
# 一.数据库与事件
# 1.redisServer
struct redisServer {
/* General */
//配置文件路径
char *configfile; /* Absolute config file path, or NULL */
//serverCron()调用频率
int hz; /* serverCron() calls frequency in hertz */
//数据库对象数组指针
redisDb *db;
//支持的命令列表
dict *commands; /* Command table */
//没有转化的命令
dict *orig_commands; /* Command table before command renaming. */
//事件
aeEventLoop *el;
//每分钟增加一次
unsigned lruclock:22; /* Clock incrementing every minute, for LRU */
unsigned lruclock_padding:10;
int shutdown_asap; /* SHUTDOWN needed ASAP */
int activerehashing; /* Incremental rehash in serverCron() */
//验证密码
char *requirepass; /* Pass for AUTH command, or NULL */
char *pidfile; /* PID file path */
int arch_bits; /* 32 or 64 depending on sizeof(long) */
int cronloops; /* Number of times the cron function run */
char runid[REDIS_RUN_ID_SIZE+1]; /* ID always different at every exec. */
int sentinel_mode; /* True if this instance is a Sentinel. */
/* Networking */
int port; /* TCP listening port */
int tcp_backlog; /* TCP listen() backlog */
char *bindaddr[REDIS_BINDADDR_MAX]; /* Addresses we should bind to */
int bindaddr_count; /* Number of addresses in server.bindaddr[] */
char *unixsocket; /* UNIX socket path */
mode_t unixsocketperm; /* UNIX socket permission */
int ipfd[REDIS_BINDADDR_MAX]; /* TCP socket file descriptors */
int ipfd_count; /* Used slots in ipfd[] */
int sofd; /* Unix socket file descriptor */
int cfd[REDIS_BINDADDR_MAX];/* Cluster bus listening socket */
int cfd_count; /* Used slots in cfd[] */
// 连接的客户端
list *clients; /* List of active clients */
list *clients_to_close; /* Clients to close asynchronously */
list *slaves, *monitors; /* List of slaves and MONITORs */
redisClient *current_client; /* Current client, only used on crash report */
int clients_paused; /* True if clients are currently paused */
mstime_t clients_pause_end_time; /* Time when we undo clients_paused */
char neterr[ANET_ERR_LEN]; /* Error buffer for anet.c */
dict *migrate_cached_sockets;/* MIGRATE cached sockets */
/* RDB / AOF loading information */
int loading; /* We are loading data from disk if true */
off_t loading_total_bytes;
off_t loading_loaded_bytes;
time_t loading_start_time;
off_t loading_process_events_interval_bytes;
/* Fast pointers to often looked up command */
struct redisCommand *delCommand, *multiCommand, *lpushCommand, *lpopCommand,
*rpopCommand;
/* Fields used only for stats */
time_t stat_starttime; /* Server start time */
long long stat_numcommands; /* Number of processed commands */
long long stat_numconnections; /* Number of connections received */
long long stat_expiredkeys; /* Number of expired keys */
long long stat_evictedkeys; /* Number of evicted keys (maxmemory) */
long long stat_keyspace_hits; /* Number of successful lookups of keys */
long long stat_keyspace_misses; /* Number of failed lookups of keys */
size_t stat_peak_memory; /* Max used memory record */
long long stat_fork_time; /* Time needed to perform latest fork() */
long long stat_rejected_conn; /* Clients rejected because of maxclients */
long long stat_sync_full; /* Number of full resyncs with slaves. */
long long stat_sync_partial_ok; /* Number of accepted PSYNC requests. */
long long stat_sync_partial_err;/* Number of unaccepted PSYNC requests. */
//保存慢日志命令
list *slowlog; /* SLOWLOG list of commands */
long long slowlog_entry_id; /* SLOWLOG current entry ID */
long long slowlog_log_slower_than; /* SLOWLOG time limit (to get logged) */
unsigned long slowlog_max_len; /* SLOWLOG max number of items logged */
/* The following two are used to track instantaneous "load" in terms
* of operations per second. */
long long ops_sec_last_sample_time; /* Timestamp of last sample (in ms) */
long long ops_sec_last_sample_ops; /* numcommands in last sample */
long long ops_sec_samples[REDIS_OPS_SEC_SAMPLES];
int ops_sec_idx;
/* Configuration */
int verbosity; /* Loglevel in redis.conf */
int maxidletime; /* Client timeout in seconds */
int tcpkeepalive; /* Set SO_KEEPALIVE if non-zero. */
int active_expire_enabled; /* Can be disabled for testing purposes. */
size_t client_max_querybuf_len; /* Limit for client query buffer length */
int dbnum; /* Total number of configured DBs */
int daemonize; /* True if running as a daemon */
clientBufferLimitsConfig client_obuf_limits[REDIS_CLIENT_LIMIT_NUM_CLASSES];
/* AOF persistence */
int aof_state; /* REDIS_AOF_(ON|OFF|WAIT_REWRITE) */
int aof_fsync; /* Kind of fsync() policy */
char *aof_filename; /* Name of the AOF file */
int aof_no_fsync_on_rewrite; /* Don't fsync if a rewrite is in prog. */
int aof_rewrite_perc; /* Rewrite AOF if % growth is > M and... */
off_t aof_rewrite_min_size; /* the AOF file is at least N bytes. */
off_t aof_rewrite_base_size; /* AOF size on latest startup or rewrite. */
off_t aof_current_size; /* AOF current size. */
int aof_rewrite_scheduled; /* Rewrite once BGSAVE terminates. */
pid_t aof_child_pid; /* PID if rewriting process */
list *aof_rewrite_buf_blocks; /* Hold changes during an AOF rewrite. */
sds aof_buf; /* AOF buffer, written before entering the event loop */
int aof_fd; /* File descriptor of currently selected AOF file */
int aof_selected_db; /* Currently selected DB in AOF */
time_t aof_flush_postponed_start; /* UNIX time of postponed AOF flush */
time_t aof_last_fsync; /* UNIX time of last fsync() */
time_t aof_rewrite_time_last; /* Time used by last AOF rewrite run. */
time_t aof_rewrite_time_start; /* Current AOF rewrite start time. */
int aof_lastbgrewrite_status; /* REDIS_OK or REDIS_ERR */
unsigned long aof_delayed_fsync; /* delayed AOF fsync() counter */
int aof_rewrite_incremental_fsync;/* fsync incrementally while rewriting? */
int aof_last_write_status; /* REDIS_OK or REDIS_ERR */
int aof_last_write_errno; /* Valid if aof_last_write_status is ERR */
/* RDB persistence */
long long dirty; /* Changes to DB from the last save */
long long dirty_before_bgsave; /* Used to restore dirty on failed BGSAVE */
pid_t rdb_child_pid; /* PID of RDB saving child */
struct saveparam *saveparams; /* Save points array for RDB */
int saveparamslen; /* Number of saving points */
char *rdb_filename; /* Name of RDB file */
int rdb_compression; /* Use compression in RDB? */
int rdb_checksum; /* Use RDB checksum? */
time_t lastsave; /* Unix time of last successful save */
time_t lastbgsave_try; /* Unix time of last attempted bgsave */
time_t rdb_save_time_last; /* Time used by last RDB save run. */
time_t rdb_save_time_start; /* Current RDB save start time. */
int lastbgsave_status; /* REDIS_OK or REDIS_ERR */
int stop_writes_on_bgsave_err; /* Don't allow writes if can't BGSAVE */
/* Propagation of commands in AOF / replication */
redisOpArray also_propagate; /* Additional command to propagate. */
/* Logging */
char *logfile; /* Path of log file */
int syslog_enabled; /* Is syslog enabled? */
char *syslog_ident; /* Syslog ident */
int syslog_facility; /* Syslog facility */
/* Replication (master) */
int slaveseldb; /* Last SELECTed DB in replication output */
long long master_repl_offset; /* Global replication offset */
int repl_ping_slave_period; /* Master pings the slave every N seconds */
char *repl_backlog; /* Replication backlog for partial syncs */
long long repl_backlog_size; /* Backlog circular buffer size */
long long repl_backlog_histlen; /* Backlog actual data length */
long long repl_backlog_idx; /* Backlog circular buffer current offset */
long long repl_backlog_off; /* Replication offset of first byte in the
backlog buffer. */
time_t repl_backlog_time_limit; /* Time without slaves after the backlog
gets released. */
time_t repl_no_slaves_since; /* We have no slaves since that time.
Only valid if server.slaves len is 0. */
int repl_min_slaves_to_write; /* Min number of slaves to write. */
int repl_min_slaves_max_lag; /* Max lag of <count> slaves to write. */
int repl_good_slaves_count; /* Number of slaves with lag <= max_lag. */
/* Replication (slave) */
char *masterauth; /* AUTH with this password with master */
char *masterhost; /* Hostname of master */
int masterport; /* Port of master */
int repl_timeout; /* Timeout after N seconds of master idle */
redisClient *master; /* Client that is master for this slave */
redisClient *cached_master; /* Cached master to be reused for PSYNC. */
int repl_syncio_timeout; /* Timeout for synchronous I/O calls */
int repl_state; /* Replication status if the instance is a slave */
off_t repl_transfer_size; /* Size of RDB to read from master during sync. */
off_t repl_transfer_read; /* Amount of RDB read from master during sync. */
off_t repl_transfer_last_fsync_off; /* Offset when we fsync-ed last time. */
int repl_transfer_s; /* Slave -> Master SYNC socket */
int repl_transfer_fd; /* Slave -> Master SYNC temp file descriptor */
char *repl_transfer_tmpfile; /* Slave-> master SYNC temp file name */
time_t repl_transfer_lastio; /* Unix time of the latest read, for timeout */
int repl_serve_stale_data; /* Serve stale data when link is down? */
int repl_slave_ro; /* Slave is read only? */
time_t repl_down_since; /* Unix time at which link with master went down */
int repl_disable_tcp_nodelay; /* Disable TCP_NODELAY after SYNC? */
int slave_priority; /* Reported in INFO and used by Sentinel. */
char repl_master_runid[REDIS_RUN_ID_SIZE+1]; /* Master run id for PSYNC. */
long long repl_master_initial_offset; /* Master PSYNC offset. */
/* Replication script cache. */
dict *repl_scriptcache_dict; /* SHA1 all slaves are aware of. */
list *repl_scriptcache_fifo; /* First in, first out LRU eviction. */
int repl_scriptcache_size; /* Max number of elements. */
/* Synchronous replication. */
list *clients_waiting_acks; /* Clients waiting in WAIT command. */
int get_ack_from_slaves; /* If true we send REPLCONF GETACK. */
/* Limits */
unsigned int maxclients; /* Max number of simultaneous clients */
unsigned long long maxmemory; /* Max number of memory bytes to use */
int maxmemory_policy; /* Policy for key eviction */
int maxmemory_samples; /* Pricision of random sampling */
/* Blocked clients */
unsigned int bpop_blocked_clients; /* Number of clients blocked by lists */
list *unblocked_clients; /* list of clients to unblock before next loop */
list *ready_keys; /* List of readyList structures for BLPOP & co */
/* Sort parameters - qsort_r() is only available under BSD so we
* have to take this state global, in order to pass it to sortCompare() */
int sort_desc;
int sort_alpha;
int sort_bypattern;
int sort_store;
/* Zip structure config, see redis.conf for more information */
size_t hash_max_ziplist_entries;
size_t hash_max_ziplist_value;
size_t list_max_ziplist_entries;
size_t list_max_ziplist_value;
size_t set_max_intset_entries;
size_t zset_max_ziplist_entries;
size_t zset_max_ziplist_value;
time_t unixtime; /* Unix time sampled every cron cycle. */
long long mstime; /* Like 'unixtime' but with milliseconds resolution. */
/* Pubsub */
dict *pubsub_channels; /* Map channels to list of subscribed clients */
list *pubsub_patterns; /* A list of pubsub_patterns */
int notify_keyspace_events; /* Events to propagate via Pub/Sub. This is an
xor of REDIS_NOTIFY... flags. */
/* Cluster */
int cluster_enabled; /* Is cluster enabled? */
mstime_t cluster_node_timeout; /* Cluster node timeout. */
char *cluster_configfile; /* Cluster auto-generated config file name. */
struct clusterState *cluster; /* State of the cluster */
int cluster_migration_barrier; /* Cluster replicas migration barrier. */
/* Scripting */
lua_State *lua; /* The Lua interpreter. We use just one for all clients */
redisClient *lua_client; /* The "fake client" to query Redis from Lua */
redisClient *lua_caller; /* The client running EVAL right now, or NULL */
dict *lua_scripts; /* A dictionary of SHA1 -> Lua scripts */
mstime_t lua_time_limit; /* Script timeout in milliseconds */
mstime_t lua_time_start; /* Start time of script, milliseconds time */
int lua_write_dirty; /* True if a write command was called during the
execution of the current script. */
int lua_random_dirty; /* True if a random command was called during the
execution of the current script. */
int lua_timedout; /* True if we reached the time limit for script
execution. */
int lua_kill; /* Kill the script if true. */
/* Assert & bug reporting */
char *assert_failed;
char *assert_file;
int assert_line;
int bug_report_start; /* True if bug report header was already logged. */
int watchdog_period; /* Software watchdog period in ms. 0 = off */
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
涉及的功能与模块:
- 通用参数(General)
- 模块(Modules)
- 网络(Networking)
- 常见的命令回调函数
- 统计相关(stat)
- 配置信息(Configuration)
- AOF 持久化相关(包括 aof rewrite 过程中,父子进程用于消除数据差异的管道)
- RDB 持久化相关(包括 RDB 过程中,父子进程用于通信的管道)
- AOF 或者主从复制下,命令传播相关
- 日志相关(logging)
- 主从复制(Replication (master)+Replication (slave))
- 主从复制的脚本缓存(Replication script cache)
- 主从同步相关(Synchronous replication)
- 系统限制(Limits)
- 阻塞客户端(Blocked clients)
- sort 命令相关(Sort)
- 数据结构转换参数
- 时间缓存(time cache)
- 发布订阅(Pubsub)
- 集群(Cluster)
- Lazy free(表示删除过期键,是否启用后台线程异步删除)
- LUA 脚本
- 延迟监控相关
- 服务端中互斥锁信息
- 系统硬件信息
# 2.redis 数据库
- 默认创建 16 个库,服务端有 16 个库
- 使用 select 切换数据库 0~15
- 客户端一次只能对应一个数据库
- 目前为止没有显示客户端数据库的命令
typedef struct redisDb {
//id是本数据库的序号,为0-15(默认Redis有16个数据库)
int id;
//存储数据库所有的key-value
dict *dict;
//键的过期时间,字典的键为键,字典的值为过期 UNIX 时间戳
dict *expires;
//blpop 存储阻塞key和客户端对象
dict *blocking_keys;
//阻塞后push 响应阻塞客户端 存储阻塞后push的key和客户端对象
dict *ready_keys;
//存储watch监控的的key和客户端对象
dict *watched_keys;
//存储的数据库对象的平均ttl(time to live),用于统计
long long avg_ttl;
//List of key names to attempt to defrag one by one, gradually.
list *defrag_later;
} redisDb;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 3.redis 键空间
Redis 是一个键值对(key-value pair)数据库服务器,服务器中的每个数据库都由一 redis.h/redisDb 结构表示,其中,redisDb 结构的dict 字典保存了数据库中的所有键值对,我们将这个字典称为键空间(key space)
typedef struct redisDB(
//…
//数据库的键空间
dict *dict;
//…
)redisDB;
2
3
4
5
6
键空间和用户所见的数据库是直接对应的:
键空间的键也就是数据库的键,每个键都是一个字符串对象。
键空间的值也就是数据库的值,每个值可以是字符串对象、列表对象、哈希表对象、集合对象和有序集合对象中的任意一种 Redis 对象。
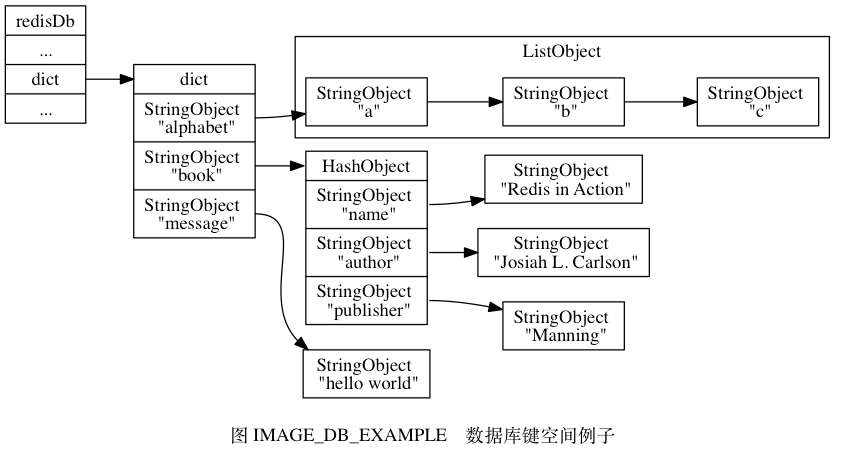
其他键空间操作 除了上面列出的添加、删除、更新、取值操作之外,还有很多针对数据库本身的 Redis 命令,也是通过对键空间进行处理来完成的 比如说:
- 用于清空整个数据库的 FLUSHDB 命令,就是通过删除键空间中的所有键值对 来实现的
- 用于随机返回数据库中某个键的 RANDOMKEY 命令,就是通过在键 空间中随机返回一个键来实现的
- 用于返回数据库键数量的 DBSIZE 命令,就是通过返回键空间中包含的键值对的 数量来实现的
- 类似的命令还有 EXISTS、RENAME、KEYS 等,这些命令都是通过对键空间 进行操作来实现的
//通用命令,帮助命令
127.0.0.1:6379> help @generic
//删除key
127.0.0.1:6379> del test
//删除多个key
127.0.0.1:6379> del test1 test2
(integer) 2
//key是否存在
127.0.0.1:6379> EXISTS test1
(integer) 1
//key的过期秒数
127.0.0.1:6379> expire test1 3
(integer) 1
//移除过期时间
127.0.0.1:6379> persist url
(integer) 1
//key重命名
127.0.0.1:6379> rename url url1234
OK
//类型检查
127.0.0.1:6379> type url
string
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
# 4.过期时间实现
键的生存时间或过期时间介绍
- 生存时间(Time To Live,TTL):在经过指定的秒数或者毫秒数之后,服务器就会自动删除生存时间为 0 的键
- 过期时间(expire time):是一个 UNIX 时间戳,当键的过期时间来临时,服务器就会自动从数据库中删除这个键
redisDb 结构的 expires 字典保存了数据库中所有键的过期时间,我们称这个字典为过期字典:
- 过期字典的键是一个指针,这个指针指向键空间中的某个键对象(也即是某个数据库键)
- 过期字典的值是一个 long 类型的整数,这个整数保存了键所指向的数据库键的过期时间,一个毫秒精度的
UNIX时间戳
typedef struct redisDB(
//…
…
//数据库的键空间
dict *dict;
//过期字典,保存着键的过期时间
dict *expires;
//…
)redisDB;
2
3
4
5
6
7
8
9
10
过期相关命令
通过 EXPIRE 命令或者 PEXPIRE 命令,客户端市可以以秒或者毫秒精度为数据库中的某个键设置生存时间(Time To Live,TTL),在经过指定的秒数或者毫秒数之后,服务器就会自动删除生存时间为 0 的键;
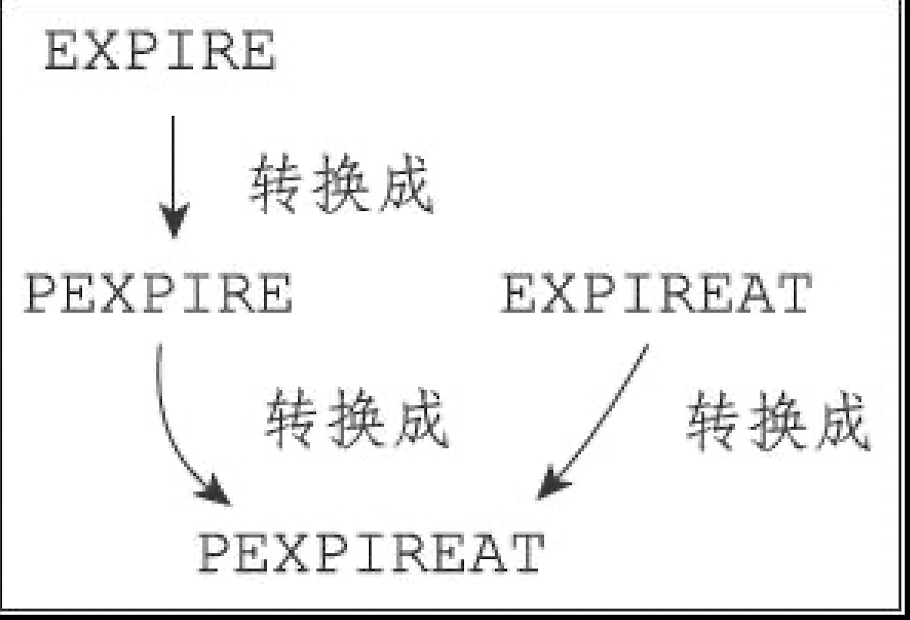
Redis 有四个不同的命令可以用于设置键的生存时间(键可以存在多久)或过期时间(键什么时候会被删除):
EXPIRE
命令用于将键 key 的生存时间设置为 ttl 秒。 PEXPIRE
命令用于将键 key 的生存时间设置为 ttl 毫秒。 EXPIREAT
命令用于将键 key 的过期时间设置为 timestamp 所指定的秒数时间戳。 PEXPIREAT
命令用于将键 key 的过期时间设置为 timestamp 所指定的毫秒数时间戳。
虽然有多种不同单位和不同形式的设置命令,但实际上 EXPIRE、PEXPIRE、EXPIREAT 三个命令都是使用 PEXPIREAT 命令来实现的:无论客户端执行的是以上四个命令中的哪一个,经过转换之后,最终的执行效果都和执行 PEXPIREAT 命令一样。
# 5.解除过期
PERSIST命令可以移除一个键的过期时间PERSIST命令就是PEXPIREAT命令的反操作:PERSIST命令在过期字典中查找给定的键,并解除键和值(过期时间)在过期字典中的关联
> setex kwan4 123 100
OK
> ttl kwan4
98
> persist kwan4
(integer) 1
> ttl kwan4
-1
2
3
4
5
6
7
8
# 6.返回过期时间
127.0.0.1:6379> ttl msg
(integer) -1
2
在为键设置了生存时间或者过期时间之后,用户可以使用 TTL 命令或者 PTTL 命令查看键的剩余生存时间,即键还有多久才会因为过期而被移除。
- 其中,TTL 命令将以秒为单位返回键的剩余生存时间;
- 而 PTTL 命令则会以毫秒为单位返回键的剩余生存时间;
# 7.过期删除策略
如果一个键过期了,那么它什么时候会被删除呢?
