# 一.Nacos
# 1.注册中心原理
服务注册的策略的是每 5 秒向 nacos server发送一次心跳,心跳带上了服务名,服务 ip,服务端口等信息。同时 nacos server 也会向 client 主动发起健康检查,支持 tcp/http 检查。如果 15 秒内无心跳且健康检查失败则认为实例不健康,如果 30 秒内健康检查失败则剔除实例。
# 2.配置自动刷新的原理?
LongPollingRunnable:如果 md5 值不一样,则发送数据变更通知,调用 safeNotifyListener 方法。
所以我们知道了这个 run 方法里面创建了一个 Runnable 方法,并放入线程池中,每隔 29.5s 执行一次,如果无变更,就正常返回,如果有变更(md5 比较不相同),则调用 sendResponse(changedGroups);方法响应客户端。
# 3.注册的原理?
注册的逻辑主要在 NacosNamingService 实现类,registerInstance 是注册实例.具体实现在 NamingHttpClientProxy
public class NacosNamingService implements NamingService {
@Override
public void registerInstance(String serviceName, String groupName, String ip, int port, String clusterName)
throws NacosException {
Instance instance = new Instance();
instance.setIp(ip);
instance.setPort(port);
instance.setWeight(1.0);
instance.setClusterName(clusterName);
registerInstance(serviceName, groupName, instance);
}
}
2
3
4
5
6
7
8
9
10
11
12
//NamingHttpClientProxy#deregisterService,里面有对实例的增删改查
@Override
public void deregisterService(String serviceName, String groupName, Instance instance) throws NacosException {
NAMING_LOGGER
.info("[DEREGISTER-SERVICE] {} deregistering service {} with instance: {}", namespaceId, serviceName,
instance);
if (instance.isEphemeral()) {
return;
}
final Map<String, String> params = new HashMap<>(16);
params.put(CommonParams.NAMESPACE_ID, namespaceId);
params.put(CommonParams.SERVICE_NAME, NamingUtils.getGroupedName(serviceName, groupName));
params.put(CommonParams.CLUSTER_NAME, instance.getClusterName());
params.put(IP_PARAM, instance.getIp());
params.put(PORT_PARAM, String.valueOf(instance.getPort()));
params.put(EPHEMERAL_PARAM, String.valueOf(instance.isEphemeral()));
reqApi(UtilAndComs.nacosUrlInstance, params, HttpMethod.DELETE);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
public class ServiceManager {
private static final ServiceManager INSTANCE = new ServiceManager();
private final ConcurrentHashMap<Service, Service> singletonRepository;
private final ConcurrentHashMap<String, Set<Service>> namespaceSingletonMaps;
}
2
3
4
5
# 4.防止读写冲突?
在更新实例列表时,会采用 CopyOnWrite 技术,首先将旧的实例列表拷贝一份,然后更新拷贝的实例列表,再用更新后的实例列表来覆盖旧的实例列表。这样在更新的过程中,就不会对读实例列表的请求产生影响,也不会出现脏读问题了。
使用 CopyOnWrite 技术,主要是因为在获取实例列表的场景下,属于读多写少的场景,在读的时候不加锁,写的时候加锁,消耗一点性能,但是最大限度的提高了读的效率,也就是常说的空间换时间,这个时间指的是读取实例的时间。
Nacos 内部接收到注册请求时,不会立即写数据,而是将服务注册的任务放入一个阻塞队列就立即响应给客户端。然后利用线程池读取阻塞队列中的任务,异步来完成实例更新,从而提高并发写能力。
# 5.心跳包的处理
在 InstanceController 类中的 beat 方法实现了心跳包的处理逻辑
@CanDistro
@PutMapping("/beat")
@Secured(action = ActionTypes.WRITE)
public ObjectNode beat(HttpServletRequest request) throws Exception {
ObjectNode result = JacksonUtils.createEmptyJsonNode();
//1.设置默认心跳间隔时间
result.put(SwitchEntry.CLIENT_BEAT_INTERVAL, switchDomain.getClientBeatInterval());
//2.获取心跳包数据
String beat = WebUtils.optional(request, "beat", StringUtils.EMPTY);
RsInfo clientBeat = null;
if (StringUtils.isNotBlank(beat)) {
//3.解析心跳包数据
clientBeat = JacksonUtils.toObj(beat, RsInfo.class);
}
//4.获取集群名称、IP地址、和端口
