from indicator_library where JSON_CONTAINS(synonyms,'\"{indicatorName}\"')"
count = session.execute(text(sql)).scalar()
2
SELECT d.*
FROM dimension d,
JSON_TABLE(
d.enumeration_values,
"$[*]" COLUMNS (
name VARCHAR(255) PATH "$.name",
sql_mapping INT PATH "$.sql_mapping",
equivalent_word JSON PATH "$.equivalent_word"
)
) AS jt
WHERE 1 = 1
and JSON_CONTAINS(jt.equivalent_word, '\"包\"') ;
2
3
4
5
6
7
8
9
10
11
12
# 7.递归查询
# 递归查询数据
WITH RECURSIVE category_tree AS (
-- Base case: select the root category/categories with name '测试目录'
SELECT id, name, parent_id, level
FROM public.document_category
WHERE name = '测试目录'
UNION ALL
-- Recursive case: select all children of categories already in the tree
SELECT c.id, c.name, c.parent_id, c.level
FROM public.document_category c
JOIN category_tree ct ON c.parent_id = ct.id
)
SELECT SUM(d.filesize) AS total_filesize
FROM public.documents d
JOIN category_tree ct ON d.category_id = ct.id;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 三.时间函数
# 1.当前时间
#当前时间
select now();
#当前日期
select current_date;
2
3
4
5
# 2.年月日时分秒
#DATE_FORMAT日期格式转换
SELECT DATE_FORMAT(SYSDATE(),'%Y-%m-%d %H:%i:%s') from dual;
2
# 3.加一天
#明天这个时候
select date_add(now(), interval 1 day);
#前一天
SELECT DATE_SUB(CURDATE(),INTERVAL 1 DAY);
2
3
4
5
# 4.加一小时
select date_add(now(), interval 1 hour); -- 加1小时
# 5.加一分钟
select date_add(now(), interval 1 minute); -- 加1分钟
# 6.加一秒
select date_add(now(), interval 1 second); -- 加1秒
# 7.加一毫秒
select date_add(now(), interval 1 microsecond);-- 加1毫秒
# 8.加一周
select date_add(now(), interval 1 week);-- 加1周
# 9.加一月
select date_add(now(), interval 1 month);-- 加1月
# 10.加一季
select date_add(now(), interval 1 quarter);-- 加1季
# 11.加一年
select date_add(now(), interval 1 year);-- 加1年
# 12.减一年
-- MySQL 为日期减去一个时间间隔:date_sub()
select date_sub(now(), interval 1 year);-- 减去1年
2
# 13.时间转换
-- str_to_date()函数字符串转换为date
str_to_date('2016-12-15 16:48:40','%Y-%m-%d %H:%i:%S')
2
# 14.date_format 转换
| 格式 | 描述 |
|---|---|
| %a | 缩写星期名 |
| %b | 缩写月名 |
| %c | 月,数值 |
| %D | 带有英文前缀的月中的天 |
| %d | 月的天,数值(00-31) |
| %e | 月的天,数值(0-31) |
| %f | 微秒 |
| %H | 小时 (00-23) |
| %h | 小时 (01-12) |
| %I | 小时 (01-12) |
| %i | 分钟,数值(00-59) |
| %j | 年的天 (001-366) |
| %k | 小时 (0-23) |
| %l | 小时 (1-12) |
| %M | 月名 |
| %m | 月,数值(00-12) |
| %p | AM 或 PM |
| %r | 时间,12-小时(hh:mm:ss AM 或 PM) |
| %S | 秒(00-59) |
| %s | 秒(00-59) |
| %T | 时间, 24-小时 (hh:mm:ss) |
| %U | 周 (00-53) 星期日是一周的第一天 |
| %u | 周 (00-53) 星期一是一周的第一天 |
| %V | 周 (01-53) 星期日是一周的第一天,与 %X 使用 |
| %v | 周 (01-53) 星期一是一周的第一天,与 %x 使用 |
| %W | 星期名 |
| %w | 周的天 (0=星期日, 6=星期六) |
| %X | 年,其中的星期日是周的第一天,4 位,与 %V 使用 |
| %x | 年,其中的星期一是周的第一天,4 位,与 %v 使用 |