这个问题有三种可能的答案,它们分别代表了三种不同的删除策略:
定时删除:在设置键的过期时间的同时,创建一个定时器(timer),让定时器在键的过期时间来删除,立即执行对键的删除操作。惰性删除:放任键过期不管,但是每次从键空间中获取键时,都检查取得的键是否过期,如果过期的话,就删除该键;如果没有过期,就返回该键。定期删除:每隔一段时间,程序就对数据库进行一次检查,删除里面的过期键。至于要删除多少过期键,以及要检查多少个数据库,则由算法决定。
Redis 服务器实际使用的是惰性删除和定期删除两种策略:通过配合使用这两种删除策略,服务器可以很好地在合理使用 CPU 时间和避免浪费内存空间之间取得平衡。
惰性删除实现
因为每个被访问的键都可能因为过期而被 expirelfNeeded 函数删除,所以每个命令的实现函数都必须能同时处理键存在以及键不存在这两种情况:
当键存在时,命令按照键存在的情况执行。
当键不存在或者键因为过期而被
expirelfNeeded函数删除时,命令按照键不存在的情况执行。
定期删除实现
过期键的定期删除策略由 redisc/activeExpireCycle 函数实现,每当 Redis 的服务器周期性操作 redisc/serverCron函数执行时, activeExpireCycle 函数就会被调用,它在规定的时间内,分多次遍历服务器中的各个数据库,从数据库的 expires 字典中随机检查一部分键的过期时间,并删除其中的过期键。
activeExpireCycle 函数的工作模式可以总结如下:
- 函数每次运行时,都从一定数量的数据库中取出一定数量的随机键进行检查,并删除其中的过期键。
- 全局变量
currentdb会记录当前activeExpireCycle函数检查的进度,并在下一次activeExpireCvcle函数调用时,接着上一次的进度进行处理。比如说,如果当前activeExpireCycle函数在遍历 10 号数据库时返回了,那么下次activeExpireCycle函数执行时,将从 11 号数据库开始查找并删除过期键。 - 随着
activeExpireCycle函数的不断执行,服务器中的所有数据库都会被检查一遍,这时函数将currentdb变量重置为 0,然后再次开始新一轮的检查工作。
# 8.redis 事件
Redis 服务器是一个事件驱动程序,服务器需要处理以下两类事件:
文件事件(file event):Redis服务器通过套接字与客户端(或者其他 Redis 服务器)进行连接,而文件事件就是服务器对套接字操作的抽象。服务器与客户端(或者其他服务器)的通信会产生相应的文件事件,而服务器则通过监听并处理这些事件来完成一系列网络通信操作。时间事件(time event):Redis服务器中的一些操作(比如serverCron函数)需要在给定的时间点执行,而时间事件就是服务器对这类定时操作的抽象。
# 9.文件事件
Redis 基于 Reactor 模式开发了自己的网络事件处理器:这个处理器被称为文件事件处理器(file event handler):
文件事件处理器使用 I/O 多路复用(
multi plexing)程序来同时监听多个套接字,并根据套接字目前执行的任务来为套接字关联不同的事件处理器。当被监听的套接字准备好执行连接应答(accept)、读取(read)、写入(write)、关闭(close)等操作时,与操作相对 应的文件事件就会产生,这时文件事件处理器就会调用套接字之前关联好的事件处理器来处理这些事件。
虽然文件事件处理器以单线程方式运行,但通过使用 I/O 多路复用程序来监听多个套接字,文件事件处理器既实现了高性能的网络通信模型,又可以很好地与 Redis 服务器中其他同样以单线程方式运行的模块进行对接,这保持了 Redis 内部单线程设计的简单性。
# 10.文件事件处理器
文件事件处理器的四个组成部分,它们分别是
- 套接字
- I/O 多路复用程序
- 文件事件分派器(dispatcher)
- 事件处理器
套接字会有序同步到同一个队列
- 文件事件(套接字):是对套接字操作的抽象,每当一个套接字准备好执行连接应答(accept)、写 入、读取、关闭等操作时,就会产生一个文件事件。因为一个服务器通常会连接多个套接 字,所以多个文件事件有可能会并发地出现
- I/O 多路复用程序:负责监听多个套接字,并向文件事件分派器传送那些产生了事件的套接字
- 尽管多个文件事件可能会并发地出现,但 I/O 多路复用程序总是会将所有产生事件的套接字都放到一个队列里面,然后通过这个队列,以有序(sequentially)、同步 (synchronously)、每次一个套接字的方式向文件事件分派器传送套接字。当上一个套接字 产生的事件被处理完毕之后(该套接字为事件所关联的事件处理器执行完毕),I/O 多路复用 程序才会继续向文件事件分派器传送下一个套接字
- **文件事件分派器:**接收 I/O 多路复用程序传来的套接字,并根据套接字产生的事件的类型, 调用相应的事件处理器
- **事件处理器:**服务器会为执行不同任务的套接字关联不同的事件处理器,这些处理器是一个个函数, 它们定义了某个事件发生时,服务器应该执行的动作
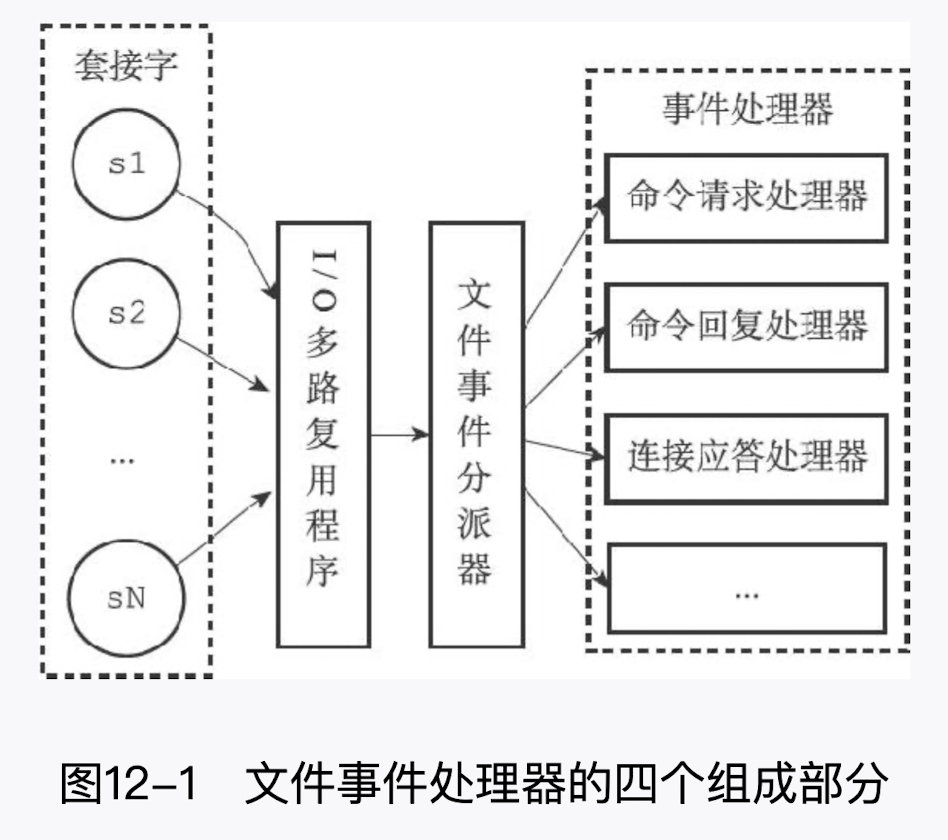
Redis 为文件事件编写了多个处理器,这些事件处理器分别用于实现不同的网络通信需求,比如说:
- 为了对连接服务器的各个客户端进行应答,服务器要为监听套接字关联连接应答处理器
- 为了接收客户端传来的命令请求,服务器要为客户端套接字关联命令请求处理器
- 为了向客户端返回命令的执行结果,服务器要为客户端套接字关联命令回复处理器
- 当主服务器和从服务器进行复制操作时,主从服务器都需要关联特别为复制功能编写的复制处理器
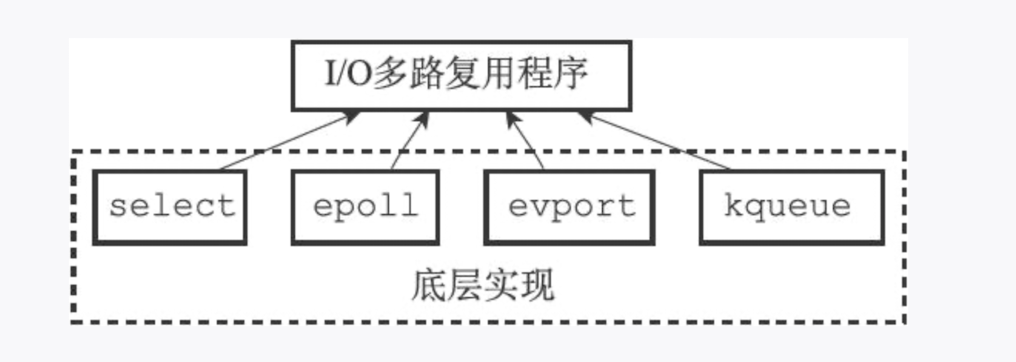
# 11.I/O 多路复用实现
Redis 的 I/O 多路复用程序的所有功能都是通过包装常见的 select、epoll、evport 和 kqueue 这些!/O 多路复用函数库来实现的,每个 I/O 多路复用函数库在 Redis 源码中都对应一个单独的文件,比如 ae_select.c、ae_epoll.c、ae_kqueue.c,诸如此类。
因为 Redis 为每个 I/O 多路复用函数库都实现了相同的 API,所以 I/O 多路复用程序的底层实现是可以互换的,如图所示。
如果套接字没有任何事件被监听,那么函数返回
AE_NONE。如果套接字的读事件正在被蓝听,那么函数返回
AE_READABLE。如果套接字的写事件正在被监听,那么函数返回
AE_WRITABLE。如果套接字的读事件和写事件正在被监听,那么函数返回
AE_READABLE|AE_WRITABLE.
Redis 在 I/O 多路复用程序的实现源码中用#include 宏定义了相应的规则,程序会在编译时 自动选择系统中性能最高的 I/O 多路复用函数库来作为 Redis 的 I/O 多路复用程序的底层实现
/* Include the best multiplexing layer supported by this system.
* The following should be ordered by performances, descending. */
# ifdef HAVE_EVPORT
# include "ae_evport.c"
# else
# ifdef HAVE_EPOLL
# include "ae_epoll.c"
# else
# ifdef HAVE_KQUEUE
# include "ae_kqueue.c"
# else
# include "ae_select.c"
# endif
# endif
# endif
2
3
4
5
6
7
8
9
10
11
12
13
14
15
引用知乎上一个高赞的回答来解释什么是 I/O 多路复用。假设你是一个老师,让 30 个学生解答一道题目,然后检查学生做的是否正确,你有下面几个选择:
- 第一种选择:按顺序逐个检查,先检查 A,然后是 B,之后是 C、D。。。这中间如果有一个学生卡住,全班都会被耽误。这种模式就好比,你用循环挨个处理 socket,根本不具有并发能力。
- 第二种选择:你创建 30 个分身,每个分身检查一个学生的答案是否正确。这种类似于为每一个用户创建一个进程或者- 线程处理连接。
- 第三种选择,你站在讲台上等,谁解答完谁举手。这时 C、D 举手,表示他们解答问题完毕,你下去依次检查 C、D 的答案,然后继续回到讲台上等。此时 E、A 又举手,然后去处理 E 和 A。
第一种就是阻塞 IO 模型,第三种就是 I/O 复用模型。
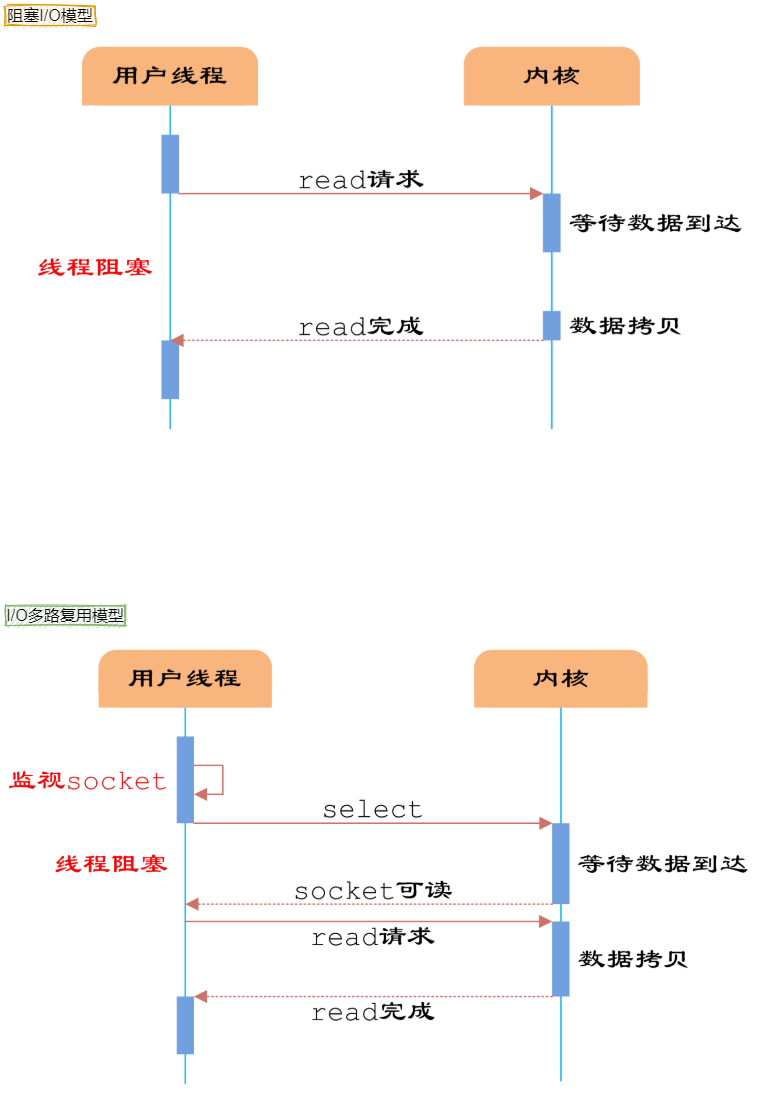
Linux 系统有三种方式实现 IO 多路复用:select、poll 和 epoll。
例如 epoll 方式是将用户 socket 对应的 fd 注册进 epoll,然后 epoll 帮你监听哪些 socket 上有消息到达,这样就避免了大量的无用操作。此时的 socket 应该采用非阻塞模式。
这样,整个过程只在进行 select、poll、epoll 这些调用的时候才会阻塞,收发客户消息是不会阻塞的,整个进程或者线程就被充分利用起来,这就是事件驱动,所谓的 reactor 模式。
# 12.一次完整的客户端与服务器连接事件示例
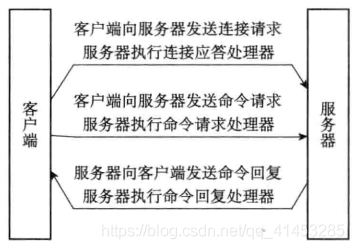
- ① 假设一个 Redis 服务器正在运作,那么这个服务器的监听套接字的
AE_READABLE事件应该正处于监听状态之下,而该事件所对应的处理器为连接应答处理器 - ② 如果这时有一个 Redis 客户端向服务器发起连接,那么监听套接字将产生
AE_READABLE事件,触发连接应答处理器执行。处理器会对客户端的连接请求进行应答, 然后创建客户端套接字,以及客户端状态,并将客户端套接字的AE_READABLE事件与命令 请求处理器进行关联,使得客户端可以向主服务器发送命令请求 - ③ 之后,假设客户端向主服务器发送一个命令请求,那么客户端套接字将产生
AE_READABLE事件,引发命令请求处理器执行,处理器读取客户端的命令内容,然后传给 相关程序去执行 - ④ 执行命令将产生相应的命令回复,为了将这些命令回复传送回客户端,服务器会将客户端套接字的
AE_WRITABLE事件与命令回复处理器进行关联。当客户端尝试读取命令回复的 时候,客户端套接字将产生AE_WRITABLE事件,触发命令回复处理器执行,当命令回复处 理器将命令回复全部写入到套接字之后,服务器就会解除客户端套接字的AE_WRITABLE事 件与命令回复处理器之间的关联
# 13.时间事件
Redis 的时间事件分为以下两类:
定时事件:让一段程序在指定的时间之后执行一次。比如说,让程序 X 在当前时间的 30 毫秒之后执行一次。
周期性事件:让一段程序每隔指定时间就执行一次。比如说,让程序 Y 每隔 30 毫秒就执行一次。
一个时间事件主要由以下三个属性组成:
id:服务器为时间事件创建的全局唯一 ID(标识号)。ID 号按从小到大的顺序递增,新事件的 ID 号比旧事件的 ID 号要大。
when:毫秒精度的 UNIX 时间戳,记录了时间事件的到达(arrive)时间。
timeProc:时间事件处理器,一个函数。当时间事件到达时,服务器就会调用相应的处理器来处理事件。
一个时间事件是定时事件还是周期性事件取决于时间事件处理器的返回值:
如果事件处理器返回 ae.h/AE_NOMORE,那么这个事件为定时事件:该事件在达到一次之后就会被删除,之后不再到达。
如果事件处理器返回一个非 AE_NOMORE 的整数值,那么这个事件为周期性时间:当一个时间事件到达之后,服务器会根据事件处理器返回的值,对时间事件的 when 属性进行更新,让这个事件在一段时间之后再次到达,并以这种方式一直更新并运行下去。比如说,如果一个时间事件的处理器返回整数值 30,那么服务器应该对这个时间事件进行更新,让这个事件在 30 毫秒之后再次到达。
# 14.时间事件实现原理
用链表连接起来的三个时间事件
注意,我们说保存时间事件的链表为无序链表,指的不是链表不按 ID 排序,而是说,该链表不按 when 属性的大小排序。正因为链表没有按 when 属性进行排序,所以当时间事件执行器运行的时候,它必须遍历链表中的所有时间事件,这样才能确保服务器中所有已到达的时间事件都会被处理。

# 15.serverCorn 函数
时间事件应用实例:serverCron 函数
持续运行的 Redis 服务器需要定期对自身的资源和状态进行检查和调整,从而确保服务器可以长期、稳定地运行,这些定期操作由redis.c/serverCron 函数负责执行,它的主要工作包括:
更新服务器的各类统计信息,比如时间、内存占用、数据库占用情况等。
清理数据库中的过期键值对。
关闭和清理连接失效的客户端。
尝试进行
AOF或RDB持久化操作。如果服务器是主服务器,那么对从服务器进行定期同步。
如果处于集群模式,对集群进行定期同步和连接测试。
Redis 服务器以周期性事件的方式来运行 serverCron 函数,在服务器运行期间,每隔一段时间,serverCron 就会执行一次,直到服务器关闭为止。
在 Redis2.6 版本,服务器默认规定 serverCron 每秒运行 10 次,平均每间隔 100 毫秒运行一次。
从 Redis28 开始,用户可以通过修改 hz 选项来调整 serverCron 的每秒执行次数,具体信息请参考示例配置文件 redisconf 关于 hz 选项的说明。
# 16.服务器的事件调度与执行
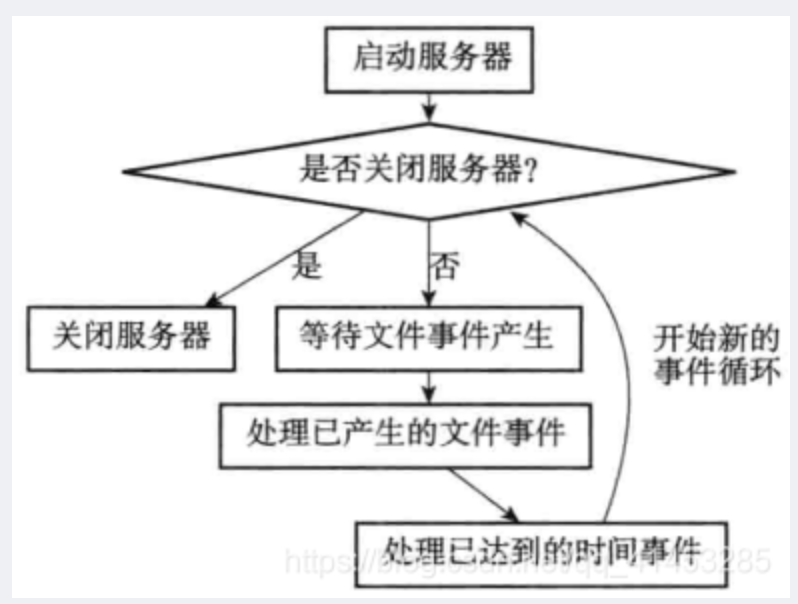
以下是事件的调度和执行规则:
- ①aeApiPoll 函数的最大阻塞时间由到达时间最接近当前时间的时间事件决定,这个方法既可以避免服务器对时间事件进行频繁的轮询(忙等待),也可以确保 aeApiPoll 函数不会 阻塞过长时间
- ② 因为文件事件是随机出现的,如果等待并处理完一次文件事件之后,仍未有任何时间事件到达,那么服务器将再次等待并处理文件事件。随着文件事件的不断执行,时间会逐 渐向时间事件所设置的到达时间逼近,并最终来到到达时间,这时服务器就可以开始处理到 达的时间事件了
- ③ 对文件事件和时间事件的处理都是同步、有序、原子地执行的,服务器不会中途中断事件处理,也不会对事件进行抢占,因此,不管是文件事件的处理器,还是时间事件的处 理器,它们都会尽可地减少程序的阻塞时间,并在有需要时主动让出执行权,从而降低造成 事件饥饿的可能性。比如说,在命令回复处理器将一个命令回复写入到客户端套接字时,如 果写入字节数超过了一个预设常量的话,命令回复处理器就会主动用 break 跳出写入循环,将 余下的数据留到下次再写;另外,时间事件也会将非常耗时的持久化操作放到子线程或者子 进程执行
- ④ 因为时间事件在文件事件之后执行,并且事件之间不会出现抢占,所以时间事件的实际处理时间,通常会比时间事件设定的到达时间稍晚一些
# 17.daemonize
daemonize 介绍
- redis.conf 配置文件中 daemonize 守护线程,默认是 NO。
- daemonize 是用来指定 redis 是否要用守护线程的方式启动。
daemonize 设置
yes或者no区别daemonize:yes:redis 采用的是单进程多线程的模式。当 redis.conf 中选项 daemonize 设置成 yes 时,代表开启守护进程模式。在该模式下,redis 会在后台运行,并将进程 pid 号写入至 redis.conf 选项 pidfile 设置的文件中,此时 redis 将一直运行,除非手动 kill 该进程。daemonize:no: 当 daemonize 选项设置成 no 时,当前界面将进入 redis 的命令行界面,exit 强制退出或者关闭连接工具(putty,xshell 等)都会导致 redis 进程退出。