String clusterName = WebUtils
.optional(request, CommonParams.CLUSTER_NAME, UtilsAndCommons.DEFAULT_CLUSTER_NAME);
String ip = WebUtils.optional(request, "ip", StringUtils.EMPTY);
int port = Integer.parseInt(WebUtils.optional(request, "port", "0"));
if (clientBeat != null) {
if (StringUtils.isNotBlank(clientBeat.getCluster())) {
clusterName = clientBeat.getCluster();
} else {
// fix #2533
clientBeat.setCluster(clusterName);
}
ip = clientBeat.getIp();
port = clientBeat.getPort();
}
//5.获取客户端服务命名空间和服务名称
String namespaceId = WebUtils.optional(request, CommonParams.NAMESPACE_ID, Constants.DEFAULT_NAMESPACE_ID);
String serviceName = WebUtils.required(request, CommonParams.SERVICE_NAME);
//6.检查服务名称规范,不符合要求抛出异常
NamingUtils.checkServiceNameFormat(serviceName);
Loggers.SRV_LOG.debug("[CLIENT-BEAT] full arguments: beat: {}, serviceName: {}, namespaceId: {}", clientBeat,
serviceName, namespaceId);
BeatInfoInstanceBuilder builder = BeatInfoInstanceBuilder.newBuilder();
builder.setRequest(request);
//7.处理心跳包数据
int resultCode = getInstanceOperator()
.handleBeat(namespaceId, serviceName, ip, port, clusterName, clientBeat, builder);
//8.返回处理结果
result.put(CommonParams.CODE, resultCode);
result.put(SwitchEntry.CLIENT_BEAT_INTERVAL,
getInstanceOperator().getHeartBeatInterval(namespaceId, serviceName, ip, port, clusterName));
result.put(SwitchEntry.LIGHT_BEAT_ENABLED, switchDomain.isLightBeatEnabled());
return result;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
# 6.handleBeat
在 InstanceOperatorClientImpl 类中 handleBeat 方法是对心跳包的具体处理流程
public int handleBeat(String namespaceId, String serviceName, String ip, int port, String cluster,
RsInfo clientBeat, BeatInfoInstanceBuilder builder) throws NacosException {
//1.根据服务命名空间和服务名称获取服务实例对象
Service service = getService(namespaceId, serviceName, true);
//2.根据ip和端口号获取客户端ID
String clientId = IpPortBasedClient.getClientId(ip + InternetAddressUtil.IP_PORT_SPLITER + port, true);
//3.查询注册的客户端
IpPortBasedClient client = (IpPortBasedClient) clientManager.getClient(clientId);
//4.如果客户端不存在或者客户端服务实例还未发布,注册客户端实例,否则跳过该操作
if (null == client || !client.getAllPublishedService().contains(service)) {
if (null == clientBeat) {
//4.1心跳包不存在,直接返回不存在的提示码
return NamingResponseCode.RESOURCE_NOT_FOUND;
}
//4.2根据心跳包和服务名称构建Instance实例对象
Instance instance = builder.setBeatInfo(clientBeat).setServiceName(serviceName).build();
//4.3注册Instance实例对象,该方式中存在关于client的实例对象的注册
registerInstance(namespaceId, serviceName, instance);
//4.4再次获取客户端实例
client = (IpPortBasedClient) clientManager.getClient(clientId);
}
//5.验证服务实例对象是否存在,不存在则抛出服务不存在的异常
if (!ServiceManager.getInstance().containSingleton(service)) {
throw new NacosException(NacosException.SERVER_ERROR,
"service not found: " + serviceName + "@" + namespaceId);
}
//6.心跳包不存在,则根据传入参数封装客户端心跳包数据
if (null == clientBeat) {
clientBeat = new RsInfo();
clientBeat.setIp(ip);
clientBeat.setPort(port);
clientBeat.setCluster(cluster);
clientBeat.setServiceName(serviceName);
}