| %Y | 年,4 位 |
| %y | 年,2 位 |
# 15.查询今天 9 点
SELECT curdate() AS cur_date
, date_add(curdate(), INTERVAL 9 HOUR) AS cur_9
, date_add(curdate(), INTERVAL 9.30 hour_minute) AS cur_9_30
, date_add(date_add(curdate(), INTERVAL 9.30 HOUR_MINUTE), INTERVAL 9 SECOND) AS cur_9_30_9
, DATE_ADD(DATE_SUB(CURDATE(), INTERVAL 1 DAY), INTERVAL 9 HOUR) AS yes_9
;
2
3
4
5
6
# 16.获取年
select YEAR(i);
# 17.加 7 天
#加7天
select DATE_ADD(i, INTERVAL 6 DAY);
#前100天
select DATE_ADD(NOW() , INTERVAL -100 DAY);
2
3
4
5
# 18.这个月最后一天
#这个月的最后一天
select LAST_DAY(i);
#获取月份
SELECT DAYOFMONTH('2023-01-01');
2
3
4
5
# 19.星期相关
DATE_FORMAT:
SELECT
CASE
DATE_FORMAT(NOW(),'%w')
WHEN 1 THEN '星期一'
WHEN 2 THEN '星期二'
WHEN 3 THEN '星期三'
WHEN 4 THEN '星期四'
WHEN 5 THEN '星期五'
WHEN 6 THEN '星期六'
WHEN 0 THEN '星期日'
END
as week
;
2
3
4
5
6
7
8
9
10
11
12
13
DAYOFWEEK:
select DAYOFWEEK('2020-07-02');

WEEKDAY:
select WEEKDAY('2020-07-02');

# 19.今天
-- 今天
SELECT DATE_FORMAT(NOW(),'%Y-%m-%d 00:00:00') AS '今天开始';
SELECT DATE_FORMAT(NOW(),'%Y-%m-%d 23:59:59') AS '今天结束';
2
3
# 20.明天
-- 昨天
SELECT DATE_FORMAT( DATE_SUB(CURDATE(), INTERVAL 1 DAY), '%Y-%m-%d 00:00:00') AS '昨天开始';
SELECT DATE_FORMAT( DATE_SUB(CURDATE(), INTERVAL 1 DAY), '%Y-%m-%d 23:59:59') AS '昨天结束';
2
3
# 21.上周
-- 上周
SELECT DATE_FORMAT( DATE_SUB( DATE_SUB(CURDATE(), INTERVAL WEEKDAY(CURDATE()) DAY), INTERVAL 1 WEEK), '%Y-%m-%d 00:00:00') AS '上周一';
SELECT DATE_FORMAT( SUBDATE(CURDATE(), WEEKDAY(CURDATE()) + 1), '%Y-%m-%d 23:59:59') AS '上周末';
2
3
# 22.本周
-- 本周
SELECT DATE_FORMAT( SUBDATE(CURDATE(),DATE_FORMAT(CURDATE(),'%w')-1), '%Y-%m-%d 00:00:00') AS '本周一';
SELECT DATE_FORMAT( SUBDATE(CURDATE(),DATE_FORMAT(CURDATE(),'%w')-7), '%Y-%m-%d 23:59:59') AS '本周末';
2
3
4
# 23.一周的开始
-- 上面的本周算法会有问题,因为mysql是按照周日为一周第一天,如果当前是周日的话,会把时间定为到下一周.
SELECT DATE_FORMAT( DATE_SUB(CURDATE(), INTERVAL WEEKDAY(CURDATE()) DAY), '%Y-%m-%d 00:00:00') AS '本周一';
SELECT DATE_FORMAT( DATE_ADD(SUBDATE(CURDATE(), WEEKDAY(CURDATE())), INTERVAL 6 DAY), '%Y-%m-%d 23:59:59') AS '本周末';
2
3
# 24.上月
-- 上月
SELECT DATE_FORMAT( DATE_SUB(CURDATE(), INTERVAL 1 MONTH), '%Y-%m-01 00:00:00') AS '上月初';
SELECT DATE_FORMAT( LAST_DAY(DATE_SUB(CURDATE(), INTERVAL 1 MONTH)), '%Y-%m-%d 23:59:59') AS '上月末';
2
3
# 25.本月
-- 本月
SELECT DATE_FORMAT( CURDATE(), '%Y-%m-01 00:00:00') AS '本月初';
SELECT DATE_FORMAT( LAST_DAY(CURDATE()), '%Y-%m-%d 23:59:59') AS '本月末';
2
3
# 四.每日一题
# 1.重复数据
SELECT period_sdate, product_key, size_code, managing_city_no
FROM ads_sense_rep.ads_day_city_brand_sku_size_rep
GROUP BY period_sdate, product_key, size_code, managing_city_no
HAVING COUNT(*) > 1;
2
3
4
# 2.赋值操作
需求:
- 知道 27 周和 53 周的数据,填充其他周的数据.