# 18.redis 事件总结
Redis 服务器是一个事件驱动程序,服务器处理的事件分为时间事件和文件事件两类。
文件事件处理器是基于 Reactor 模式实现的网络通信程序。
文件事件是对套接字操作的抽象:每次套接字变为可应答(acceptable)、可写(writable)或者可读(readable)时,相应的文件事件就会产生。
文件事件分为 AEREADABLE 事件(读事件)和 AEWRITABLE 事件(写事件)两类。
时间事件分为定时事件和周期性事件:定时事件只在指定的时间到达一次,而周期性事件则每隔一段时间到达一次。
服务器在一般情况下只执行 serverCron 函数一个时间事件,并且这个事件是周期性事件。
文件事件和时间事件之间是合作关系,服务器会轮流处理这两种事件,并且处理事件的过程中也不会进行抢占。
时间事件的实际处理时间通常会比设定的到达时间晚一些。
# 二.Redis 客户端
# 1.服务端客户端交互
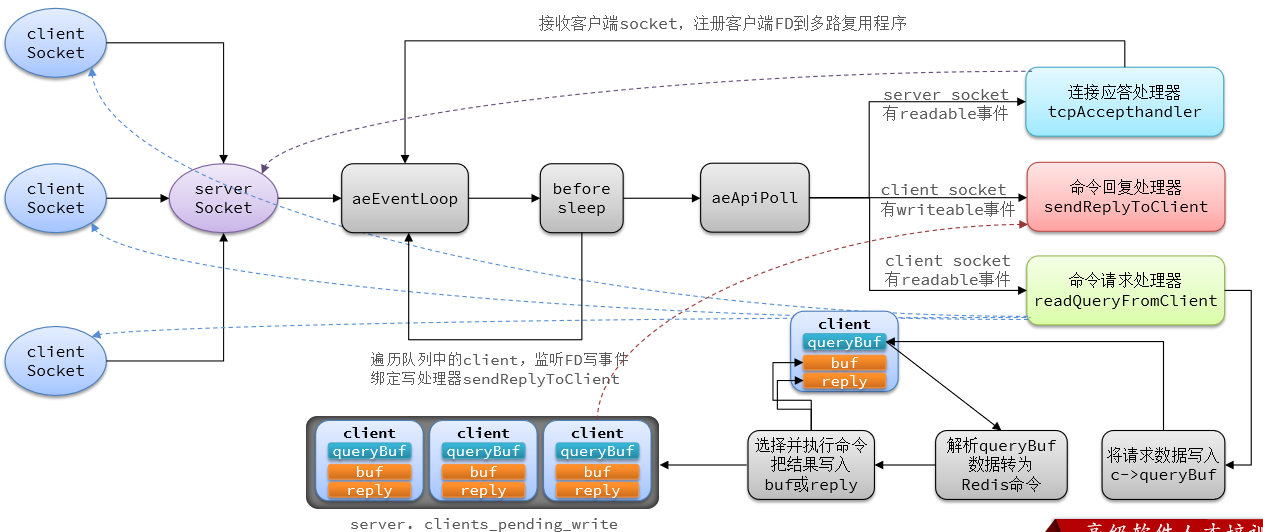
- Redis 服务器是典型的一对多服务器程序:一个服务器可以与多个客户端建立网络连接, 每个客户端可以向服务器发送命令请求,而服务器则接收并处理客户端发送的命令请求,并向客户端返回命令回复
- Redis 服务器通过使用由 I/O 多路复用技术实现的文件事件处理器,Redis 服务器使用单线程单进程的方式来处理命令请求,并与多个客户端进行网络通信
struct redisServer {
// ...
list *clients;// 一个链表,保存了所有客户端状态
// ...
};
2
3
4
5
- Redis 服务器状态结构的 clients 属性是一个链表,这个链表保存了所有与服务器连接的客 户端的状态结构,对客户端执行批量操作,或者查找某个指定的客户端,都可以通过遍历 clients 链表来完成
- 作为例子,左图展示了一个与三个客户端进行连接的服务器,而右图则展示了这个服务器的 clients 链表的样子
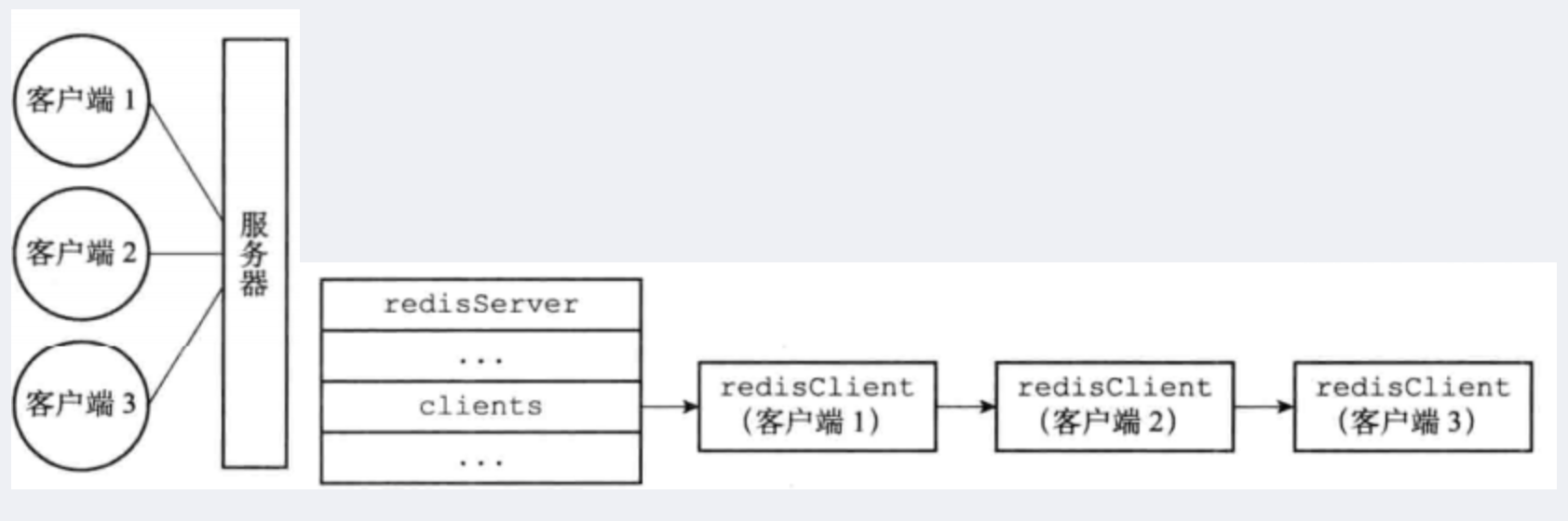
Redis 服务器状态结构的 clients 属性是一个链表,这个链表保存了所有与服务器连接的客户端的状态结构,对客户端执行批量操作,或者查找某个指定的客户端,都可以通过遍历 clients 链表来完成;
# 2.redisClient 结构
typedef struct client {
uint64_t id; // 客户端唯一ID,通过全局变量server.next_client_id实现。
int fd; // socket的文件描述符。
redisDb *db; // select命令选择的数据库对象
robj *name; // 客户端名称,可以使用命令CLIENT SETNAME设置。
time_t lastinteraction // 客户端上次与服务器交互的时间,以此实现客户端的超时处理。
sds querybuf; //输入缓冲区,recv函数接收的客户端命令请求会暂时缓存在此缓冲区。
int argc;
robj **argv;
struct redisCommand *cmd;
list *reply;
unsigned long long reply_bytes;
size_t sentlen;
char buf[PROTO_REPLY_CHUNK_BYTES];
int bufpos;
} client;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
属性说明
id 为客户端唯一 ID,通过全局变量 server.next_client_id 实现。
fd 为客户端 socket 的文件描述符。
db 为客户端使用 select 命令选择的数据库对象。
name:客户端名称,可以使用命令 CLIENT SETNAME 设置。
lastinteraction:客户端上次与服务器交互的时间,以此实现客户端的超时处理。
querybuf:输入缓冲区,recv 函数接收的客户端命令请求会暂时缓存在此缓冲区。
argc:输入缓冲区的命令请求是按照 Redis 协议格式编码字符串,需要解析出命令请求的所有参数,参数个数存储在 argc 字段,参数内容被解析为 robj 对象,存储在 argv 数组。
cmd:待执行的客户端命令;解析命令请求后,会根据命令名称查找该命令对应的命令对象,存储在客户端 cmd 字段,可以看到其类型为 struct redisCommand。
reply:输出链表,存储待返回给客户端的命令回复数据。链表节点存储的值类型为 clientReplyBlock
typedef struct clientReplyBlock {
size_t size, used;
char buf[];
} clientReplyBlock;
2
3
4
可以看到链表节点本质上就是一个缓冲区(buffffer),其中 size 表示缓冲区空间总大小,used 表示缓冲区已使用空间大小。
- reply_bytes:表示输出链表中所有节点的存储空间总和;
- sentlen:表示已返回给客户端的字节数;
- buf:输出缓冲区,存储待返回给客户端的命令回复数据,
- bufpos 表示输出缓冲区中数据的最大字节位置,显然 sentlen ~ bufpos 区间的数据都是需要返回给客户端的。可以看到 reply 和 buf 都用于缓存待返回给客户端的命令回复数据,为什么同时需要 reply 和 buf 的存在呢?其实二者只是用于返回不同的数据类型而已,将在后面讲解。
对于每个与服务器进行连接的客户端,服务器都为这些客户端建立了相应的 redis.h/redisClient 结构(客户端状态),这个结构保存了客户端当前的状态信息,以及执行相关功能时需要用到的数据结构,其中包括:
客户端的套接字描述符。
客户端的名字。
客户端的标志值(flag)。
指向客户端正在使用的数据库的指针,以及该数据库的号码。
客户端当前要执行的命令、命令的参数、命令参数的个数,以及指向命令实现函数的指针。
客户端的输入缓冲区和输出缓冲区。
客户端的复制状态信息,以及进行复制所需的数据结构。
客户端执行 BRPOP、BLPOP 等列表阻塞命令时使用的数据结构。
客户端的事务状态,以及执行 WATCH 命令时用到的数据结构。
客户端执行发布与订阅功能时用到的数据结构。
客户端的身份验证标志。
客户端的创建时间,客户端和服务器最后一次通信的时间,以及客户端的输出缓冲区大小超出软性限制(soft limit)的时间。
# 3.套接字描述符
客户端状态的 fd 属性记录了客户端正在使用的套接字描述符:
根据客户端类型的不同,fd 属性的值可以是-1 或者是大于-1 的整数:
- 伪客户端(fake client)的 fd 属性的值为-1:伪客户端处理的命令请求来源于 AOF 文件或者 Lua 脚本,而不是网络,所以这种客户端不需要套接字连接,自然也不需要记录套接字描述符。目前 Redis 服务器会在两个地方用到伪客户端,一个用于载入 AOF 文件并还原数据库状态,而另一个则用于执行 Lua 脚本中包含的 Redis 命令。
- 普通客户端的 fd 属性的值为大于-1 的整数:普通客户端使用套接字来与服务器进行通信,所以服务器会用 fd 属性来记录客户端套接字的描述符。因为合法的套接字描述符不能是-1,所以普通客户端的套接字描述符的值必然是大于-1 的整数。
127.0.0.1:6379> client list
id=9 addr=127.0.0.1:56659 laddr=127.0.0.1:6379 fd=8 name= age=5 idle=0 flags=N db=0 sub=0 psub=0 ssub=0 multi=-1 qbuf=26 qbuf-free=16864 argv-mem=10 multi-mem=0 rbs=1024 rbp=0 obl=0 oll=0 omem=0 tot-mem=18682 events=r cmd=client|list user=default redir=-1 resp=2
2
# 4.客户端名字
在 Redis 中,客户端可以设置一个名字(name 属性)来标识自己。这可以用于识别不同的客户端连接,监控日志,以及调试。以下是关于客户端名字的一些重要信息:
默认名字: 在默认情况下,连接到 Redis 服务器的客户端没有名字,即 name 属性为空。
设置客户端名字: 可以使用
CLIENT SETNAME命令来为客户端设置一个名字。例如,以下命令将为当前连接设置名字为 "myclient":CLIENT SETNAME myclient1查看客户端名字: 使用
CLIENT GETNAME命令可以获取当前客户端的名字。例如:CLIENT GETNAME1如果名字为空,命令将返回
nil。用途: 设置客户端名字有助于在监控和日志中区分不同的客户端连接。这在调试、追踪问题和性能监控时特别有用。
注意事项: 客户端名字是以字符串形式存储在 Redis 服务器中,可以根据需要进行设置和更改。然而,客户端名字不是唯一标识客户端的方法。IP 地址和端口号等连接信息也可以用来区分不同的客户端连接。
示例:
rubyCopy code
127.0.0.1:6379> CLIENT SETNAME myclient
OK
127.0.0.1:6379> CLIENT GETNAME
"myclient"
2
3
4
5
# 5.客户端标志
flags 标志:客户端的标志属性 flags 记录了客户端的角色(role),以及客户端目前所处的状态;
每个标志使用一个常量表示,一部分标志记录了客户端的角色.
在主从服务器进行复制操作时,主服务器会成为从服务器的客户端,而从服务器也会成为主服务器的客户端。
REDIS_MASTER标志表示客户端代表的是一个主服务器,REDIS_SLAVE标志表示客户端代表的是一个从服务器。REDIS_PRE_PSYNC标志表示客户端代表的是一个版本低于 Redis2.8 的从服务器,主服务器不能使用PSYNC命令与这个从服务器进行同步。这个标志只能在REDIS_SLAVE标志处于打开状态时使用。REDIS_LUA_CLIENT标识表示客户端是专门用于处理 Lua 脚本里面包含的 Redis 命令的伪客户端。而另外一部分标志则记录了客户端目前所处的状态;REDIS_MONITOR标志表示客户端正在执行MONITOR命令。REDIS_UNIX_SOCKET标志表示服务器使用UNIX套接字来连接客户端。REDIS_BLOCKED标志表示客户端正在被BRPOP、BLPOP等命令阻塞。REDIS_UNBLOCKED标志表示客户端已经从REDIS_BLOCKED标志所表示的阻塞状态中脱离出来,不再阻塞。REDIS_UNBLOCKED标志只能在REDIS_BLOCKED标志已经打开的情况下使用。REDIS_MULTI标志表示客户端正在执行事务。REDIS_DIRTY_CAS标志表示事务使用WATCH命令监视的数据库键已经被修改,REDIS_DIRTY_EXEC标志表示事务在命令入队时出现了错误,以上两个标志都表示事务的安全性已经被破坏,只要这两个标记中的任意一个被打开,EXEC命令必然会执行失败。这两个标志只能在客户端打开了REDIS_MULTI标志的情况下使用。REDIS_CLOSE_ASAP标志表示客户端的输出缓冲区大小超出了服务器允许的范围,服务器会在下一次执行serverCron函数时关闭这个客户端,以免服务器的稳定性受到这个客户端影响。积存在输出缓冲区中的所有内容会直接被释放,不会返回给客户端。REDIS_CLOSE_AFTER_REPLY标志表示有用户对这个客户端执行了CLIENT KILL命令,或者客户端发送给服务器的命令请求中包含了错误的协议内容。服务器会将客户端积存在输出缓冲区中的所有内容发送给客户端,然后关闭客户端。REDIS_ASKING标志表示客户端向集群节点(运行在集群模式下的服务器)发送了ASKING命令。REDIS_FORCE_AOF标志强制服务器将当前执行的命令写入到AOF文件里面,REDIS_FORCE_REPL标志强制主服务器将当前执行的命令复制给所有从服务器。执行PUBSUB命令会使客户端打开REDIS_FORCE_AOF标志,执行SCRIPT LOAD命令会使客户端打开REDIS_FORCE_AOF标志和REDIS_FORCE_REPL标志。
在主从服务器进行命令传播期间,从服务器需要向主服务器发送 REPLICATION_ACK 命令,在发送这个命令之前,从服务器必须打开主服务器对应的客户端的 REDIS_MASTER_FORCE_REPLY 标志,否则发送操作会被拒绝执行。
两种特殊客户端
- 服务器会在初始化时创建负责执行
Lua脚本中包含的Redis命令的伪客户端,并将这个伪客户端关联在服务器状态结构的lua_client属性中: lua_client伪客户端在服务器运行的整个生命周期中会一直存在,只有服务器被关闭时,这 个客户端才会被关闭。- 服务器在载入
AOF文件时,会创建用于执行AOF文件包含的Redis命令的伪客户端,并在 载入完成之后,关闭这 个伪客户端。
# 6.输入缓冲区
在 Redis 中,客户端状态(Client State)中的 querybuf 属性是用于处理输入缓冲区的。以下是关于 querybuf 属性以及输入缓冲区的一些重要信息:
- querybuf 属性: 在 Redis 的客户端状态中,
querybuf是一个输入缓冲区(Input Buffer),用于暂时存储客户端发送的命令请求。 - 输入缓冲区: 输入缓冲区是用来存储客户端发送给 Redis 服务器的命令、查询或其他数据的临时区域。当客户端发送命令时,这些命令会被读取并存储在输入缓冲区中。
- 动态调整: 输入缓冲区(
querybuf)可以根据需要动态地扩大和缩小。这有助于适应不同大小的命令请求。 - 缓冲区大小限制: 输入缓冲区的大小有一个最大限制,一般情况下不能超过
1GB。如果输入缓冲区的大小超过这个限制,Redis会关闭该客户端连接,以避免资源耗尽和系统崩溃。 - 使用场景: 输入缓冲区的使用场景包括处理客户端发送的命令、读取数据、解析命令参数等。一旦命令完全读取并解析完毕,服务器将会执行命令,然后将执行结果发送回客户端。
# 7.命令与命令参数
在服务器将客户端发送的命令请求保存到客户端状态的 querybuf 属性之后,服务器将对命令请求的内容进行分析后,并将得出的命令参数以及命令参数的个数分别保存到客户端状态的 argv 属性和 argc 属性:
在 Redis 中,argv 和 argc 是两个重要的属性,用于处理命令和命令参数。以下是关于 argv 和 argc 的详细说明:
argv属性:argv是一个数组(Array),数组中的每个元素都是一个指向字符串对象的指针,其中argv[0]是要执行的命令的名称,而之后的元素则是传递给命令的参数。每个参数都表示为一个字符串对象。argc属性:argc是一个整数(Integer),用于记录argv数组的长度。它表示了命令及其参数的数量。命令执行过程: 当客户端发送一个命令请求给 Redis 服务器时,服务器会将命令及其参数解析为字符串对象并存储在
argv数组中。argc记录了数组的长度。然后,服务器会根据argv[0]中的命令名称找到相应的命令处理函数,并传递argc和argv作为参数。这样,命令就可以被正确执行并处理。例子: 假设客户端发送命令请求
SET key value给 Redis 服务器。服务器会将命令名称"SET"存储在argv[0],参数"key"存储在argv[1],参数"value"存储在argv[2]。同时,argc将设置为 3,表示命令及其参数的数量。makefileCopy code argv[0] = "SET" argv[1] = "key" argv[2] = "value" argc = 31
2
3
4
5
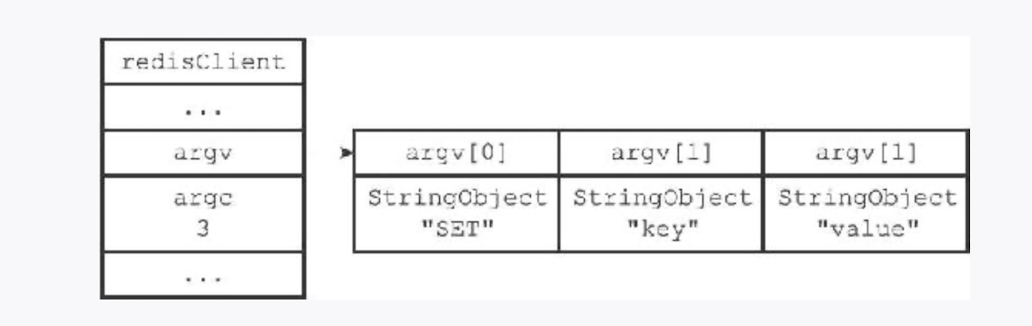
命令表中使用字典保存着 redis 的命令字典.且不区分大小写.