//7.服务健康检查,更新服务的心跳时间,如果服务的健康状态是false,则更新为true,表明服务实例是健康状态
ClientBeatProcessorV2 beatProcessor = new ClientBeatProcessorV2(namespaceId, clientBeat, client);
HealthCheckReactor.scheduleNow(beatProcessor);
//8.更新客户端时间
client.setLastUpdatedTime();
return NamingResponseCode.OK;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
# 7.registerInstance
InstanceOperatorClientImpl 类中的 registerInstance 方法实现了 IpPortBasedClient 客户端和 Instance 服务实例的注册。
public void registerInstance(String namespaceId, String serviceName, Instance instance) throws NacosException {
//1.检查服务实例是否合法
NamingUtils.checkInstanceIsLegal(instance);
//2.获取IpPortBasedClient客户端id
boolean ephemeral = instance.isEphemeral();
String clientId = IpPortBasedClient.getClientId(instance.toInetAddr(), ephemeral);
//3.创建IpPortBasedClient客户端
createIpPortClientIfAbsent(clientId);
//4.获取服务实例
Service service = getService(namespaceId, serviceName, ephemeral);
//5.创建Instance实例
clientOperationService.registerInstance(service, instance, clientId);
}
2
3
4
5
6
7
8
9
10
11
12
13
# 二.Sentinel
# 1.ArrayMetric
Metric 是一个接口,翻译过来就是度量的意思,它里面定义了很多统计数据的方法:
import com.alibaba.csp.sentinel.node.metric.MetricNode;
import com.alibaba.csp.sentinel.slots.statistic.data.MetricBucket;
import com.alibaba.csp.sentinel.slots.statistic.metric.DebugSupport;
public interface Metric extends DebugSupport {
long success();
long maxSuccess();
long exception();
long block();
long pass();
long rt();
long minRt();
List<MetricNode> details();
List<MetricNode> detailsOnCondition(Predicate<Long> var1);
MetricBucket[] windows();
void addException(int var1);
void addBlock(int var1);
void addSuccess(int var1);
void addPass(int var1);
void addRT(long var1);
double getWindowIntervalInSec();
int getSampleCount();
long getWindowPass(long var1);
void addOccupiedPass(int var1);
void addWaiting(long var1, int var3);
long waiting();
long occupiedPass();
long previousWindowBlock();
long previousWindowPass();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
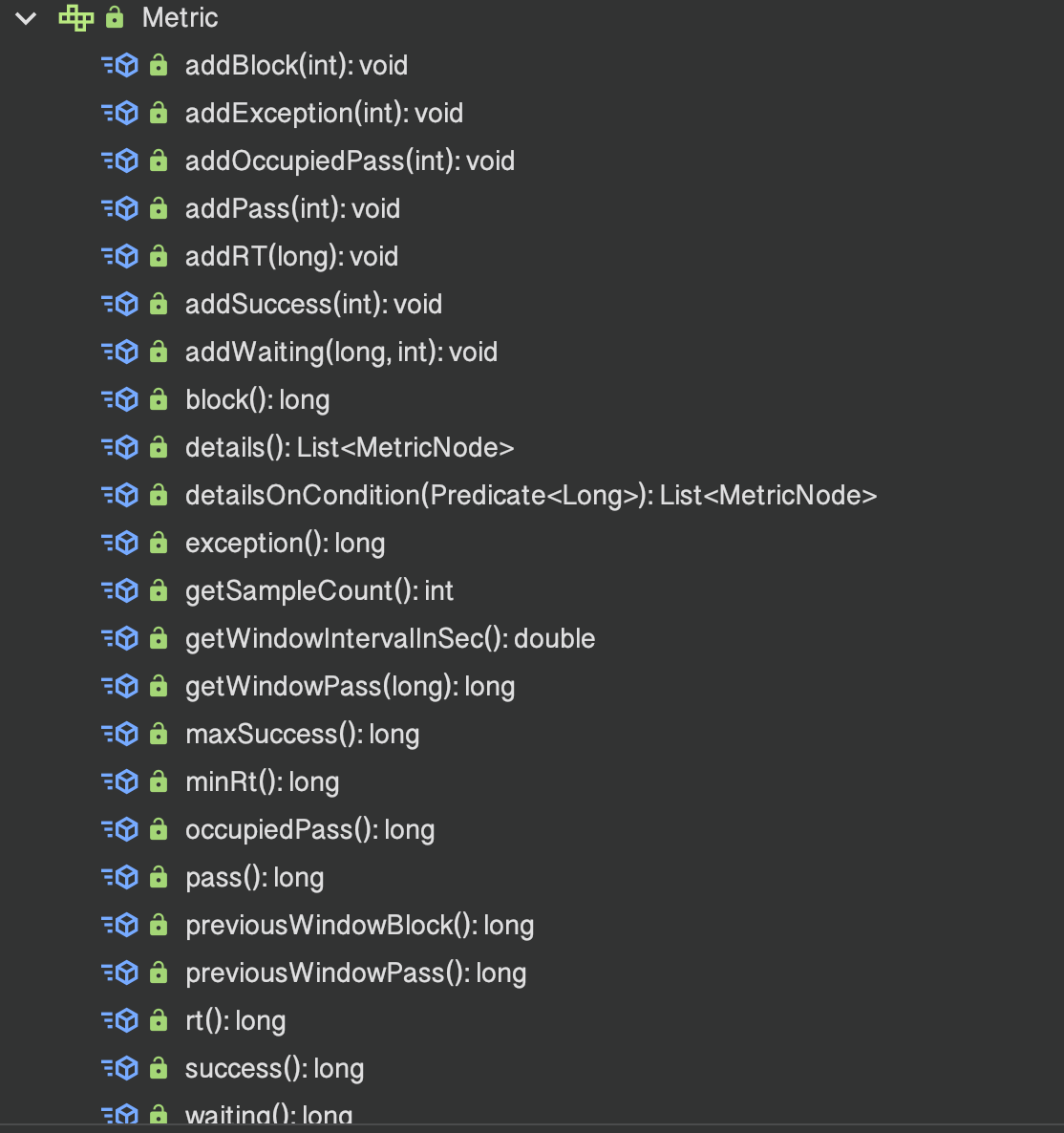
而 ArrayMeric 就是实现了 Metric 接口,它是 sentinel 对资源的 qps 数据统计的最外层 api,封装了对时间窗口数据的操作,比如给当前时间窗口增加成功的请求数,增加异常的请求数,获取时间窗口中所有成功的请求数等等。
# 2.LeapArray
LeapArray实现了整个滑动时间窗口的框架,它抽象了滑动时间窗口的具体实现,它的泛型会由继承的子类去定义,作用是WindowWrap中使用哪种数据统计类型,比如BucketLeapArray就是使用了MetricBucket作为每一个样本窗口的数据存储对象。
LeapArray 的特点包括:
灵活的时间粒度:
LeapArray支持多种时间粒度,比如毫秒、秒、分钟等。这使得你可以根据具体需求来选择合适的粒度进行统计和监控。并发安全性:
LeapArray能够在高并发环境下保持数据的一致性和安全性,适用于大规模的分布式系统。高性能:
LeapArray采用了高效的数据结构和算法,以最小的性能开销来处理流数据,能够在高负载下保持较高的性能。动态窗口大小:
LeapArray允许动态调整窗口的大小,以适应不同的场景和需求。多维度统计:
LeapArray支持在多个维度上进行统计,比如按照接口、应用等维度来分别统计数据。实时查询:
LeapArray支持实时查询,可以快速地获取统计数据,帮助你及时发现问题和趋势。
LeapArray实体类:
//Leap数组使用滑动窗口算法来计数数据
public abstract class LeapArray<T> {
//单个窗口长度
protected int windowLengthInMs;
//一个时间窗中包含的样本窗口数量,数量越多,则每个时间窗口长度越短,这样整个滑动时间窗口算法也越准确
protected int sampleCount;
//时间窗长度,以毫秒为单位
protected int intervalInMs;
//时间窗长度,以秒为单位
private double intervalInSecond;
//这个一个数组,元素为windowwrap样本窗口
//注意,这里的泛型T实际为MetricBucket类型,这一点很关键