- 要求同财年的时候 27 和 53 周不变
- 同财年的时候,大于 27,小于 53,取 27 周的数据
- 不同财年,大于 53 周,小于 27 周,取上一次财年 53 周数据
ON (
(t1.financial_year = t2.financial_year AND t1.financial_year_week >= t2.financial_year_week AND
t1.financial_year_week >= 27 AND t1.financial_year_week < 53)
OR (t1.financial_year = t2.financial_year AND t1.financial_year_week = 53 AND
t1.financial_year_week = t2.financial_year_week)
OR (t1.financial_year = t2.financial_year + 1 AND t1.financial_year_week < 27 AND
t2.financial_year_week = 53)
) --27和27相同 t1: 28 t2:27 t1:53 t2
AND t1.gender_name = t2.gender_name
AND t1.category_name1 = t2.category_name1
AND t1.brand_detail_no = t2.brand_detail_no
2
3
4
5
6
7
8
9
10
11
# 3.存储过程实现指定周区间
-- 使用前先删除存储过程,因为创建存储过程后,存储过程会一直存在于mysql中
DROP PROCEDURE IF EXISTS test_procedure_insert_week;
-- 标记上面的命令执行结束 #声明;;为结束标志
DELIMITER;;
-- 创建存储过程
CREATE PROCEDURE test_procedure_insert_week()
BEGIN
DECLARE
i DATE;
DECLARE
next_year DATE;
DECLARE
week_count INT;
DECLARE
year INT;
DECLARE
last_day DATE;
SET
i = '2018-03-01';
SET
week_count = 1;
SET
year = YEAR(i);
WHILE
i < '2025-03-01'
DO
SET
next_year = STR_TO_DATE(CONCAT((year + 1), '-03-01'), '%Y-%m-%d');
SET
i = IF(i >= next_year, next_year, i); #日期
SET
year = IF(i >= next_year, year + 1, year); #财年
SET
week_count = IF(i >= next_year, 1, week_count);
SET
last_day = IF(DATE_ADD(i, INTERVAL 6 DAY) >= next_year, LAST_DAY(i),
DATE_ADD(i, INTERVAL 6 DAY));
INSERT INTO `kwan`.`dim_bl_week_info` (week_start_day, week_end_day, financial_year_week, financial_year)
VALUES (i, last_day, week_count, year);
SET
i = DATE_ADD(i, INTERVAL 7 DAY);
SET
week_count = week_count + 1;
END WHILE;
END;;
# 调用无参的存储过程,当然也可以设置参数,调用时也需要传递参数
CALL test_procedure_insert_week();
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
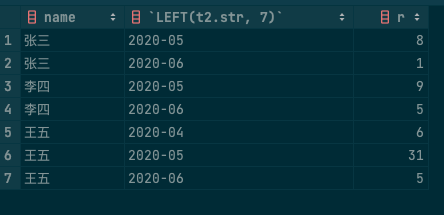
# 4.请假天数
SELECT t2.name
, LEFT(t2.str, 7)
, COUNT(1) AS r -- 通过姓名和 月份分组,统计天数
FROM (
SELECT t1.*, DATE_ADD(t1.start_date, INTERVAL cn DAY) AS str -- 从开始日期开始累加
FROM (
SELECT a.*, ROW_NUMBER() OVER (PARTITION BY name,start_date) - 1 AS cn, t.help_topic_id -- 开窗函数排序
FROM (
SELECT *, DATEDIFF(end_date, start_date) + 1 AS days
FROM day_emp_leave -- 查询请假天数间隔
) a
LEFT JOIN mysql.help_topic t -- 倒序
ON t.help_topic_id > 0
AND t.help_topic_id <= a.days
) t1
) t2
GROUP BY t2.name, LEFT(t2.str, 7);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 5.最多好友
-- 新建表
CREATE TABLE `day_most_friends`
(
`requester_id` INT(3) DEFAULT NULL COMMENT '请求人',
`accepter_id` INT(3) DEFAULT NULL COMMENT '接受人',
`accept_date` date DEFAULT NULL COMMENT '接受日期'
) ENGINE = InnoDB
DEFAULT CHARSET = utf8;
-- 查询
SELECT *
FROM day_most_friends;
-- 清空表
TRUNCATE TABLE day_most_friends;
-- 插入数据
INSERT INTO day_most_friends (requester_id, accepter_id, accept_date)
VALUES (1, 2, '2016-06-03')
, (1, 3, '2016-06-08')
, (2, 3, '2016-06-08')
, (3, 4, '2016-06-09');
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
-- 查询所有数据
SELECT a.IDS AS ID, COUNT(*) AS NUM
FROM (
SELECT requester_id AS IDS
FROM day_most_friends
UNION ALL
SELECT accepter_id AS IDS
FROM day_most_friends
) a
GROUP BY a.IDS
ORDER BY COUNT(*);
-- 只查询一条数据
SELECT a.IDS AS ID, COUNT(*) AS NUM
FROM (
SELECT requester_id AS IDS
FROM day_most_friends
UNION ALL
SELECT accepter_id AS IDS
FROM day_most_friends
) a
GROUP BY a.IDS
ORDER BY COUNT(*) DESC
LIMIT 1;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# 6.等分数据
1 到 n 的连续数字,分成 5 等分,并展示没等分开始和结束数据,用 sql 怎么实现?