# 8.命令的实现函数
当服务器从协议内容中分析并得出 argv 属性和 argc 属性的值之后,服务器将根据项 argv[0]的值,在命令表中查找命令所对应的命令实现函数.
命令表格式,下图展示了一个命令表示例,该表是一个字典,字典的键是一个 SDS 结构,保存了命令的名字,字典的值是命令所对应的 redisCommand 结构,这个结构保存了命令的实现函数、 命令的标志、命令应该给定的参数个数、命令的总执行次数和总消耗时长等统计信息.
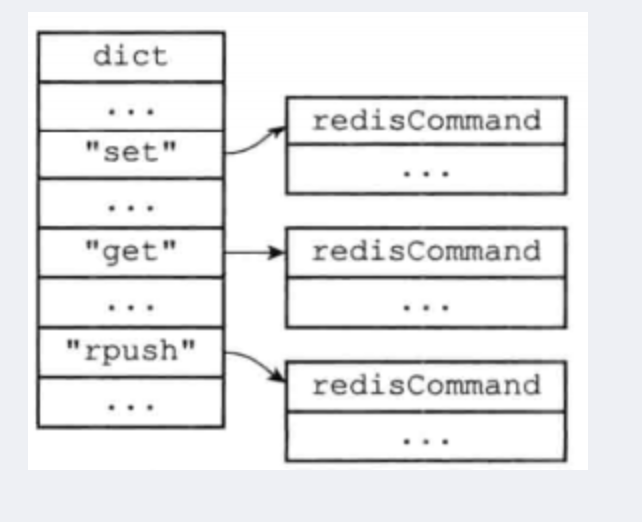
- 当程序在命令表中成功找到
argv[0]所对应的redisCommand结构时,它会将客户端状态的cmd指针指向这个结构 - 之后,服务器就可以使用
cmd属性所指向的redisCommand结构,以及argv、argc属性中保存的命令参数信息,调用命令实现函数,执行客户端指定的命令 - 服务器在
argv[0]为"SET"时,查找命令表并将客户端状态的cmd指针指向目标redisCommand结构 - 针对命令表的查找操作
不区分输入字母的大小写,所以无论argv[0]是"SET"、"set"、或 者"SeT"等等,查找的结果都是相同的
# 9.输出缓冲区
执行命令所得的命令回复会被保存在客户端状态的输出缓冲区里面,每个客户端都有两个输出缓冲区可用,一个缓冲区的大小是固定的,另一个缓冲区的大小是可变的:
固定大小的缓冲区用干保存那些长度比较小的回复,比如 OK、简短的字符串值、整数值、错误回复等等。可变大小的缓冲区用于保存那些长度比较大的回复,比如一个非常长的字符串值,一个由很多项组成的列表,一个包含了很多元素的集合等等。
客户端的固定大小缓冲区由 buf 和 bufpos 两个属性组成:
buf是一个大小为REDIS_REPLY_CHUNK_BYTES字节的字节数组,而bufpos属性则记录了buf数组目前已使用的字节数量。REDIS_REPLY_CHUNK_BYTES常量目前的默认值为 16*1024,也即是说,buf数组的默认大小为16KB。
通过使用链表来连接多个字符串对象,服务器可以为客户端保存一个非常长的命令回复,而不必受到固定大小缓冲区 16KB 大小的限制。
服务器使用两种模式来限制客户端输出缓冲区的大小:
硬性限制(hardlimit):如果输出缓冲区的大小超过了硬性限制所设置的大小,那么服务器立即关闭客户端。软性限制(softlimit):如果输出缓冲区的大小超过了软性限制所设置的大小,但还没超过硬性限制,那么服务器将使用客户端状态结构的 obuf_soft_limit_reached_time 属性记录下客户端到达软性限制的起始时间;之后服务器会继续监视客户端,如果输出缓冲区的大小一直超出软性限制,并且持续时间超过服务器设定的时长,那么服务器将关闭客户端;相反地,如果输出缓冲区的大小在指定时间之内,不再超出软性限制,那么客户端就不会被关闭,并且 obuf_soft_limit_reachedtime 属性的值也会被清零。
# 10.身份验证
客户端状态的 authenticated 属性用于记录客户 端是否通过了身份验证:
- 如果
authenticated的的值为 0,那么表示客户端未通过身份验证; - 如果
authenticated的值为 1,那么表示客户端已经通过了身份验证。
当客户端 authenticated 属性的值为 0 时,除除了 AUTH 命令之外,客户端发送的所有其他命令都会被服务器拒绝执行;
# 11.客户端时间属性
typedef struct redisClient {
// ...
time_t ctime;
time_t lastinteraction;
time_t obuf_soft_limit_reached_time;
// ...
} redisClient;
2
3
4
5
6
7
ctime 属性记录了创建客户端的时间,这个时间可以用来计算客户端与服务器已经连接了多少秒,CLIENT list命令的 age 域记录了这个秒数;
lastinteraction 属性
- 记录了客户端与服务器最后一次进行互动(
interaction)的时间,这里的互动可以是客户端向服务器发送命令请求,也可以是服务器向客户端发送命令回复 - 可以用来计算客户端的空转(
idle)时间,也即是,距离客户端与服务器最后一次进行互动以来,已经过去了多少秒,CLIENT list命令的idle域记录了这个秒数
obuf_soft_limit_reachedtime 属性记录了输出缓冲区大小第一次到达软性限制(soft limit)的时间.
# 12.客户端关闭原因
一个普通客户端可以因为多种原因而被关闭:
- 如果客户端进程退出或者被杀死,那么客户端与服务器之间的网络连接将被关闭,从而造成客户端被关闭
- 如果客户端向服务器发送了带有不符合协议格式的命令请求,那么这个客户端也会被服务器关闭
- 如果客户端成为了
CLIENT KILL命令的目标,那么它也会被关闭 - 如果用户为服务器设置了 timeout 配置选项,那么当客户端的空转时间超过
timeout选项 设置的值时,客户端将被关闭。不过timeout选项有一些例外情况:如果客户端是主服务器 (打开了REDIS_MASTER标志),从服务器(打开了REDIS_SLAVE标志),正在被BLPOP等命令阻塞(打开了REDIS_BLOCKED标志),或者正在执行SUBSCRIBE、PSUBSCRIBE等 订阅命令,那么即使客户端的空转时间超过了timeout选项的值,客户端也不会被服务器关 闭 - 如果客户端发送的命令请求的大小超过了
输入缓冲区的限制大小(默认为 1 GB),那么这个客户端会被服务器关闭 - 如果要发送给客户端的命令回复的大小超过了
输出缓冲区的限制大小,那么这个客户端 会被服务器关闭
# 13.客户端总结
- 服务器状态结构使用
clients链表连接起多个客户端状态,新添加的客户端状态会被放到链表的末尾。 - 客户端状态的
flags属性使用不同标志来表示客户端的角色,以及客户端当前所处的状态。 - 输入缓冲区记录了客户端发送的命令请求,这个缓冲区的大小不能超过
1GB。 命令的参数和参数个数会被记录在客户端状态的argv和argc属性里面,而cmd属性则记录了客户端要执行命令的实现函数。- 客户端有固定大小缓冲区和可变大小缓冲区两种缓冲区可用,其中固定大小缓冲区的最大大小为
16KB,而可变大小缓冲区的最大大小不能超过服务器设置的硬性限制值。 - 输出缓冲区限制值有两种,如果输出缓冲区的大小超过了服务器设置的
硬性限制,那么客户端会被立即关闭;除此之外,如果客户端在一定时间内,一直超过服务器设置的软性限制,那么客户端也会被关闭。 - 当一个客户端通过网络连接连上服务器时,服务器会为这个客户端创建相应的客户端状态。网络连接关闭、发送了不符合协议格式的命令请求、成为
CLIENT KILL命令的目标、空转时间超时、输出缓冲区的大小超出限制,以上这些原因都会造成客户端被关闭。 - 处理
Lua脚本的伪客户端在服务器初始化时创建,这个客户端会一直存在,直到服务器关闭。 - 载入
AOF文件时使用的伪客户端在载入工作开始时动态创建,载入工作完毕之后关闭。
# 三.Redis 服务端
# 1.服务端命令的执行过程
客户端向服务器发送命 令请求 SET KEY VALUE。
服务器接收并处理客户端发来的命令请求 SET KEY VALUE,在数据库中进行设置操作,并产生命令回复 OK。
服务器将命令回复 OK 发送给客户端。
客户端接收服务器返回的命令回复 OK,并将这个回复打印给用户观看。
# 2.发送命令请求
客户端从用户得到命令请求后转换为协议格式,再连接服务器的套接字,再将协议格式的命令发送给服务器
# 3.读取命令请求
当客户端与服务器之间的连接套接字因为客户端的写入而变得可读时,服务器将调用命令请求处理器来执行以下操作:
- 读取套接字中
协议格式的命令请求,并将其保存到客户端状态的输入缓冲区里面。 - 对
输入缓冲区中的命令请求进行分析,提取出命令请求中包含的命令参数,以及命令参数的个数,然后分别将参数和参数个数保存到客户端状态的argv属性和argc属性里面。 - 调用命令执行器,执行客户端指定的命令。
# 4.命令执行器
查找命令
第一件事根据 argv[0]参数在命令表中查找命令,并保存到客户端状态的 cmd 属性中命令表是一个字典,键为字符串对象,值为 redisCommand 结构记录 redis 命令实现信息 redisCommand 结构主要属性:

struct redisCommand {
char *name;//命令名
redisCommandProc *proc;//命令执行函数
int arity; //参数个数,-N代表参数个数>=N,正数表示参数个数为N
char *sflags; //命令的sflags属性字符串
int flags; //从sflags获取的整数mask值
//获取key参数的可选函数,当下面3种情况都无法确定key参数的时候才需要使用该函数
redisGetKeysProc *getkeys_proc;
int firstkey; //第一个key的位置,0表示没有key
int lastkey; //最后一个key的位置;负数计算为正数第(argc+lastkey)个
int keystep; //参数为 key,val,key,val,...格式,第一个和最后一个key之间的key跨步
long long microseconds;//命令从服务启动到现在的执行时间,单位:微秒
long long calls;//命令从服务启动到现在的执行的次数
};
2
3
4
5
6
7
8
9
10
11
12
13
14
属性说明
name:命令名称。
proc:命令处理函数。
arity:命令参数数目,用于校验命令请求格式是否正确;当 arity 小于 0 时,表示命令参数数目大于等于 arity;当 arity 大于 0 时,表示命令参数数目必须为 arity;注意命令请求中,命令的名称本身也是一个参数,如 get 命令的参数数目为 2,命令请求格式为 get key。
sflags:命令标志,例如标识命令时读命令还是写命令,详情参见表 9-2;注意到 sflags 的类型为字符串,此处只是为了良好的可读性。
flags:命令的二进制标志,服务器启动时解析 sflags 字段生成。
calls:从服务器启动至今命令执行的次数,用于统计。
microseconds:从服务器启动至今命令总的执行时间,
microseconds/calls 即可计算出该命令的平均处理时间,用于统计。
执行预操作
执行命令之前还需要一些预操作
检查客户端状态的 cmd 是否指向 NULL,是则找不到命令实现,返回错误
根据 cmd 指向的 redisCommand 结构的 arity 属性,检查命令的个数是否匹配,否则不执行返回错误
检查客户端是否通过了身份验证,没有则只能执行 AUTH 命令,否则则返回错误
如果服务器打开了 maxmemory 功能,会先检查服务器的内存占用情况,并在有需要时进行内存回收,如果回收失败则不再执行后续步骤,返回错误
如果服务器上一次执行 BGSAVE 命令出差,且打开了 stop-writes-on-bgsave-error 功能
如果客户端在使用 SUBSCRIBE 命令订阅频道,或者在使用 PSUBSCRIBE 模式,则只会执行 SUBSCRIBE、PSUBSCRIBE、UNSUBSCRIBE、PUNSUBSCRIBE 四个命令,其他则拒绝
如果服务器在进行数据载入,客户端发送的命令需要带有 l 标识(INFO、SHUTDOWN、PUBLISH)才会被服务器执行
如果服务器执行 Lua 脚本超时而阻塞,则只会执行 SHUTDOWN nosave 和 SCRIPT KILL 命令
如果客户端在执行事务,服务器只会执行客户端的 EXEC、DISCARD、MULTI、WATCH 命令,其他会被放进事务队列
如果服务器打开了监视器功能,服务器则先把执行的命令和参数发给监视器,然后才真正执行命令
调用命令实现函数
由于 cmd 已经保存了命令实现,命令参数、个数已经保存在 argv、argc 中,只需要执行
client -> cmd -> proc(client)
命令实现函数执行指定操作,并参数相应回复,保存在客户端输出缓冲区 (buf、reply 属性),再为客户端的套接字关联命令回复处理器
执行后续工作
如果服务器开启慢查询,慢查询模块需要检查是否为执行完的命令添加一条新的慢查询日志
根据耗费时长,更新 redisCommand 结构的 milliseconds 属性,并将 calls 计数器 + 1
如果 AOF 开启了,则会将命令写入 AOF 缓冲区
如果有其他服务器正在复制当前的服务器,也会将命令传播给所有从服务器
将命令发送给客户端
命令实现函数会将输出回复保存在输出缓冲区里面,并为客户端套接字关联命令回复处理器,当客户端套接字可写时,服务器则会执行命令回复处理器,将保存在客户端输出缓冲区的命令回复发送给客户端
客户端接受并打印命令回复
当客户端接收到协议格式的命令回复之后,它会将这些回复转换成人类可读的格式,并打印给用户观看
# 5.serverCron 常见任务
以下是一些可能由 serverCron 函数执行的常见任务:
- 过期键清理:Redis 使用定期任务来清理过期的键,以释放已经过期但未被删除的键的内存。
serverCron可能会定期检查并清理这些过期键。 - 持久化:如果 Redis 配置为持久化数据,
serverCron可能会负责执行 RDB 快照或者 AOF 文件的写入,以将数据持久化到磁盘。 - 内存管理:
serverCron可能会定期进行内存碎片整理和内存回收,以优化 Redis 的内存使用情况。 - 统计信息收集:服务器周期性地收集关于内存使用、命令执行次数、客户端连接数等统计信息,以便管理员进行监控和调优。
- 事件通知:
serverCron可能会定期发布一些特定的事件通知,以便外部系统可以订阅这些事件并做出相应处理。 - LUA 脚本清理:
serverCron可能会定期清理没有在使用的 LUA 脚本缓存,以释放内存。 - 慢查询日志:如果启用了慢查询日志,
serverCron可能会定期检查命令执行时间,并将超过阈值的慢查询记录下来。
# 6.serverCron 时间相关
默认每隔 100 毫秒运行一次,负责管理服务器资源,并保持服务器自身的良好运作
更新服务器时间缓存
获取系统当前时间需要执行系统调用,为了减少次数,服务器中的 unixtmie 和 mstime 属性被用作当前时间的缓存,因为 serverCron 函数默认会以每 100 毫秒一次的频率更新 unixtime 属性和 mstime 属性,所以这两个属性记录的时间的精确度并不高
服务器只会在打印日志、更新服务器的
LRU时钟、决定是否执行持久化任务、计算服务器上线时间等对时间精确度要求不高的功能上使用上述两个属性对于键过期时间、添加慢查询日志这种高精度时间的功能仍旧执行系统调用
struct redisServer {
// ...
//保存了秒级精度的系统当前UNIX 时间戳
time_t unixtime;
//保存了毫秒级精度的系统当前UNIX 时间戳
long long mstime;
// ...
};
2
3
4
5
6
7
8
更新 LRU 时钟
struct redisServer {
// ...
//默认每10 秒更新一次的时钟缓存,
//用于计算键的空转(idle )时长。
unsigned lruclock:22;
// ...
};
2
3
4
5
6
7
lruclock保存了服务器的LRU时钟,为时间缓存的一种,默认每 10 秒更新一次每个对象都有一个
lru属性,保存了对象最后一次被命令访问的时间数据库键的空转时间(减法):
lruclock - lru
typedef struct redisObject {
// ...
unsigned lru:22;
// ...
} robj;
2
3
4
5
更新服务器每秒执行命令次数
struct redisServer {
// ...
//上一次进行抽样的时间
long long ops_sec_last_sample_time;
//上一次抽样时,服务器已执行命令的数量
long long ops_sec_last_sample_ops;
// REDIS_OPS_SEC_SAMPLES 大小(默认值为16 )的环形数组,
//数组中的每个项都记录了一次抽样结果。
long long ops_sec_samples[REDIS_OPS_SEC_SAMPLES];
// ops_sec_samples 数组的索引值,
//每次抽样后将值自增一,
//在值等于16 时重置为0 ,
//让ops_sec_samples 数组构成一个环形数组。
int ops_sec_idx;
// ...
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
serverCron 中的 trackOpearationPerSecond 函数会以每 100 毫秒频率执行,功能是以抽样方式估算记录服务器在最近一秒钟处理的命令请求数量,通过 Info stats 命令的 instanceous_ops_sec 域查看
127.0.0.1:6379> INFO stats
#Stats
total_connections_received:2
total_commands_processed:3
instantaneous_ops_per_sec:0
2
3
4
5
trackOpearationPerSecond 函数和服务器状态中四个 ops_sec 开头的属性有关
trackOpearationPerSecond 函数每次运行会根据 ops_sec_last_sample_time 记录的上一次抽样时间和服务器当前时间,以及 ops_sec_last_sample_ops 记录的上一次抽样的已执行命令数量和服务器当前的已执行数量,计算两次调用之间服务器平均每毫秒处理了多少请求,再计算一秒钟服务器能处理多少请求的估计值,再作为新数组项放进 ops_sec_samples 环形数组里
执行 INFO 命令时服务器调用 getOperationPerSecond 函数,根据 ops_sec_samples 环形数组中抽样结果,计算 instanceous_ops_per_sec 属性的值
# 7.serverCron 内存和资源
更新服务器内存峰值记录
struct redisServer {
// ...