protected final AtomicReferenceArray<WindowWrap<T>> array;
/**
* 更新锁仅在不推荐使用当前存储桶时使用
*/
private final ReentrantLock updateLock = new ReentrantLock();
/**
*这个构造方法其实就是计算出来这个窗口长度,创建了窗口数组。
*sentinel默认创建的样本数量就是2,时间窗口大小就是1000ms
*/
public LeapArray(int sampleCount, int intervalInMs) {
AssertUtil.isTrue(sampleCount > 0, "bucket count is invalid: " + sampleCount);
AssertUtil.isTrue(intervalInMs > 0, "total time interval of the sliding window should be positive");
AssertUtil.isTrue(intervalInMs % sampleCount == 0, "time span needs to be evenly divided");
//每个窗口分的时间长度=总时间/窗口个数
this.windowLengthInMs = intervalInMs / sampleCount;
this.intervalInMs = intervalInMs;
this.intervalInSecond = intervalInMs / 1000.0;
this.sampleCount = sampleCount;
this.array = new AtomicReferenceArray<>(sampleCount);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
# 3.BucketLeapArray
LeapArray 是一个抽象类,具体实现如下:
LeapArray (com.alibaba.csp.sentinel.slots.statistic.base)
FutureBucketLeapArray(com.alibaba.csp.sentinel.slots.statistic.metric.occupy)ClusterMetricLeapArray(com.alibaba.csp.sentinel.cluster.flow.statistic.metric)UnaryLeapArray(com.alibaba.csp.sentinel.slots.statistic.base)HotParameterLeapArray(com.alibaba.csp.sentinel.slots.statistic.metric)BucketLeapArray(com.alibaba.csp.sentinel.slots.statistic.metric)OccupiableBucketLeapArray(com.alibaba.csp.sentinel.slots.statistic.metric.occupy)ClusterParameterLeapArray(com.alibaba.csp.sentinel.cluster.flow.statistic.metric)

BucketLeapArray是sentinel使用的默认时间窗口的实现,它指定了使用MetricBucket作为每一个样本窗口存储统计数据的对象。
//BucketLeapArray是最常见的子类
public class BucketLeapArray extends LeapArray<MetricBucket> {
public BucketLeapArray(int sampleCount, int intervalInMs) {
super(sampleCount, intervalInMs);
}
public MetricBucket newEmptyBucket(long time) {
return new MetricBucket();
}
protected WindowWrap<MetricBucket> resetWindowTo(WindowWrap<MetricBucket> w, long startTime) {
//更新窗口起始时间
w.resetTo(startTime);
//将多维度统计数据清零
((MetricBucket)w.value()).reset();
return w;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 4.WindowWrap
样本窗口对象,一个时间窗中可以包含多个样本窗口,样本窗口分得越小,整个时间窗就越准确。在sentinel中LeapArray可以看作就是整合滑动时间窗口,它里面使用了一个array数组存储每一个WindowWrap样本窗口对象,它里面主要包含三个属性,一个是当前样本窗口的长度,一个是样本窗口的起始时间戳,最后一个是这个样本窗口的数据统计对象,它的类型由泛型T去规定,因为LeapArray包含了WindowWrap,所以最终LeapArray的子类会去规定具体的数据统计类型,比如BucketLeapArray使用了MetricBucket作为WindowWrap的数据存储对象。
public class WindowWrap<T> {
//样本窗口长度
private final long windowLengthInMs;
//样本窗口的起始时间戳
private long windowStart;
//当前样本窗口中的统计数据,其类型为MetricBucket,这一点巨关键
private T value;
public WindowWrap(long windowLengthInMs, long windowStart, T value) {
this.windowLengthInMs = windowLengthInMs;
this.windowStart = windowStart;
this.value = value;
}
public long windowLength() {
return this.windowLengthInMs;
}
public long windowStart() {
return this.windowStart;
}
public T value() {
return this.value;
}
public void setValue(T value) {
this.value = value;
}
public WindowWrap<T> resetTo(long startTime) {
this.windowStart = startTime;
return this;
}