WITH nums AS (
SELECT 1 AS n UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4 UNION ALL SELECT 5 UNION ALL
SELECT 6 UNION ALL SELECT 7 UNION ALL SELECT 8 UNION ALL SELECT 9 UNION ALL SELECT 10
)
SELECT
MIN(n) AS start_num,
MAX(n) AS end_num
FROM (
SELECT
n,
FLOOR((n - 1) / 2) AS group_num
FROM nums
) AS grouped_nums
GROUP BY group_num
ORDER BY MIN(n)
;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 7.排名中位数
floor()是对括号里面的数向下取整,ceil()是向上取整
-- 城市销量
SELECT *
FROM (SELECT period_sdate AS period_sdate
, product_key AS product_key
, managing_city_no AS managing_city_no
, sal_qty AS sal_qty
, row_number() over (PARTITION BY period_sdate,brand_detail_no,managing_city_no ORDER BY sal_qty ) AS sql_qty_rank
, COUNT(product_key) over(partition BY period_sdate,brand_detail_no,managing_city_no) AS total
FROM default.ads_day_city_sku_info_tag_rep_uat_1029
WHERE 1 = 1
AND period_sdate >= '2023-02-03'
AND period_sdate <= '2023-02-09'
AND sal_qty > 0
AND brand_detail_no = 'BS01'
AND managing_city_no = 'M0520'
)
WHERE sql_qty_rank = ceil(total / 2)
;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 8.分组最大值
<select id="selectAdsDayCountryOrrHomeTotal" resultMap="BaseResultMap">
SELECT orr.product_key AS product_key
, orr.period_sdate AS period_sdate
, orr.order_not_arrive_qty AS order_not_arrive_qty
, orr.replenish_not_arrive_qty AS replenish_not_arrive_qty
FROM (
SELECT country.product_key AS product_key
, country.period_sdate AS period_sdate
, country.order_not_arrive_qty AS order_not_arrive_qty
, country.replenish_not_arrive_qty AS replenish_not_arrive_qty
, ROW_NUMBER() over (partition BY country.product_key ORDER BY country.period_sdate DESC) AS rn
FROM ads_day_country_orr_rep_${versionSuffix2} country
where 1=1
<if test="query.brandDetailNo != null and query.brandDetailNo != ''">
and country.brand_detail_no = #{query.brandDetailNo}
</if>
<if test="query.date != null and query.date != ''">
and country.period_sdate <= #{query.date}
</if>
<if test="query.productKeyList != null and query.productKeyList.size > 0">