//已使用内存峰值
size_t stat_peak_memory;
// ...
};
2
3
4
5
6
服务器状态的 stat_peak_memory 记录了服务器内存峰值大小
serverCron 函数执行时服务器则查看当前使用内存数量,与 stat_peak_memory 进行大小对比
127.0.0.1:6379> info memory
# Memory
used_memory_peek:692456
used_memory_peek_human:676.23K
2
3
4
used_memory_peek 和 used_memory_peek_human 是两种不同格式记录
管理客户端资源 serverCron 函数会调用 clientsCron 函数对一定数量的客户端进行检查:
连接超时,即很长时间没有互动,释放客户端
输入缓冲区超过一定长度,释放客户端当前输入缓冲区,重新创建一个默认大小的输入缓冲区,防止耗费内存
管理数据库资源 serverCron 函数会调用 databasesCron 函数对一部分数据库检查,删除过期键,并在有需要时对字典进行收缩操作
# 8.serverCron 事件通知
处理 SIGTERM 信号 服务器启动后服务器进程的 SIGTERM 信号会关联 sigtermHandler 函数,负责在服务器接到 SIGTERM 信号时,打开服务器状态的 shutdown_asap 标识
// SIGTERM 信号的处理器
static void sigtermHandler(int sig) {
//打印日志
redisLogFromHandler(REDIS_WARNING,"Received SIGTERM, scheduling shutdown...");
//打开关闭标识
server.shutdown_asap = 1;
}
2
3
4
5
6
7
serverCron 函数则是对服务器状态的 shutdown_asap 属性检查,根据只决定是否关闭服务器
- 1 :关闭服务器
- 0: 不做动作
服务器在关闭自身之前会进行 RDB 持久化操作,对 SIGTERM 信号拦截
执行被延迟的 BGREWRITEAOF
在执行 BGSAVE 期间,如果客户端向服务器发来 BGREWRITEAOF 命令,则会延迟到 BGSAVE 命令结束之后
服务器的 aof_rewrite_scheduled 标识了是否延迟,1 为延迟
serverCron 函数会检查 BGSAVE 或 BGREWRITEAOF 是否在运行,如果没有且 aof_rewrite_scheduled 为 1,则执行被延迟的 BGREWRITEAOF 命令
检查持久化操作的运行状态
服务器状态使用 rdb_child_pid 属性和 aof_child_pid 属性记录了执行 BGSAVE 和 BGREWRITEAOF 命令子进程的 ID,可以用于检查 BGSAVE 和 BGREWRITEAOF 是否正在执行,如果为 -1 表示没有在执行
serverCron 函数执行时会检查这两个属性,如果有一个不为 -1,则程序会执行 wait3 函数,检查子进程是否有信号发来服务器进程:
有信号到达,则新的 RDB 文件生成,或者 AOF 文件重写完成,服务器需要进行新的操作,如新的文件代替旧的文件
没有则持久化未完成,不做动作
如果都为 -1,则服务器没有在持久化,则
- 查看是否有 BGREWRITEAOF 被延迟,有则进行 BGREWRITEAOF 操作
- 检查服务器自动保存条件是否满足,是的情况且服务器没有执行其他持久化操作,则进行 BGSAVE 操作
- 检查 AOF 条件是否满足,是且没有其他持久化操作,则进行 BGREWRITEAOF 操作判断是否持久化
将 AOF 缓冲区中的内容写入 AOF 文件
如果服务器开启了 AOF 持久化功能,并且 AOF 缓冲区里面还有待写入的数据,那么 serverCron 函数会调用相应的程序,将 AOF 缓冲区中的内容写入到 AOF 文件里面
关闭异步客户端 关闭输出缓冲区大小超过限制的客户端
增加 cronloops 计数值 服务器状态的 cronloops 记录了 serverCron 函数执行次数,作用为在复制模块实现每执行 N 次操作执行一次指定代码
struct redisServer {
// ...
// serverCron 函数的运行次数计数器
// serverCron 函数每执行一次,这个属性的值就增一。
int cronloops;
// ...
};
2
3
4
5
6
7
# 9.初始化服务器
int main(int argc, char **argv) {
...
initServerConfig();
...
loadServerConfig(configfile,options);
...
initServer();
...
loadDataFromDisk();
...
InitServerLast();
...
aeMain(server.el);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
redis 服务初始化分为六个阶段:
- ① 初始化服务配置;
- ② 载入配置选项;
- ③ 服务器初始化;
- ④ 还原数据库状态;
- ⑤ 服务器最终初始化;
- ⑥ 启动 event loop
初始化服务器状态结构 第一步是创建一个 struct redisServer 类型的实例变量 server 作为服务器状态,并为结构中的各个属性设置默认值
初始化 server 由 redis.c/initServerConfig 完成,主要工作:
设置运行 ID
设置默认运行频率
设置默认配置文件路径
设置运行架构
设置默认端口号
设置默认 RDB 持久化条件和 AOF 持久化条件
初始化服务器的 LRU 时钟
创建命令表
void initServerConfig(void){
//设置服务器的运行id
getRandomHexChars(server.runid,REDIS_RUN_ID_SIZE);
//为运行id 加上结尾字符
server.runid[REDIS_RUN_ID_SIZE] = '\0';
//设置默认配置文件路径
server.configfile = NULL;
//设置默认服务器频率
server.hz = REDIS_DEFAULT_HZ;
//设置服务器的运行架构
server.arch_bits = (sizeof(long) == 8) ? 64 : 32;
//设置默认服务器端口号
server.port = REDIS_SERVERPORT;
// ...
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
载入配置选项 启动服务器时可以给定配置参数或者指定配置文件来修改服务器的默认配置
在 initServerConfig 函数初始化完成后,就会载入用户给定的参数对 server 变量的属性进行修改
服务器在用 initServerConfig 函数初始化完 server 变量之后,就会开始载入用户给定的配置参数和配置文件,并根据用户设定的配置,对 server 变量相关属性的值进行修改
初始化服务器数据结构(initServer 函数) initServerConfig 函数只创建了命令表,但还有部分数据结构需要创建
server.clients 链表:客户端状态链表,redisClient 结构
server.db 数组:服务器所有数据库
server.pubsub_channels 字典:保存频道订阅信息
server.subpub_patterns 链表:保存模式订阅信息
server.lua:保存 Lua 脚本的环境
server.slowlog:保存慢查询日志
调用 initServer 函数为以上数据结构分配数据,并在有需要时设置默认值或关联初始化值,服务器到这一步才初始化数据结构是因为服务器需要载入用户指定的配置选项才能对数据结构正确初始化,如果在 initServerConfig 就初始化,而用户配置不同的值,导致重新调整和修改
initServer 函数还进行了:
- 为服务器设置进程信号处理器
- 创建共享对象:这些对象包含 Redis 服务器经常用到的一些值,比如包含"OK"回复的字 符串对象,包含"ERR"回复的字符串对象,包含整数 1 到 10000 的字符串对象等等,服务器通 过重用这些共享对象来避免反复创建相同的对象
- 打开服务器的监听端口,并为监听套接字关联连接应答事件处理器,等待服务器正式运 行时接受客户端的连接
- 为 serverCron 函数创建时间事件,等待服务器正式运行时执行 serverCron 函数
- 如果 AOF 持久化功能已经打开,那么打开现有的 AOF 文件,如果 AOF 文件不存在,那么 创建并打开一个新的 AOF 文件,为 AOF 写入做好准备。
- 初始化服务器的后台 I/O 模块(bio),为将来的 I/O 操作做好准备
初始完成则在日志中打印 Redis 图标及相关版本信息
还原数据库状态
- 在完成了对服务器状态 server 变量的初始化之后,服务器需要载入 RDB 文件或者 AOF 文件,并根据文件记录的内容来还原服务器的数据库状态
- 根据服务器是否启用了 AOF 持久化功能,服务器载入数据时所使用的目标文件会有所不同:
- 如果服务器启用了 AOF 持久化功能,那么服务器使用 AOF 文件来还原数据库状态
- 相反地,如果服务器没有启用 AOF 持久化功能,那么服务器使用 RDB 文件来还原数据库状态
- 当服务器完成数据库状态还原工作之后,服务器将在日志中打印出载入文件并还原数据库状态所耗费的时长
执行事件循环
在初始化的最后一步,服务器将打印出以下日志,并开始执行服务器的事件循环(loop)
# 10.INFO 命令
在 Redis 中,可以使用INFO命令获取 Redis 服务器的信息,其中包含了关于内存使用情况的信息,包括总内存和已用内存。
如果你想获取剩余可用空间,可以执行以下步骤:
- 连接到 Redis 服务器,可以使用命令行工具如
redis-cli或者连接到相应的客户端库。 - 发送
INFO命令,获取 Redis 服务器的信息。 - 解析返回的信息,找到
used_memory和total_system_memory字段的值。 - 计算剩余可用空间:
剩余可用空间 = total_system_memory - used_memory
> info
# Server
redis_version:6.0.5
redis_git_sha1:00000000
redis_git_dirty:0
redis_build_id:a738add6a60618b1
redis_mode:standalone
os:Linux 3.10.0-1062.9.1.el7.x86_64 x86_64
arch_bits:64
multiplexing_api:epoll
atomicvar_api:atomic-builtin
gcc_version:9.3.1
process_id:17891
run_id:d49c0ef6541980e2d4d7f2d2c3e076c3068b7f94
tcp_port:6379
uptime_in_seconds:46203535
uptime_in_days:534
hz:10
configured_hz:10
lru_clock:13308257
executable:/opt/redis-6.0.5/src/redis-server
config_file:/opt/redis-6.0.5/conf/redis_master1.conf
# Clients
connected_clients:21
client_recent_max_input_buffer:2
client_recent_max_output_buffer:0
blocked_clients:0
tracking_clients:0
clients_in_timeout_table:0
# Memory
used_memory:13063748056
used_memory_human:12.17G
used_memory_rss:12348461056
used_memory_rss_human:11.50G
used_memory_peak:32643801104
used_memory_peak_human:30.40G
used_memory_peak_perc:40.02%
used_memory_overhead:5105632
used_memory_startup:837968
used_memory_dataset:13058642424
used_memory_dataset_perc:99.97%
allocator_allocated:13064219616
allocator_active:13163974656
allocator_resident:13246275584
total_system_memory:33565130752
total_system_memory_human:31.26G
used_memory_lua:44032
used_memory_lua_human:43.00K
used_memory_scripts:496
used_memory_scripts_human:496B
number_of_cached_scripts:2
maxmemory:0
maxmemory_human:0B
maxmemory_policy:noeviction
allocator_frag_ratio:1.01
allocator_frag_bytes:99755040
allocator_rss_ratio:1.01
allocator_rss_bytes:82300928
rss_overhead_ratio:0.93
rss_overhead_bytes:-897814528
mem_fragmentation_ratio:0.95
mem_fragmentation_bytes:-715285440
mem_not_counted_for_evict:3684
mem_replication_backlog:1048576
mem_clients_slaves:16986
mem_clients_normal:356706
mem_aof_buffer:3684
mem_allocator:jemalloc-5.1.0
active_defrag_running:0
lazyfree_pending_objects:0
# Persistence
loading:0
rdb_changes_since_last_save:1051114
rdb_bgsave_in_progress:0
rdb_last_save_time:1681976405
rdb_last_bgsave_status:ok
rdb_last_bgsave_time_sec:39
rdb_current_bgsave_time_sec:-1
rdb_last_cow_size:14303232
aof_enabled:1
aof_rewrite_in_progress:0
aof_rewrite_scheduled:0
aof_last_rewrite_time_sec:76
aof_current_rewrite_time_sec:-1
aof_last_bgrewrite_status:ok
aof_last_write_status:ok
aof_last_cow_size:24842240
module_fork_in_progress:0
module_fork_last_cow_size:0
aof_current_size:5990757043
aof_base_size:4694756389
aof_pending_rewrite:0
aof_buffer_length:0
aof_rewrite_buffer_length:0
aof_pending_bio_fsync:0
aof_delayed_fsync:0
# Stats
total_connections_received:2231654
total_commands_processed:311568905
instantaneous_ops_per_sec:7
total_net_input_bytes:350127507381
total_net_output_bytes:1309328211017
instantaneous_input_kbps:0.44
instantaneous_output_kbps:1.07
rejected_connections:0
sync_full:4
sync_partial_ok:1
sync_partial_err:0
expired_keys:379541
expired_stale_perc:0.00
expired_time_cap_reached_count:0
expire_cycle_cpu_milliseconds:8109435
evicted_keys:0
keyspace_hits:3956424
keyspace_misses:1228732
pubsub_channels:1
pubsub_patterns:0
latest_fork_usec:530062
migrate_cached_sockets:0
slave_expires_tracked_keys:0
active_defrag_hits:0
active_defrag_misses:0
active_defrag_key_hits:0
active_defrag_key_misses:0
tracking_total_keys:0
tracking_total_items:0
tracking_total_prefixes:0
unexpected_error_replies:0
# Replication
role:master
connected_slaves:1
slave0:ip=10.250.14.xxx,port=6379,state=online,offset=332902416254,lag=0
master_replid:11c48f5e7bffd88cdbf8c7e2ca49e9ab49e17239
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:332902416396
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:332901367821
repl_backlog_histlen:1048576
# CPU
used_cpu_sys:105911.273165
used_cpu_user:135566.577203
used_cpu_sys_children:680.205620
used_cpu_user_children:4969.491196
# Modules
module:name=graph,ver=20200,api=1,filters=0,usedby=[],using=[],options=[]
# Cluster
cluster_enabled:0
# Keyspace
db0:keys=19514,expires=19514,avg_ttl=1850504861406
db2:keys=125,expires=125,avg_ttl=399010423
db3:keys=4628,expires=4628,avg_ttl=5148277550792
db8:keys=9,expires=9,avg_ttl=1654111426310600
db10:keys=1106,expires=1106,avg_ttl=341835600
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
# 11.服务端总结
一个命令请求从发送到完成主要包括以下步骤:
客户端将命令请求发送给服务器;
服务器读取命令请求,并分析出命令参数;
命令执行器根据参数查找命令的实现函数,然后执行实现函数并得出命令回复;
服务器将命令回复返回给客户端。
serverCron函数默认每隔100 毫秒执行一次,它的工作主要包括更新服务器状态信息,处理服务器接收的SIGTERM信号,管理客户端资源和数据库状态,检查并执行持久化操作等等。服务器从启动到能够处理客户端的命令请求需要执行以下步骤:
- 初始化服务器状态;
- 载入服务器配置;
- 初始化服务器数据结构;
- 还原数据库状态;
- 执行事件循环。
# 四.Redis 事务
# 1.事务 ACID
事务的 ACID 性质
- 在传统的关系式数据库中,常常用 ACID 性质来检验事务功能的可靠性和安全性
- 在 Redis 中,事务总是具有以下的特性:
- 原子性(Atomicity)
- 一致性(Consistency)
- 隔离性 (Isolation)
- 耐久性 (Durability)
# 2.redis 事务的持久性
事务的耐久性指的是,当一个事务执行完毕时,执行这个事务所得的结果已经被保存到永久性存储介质(比如硬盘)里面了,即使服务器在事务执行完毕之后停机,执行事务所得的结果也不会丢失.
因为 Redis 的事务不过是简单地用队列包裹起了一组 Redis 命令,Redis 并没有为事务提供任何额外的持久化功能,所以 Redis 事务的耐久性由 Redis 所使用的持久化模式决定:
- **当服务器在无持久化的内存模式下运作时,事务不具有耐久性:**一旦服务器停机,包括 事务数据在内的所有服务器数据都将丢失
- 当服务器在 RDB 持久化模式下运作时,服务器只会在特定的保存条件被满足时,才会执行 BGSAVE 命令,对数据库进行保存操作,并且异步执行的 BGSAVE 不能保证事务数据被第 一时间保存到硬盘里面,因此 RDB 持久化模式下的事务也不具有耐久性。
- 当服务器运行在 AOF 持久化模式下,并且 appendfsync 选项的值为 always 时,程序总会 在执行命令之后调用同步(sync)函数,将命令数据真正地保存到硬盘里面,因此这种配置 下的事务是具有耐久性的
- 当服务器运行在 AOF 持久化模式下,并且 appendfsync 选项的值为 everysec 时,程序会 每秒同步一次命令数据到硬盘。因为停机可能会恰好发生在等待同步的那一秒钟之内,这可 能会造成事务数据丢失,所以这种配置下的事务不具有耐久性
- 当服务器运行在 AOF 持久化模式下,并且 appendfsync 选项的值为 no 时,程序会交由操作系统来决定何时将命令数据同步到硬盘。因为事务数据可能在等待同步的过程中丢失,所 以这种配置下的事务不具有耐久性
# 3.说说 redis 事务
Redis 通过 MULTI、EXEC、WATCH 等命令来实现事务(transaction)功能。
multi:开始事务;exec:提交事务;discard:取消事务;watch:监视某个 key;unwatch:取消监视某个 key。
事务的特性
- 事务提供了一种将多个命令请求打包,然后一次性、按顺序地执行多个命令的机制
- 并且在事务执行期间,服务器不会中断事务而改去执行其他客户端的命令请求,它会将事务中的所有命令都执行完毕,然后才去处理其他客户端的命令请求。
- redis 事务不支持回滚机制
- 单机模式默认是关闭事务的
- 事务是一个单独的隔离操作:事务中的所有命令都会序列化、按顺序地执行。事务在执行的过程中,不会被其他客户端发送来的命令请求所打断。
一个事务执行的过程,该事务首先以一个 MULT|命令为开始,接着将多个命令放入事务当中,最后由 EXEC 命令将这个事务提交(commit) 给服务器执行.
# 4.事务的错误处理
事务的错误处理:
- 如果事务中的命令是在执行期间出现了错误,事务的后续命令也会继续执行下去,并且之前执行的命令也不会有任何影响
- 事务因为命令入队出错而被服务器拒绝执行,事务中的所有命令都不会被执行
- 事务是一个原子操作:事务中的命令要么全部被执行,要么全部都不执行。执行和是否成功是 2 个概念,并不是一个失败报错等,其他就失败。redis 对事务是部分支持。如果最开始语法等就有提交错误,就相当于 java 的编译器都过不了,那么肯定全部不执行。如果在执行过程中报错,已经全部执行了,但是谁报错找谁,其他正常执行放行。各取所需!这里的事务并不是要么全部成功,要么全部失败,全部执行和全部成功(或者都失败)是 2 个概念
- 在事务执行的过程中,出错的命令会被服务器识别出来,并进行相应的错误处理, 所以这些出错命令不会对数据库做任何修改,也不会对事务的一致性产生任何影响
# 5.事务的实现过程
事务实现步骤:
- 事务开始
- 命令入队
- 事务执行
事务的开始
MULTI 命令可以将执行该命令的客户端从非事务状态切换至事务状态,这一切换是通过在客户端状态的 flags 属性中打开 REDIS_MULTI 标识来完成的
命令入队
- 当一个客户端处于非事务状态时,这个客户端发送的命令会立即被服务器执行
- 当一个客户端切换到事务状态之后,服务器会根据这个客户端发来的不 同命令执行不同的操作:
- 如果客户端发送的命令为 EXEC、DISCARD、WATCH、MULTI 四个命令的其中一个, 那么服务器立即执行这个命令
- 与此相反,如果客户端发送的命令是 EXEC、DISCARD、WATCH、MULTI 四个命令以外的其他命令,那么服务器并不立即执行这个命令,而是将这个命令放入一个事务队列里面,然后向客户端返回 QUEUED 回复
每个 Redis 客户端都有自己的事务状态,这个事务状态保存在客户端状态的 mstate 属性里面:
typedef struct redisClient {
// ...
//事务状态
multiState mstate; /* MULTI/EXEC state */
// ...