public boolean isTimeInWindow(long timeMillis) {
return this.windowStart <= timeMillis && timeMillis < this.windowStart + this.windowLengthInMs;
}
public String toString() {
return "WindowWrap{windowLengthInMs=" + this.windowLengthInMs + ", windowStart=" + this.windowStart + ", value=" + this.value + '}';
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
# 5.MetricBucket
数据统计对象,也就是上面说到的WindowWrap中的泛型对象,当然数据统计对象并不只有MetricBucket,LeapArray的很多子类都有各自的数据统计类型,比如ClusterMetricBukcet,ParamMapBucket。那么MetricBucket是以什么形式去存储不同类型的数据的呢?答案就是通过一个LongAddr数组。
MetricBucket,统计数据的封装类
//MetricBucket,统计数据的封装类
public class MetricBucket {
//统计的数据存放在这里
//这里要统计的数据是多维度的,这些维度类型在MetricEvent枚举中
private final LongAdder[] counters;
private volatile long minRt;
public MetricBucket() {
MetricEvent[] events = MetricEvent.values();
this.counters = new LongAdder[events.length];
MetricEvent[] var2 = events;
int var3 = events.length;
for(int var4 = 0; var4 < var3; ++var4) {
//将时间装入LongAdder中
MetricEvent event = var2[var4];
this.counters[event.ordinal()] = new LongAdder();
}
this.initMinRt();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
数组中的每一个位置都对应着不同类型数据的累计结果,比如我们看请求成功维度的数据:
public long pass() {
return get(MetricEvent.PASS);
}
public long get(MetricEvent event) {
return counters[event.ordinal()].sum();
}
2
3
4
5
6
7
MetricEvent窗口统计的事件,MetricEvent 枚举定义了数据不同的维度,根据枚举的顺序编号去作为数组下标到 LongAddr 数组中找到这个维度的统计数据即可。
//窗口统计的事件
public enum MetricEvent {
PASS,
BLOCK,
EXCEPTION,
SUCCESS,
RT,
OCCUPIED_PASS
}
2
3
4
5
6
7
8
9
# 6.更新样本窗口实现
public WindowWrap<T> currentWindow() {
// 更新当前时间点所在的样本窗口并返回
return currentWindow(TimeUtil.currentTimeMillis());
}
/**
* 根据提供的时间戳去获取到对应的时间窗口
*
* @param timeMillis 以毫秒为单位的有效时间戳(通常都是传当前时间戳)
* @return 如果时间有效则返回对应的时间窗口对象,否则返回null
*/
public WindowWrap<T> currentWindow(long timeMillis) {
if (timeMillis < 0) {
return null;
}
// 计算当前时间所在的样本窗口id,即在计算数组LeapArray中的索引
int idx = calculateTimeIdx(timeMillis);
// 计算当前时间所在区间的开始时间点
long windowStart = calculateWindowStart(timeMillis);
while (true) {
// 获取到当前时间所在的样本窗口
WindowWrap<T> old = array.get(idx);
// 条件成立:说明该样本窗口还不存在,则创建一个,这里主要就是刚开始的时候会进来对样本窗口实例的初始化,后面基本不会进来
if (old == null) {
// 创建一个时间窗
WindowWrap<T> window = new WindowWrap<T>(windowLengthInMs, windowStart, newEmptyBucket(timeMillis));
// 通过CAS方式将新建窗口放入到array
if (array.compareAndSet(idx, null, window)) {
// Successfully updated, return the created bucket.
return window;
} else {
// Contention failed, the thread will yield its time slice to wait for bucket available.
Thread.yield();
}
}
// 条件成立:说明当前样本窗口的起始时间点与计算出的样本窗口起始时间点相同,也就是说此时共用同一个样本窗口即可
else if (windowStart == old.windowStart()) {
return old;
}
// 条件成立:说明当前样本窗口的起始时间点 大于 计算出的样本窗口起始时间点,也就是说计算出的样本窗口已经过时了,此时需要将原来的样本窗口替换
else if (windowStart > old.windowStart()) {
// 加锁进行更新老窗口中过期的统计数据
if (updateLock.tryLock()) {
try {
// 重置老窗口的统计数据
return resetWindowTo(old, windowStart);
} finally {
updateLock.unlock();
}
} else {
// Contention failed, the thread will yield its time slice to wait for bucket available.