and country.product_key in
<foreach close=")" collection="query.productKeyList" item="product" open="("
separator=",">
#{product}
</foreach>
</if>
) orr
where orr.rn <= 1
</select>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
# 9.王者荣耀排名
-- 在order by 中使用了case when
SELECT *
FROM kwan_user_stars
ORDER BY user_star DESC
, user_grade DESC
, CASE WHEN user_id = 7 THEN 1 ELSE 0 END DESC
;
2
3
4
5
6
7
# 10.多指标累计去重问题
1.数据准备
create table db.sku_store_info as
select '1' as product_key, '2018-01-01' as time_id, '001' as store_key
UNION ALL
select '1' as product_key, '2018-01-01' as time_id, '002' as store_key
UNION ALL
select '1' as product_key, '2018-01-01' as time_id, '001' as store_key
UNION ALL
select '1' as product_key, '2018-01-02' as time_id, '004' as store_key
UNION ALL
select '1' as product_key, '2018-01-02' as time_id, '002' as store_key
UNION ALL
select '1' as product_key, '2018-01-02' as time_id, '003' as store_key
UNION ALL
select '1' as product_key, '2018-01-02' as time_id, '002' as store_key
UNION ALL
select '1' as product_key, '2018-01-02' as time_id, '004' as store_key
UNION ALL
select '1' as product_key, '2018-01-03' as time_id, '005' as store_key
UNION ALL
select '1' as product_key, '2018-01-03' as time_id, '003' as store_key
UNION ALL
select '1' as product_key, '2018-01-03' as time_id, '001' as store_key
UNION ALL
select '1' as product_key, '2018-01-03' as time_id, '005' as store_key
UNION ALL
select '1' as product_key, '2018-02-03' as time_id, '005' as store_key
UNION ALL
select '1' as product_key, '2018-02-04' as time_id, '005' as store_key
UNION ALL
select '1' as product_key, '2018-02-05' as time_id, '009' as store_key
UNION ALL
select '2' as product_key, '2018-01-03' as time_id, '005' as store_key
UNION ALL
select '2' as product_key, '2018-02-03' as time_id, '001' as store_key
UNION ALL
select '2' as product_key, '2019-01-03' as time_id, '006' as store_key
UNION ALL
select '2' as product_key, '2020-01-03' as time_id, '005' as store_key
;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