} redisClient;
2
3
4
5
6
7
8
事务状态包含一个事务队列,以及一个已入队命令的计数器(也可以说是事务队列的长度)
typedef struct multiState {
//事务队列,FIFO 顺序
multiCmd *commands;
//已入队命令计数
int count;
} multiState;
2
3
4
5
6
7
事务队列是一个 multiCmd 类型的数组,数组中的每个 multiCmd 结构都保存了一个已入队命令的相关信息,包括指向命令实现函数的指针、命令的参数,以及参数的数量
typedef struct multiCmd {
//参数
robj **argv;
//参数数量
int argc;
//命令指针
struct redisCommand *cmd;
} multiCmd;
2
3
4
5
6
7
8
9
10
事务队列以先进先出(FIFO)的方式保存入队的命令,较先入队的命令会被放到数组的 前面,而较后入队的命令则会被放到数组的后面
事务执行
当一个处于事务状态的客户端向服务器发送 EXEC 命令时,这个 EXEC 命令将立即被服务器执行。服务器会遍历这个客户端的事务队列,执行队列中保存的所有命令,最后将执行命 令所得的结果全部返回给客户端
# 6.事务中命令校验
如果客户端发送的命令为
EXEC、DISCARD、WATCH、MULTIL四个命令的其中一个,那么服务器立即执行这个命令。如果客户端发送的命令是
EXEC、DISCARD、WATCH、MULTI四个命令以外的其他命令,那么服务器并不立即执行这个命令,而是将这个命令放入一个事务队列里面,然后向客户端返回QUEUED回复。
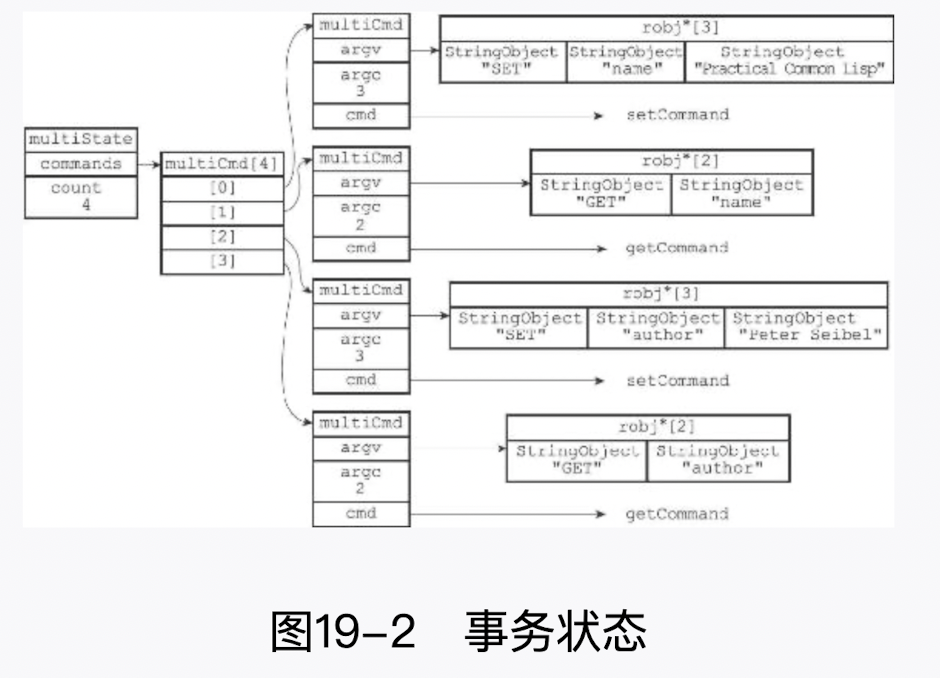
# 7.Multi 和 Pipleline 区别?
Redis 中的 Multi 和 Pipleline 都可以一次性执行多个命令,
Pipeline 只是把多个 redis 指令一起发出去,redis 并没有保证这些指令执行的顺序,且减少了多次网络传递的开销,因而其执行效率很高;
Multi 相当于一个 redis 的 transaction,保证整个操作的有序性,通过 watch 这些 key,可以避免这些 key 在事务的执行过程中被其它的命令修改,从而导致得的到结果不是所期望的。
redis 管道命令
redis-cli --pipe 可以大量插入数据,也可以从文件中批量插入数据。对于我们要手动为系统缓存一些数据到 Redis 时,可以通过数据库进行查询,查询后通过管道来进行导入
[root@VM_0_4_centos ~]# cat cmd.txt | redis-cli --pipe
All data transferred. Waiting for the last reply...
Last reply received from server.
errors: 0, replies: 5
2
3
4
# 8.watch 命令的实现
WATCH 命令是一个乐观锁(optimistic locking)
功能: EXEC 命令执行之前,监视任意数量的数据库键,并在 EXEC 命令执行时,检查被监视的键是否至少有一个已经被修改过了,如果是的话,服务器将拒绝执行事务,并向客户端返回代表事务执行失败的空回复。
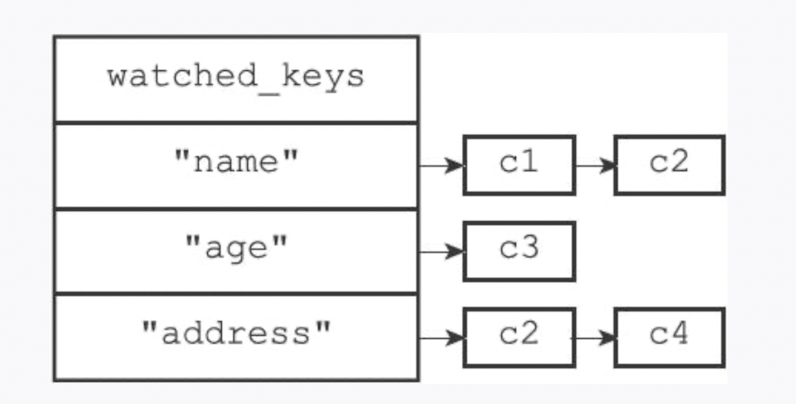
每个 Redis 数据库都保存着一个 watched_keys 字典
- 字典的键是某个被
WATCH命令监视的数据库键 - 字典的值则是一个链表,链表中记录了所有监视相应数据库键的客户端
typedef struct redisDb {
// ...
//正在被WATCH 命令监视的键
dict *watched_keys;
// ...
} redisDb;
2
3
4
5
6
监视机制的触发
所有对数据库进行修改的命令,比如 SET、LPUSH、SADD、ZREM、DEL、FLUSHDB 等等,在执行之后都会调用 multi.c/touchWatchKey 函数对 watched_keys 字典进行检查,查看是否有客户端正在监视刚刚被命令修改过的数据库键,如果有的话,那么 touchWatchKey 函数会将监视被修改键的客户端的REDIS_DIRTY_CAS标识打开,表示该客户端的事务安全性已经被破坏。
判断事务是否安全
当服务器接收到一个客户端发来的 EXEC 命令时,服务器会根据这个客户端是否打开了 REDIS_DIRTY_CAS 标识来决定是否执行事务:
- 如果客户端的
REDIS_DIRTY_CAS标识已经被打开,那么说明客户端所监视的键当中,至少有一个键已经被修改过了,在这种情况下,客户端提交的事务已经不再安全,所以服务器会拒绝执行客户端提交的事务。 - 如果客户端的
REDIS_DIRTY_CAS标识没有被打开,那么说明客户端监视的所有键都没有被修改过(或者客户端没有监视任何键),事务仍然是安全的,服务器将执行客户端提交的这个事务。
# 五.扩展模块
# 1.处理经纬坐标
通过 geo 相关的 redis 命令计算坐标之间的距离
| 命令 | 描述 |
|---|---|
geoadd | 添加一个或多个地理空间位置到 sorted set |
geohash | 返回指定地理空间位置的 GeoHash 字符串。 |
geopos | 返回指定地理空间位置的经纬度。 |
geodist | 返回两个地理空间位置之间的距离。 |
georadius | 查询指定半径内所有的地理空间元素的集合。 |
georadiusbymember | 查询指定半径内与给定地理空间元素匹配的元素。 |
场景:
- 计算两点之间的距离
- 附近的人/餐厅/机构
这些命令用于在 Redis 中处理地理空间信息,可以用于实现场景,比如寻找附近的人、餐厅、机构等。通过使用这些命令,您可以有效地管理地理位置数据,并执行各种有趣的查询和分析操作。
# 2.数据库通知
键空间通知:“某个键执行了什么命令”的通知称为键空间通知(key-space notification)键事件通知:键事件通知(key-event notification)关注的是“某个命令被什么键执行了”
notify-keyspace-events 是 Redis 的一个配置选项,用于启用或禁用键空间通知(keyspace notifications)。键空间通知允许 Redis 在某些事件发生时发送消息通知客户端或者执行订阅操作。这对于实现实时监控、缓存失效通知、数据同步等功能非常有用。
该选项可以设置为一个字符串,表示您希望在哪些事件发生时发送通知。以下是一些可能的事件和对应的标识符:
K:键空间通知,指示某个键空间中的键被修改(比如设置新值、删除等操作)。E:事件通知,指示 Redis 服务器发生了某些重要的事件(如客户端连接、断开等)。g:一般性命令通知,指示通用命令执行。x:过期事件通知,指示某个键过期被删除。s:数据结构事件通知,指示数据结构(如集合、有序集合等)被修改。
# 3.发布与订阅
Redis 的发布与订阅功能由 PUBLISH、SUBSCRIBE、PSUBSCRIBE 等命令组成。通过执行 SUBSCRIBE 命令,客户端可以订阅一个或多个频道,从而成为这些频道的订阅者(subscriber):每当有其他客户端向被订阅的频道发送消息(message) 时,频道的所有订阅者都会收到这条消息。
客户端执行命令,订阅频道
SUBSCRIBE "news.it"
客户端执行命令,向频道发消息
PUBLISH "news.it" "hello'
- PSUBSCRIBE 订阅多个频道
- 注意频道匹配模式
- UNSUBSCRIBE 频道退订
发布到频道
- 当一个客户端执行 PUBLISH 命令的时候,会将消息 message 发送给频道 channel
- PUBLISH 命令执行完之后,服务器需要执行以下两个动作:
- 将消息 message 发送给 channel 频道的所有订阅者
- 如果有一个或多个模式 pattern 与频道 channel 相匹配,那么将消息 message 发送给 pattern 模式的订阅者
订阅频道实现
Redis 将所有频道的订阅关系都保存在服务器状态的 pubsub_channels 字 典里面,这个字典的键是某个被订阅的频道,而键的值则是一个链表,链表里面记录了所有订阅这个频道的客户端:
struct redisServer {
// ...
//保存所有频道的订阅关系
dict *pubsub_channels;
// ...
};
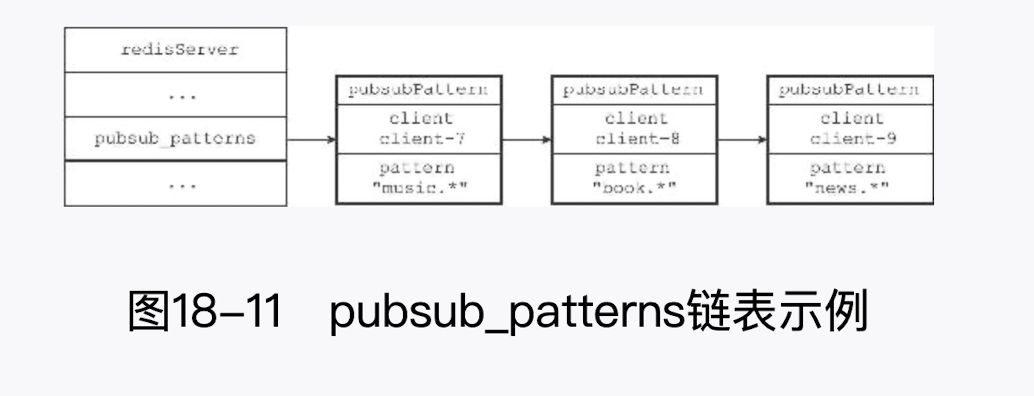
typedef struct pubsubPattern {
//订阅模式的客户端
redisClient *client;
//被订阅的模式
robj *pattern;
} pubsubPattern;
2
3
4
5
6
7
8
9
10
11
12
13
14
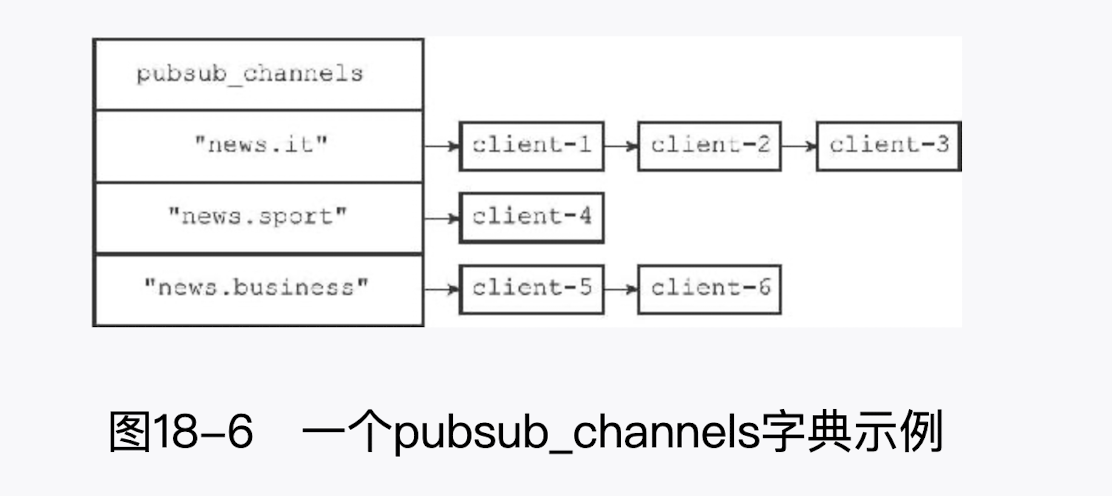
模式的订阅实现
前面说过,服务器将所有频道的订阅关系都保存在服务器状态的 pubsub_channels 属性里面,与此类似,服务器也将所有模式的订阅关系都保存在服务器状态的 pubsub_channels 属 性里面:
# 4.查看订阅信息
PUBSUB CHANNELS
PUBSUB CHANNELS [pattern]子命令用于返回服务器当前被订阅的频道,其中 pattern 参 数是可选的:
- 如果不给定 pattern 参数,那么命令返回服务器当前被订阅的所有频道。
- 如果给定 pattern 参数,那么命令返回服务器当前被订阅的频道中那些与模式相匹配的频道
PUBSUB NUMSUB
PUBSUB NUMSUB [channel-1 channel-2...channel-n]子命令接受任意多个频道作为输入参数,并返回这些频道的订阅者数量。这个子命令是通过在 pubsub_channels 字典 中找到频道对应的订阅者链表,然后返回订阅者链表的长度来实现的(订 阅者链表的长度就是频道订阅者的数量),
PUBSUB NUMPAT
PUBSUB NUMPAT 子命令用于返回服务器当前被订阅模式的数量。这个子命令是通过返回 pubsub_patterns 链表的长度来实现的,因为这个链表的长度就是服务器被订阅模式的数量
# 5.lua 脚本
先说下使用 Lua 脚本的好处:
减少网络开销:可以将多个请求通过脚本的形式一次发送,减少网络时延。原子操:redis 会将整个脚本作为一个整体执行,中间不会被其他命令插入。因此在编写脚本的过程中无需担心会出现竞态条件,无需使用事务。复用:客户端发送的脚本会永久存在 redis 中,这样,其他客户端可以复用这一脚本而不需要使用代码完成相同的逻辑。
Redis 从 2.6 版本开始引入对 Lua 脚本的支持,通过在服务器中嵌入 Lua 环境,Redis 客户端可以使用 Lua 脚本,直接在服务器端原子地执行多个 Redis 命令。
redis> EVAL "return 'hello world'"
"hello world"
2
而使用 EVALSHA 命令则可以根据脚本的 SHA1 校验和来对脚本进行求值,但这个命令要求校验和对应的脚本必须至少被 EVAL 命令执行过一次.
# 6.创建并修改 lua 环境
Redis 服务器创建并修改 Lua 环境的整个过程由以下步骤组成:
- 创建一个基础的 L ua 环境,之后的所有修改都是针对这个环境进行的。
- 载入多个函数库到 Lua 环境里面,让 Lua 脚本可以使用这些函数库来进行数据操作。
- 创建全局表格 redis,这个表格包含了对 Redis 进行操作的函数,比如用于在 L ua 脚本中执行 Redis 命令的 redis.call 函数。
- 使用 Redis 自制的随机函数来替换 L ua 原有的带有副作用的随机函数,从而避免在脚本中引入副作用。
- 创建排序辅助函数,Lua 环境使用这个辅佐函数来对一部分 Redis 命令的结果进行排序,从而消除这些命令的不确定性。
- 创建 redis.pcall 函数的错误报告辅助函数,这个函数可以提供更详细的出错信息。
- 对 L ua 环境中的全局环境进行保护,防止用户在执行 Lua 脚本的过程中,将额外的全局变量添加到 L ua 环境中。
- 将完成修改的 Lua 环境保存到服务器状态的 Iua 属性中,等待执行服务器传来的 Lua 脚本。
lua 脚本通信步骤:
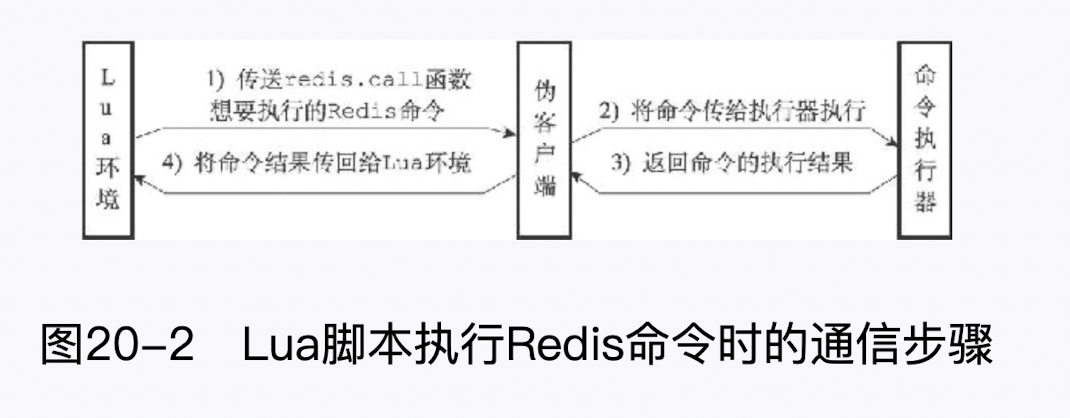
# 7.EVAL 命令的实现
EVAL 命令的执行过程可以分为以下三个步骤:
- 根据客户端给定的
Lua脚本,在Lua环境中定义一个Lua函数。 - 将客户端给定的脚本保存到
lua_scripts字典,等待将来进一步使用。 - 执行刚刚在
Lua环境中定义的函数,以此来执行客户端给定的Lua脚本。
Lua 环境协作组件
- 除了创建并修改 Lua 环境之外,Redis 服务器还创建了两个用于与 Lua 环境进行协作的组件,它们分别是:
- 负责执行 Lua 脚本中的 Redis 命令的伪客户端
- 用于保存 Lua 脚本的lua_scripts 字典
lua_scripts 字典
除了伪客户端之外,Redis 服务器为 Lua 环境创建的另一个协作组件是 lua_scripts 字典:
- 字典的键为某个 Lua 脚本的 SHA1 校验和(checksum)
- 字典的值则是 SHA1 校验和对应 的 Lua 脚本
struct redisServer {
// ...
dict *lua_scripts;
// ...