Thread.yield();
}
}
// 条件成立:说明当前样本窗口的起始时间点 小于 计算出的样本窗口起始时间点,这种情况一般不会出现,因为时间不会倒流。除非人为修改了系统时钟
else if (windowStart < old.windowStart()) {
// Should not go through here, as the provided time is already behind.
return new WindowWrap<T>(windowLengthInMs, windowStart, newEmptyBucket(timeMillis));
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
这段代码比较长,是实现滑动时间窗口算法的关键,我们这里分为四段进行讲解(下面都以样本窗口数量为 2,样本窗口大小为 500ms 去举例):
timeMillis 传的都是当前时间戳,calculateTimeIdx 方法主要就是计算出当前时间戳应该要占用的样本窗口位置,计算方法也很简单,就是先用当前时间戳除以样本窗口大小,再用得到的结果对样本窗口数量进行取模,比方说当前时间戳是 1200,那么 1200 / 500 = 2,2 % 2 = 0,这样当前时间戳就是要使用 0 号位置的样本窗口实例了 。
//获取当前时间所属的样本窗口位置
private int calculateTimeIdx(/*@Valid*/ long timeMillis) {
// 计算出当前时间在哪个样本窗口
long timeId = timeMillis / windowLengthInMs;
// Calculate current index so we can map the timestamp to the leap array.
return (int) (timeId % array.length());
}
2
3
4
5
6
7
calculateWindowStart 方法主要是用来计算当前时间戳的样本窗口的开始时间,比方说当前时间戳是 1200,那么算出来的开始时间 = 1200 - 1200 % 500 = 1000,以此类推,如果传入的是 1800,那么就是 1500,也就是说算出来的结果是往前最靠近当前时间戳的 500 的倍数。
//计算时间窗口的开始时间,以及计算当前时间所对应的样本窗口开始时间
protected long calculateWindowStart(/*@Valid*/ long timeMillis) {
return timeMillis - timeMillis % windowLengthInMs;
}
2
3
4
这个分支是给 array 数组中初始化样本窗口实例的,一般都是在程序一开始运行的时候会走到这里,一开始 array 数组中都是空的,根据我们上面算出来的样本窗口位置,以及样本窗口的开始位置去创建出样本窗口实例,然后通过 cas 去放到 array 中,如果 cas 失败的线程则通过 yield 方法去释放 cpu 时间片,等待抢占到 cpu 时间片的时候再进来 while 循环
//如果样本窗口还未初始化,则进行样本窗口实例的初始化
if (old == null) {
// 创建一个时间窗
WindowWrap<T> window = new WindowWrap<T>(windowLengthInMs, windowStart, newEmptyBucket(timeMillis));
// 通过CAS方式将新建窗口放入到array
if (array.compareAndSet(idx, null, window)) {
// Successfully updated, return the created bucket.
return window;
} else {
// Contention failed, the thread will yield its time slice to wait for bucket available.
Thread.yield();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
如果样本窗口并未过期,直接返回该样本窗口。
首先我们要知道windowStart 与old.windowStart这两个值比较的结果分别对应着什么场景,这里还是通过例子进行举例,假如当前时间戳是1200ms,第一次进来先去找到对应的样本窗口,根据上面的计算可以算出应该是属于array数组的第 0 号位置,因为是第一次进来,所以需要初始化这个样本窗口实例,最后返回这个新创建的样本窗口实例;当1400ms的时候请求又进来了,首先我们知道1400ms和1200ms之间只间隔了200ms,所以它们是同属一个时间窗口的,而1400ms的窗口开始时间等于1000ms,与1200ms时创建的样本窗口实例的开始时间正好相等,所以windowStart == old.windowStart其实就意味着这个样本窗口还未过期;而2300ms与1200ms不是属于同一个时间窗的,2300ms的窗口开始时间是2000ms,大于1200ms的窗口开始时间,所以 windowStart > old.windowStart 就意味着这个样本窗口已经过期了。所以最终可以得出windowStart 与old.windowStart这两个值比较的结果能够判断这个样本窗口是否已经过期了。
// 条件成立:条件成立:说明当前样本窗口的起始时间点与计算出的样本窗口起始时间点相同,也就是说这个样本窗口并未过期
else if (windowStart == old.windowStart()) {
/*
* B0 B1 B2 B3 B4
* ||_______|_______|_______|_______|_______||___
* 200 400 600 800 1000 1200 timestamp
* ^
* time=888
* startTime of Bucket 3: 800, so it's up-to-date
*
* 如果当前{@code windowStart}等于旧bucket的开始时间戳,则表示时间在bucket内,因此直接返回bucket。
*/
return old;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
如果样本窗口已过期,则更新样本窗口并返回
根据上面的推断,如果windowStart > old.windowStart成立,就说明这个样本窗口已经过期了,也就意味着这个样本窗口中的统计数组已经没用了,所以调用了resetWindowTo方法去对统计数据进行重置,而resetWindowTo是个抽象方法,需要子类去进行实现,下面是BucketLeapArray的实现。
// 条件成立:说明当前样本窗口的起始时间点 大于 计算出的样本窗口起始时间点,也就是说计算出的样本窗口已经过时了,此时需要将原来的样本窗口替换
else if (windowStart > old.windowStart()) {
// 加锁进行更新老窗口中过期的统计数据
if (updateLock.tryLock()) {
try {
// 重置老窗口的统计数据
return resetWindowTo(old, windowStart);
} finally {
updateLock.unlock();
}
} else {
// Contention failed, the thread will yield its time slice to wait for bucket available.