2.编写 sql
I.当天累计
with tmp_table as (
select product_key as product_key
, time_id as date_id
, store_key as store_key
from ads_sense_rep.sku_store_info
group by product_key, time_id, store_key
)
select product_key as product_key
, date_id as date_id
, store_key as store_key
, count(distinct store_key) over(partition by product_key, date_id) as user_cnt_act
from tmp_table
;
2
3
4
5
6
7
8
9
10
11
12
13
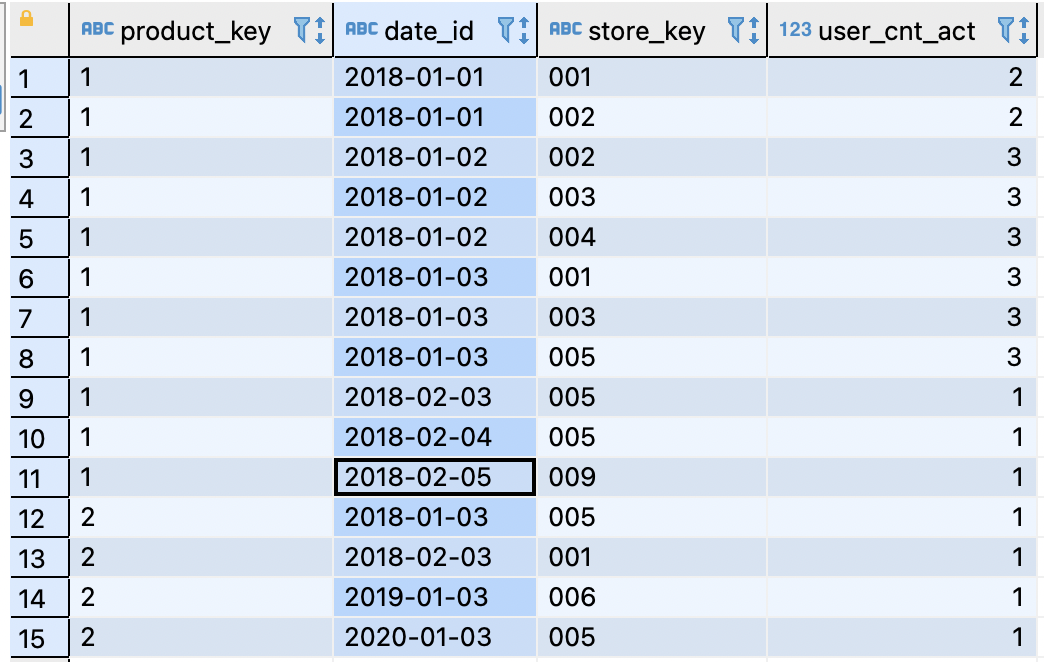
II.历史累计
with tmp_table as (
select product_key as product_key
, time_id as date_id
, store_key as store_key
from ads_sense_rep.sku_store_info
group by product_key, time_id, store_key
)
, tmp_total_table as (
select product_key as product_key
, date_id as date_id
, store_key as store_key
, count(distinct store_key) over(partition by product_key,date_id) as user_cnt_act
, count(distinct store_key) over(partition by product_key order by date_id asc rows between unbounded preceding AND current row) as tmp_day_user_cnt_act_total
from tmp_table
)
select product_key as product_key
, date_id as date_id
, max(user_cnt_act) as user_cnt_act
, max(tmp_day_user_cnt_act_total) as user_cnt_act_total
from tmp_total_table
group by product_key, date_id
;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# 五.常见问题
# 1.SQL 显示
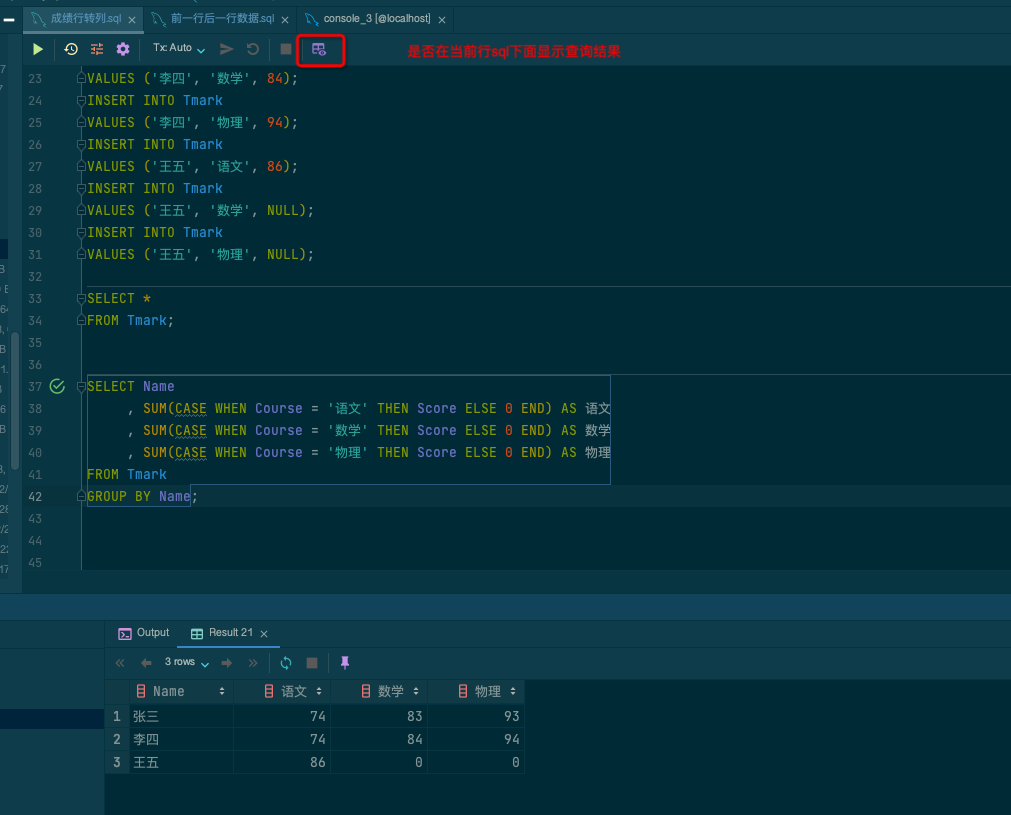
# 2.Idea-Sql 自定义
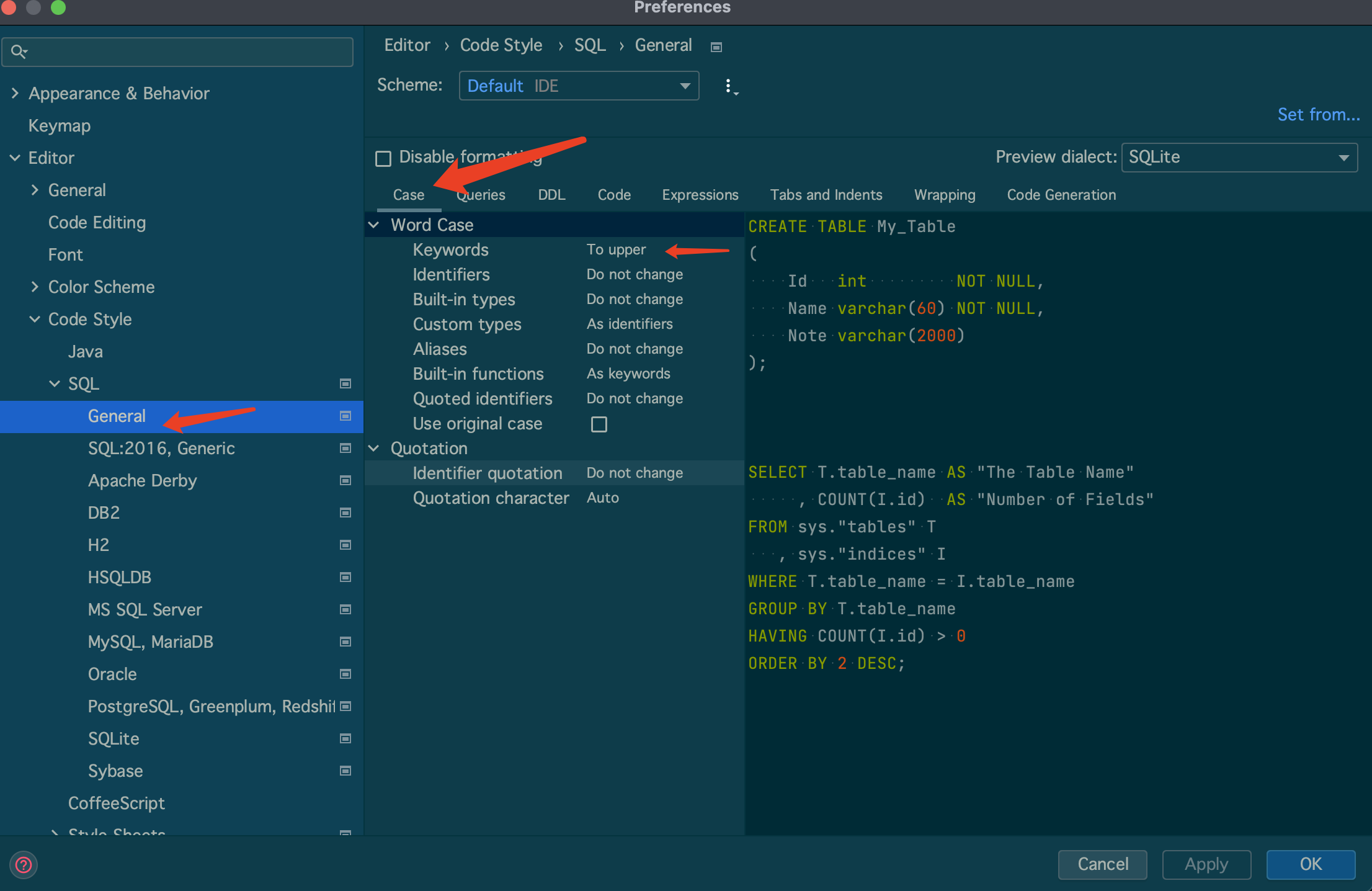
# 3.多数据源
import com.baomidou.dynamic.datasource.annotation.DS;
@DS("data")
@Service
@Slf4j
public class BrandCategoryServiceImpl implements BrandCategoryService {}
2
3
4
5
spring:
datasource:
dynamic:
# 设置默认的数据源或数据源组,默认值即为master
primary: biz
# 严格匹配数据源,默认false,true未匹配到指定数据源时抛异常,false使用默认数据源
strict: false
datasource:
biz:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://xxxx:3306/insight_test?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=GMT%2B8&allowMultiQueries=true
username: test
password: test
type: com.zaxxer.hikari.HikariDataSource
hikari:
minimum-idle: 1
maximum-pool-size: 15
idle-timeout: 3000
max-lifetime: 1800000
connection-test-query: SELECT 1
data:
driver-class-name: ru.yandex.clickhouse.ClickHouseDriver
url: jdbc:clickhouse://xxxx:80/default?socket_timeout=3000000&max_memory_usage=100000000000
username: default
password: xxxx
type: com.zaxxer.hikari.HikariDataSource
hikari:
minimum-idle: 1
maximum-pool-size: 15
idle-timeout: 3000
max-lifetime: 1800000
connection-test-query: SELECT 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
# 4.获取最后 2 天
#日期年月日
SELECT *
FROM your_table
WHERE your_date_column >= DATE_SUB(CURDATE(), INTERVAL 2 DAY)
;
#日期年月日时分秒
SELECT *
FROM your_table
WHERE DATE(your_date_column) >= DATE_SUB(CURDATE(), INTERVAL 2 DAY)
;
2
3
4
5
6
7
8
9
10
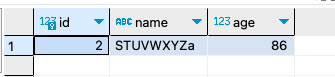
# 5.大小写问题
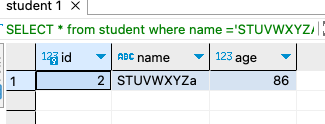
在 MySQL 中,默认情况下,表名、列名以及字符串比较是不区分大小写的。这意味着,如果你执行一个查询,使用了不同大小写形式的表名或列名,MySQL 将会将它们视为相同。然而,有一些方法可以实现大小写敏感的查询。
普通查询:
SELECT * from student
where name ='STUVWXYZa'
;
2
3
SELECT * from student
where name ='STUVWXYZA'
;
2
3
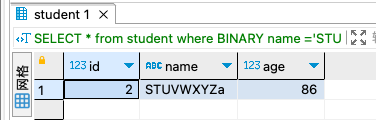
BINARY 查询:
使用 BINARY 操作符:可以在查询中使用 BINARY 操作符来进行大小写敏感的比较。
SELECT * from student
where BINARY name ='STUVWXYZa'
;
2
3
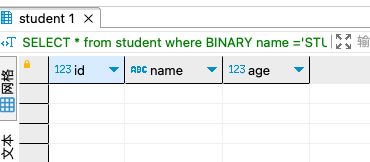
SELECT * from student
where BINARY name ='STUVWXYZA'
;
2
3
服务器配置:
修改服务器配置:如果你需要全局地启用大小写敏感的查询,可以修改 MySQL 服务器的配置。在 MySQL 配置文件中(通常是 my.cnf 或 my.ini),添加或修改以下行:
[mysqld]
lower_case_table_names=0
2
然后重新启动 MySQL 服务器。这将禁用表名和列名的大小写转换,使查询区分大小写。
请注意,修改服务器配置可能需要管理员权限,并且会影响整个 MySQL 服务器上的所有数据库和表。
# 6.判断字符串
方式一:
<if test="sex=='Y'.toString()">
方式二:
<if test = 'sex== "Y"'>
错误的方式:
<if test="sex=='Y'">
and 1=1
</if>
2
3
原因是因为 mybatis 会把’Y’解析为字符,比较的时候,会转换为数字类型进行比较,会报一个
把字符串转换成 int 或 long 型时,出现 java.lang.NumberFormatException: For input string: “”错误。
java 是强类型语言,所以不能这样写。
# 7.自定义排序
使用 case when 自定义排序
order by CASE WHEN season_name = '春' THEN 4
WHEN season_name = '夏' THEN 3
WHEN season_name = '秋' THEN 2
WHEN season_name = '冬' THEN 1
ELSE 0 END DESC
2
3
4
5
先按某个字段,再按分组后的字段
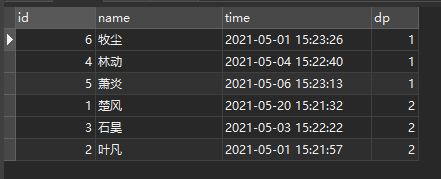
SELECT id,name,time,dp
FROM USER
ORDER BY
dp,//可写可不写,只是按照dp正排
CASE WHEN dp = 1 THEN time END ASC,