};
2
3
4
5
- Redis 服务器会将所有被 EVAL 命令执行过的 Lua 脚本,以及所有被 SCRIPT LOAD 命令载入过的Lua 脚本都保存到 lua_scripts 字典里面
- **lua_scripts 字典有两个作用:**一个是实现 SCRIPT EXISTS 命令,另一个是实现脚本复制功能
# 8.redis 排序
Redis 的 SORT 命令可以对列表键、集合键或者有序集合键的值进行排序,转换的思想,行转列.
redis> SORT key
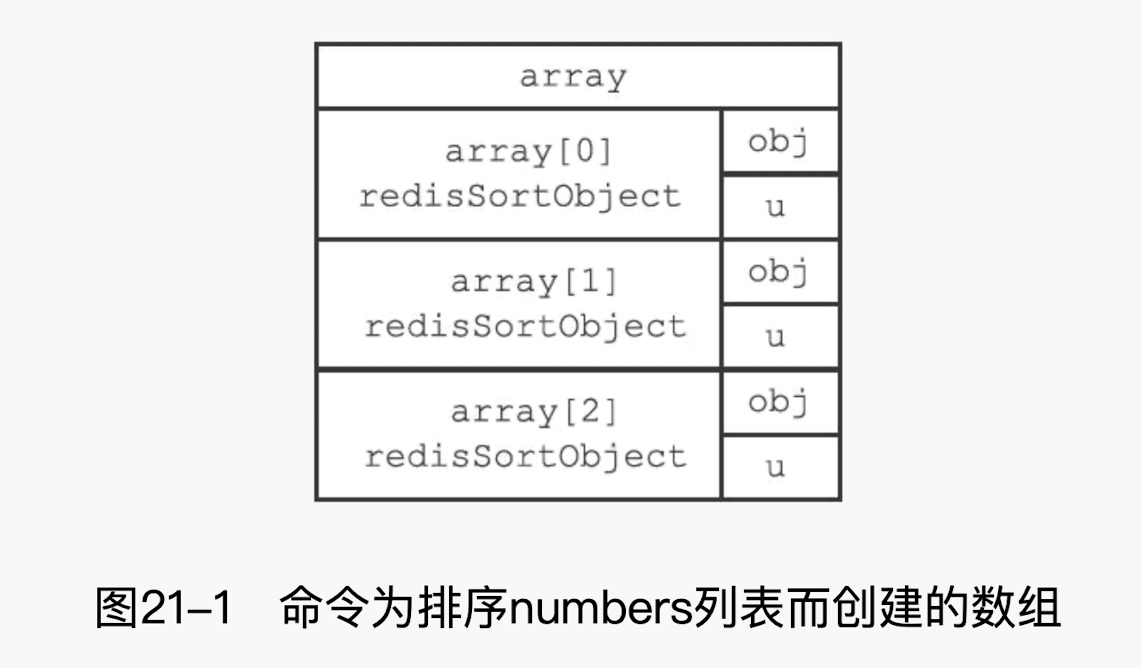
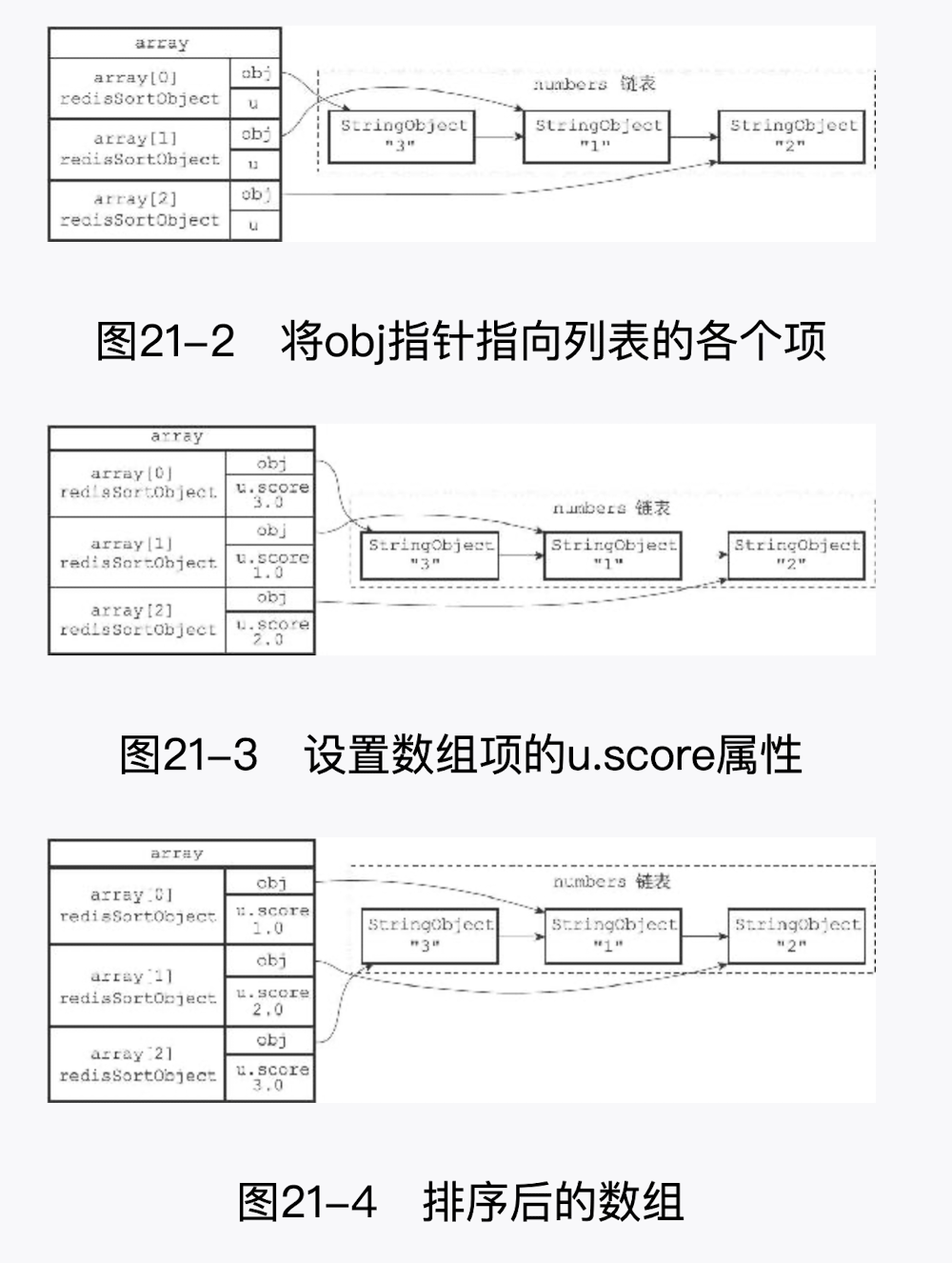
实现原理
- 创建一个和 numbers 列表长度相同的数组,该数组的每个项都是一个 redis.h/redisSortObject 结构,如图 21-1 所示。
- 遍历数组,将各个数组项的 obj 指针分别指向 numbers 列表的各个项,构成 obj 指针和列表项之间的一对一关系,如图 21- -2 所示。
- 遍历数组,将各个 obj 指针所指向的列表项转换成一个 double 类型的浮点数,并将这个浮点数保存在相应数组项的 u.score 属性里面,如图 21- 3 所示。
- 根据数组项 u.score 属性的值,对数组进行数字值排序,排序后的数组项按 u.score 属性的值从小到大排列,如图 21- -4 所示。
- 遍历数组,将各个数组项的 obj 指针所指向的列表项作为排序结果返回给客户端,程序首先访问数组的索引 0,返回 u.score 值为 1.0 的列表项"1";然后访问数组的索引 1,返回 u.score 值为 2.0 的列表项"2";最后访问数组的索引 2,返回 u.score 值为 3.0 的列表 项"3"。
typedef struct _redisSortObject {
//被排序键的值
robj *obj;
//权重
union {
//排序数字值时使用
double score;
//排序带有BY 选项的字符串值时使用
robj *cmpobj;
} u;
} redisSortObject;
2
3
4
5
6
7
8
9
10
11
12
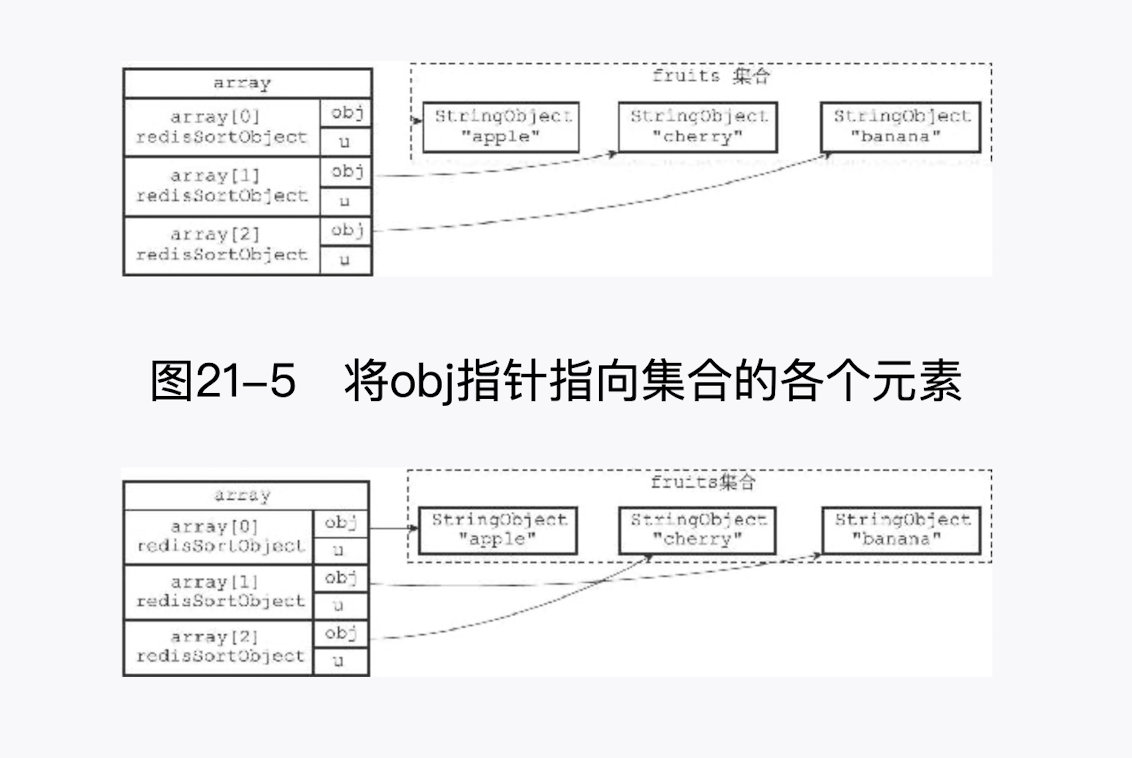
# 9.ALPHA 选项的实现
通过使用 ALPHA 选项,SORT 命令可以对包含字符串值的键进行排序:
SORT <key> ALPHA
# 10.BY 选项的实现
在默认情况下,SORT 命令使用被排序键包含的元素作为排序的权重,元素本身决定了元素在排序之后所处的位置。例如,排序 fruits 集合所使用的权重就是"apple"、"banana" 、"cherry"三个元素本身:
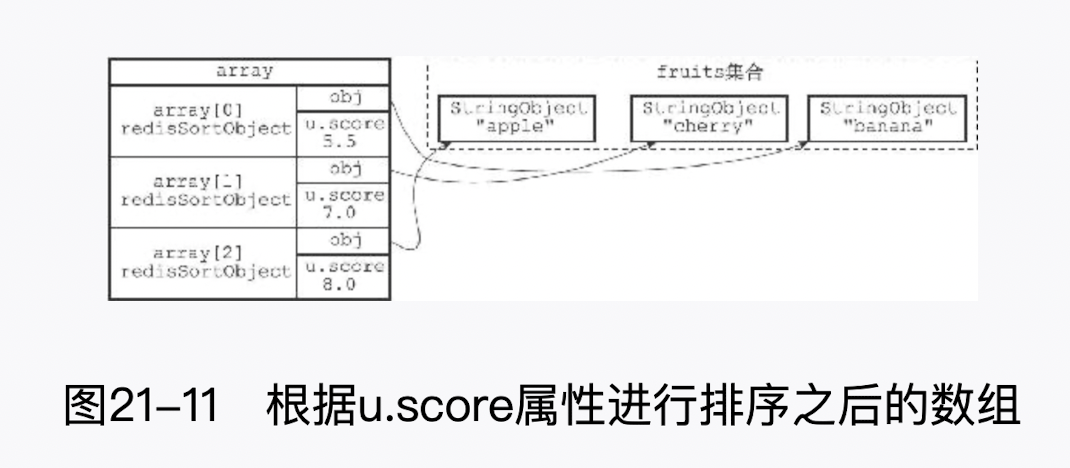
另一方面,通过使用 BY 选项,SORT 命令可以指定某些字符串键,或者某个哈希键所包含的某些域(fheld) 来作为元素的权重,对一个键进行排序。 例如,以下这个例子就使用苹果、香蕉、樱桃三种水果的价钱,对集合键 fruits 进行了排序:
redis> MSET apple- -price 8 banana-price 5.5 cherry-price 7
OK
redis> SORT fruits BY *-price
1) "banana"
2) "cherry"
3) "apple"
2
3
4
5
6
# 11.二进制位数组
Redis 提供了 SETBIT、GETBIT、 BITCOUNT、BITOP 四个命令用于处理二进制位数组(bit array,又称“位数组”)
SETBIT命令 用于为位数组指定偏移量上的二进制位设置值,位数组的偏移量从 0 开始计数,而二进制位的值则可以是 0 或者 1.GETBIT命令则用于获取位数组指定偏移量.上的二进制位的值.BITCOUNT命令用于统计位数组里面,值为 1 的二进制位的数量.BITOP命令既可以对多个位数组进行按位与(and)按位或(or) 、按位异或(xor) 运算.
备注重点
- buf 数组保存二进制位与我们平时表示的二进制为顺序是相反的
- 例如我们的 buf 数组第 1 字节表示的二进制为 10110010,实质上其表示的是 01001101
- 使用逆序来保存位数组可以简化 SETBIT 命令的实现
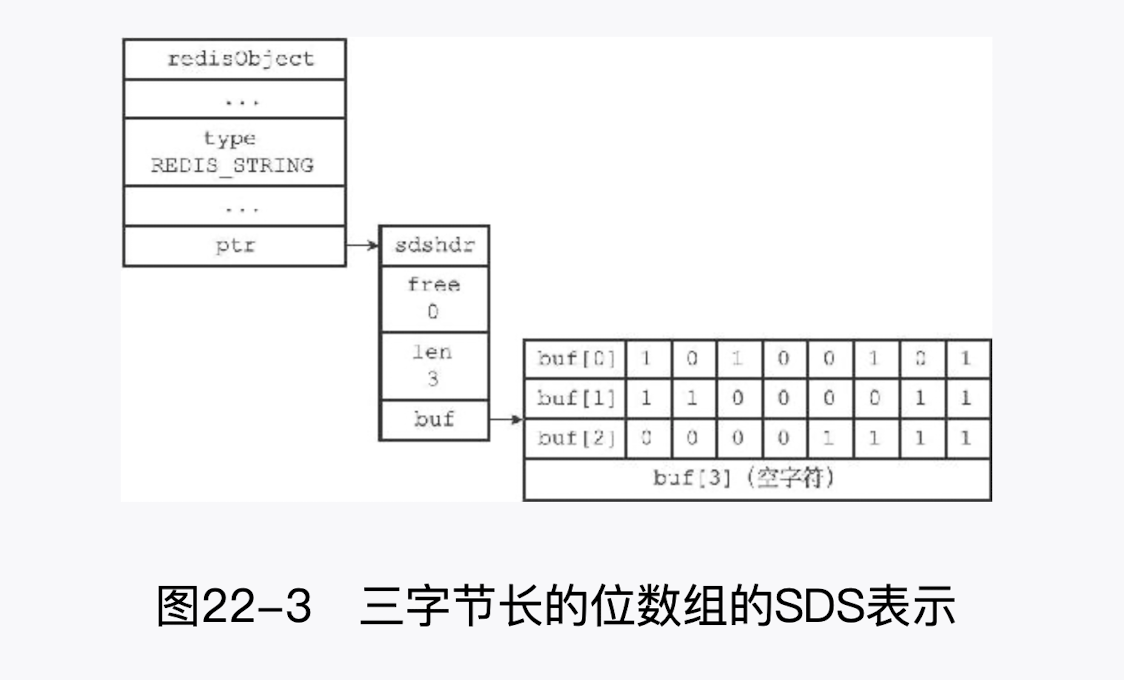
# 12.GETBIT 的实现
- 计算 byte= loffset/8」 ,byte 值记录了 offset 偏移量指定的 1 二进制位保存在位数组的哪个字节。
- 计算 bit= (offset mod 8) +1, bit 值记录了 offset 偏移量指定的二进制位是 byte 字节的第几个二进制位。
- 根据 byte 值和 bit 值,在位数组 bitarray 中定位 offset 偏移量指定的二进制位,并返回这个位的值。
# 13.SETBIT 的实现
- 计算 len= offset/8 +1,len 值记录了保存 offset 偏移量指定的二进制位至少需要多少字节。
- 检查 bitarray 键 保存的位数组(也即是 SDS)的长度是否小于 len,如果是的话,将 SDS 的长度扩展为 len 字节,并将所有新扩展空间的二进制位的值设置为 0。
- 计算 byte= offset/8 ,byte 值 记录了 offset 偏移量指定的二进制位保存在位数组的哪个字节。
- 计算 bit= (offset mod 8) +1, bit 值记录了 offset 偏移量指定的二进制位是 byte 字节的第几个二进制位。
- 根据 byte 值和 bit 值, 在 bitarray 键保存的位数组中定位 offset 偏移量指定的二进制位,首先将指定二进制位现在值保存在 oldvalue 变量,然后将新值 value 设置为这个二进制位的值。
- 向客户端返回 oldvalue 变量的值。
# 14.BITCOUNT 的实现
计算汉明距离
- 遍历算法
- 查表算法
- variable-precision SWAR
- Redis 的实现(查表和 SWAR 结合,二进制位数量 128 位)
以下是调用 swar (bitarray) 的执行步骤:
- 步骤 1 计算出的值 i 的二进制表示可以按每两个二进制位为一-组进行分组,各组的十进制表示就是该组的汉明重量。
- 步骤 2 计算出的值 i 的二进制表示可以按每四个二进制位为一组进行分组,各组的十进制表示就是该组的汉明重量。
- 步骤 3 计算出的值 i 的二进制表示可以按每八个二进制位为一-组进行分组,各组的十进制表示就是该组的汉明重量。
- 步骤 4 的 i*0x01010101 语句计算出 bitarray 的汉明重量并记录在二_进制位的最高八位,而>>24 语句则通过右移运算,将 bitarray 的汉明重量移动到最低八位,得出的结果就是 bitarray 的汉明重量。
uint32_t swar(uint32_t i) {
//步骤1
i = (i & 0x55555555) + ((i >> 1) & 0x55555555);
//步骤2
i = (i & 0x33333333) + ((i >> 2) & 0x33333333);
//步骤3
i = (i & 0x0F0F0F0F) + ((i >> 4) & 0x0F0F0F0F);
//步骤4
i = (i*(0x01010101) >> 24);
return i;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
总结
- swar 函数每次执行可以计算 32 个二进制位的汉明重量,它比之前介绍的遍历算法要快 32 倍,比键长为 8 位的查表法快 4 倍,比键长为 16 位的查表法快 2 倍,并且因为 swar 函数是单纯 的计算操作,所以它无须像查表法那样,使用额外的内存
- 另外,因为 swar 函数是一个常数复杂度的操作,所以我们可以按照自己的需要,在一次循环中多次执行 swar,从而按倍数提升计算汉明重量的效率:
- 例如,如果我们在一次循环中调用两次 swar 函数,那么计算汉明重量的效率就从之前的 一次循环计算 32 位提升到了一次循环计算 64 位
- 又例如,如果我们在一次循环中调用四次 swar 函数,那么一次循环就可以计算 128 个二 进制位的汉明重量,这比每次循环只调用一次 swar 函数要快四倍!
- 当然,在一个循环里执行多个 swar 调用这种优化方式是有极限的:一旦循环中处理的位数组的大小超过了缓存的大小,这种优化的效果就会降低并最终消失
# 15.慢查询日志
Redis 的慢查询日志功能用于记录执行时间超过给定时长的命令请求,用户可以通过这个功能产生的日志来监视和优化查询速度。服务器配置有两个和慢查询日志相关的选项:
- slowlog-log-slower-than选项指定执行时间超过多少微秒(1 秒等于 1 000 000 微秒)的命令请求会被记录到日志上。
- 如果这个选项的值为 100,那么执行时间超过 100 微秒的命令就会被记录到慢查询日志;
- 如果这个选项的值为 500,那么执行时间超过 500 微秒的命令就会被记录到慢查询日志。
- slowlog-max-len 选项指定服务器最多保存多少条慢查询日志。服务器使用先进先出的方式保存多条慢查询日志,当服务器存储的慢查询日志数量等于 slowlog-max-len 选项的值时,服务器在添加一条新的慢查询日志之前,会先将最旧一条慢查询日志删除。
一般情况下,我们都是通过客户端连接 Redis 服务器,然后发送命令给 Redis 服务器,Redis 服务器会把每个客户端发来的命令缓存入一个队列,然后逐个进行执行,最后再把结果返回给客户端。而我们这里的慢查询指的就是“执行命令”的那部分。而非网络 I/O 或者 命令排队的问题。
命令
- **SLOWLOG GET:**用来查看服务器所保存的慢查询日志
- **SLOWLOG RESET:**用于清空所有慢查询日志
- **SLOWLOG LEN:**查询慢查询日志的数量
#获取慢查询日志
slowlog get
#清除慢查询日志
slowlog reset
2
3
4
5
慢查询日志的保存
struct redisServer {
// ...
//下一条慢查询日志的ID
long long slowlog_entry_id;
//保存了所有慢查询日志的链表
list *slowlog;
//服务器配置slowlog-log-slower-than 选项的值
long long slowlog_log_slower_than;
//服务器配置slowlog-max-len 选项的值
unsigned long slowlog_max_len;
// ...