Thread.yield();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
可以看到这个方法里面会把窗口开始时间进行重置更新,然后再把 MetricBucket 中记录的统计数据清空。这里还需要注意的是,在执行 resetWindowTo 方法之前会先去加锁,这是因为 resetWindowTo 方法中做了重置和清理这两个事情,加锁是为了保证两个操作的原子性,最后返回更新后的样本窗口实例。
protected WindowWrap<MetricBucket> resetWindowTo(WindowWrap<MetricBucket> w, long startTime) {
// 更新窗口起始时间
w.resetTo(startTime);
// 将多维度统计数据清零
w.value().reset();
return w;
}
public MetricBucket reset() {
// 将每个维度的统计数据清零
for (MetricEvent event : MetricEvent.values()) {
counters[event.ordinal()].reset();
}
initMinRt();
return this;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
样本窗口开始时间还大于当前时间戳的开始时间(一般不会出现)
// 条件成立:说明当前样本窗口的起始时间点 小于 计算出的样本窗口起始时间点,这种情况一般不会出现,因为时间不会倒流。除非人为修改了系统时钟
else if (windowStart < old.windowStart()) {
// Should not go through here, as the provided time is already behind.
return new WindowWrap<T>(windowLengthInMs, windowStart, newEmptyBucket(timeMillis));
}
2
3
4
5
# 7.chainMap 设计
public class CtSph implements Sph {
private static final Object[] OBJECTS0 = new Object[0];
//使用的普通的map,在高并发场景下,减少锁带来的性能消耗,因为不是全部必须加锁
private static volatile Map<ResourceWrapper, ProcessorSlotChain> chainMap
= new HashMap<ResourceWrapper, ProcessorSlotChain>();
private static final Object LOCK = new Object();
}
2
3
4
5
6
7
8
9
10
构建责任链: 上面的代码简单来说,就是从 chainMap 里面获取 slot 功能链, 没有的话,就构建一个,这里需要注意一点 Constants.MAX_SLOT_CHAIN_SIZE , chainMap 是限制了大小,最大不能超过 6000, 也就是说,默认不能超过 6000 个资源,如果超过 6000 个资源,则会有资源的限流没办法生效。
执行责任链就是执行各种 Slot。
ProcessorSlot<Object> lookProcessChain(ResourceWrapper resourceWrapper) {
//根据资源获取slot功能链
ProcessorSlotChain chain = chainMap.get(resourceWrapper);
if (chain == null) {
//上锁保证仅会初始化一个,双检锁
synchronized (LOCK) {
chain = chainMap.get(resourceWrapper);
if (chain == null) {
//Entry size limit. 最大的资源大小是6000个
if (chainMap.size() >= Constants.MAX_SLOT_CHAIN_SIZE) {
return null;
}
//构建一个slot引用链 -----
chain = SlotChainProvider.newSlotChain();
//map存储,写时复制,提高读取的效率,容量加1
Map<ResourceWrapper, ProcessorSlotChain> newMap = new HashMap<ResourceWrapper, ProcessorSlotChain>(
chainMap.size() + 1);
newMap.putAll(chainMap);
newMap.put(resourceWrapper, chain);
chainMap = newMap;
}
}
}
return chain;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# 8.常见 node
| 节点 | 作用 |
|---|---|
StatisticNode | 执行具体的资源统计操作 |
DefaultNode | 该节点持有指定上下文中指定资源的统计信息,当在同一个上下文中多次调用 entry 方法时,该节点可能下会创建有一系列的子节点。 另外每个 DefaultNode 中会关联一个 ClusterNode |
ClusterNode | 该节点中保存了资源的总体的运行时统计信息,包括 rt,线程数,qps 等等,相同的资源会全局共享同一个 ClusterNode,不管他属于哪个上下文 |
EntranceNode | 该节点表示一棵调用链树的入口节点,通过他可以获取调用链树中所有的子节点 |

# 9.顶层统计 Node
滑动窗口的基本思想是,通过维护一个固定大小的窗口,该窗口会在序列数据中向前滑动。每次滑动窗口都会基于窗口内的数据执行特定的操作。在 Sentinel 中,滑动窗口通常用于统计、聚合和监控流数据,以便及时识别异常或执行其他处理。
//StatisticNode统计信息
public class StatisticNode implements Node {
private transient volatile Metric rollingCounterInSecond;
private transient Metric rollingCounterInMinute;
private LongAdder curThreadNum;
private long lastFetchTime;
public StatisticNode() {
//秒级别设置,窗口是2个,总时间是1000ms
this.rollingCounterInSecond = new ArrayMetric(SampleCountProperty.SAMPLE_COUNT, IntervalProperty.INTERVAL);
//分钟级别设置,分钟级统计窗口是60个,每个统计时间是1s
this.rollingCounterInMinute = new ArrayMetric(60, 60000, false);
this.curThreadNum = new LongAdder();