CASE WHEN dp = 2 THEN time END DESC
2
3
4
5
6
# 8.mysql 客户端连接数量
您可以使用以下命令查看当前 MySQL 服务器的客户端连接数量:
show status where `variable_name` = 'Threads_connected';
或者简写为:
show status like 'Threads_connected';
这将返回一个名为 "Threads_connected" 的变量和当前的连接数,例如:
+-------------------+-------+
| Variable_name | Value |
+-------------------+-------+
| Threads_connected | 5 |
+-------------------+-------+
2
3
4
5
其中,Value 就是当前的连接数。
# 9.隐式转换的例子
SQL:
select * from `app-cloud`.cl_sation where id = "082f660d-e1d3-4a36-bcd8-e8494f52e0eb";
id 数据类型:
`id` int NOT NULL AUTO_INCREMENT,
等价 SQL:
select * from `app-cloud`.cl_sation where id = 082;
# 10.隐式转换场景
在 MySQL 中,隐式类型转换通常发生在以下几种场景:
字符串和数字混合比较:
字符串和数字混合比较:当你试图将字符串与数字进行比较时,MySQL 会尝试将字符串转换为数字。例如:
SELECT * FROM table WHERE column = '123';
如果column是一个数字类型,MySQL 会尝试将字符串'123'转换为数字 123。
字符串到数字的插入:
字符串到数字的插入:当你尝试将字符串插入到一个数字类型的列时,MySQL 会尝试将字符串转换为相应的数字类型。
INSERT INTO table (column) VALUES ('456');
如果column是一个数字类型,MySQL 会将字符串'456'转换为数字 456。
数字到字符串的插入:
数字到字符串的插入:相反,如果你尝试将数字插入到一个字符串类型的列中,MySQL 也会进行隐式转换。
INSERT INTO table (column) VALUES (789);
如果column是一个字符串类型,MySQL 会将数字 789 转换为字符串'789'。
函数参数:
函数参数:在调用某些函数时,如果参数的数据类型与函数期望的类型不匹配,MySQL 可能会尝试进行隐式转换。
SELECT DATE_ADD('2021-01-01', INTERVAL '1' DAY);
在这个例子中,INTERVAL期望数字类型的参数,但提供了字符串,MySQL 会尝试将其转换为数字。
ORDER BY 或 GROUP BY 子句:
ORDER BY 或 GROUP BY 子句:在使用ORDER BY或GROUP BY子句时,如果列的类型与排序/分组表达式中的类型不匹配,MySQL 可能会进行隐式转换。
SELECT column FROM table ORDER BY 'column';
如果column是字符串类型,而排序表达式是字符串字面量,MySQL 会尝试将列值转换为字符串进行排序。
CASE WHEN 语句:
CASE WHEN 语句:在使用CASE WHEN语句时,如果条件表达式的数据类型与比较值的数据类型不匹配,MySQL 会尝试进行隐式转换。
SELECT column FROM table WHERE column = CASE WHEN condition THEN 'value' ELSE 0 END;
JOIN 操作:
JOIN 操作:在执行 JOIN 操作时,如果连接条件中的列数据类型不匹配,MySQL 可能会尝试进行隐式转换以满足条件。
默认值:
默认值:当列的默认值是字符串,而插入数据时没有提供该列的值,MySQL 会尝试将字符串默认值转换为列的数据类型。
# 11.数据备份
通过创建新表来备份clAppUser表中的password字段是一种简单而有效的方法。以下是在 MySQL 数据库中执行此操作的步骤:
创建一个新表,结构与clAppUser表相同,但只包含password字段。你可以使用CREATE TABLE语句来实现:
CREATE TABLE clAppUser_backup AS
SELECT user_name,password
FROM clAppUser;
2
3
这条命令会创建一个名为clAppUser_backup的新表,它包含clAppUser表中的password字段的所有数据。