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
- slowlog_entry_id 属性:的初始值为 0,每当创建一条新的慢查询日志时,这个属性的值就 会用作新日志的 id 值,之后程序会对这个属性的值增一
- 例如,在创建第一条慢查询日志时,slowlog_entry_id 的值 0 会成为第一条慢查询日志的 ID,而之后服务器会对这个属性的值增一;当服务器再创建新的慢查询日志的时候, slowlog_entry_id 的值 1 就会成为第二条慢查询日志的 ID,然后服务器再次对这个属性的值增 一,以此类推
- slowlog 链表:保存了服务器中的所有慢查询日志,链表中的每个节点都保存了一个 slowlogEntry 结构,每个 slowlogEntry 结构代表一条慢查询日志
typedef struct slowlogEntry {
//唯一标识符
long long id;
//命令执行时的时间,格式为UNIX 时间戳
time_t time;
//执行命令消耗的时间,以微秒为单位
long long duration;
//命令与命令参数
robj **argv;
//命令与命令参数的数量
int argc;
} slowlogEntry;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 16.监视器
通过执行 MONITOR 命令,客户端可以将自己变为一个监视器,实时地接收并打印出服务器当前处理的命令请求的相关信息:
每当一个客户端向服务器发送一条命令请求时,服务器除了会处理这条命令请求之外, 还会将关于这条命令请求的信息发送给所有监视器
redis> MONITOR
OK
2
def MONITOR():
# 打开客户端的监视器标志
client.flags |= REDIS_MONITOR
# 将客户端添加到服务器状态的monitors 链表的末尾
server.monitors.append(client)
# 向客户端返回OK
send_reply("OK")
2
3
4
5
6
7
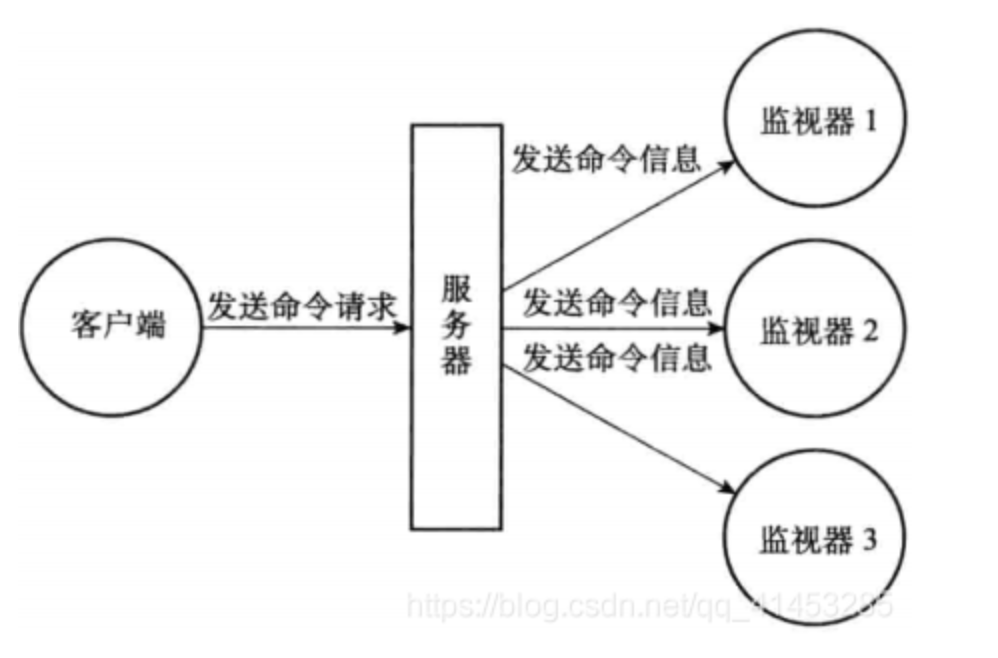
# 17.redis 的优化
Redis 是一个纯内存的 KV 数据库,对于内存使用做了相当多的优化,比如:
- 为了对键值对做优化,很多类型底层都有两种实现方案,比如 List 和 Hash 在数据量较少时,采用 ziplist 和 zipmap 实现,内存使用效率更高,当数据量增大时,为了查询效率,才转化为 quicklist 和 dict。
- 在内存分配中,Redis 放弃了 glibc 中的 tcmalloc,采用 jemalloc,大大减少了内存碎片率。
- 当数据库所占内存超过配置的阈值时,为了保护系统,Redis 会采用对应的规则淘汰 KV 对,淘汰策略有很多,包括 LRU、LFU 等算法,这部分在 evict.c 中。
- Redis 支持对 key 设置过期时间,当 key 过期时,会采用相应策略删除 KV 对,这部分在 expire.c 中。
同时 Redis 是个单线程数据库,意味着包括读取解析客户端命令、处理命令、回复响应、大部分后台任务都要在一个线程中完成,这就要求任何步骤都不能造成长时间的阻塞,由此造成了 Redis 独有的一些处理方式:
- 当数据库需要扩容时,会逐步 rehash,这部分在 dict.h/c 中
- 部分后台任务会在单独的线程中处理,例如:删除 key、关闭文件、fsync 文件,这部分在 bio.h/c 和 lazyfree.c 中。
- 每个模块都需要一些周期性任务,这些任务在 server.c 中实现,同时根据执行频率确定每个任务的执行间隔,有些任务还会严格的限制执行时间
# 六.常见问题
# 1.Redis 的全称是什么?
Redis 全称:Remote Dictionary Server 远程字典服务
# 2.集群脑裂
Redis 主从集群切换数据丢失问题如何应对
- 异步复制同步丢失
- 集群产生脑裂数据丢失
对于 Redis 主节点与从节点之间的数据复制,是异步复制的,当客户端发送写请求给 master 节点的时候,客户端会返回 OK,然后同步到各个 slave 节点中。如果此时 master 还没来得及同步给 slave 节点时发生宕机,那么 master 内存中的数据会丢失;要是 master 中开启持久化设置数据可不可以保证不丢失呢?答案是否定的。在 master 发生宕机后,sentinel 集群检测到 master 发生故障,重新选举新的 master,如果旧的 master 在故障恢复后重启,那么此时它需要同步新 master 的数据,此时新的 master 的数据是空的(假设这段时间中没有数据写入)。那么旧 master 中的数据就会被刷新掉,此时数据还是会丢失。
首先我们需要理解集群的脑裂现象,这就好比一个人有两个大脑,那么到底受谁来控制呢?在分布式集群中,分布式协作框架 zookeeper 很好的解决了这个问题,通过控制半数以上的机器来解决。那么在 Redis 中,集群脑裂产生数据丢失的现象是怎么样的呢?
假设我们有一个 redis 集群,正常情况下 client 会向 master 发送请求,然后同步到 salve,sentinel 集群监控着集群,在集群发生故障时进行自动故障转移。此时,由于某种原因,比如网络原因,集群出现了分区,master 与 slave 节点之间断开了联系,sentinel 监控到一段时间没有联系认为 master 故障,然后重新选举,将 slave 切换为新的 master。但是 master 可能并没有发生故障,只是网络产生分区,此时 client 任然在旧的 master 上写数据,而新的 master 中没有数据,如果不及时发现问题进行处理可能旧的 master 中堆积大量数据。在发现问题之后,旧的 master 降为 slave 同步新的 master 数据,那么之前的数据被刷新掉,大量数据丢失。
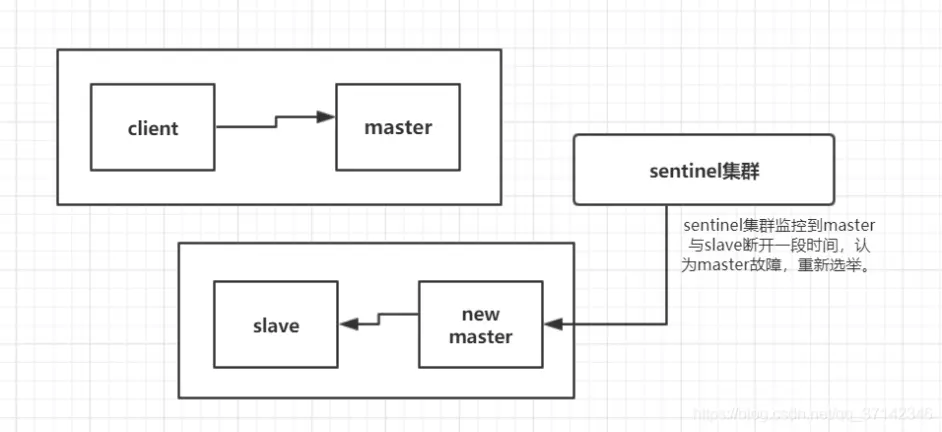
在了解了上面的两种数据丢失场景后,我们如何保证数据可以不丢失呢?在分布式系统中,衡量一个系统的可用性,我们一般情况下会说 4 个 9,5 个 9 的系统达到了高可用(99.99%,99.999%,据说淘宝是 5 个 9)。对于 redis 集群,我们不可能保证数据完全不丢失,只能做到使得尽量少的数据丢失。
在 redis 的配置文件中有两个参数我们可以设置:
min-slaves-to-write 1
min-slaves-max-lag 10
#默认情况下是 0
min-slaves-to-write 0
#默认情况下是 10
min-slaves-max-lag 10
2
3
4
5
6
7
min-slaves-to-write 1表示:表示至少有 1 个 salve 与 master 的同步复制延迟不能超过 10s
min-slaves-max-lag 10表示: salve 与 master 的同步复制延迟不能超过 10s
一旦不满足上述配置的要求,那么此时 master 就不会接受任何请求。
我们可以减小 min-slaves-max-lag 参数的值,这样就可以避免在发生故障时大量的数据丢失,一旦发现延迟超过了该值就不会往 master 中写入数据。
那么对于 client,我们可以采取降级措施,将数据暂时写入本地缓存和磁盘中,在一段时间后重新写入 master 来保证数据不丢失;也可以将数据写入 kafka 消息队列,隔一段时间去消费 kafka 中的数据。
通过上面两个参数的设置我们尽可能的减少数据的丢失,具体的值还需要在特定的环境下进行测试设置。
# 3.性能问题排查与优化
从资源使用角度来看,包含的知识点如下:
- CPU 相关:使用复杂度过高命令、数据的持久化,都与耗费过多的 CPU 资源有关
- 内存相关:bigkey 内存的申请和释放、数据过期、数据淘汰、碎片整理、内存大页、内存写时复制都与内存息息相关
- 磁盘相关:数据持久化、AOF 刷盘策略,也会受到磁盘的影响
- 网络相关:短连接、实例流量过载、网络流量过载,也会降低 Redis 性能
- 计算机系统:CPU 结构、内存分配,都属于最基础的计算机系统知识
- 操作系统:写时复制、内存大页、Swap、CPU 绑定,都属于操作系统层面的知识
# 4.如何无阻塞找 key
假如 Redis 里面有 1 亿个 key,其中有 10w 个 key 是以某个固定的已知的前缀开头的,如何将它们全部找出来?
使用 keys 指令可以扫出指定模式的 key 列表。但是要注意 keys 指令会导致线程阻塞一段时间,线上服务会停顿,直到指令执行完毕,服务才能恢复。这个时候可以使用 scan 指令,scan 指令可以无阻塞的提取出指定模式的 key 列表,但是会有一定的重复概率,在客户端做一次去重就可以了,但是整体所花费的时间会比直接用 keys 指令长。
# 5.Template 区别
RedisTemplate 和 StringRedisTemplate 的区别
使用 RedisTemplate 和 StringRedisTemplate 之所以有所差异,**是因为 StringRedisTemplate 在对 Key 和 Value 进行序列化时,都使用字符串的方式进行序列化。**因此,我们选择 StringRedisTemplate 会方便一些。
- 两者的关系是 StringRedisTemplate 继承 RedisTemplate。
- 两者的数据是不共通的;也就是说 StringRedisTemplate 只能管理 StringRedisTemplate 里面的数据,RedisTemplate 只能管理 RedisTemplate 中的数据。
- SDR(Spring Data Redis) 默认采用的序列化策略有两种,一种是 String 的序列化策略,一种是 JDK 的序列化策略。
- StringRedisTemplate 默认采用的是 String 的序列化策略,保存的 key 和 value 都是采用此策略序列化保存的。
- RedisTemplate 默认采用的是 JDK 的序列化策略,保存的 key 和 value 都是采用此策略序列化保存的。
# 6.RESP 协议
为了满足Redis高性能的要求,Redis特地设计了RESP(全称REdis Serialization Protocol)协议,用来作为Redis客户端与服务端的通讯协议,RESP协议有以下优点实现简单,解析高效,可读性好
注意:RESP底层用的连接方式还是TCP,RESP只定义了客户端与服务端的数据交互格式
RESP 协议的特点包括:
- 简单性: RESP 是一种相对简单的文本协议,易于理解和实现。
- 可读性: RESP 消息以文本形式表示,对于调试和分析来说很方便。
- 紧凑性: RESP 消息使用最小的字节数来表示数据,减少了网络传输开销。
- 可扩展性: RESP 支持多种数据类型(例如字符串、整数、数组、错误消息等),因此可以用于多种不同类型的数据。
- 高效性: RESP 协议的设计使得它在序列化和反序列化数据时非常高效,适用于高性能的数据交换场景。
RESP 协议的一些常见数据类型包括:
- 简单字符串(Simple Strings),第一个字节为
+ - 错误消息(Errors),第一个字节为
- - 整数(Integers),第一个字节为
: - 块字符串(Bulk Strings),第一个字节为
$ - 数组(Arrays),第一个字节为
*
每种数据类型都有特定的表示方式,例如:
#简单字符串:以 "+" 开头
+OK\r\n
#错误消息:以 "-" 开头
-ERR unknown command 'foobar'\r\n
#整数:以 ":" 开头
:123\r\n
#块字符串:以 "$" 开头,后跟字符串长度和字符串内容
$6\r\nfoobar\r\n
#数组:以 "*" 开头,后跟数组长度和数组内容
*2\r\n$3\r\nfoo\r\n$3\r\nbar\r\n
2
3
4
5
6
7
8
9
10
11
12
13
14
# 7.NoSQL 介绍
NoSQL 是指非关系型数据库 ,非关系型数据库和关系型数据库两者存在许多显著的不同点,其中最重要的是 NoSQL 不使用 SQL 作为查询语言。其数据存储可以不需要固定的表格模式,一般都有水平可扩展性的特征。
NoSQL 主要有如下几种不同的分类:
key/value 键值存储。这种数据存储通常都是无数据结构的, 一般被当作字符串或者二进制数据,但是数据加载速度快,典型的使用场景是处理高并发或者用于日志系统等,这一类的数据库有Redis等。列存储数据库。列存储数据库功能相对局限,但是查找速度快,容易进行分布式扩展,一般用于分布式文件系统中,这一类的数据库有HBase、clickhouse等。文档型数据库和 key/value 键值存储类似,文档型数据库也没有严格的数据格式,这既是缺点也是是优势,因为不需要预先创建表结构,数据格式更加灵活,一般可用在 We 应用中,这一类数据库有MongoDB等。图形数据库。图形数据库专注于构建关系图谱,例如社交网络,推荐系统等,这一类的数据库有Neo4J等。
# 8.什么是 redlock?
多个服务间保证同一时刻同一时间段内同一用户只能有一个请求(防止关键业务出现并发攻击)
- 防止了 单节点故障造成整个服务停止运行的情况;
- 在多节点中锁的设计,及多节点同时崩溃等各种意外情况有自己独特的设计方法
- 使用 redession 实现分布锁的过程
Redlock 是一个用于分布式系统中实现分布式锁的算法。它的设计目标是在多个 Redis 节点之间实现高可用的分布式锁,以确保在分布式环境中对共享资源的访问是有序的。
Redlock 算法是由 Redis 的作者 Salvatore Sanfilippo 在 Redis 官方文档中提出的,但是需要注意的是,Redlock 并不是官方支持的 Redis 功能,而是一种基于 Redis 的分布式锁方案。
Redlock 的核心思想是通过在多个 Redis 节点上创建相同名称的分布式锁来实现。在获取锁时,客户端会尝试在多个节点上同时获取锁,并采用一定的策略来判断是否成功获取锁。这样可以增加锁的可靠性和可用性,即使部分节点不可用或者出现网络问题,仍然可以保持锁的正确性。
然而,需要注意的是 Redlock 也存在一些争议和问题。在实际使用中,有一些情况下可能会导致竞态条件或者死锁的问题。因此,一些专家建议在考虑使用 Redlock 时要慎重,确保了解其特点和限制,并在具体应用场景中进行适当的测试和评估。
如果您正在考虑在分布式系统中使用分布式锁,可以考虑使用 Redis 的官方支持的分布式锁实现(如使用 SETNX 命令),或者结合其他分布式锁算法来满足您的需求。
# 9.一批 key 过期,影响读写?
当一批 key 瞬间过期时,Redis 需要进行以下操作:
过期键的删除:Redis 需要遍历这批过期的 key 并删除它们。这个删除操作可能会占用一定的 CPU 资源和时间,特别是当过期的 key 数量较大时。
内存回收:过期键的删除会释放相应的内存空间,但这些内存并不会立即被操作系统回收,而是由 Redis 内部的内存管理机制来处理。这涉及到内存页的管理和回收,可能导致额外的内存操作和资源消耗。
单线程操作:Redis 是单线程的,意味着它在任意时刻只能执行一个操作。当大量 key 过期需要删除时,这些删除操作可能会占据 Redis 的执行时间,导致其他操作(如读写操作)被阻塞。
以上这些因素可能导致其他 key 的读写效率降低,因为 Redis 在处理过期键和资源回收时会消耗一定的计算资源和时间,从而影响到对其他 key 的操作。为了减轻这种影响,可以考虑以下几点:
合理设置过期时间: 避免一次性大量 key 同时过期,尽量将过期时间分散开,避免在某一短时间内触发大量过期操作。
使用惰性删除: Redis 使用惰性删除(lazy expiration)策略,即在访问 key 时检查是否过期,而不是主动清理过期 key。这可以减轻过期键一次性过多删除的负担。
考虑使用Redis集群: Redis 集群可以将负载分散到多个节点上,减轻单一节点的压力,提高整体性能。
合理规划内存: 为 Redis 分配足够的内存,避免内存不足导致频繁的内存回收操作。
优化业务逻辑: 在设计业务逻辑时,考虑如何降低对 Redis 的高频读写操作,以减少对其性能的影响。
# 10.单机 redis 最大存储量?
Redis 的最大存储能力取决于多个因素,包括硬件资源、操作系统、Redis 版本以及实际存储数据的大小等。然而,一般来说,Redis 的最大存储能力可以达到数百万到数千万个键值对。
以下是一些影响 Redis 最大存储能力的因素:
可用内存: Redis 将所有数据存储在内存中,因此可用的系统内存是限制 Redis 存储容量的关键因素。你可以通过在 Redis 配置文件中设置 maxmemory 参数来限制 Redis 使用的最大内存量。
数据大小: 单个键值对的大小也会影响 Redis 的存储能力。如果你的数据集中有大量的大键值对,那么存储的总数可能会较少。
操作系统限制: 操作系统对单个进程的内存使用和文件句柄数等也会有限制。不同操作系统和配置可能会影响 Redis 的最大存储能力。
数据结构选择: 不同的数据结构(例如字符串、哈希、列表、集合、有序集合等)在内存中的存储方式不同,也会影响 Redis 的存储能力。
使用的Redis版本: Redis 在不同版本之间可能会对性能和内存管理进行改进,因此使用较新版本可能会具有更好的存储能力。
# 11.缓存一致性?
三个经典的缓存模式:缓存可以提升性能、缓解数据库压力,但是使用缓存也会导致数据不一致性的问题。
有三种经典的缓存模式:
- Cache-Aside Pattern 旁路缓存模式
- Read-Through/Write through 读写穿透
- Write behind 异步缓存写入
# 12.旁路缓存模式
Cache-Aside Pattern:
读流程
- 读的时候,先读缓存,缓存命中的话,直接返回数据
- 缓存没有命中的话,就去读数据库,从数据库取出数据,放入缓存后,同时返回响应。
写流程
更新的时候,先更新数据库,然后再删除缓存。
# 13.读写穿透
Read-Through/Write-Through(读写穿透):
Read/Write Through模式中,服务端把缓存作为主要数据存储。应用程序跟数据库缓存交互,都是通过抽象缓存层完成的。
- 从缓存读取数据,读到直接返回
- 如果读取不到的话,从数据库加载,写入缓存后,再返回响应。
Write-Through模式下,当发生写请求时,也是由缓存抽象层完成数据源和缓存数据的更新
# 14.异步缓存写入
Write behind (异步缓存写入):
Write behind跟Read-Through/Write-Through有相似的地方,都是由Cache Provider来负责缓存和数据库的读写。它两又有个很大的不同:Read/Write Through是同步更新缓存和数据的,Write Behind则是只更新缓存,不直接更新数据库,通过批量异步的方式来更新数据库。
这种方式下,缓存和数据库的一致性不强,对一致性要求高的系统要谨慎使用。但是它适合频繁写的场景,MySQL 的InnoDB Buffer Pool 机制就使用到这种模式。
# 15.缓存一致性方案
延迟双删:
- 先删除缓存
- 再更新数据库
- 休眠一会(比如 1 秒),再次删除缓存。
这个休眠时间 = 读业务逻辑数据的耗时 + 几百毫秒。 为了确保读请求结束,写请求可以删除读请求可能带来的缓存脏数据。
删除缓存重试机制:
不管是延时双删还是Cache-Aside 的先操作数据库再删除缓存,如果第二步的删除缓存失败呢,删除失败会导致脏数据哦~
删除失败就多删除几次呀,保证删除缓存成功呀~ 所以可以引入删除缓存重试机制
读取 biglog 异步删除缓存:
重试删除缓存机制还可以,就是会造成好多业务代码入侵。其实,还可以通过数据库的 binlog 来异步淘汰 key。