this.lastFetchTime = -1L;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
public class SampleCountProperty {
public static volatile int SAMPLE_COUNT = 2;
}
public class IntervalProperty {
public static volatile int INTERVAL = 1000;
}
2
3
4
5
6
# 10.ContextUtil
ContextUtil 很经典,使用了很多并发编程中的知识
- 先从
ThreadLocal中尝试获取,获取到则直接返回 - 如果第一步没有获取,尝试从缓存中获取该上下文名称对应的 入口节点
- 判断缓存中入口节点数量是否大于 2000public final static int MAX_CONTEXT_NAME_SIZE = 2000;如果已经大于 2000,返回一个 NULL_CONTEXT
- 以上检查都通过根据上下文名称生成入口节点(entranceNode),期间会进行双关检索确保线程安全
- 加入至全局根节点下,并加入缓存,注意每个 ContextName 对应一个入口节点 entranceNode
- 根据 ContextName 和 entranceNode 初始化上下文对象,并将上下文对象设置到当前线程中
public class ContextUtil {
/**
* Store the context in ThreadLocal for easy access.
*/
private static ThreadLocal<Context> contextHolder = new ThreadLocal<>();
/**
* Holds all {@link EntranceNode}. Each {@link EntranceNode} is associated with a distinct context name.
*/
private static volatile Map<String, DefaultNode> contextNameNodeMap = new HashMap<>();
private static final ReentrantLock LOCK = new ReentrantLock();
private static final Context NULL_CONTEXT = new NullContext();
static {
// Cache the entrance node for default context.
initDefaultContext();
}
private static void initDefaultContext() {
String defaultContextName = Constants.CONTEXT_DEFAULT_NAME;
EntranceNode node = new EntranceNode(new StringResourceWrapper(defaultContextName, EntryType.IN), null);
Constants.ROOT.addChild(node);
contextNameNodeMap.put(defaultContextName, node);
}
//SentinelResource注解生效的入口
public static Context enter(String name, String origin) {
if (Constants.CONTEXT_DEFAULT_NAME.equals(name)) {
throw new ContextNameDefineException(
"The " + Constants.CONTEXT_DEFAULT_NAME + " can't be permit to defined!");
}
return trueEnter(name, origin);
}
protected static Context trueEnter(String name, String origin) {
Context context = contextHolder.get();
if (context == null) {
Map<String, DefaultNode> localCacheNameMap = contextNameNodeMap;
DefaultNode node = localCacheNameMap.get(name);
if (node == null) {
if (localCacheNameMap.size() > Constants.MAX_CONTEXT_NAME_SIZE) {
setNullContext();
return NULL_CONTEXT;
} else {
LOCK.lock();
try {
node = contextNameNodeMap.get(name);
if (node == null) {
if (contextNameNodeMap.size() > Constants.MAX_CONTEXT_NAME_SIZE) {
setNullContext();
return NULL_CONTEXT;
} else {
node = new EntranceNode(new StringResourceWrapper(name, EntryType.IN), null);
// Add entrance node.
Constants.ROOT.addChild(node);
Map<String, DefaultNode> newMap = new HashMap<>(contextNameNodeMap.size() + 1);
newMap.putAll(contextNameNodeMap);
newMap.put(name, node);
contextNameNodeMap = newMap;
}
}
} finally {
LOCK.unlock();
}
}
}
context = new Context(node, name);
context.setOrigin(origin);
contextHolder.set(context);
}
return context;
}
//xXXXXXXXXXXXXXXXx
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
# 11.时间窗口统计
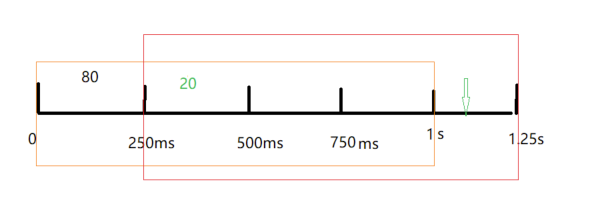
有了滑动时间时间窗口之后的统计变成下面的样子。把 1s 分成四个 bucket,每个是 250ms 间隔。
假如 750ms~1s 之间,来了一个请求,统计当前 bucket 和前面三个 bucket 中的请求量总和 101,大于阈值,就会把当前这个请求进行限流。
假如 1s 到 1.25s 之间,来了一个请求,统计当前 bucket 和前面三个 bucket 中的请求量总和 21,小于阈值,就会正常放行。这里请求总量统计去掉了 0250ms 之间的 bucket,就是体现了时间窗口的滑动。