
# 一.基础概念
# 1.架构演进
在系统架构与设计的实践中,从宏观上可以总结为三个阶段;
单体架构:就是把所有的功能、模块都集中到一个项目中,部署在一台服务器上,从而对外提供服务(单体架构、单体服务、单体应用)。直白一点:就是只有一个项目,只有一个 war;
分布式架构:就是把所有的功能、模块拆分成不同的子项目,部署在多台不同的服务器上,这些子项目相互协作共同对外提供服务。直白一点:就是有很多项目,有很多 wr 包,这些项目相互协作完成需要的功能,不是一个 war 能完成的,一个 war 包完成不了;
微服务架构:分布式强调系统的拆分,微服务也是强调系统的拆分,微服务架构属于分布式架构的范畴;
并且到目前为止,微服务并没有一个统一的标准的定义
SOA:(Service-Oriented Architecture,面向服务的架构)是一种软件设计和架构模式,旨在通过将应用程序拆分为独立的、可重用的服务组件来实现系统的松耦合和灵活性。每个服务都代表着一个特定的功能单元,可以通过网络进行通信并相互交互。SOA 有助于在复杂的企业环境中构建可扩展、可维护和可协作的应用程序。
# 2.分布式和微服务区别?
分布式,就是将巨大的一个系统划分为多个模块,这一点和微服务是一样的,都是要把系统进行拆分,部署到不同机器上,因为一台机器可能承受不了这么大的访问压力,或者说要支撑这么大的访问压力需要采购一台性能超级好的服务器其财务成本非常高,有这些预算完全可以采购很多台普通的服务器了,分布式系统各个模块通过接口进行数据交互,其实分布式也是一种微服务,因为都是把模块拆分变为独立的单元,提供接口来调用
它们的本质的区别体现在“目标”上,何为目标,就是你采用分布式架构或者采用微服务架构,你最终是为了什么,要达到什么目的?分布式架构的目标是什么?就是访问量很大一台机器承受不了,或者是成本问题,不得不使用多台机器来完成服务的部署;而微服务的目标是什么?只是让各个模块拆分开来,不会被互相影响,比如模块的升级或者出现 BUG 或者是重构等等都不要影响到其他模块,微服务它是可以在一台机器上部署;
# 3.什么是微服务?
简单的说,微服务架构就是将一个完整的应用从数据存储开始垂直拆分成多个不同的服务,每个服务都能独立部署、独立维护、独立扩展,服务与服务间通过诸如 RESTful API 的方式互相调用。
# 4.服务治理
服务治理可以说是微服务架构中最为核心和基础的模块, 它主要用来实现各个微服务实例的自动化注册与发现。 为什么我们在微服务架构中那么需要服务治理模块呢?微服务系统没有它会有什么不好的地方吗?
在最初开始构建微服务系统的时候可能服务并不多, 我们可以通过做一些静态配置来 完成服务的调用。 比如,有两个服务 A 和 B, 其中服务 A 需要调用服务 B 来完成一个业务 操作时,为了实现服务 B 的高可用, 不论采用服务端负载均衡还是客户端负载均衡, 都需 要手工维护服务 B 的具体实例清单。 但是随着业务的发展, 系统功能越来越复杂, 相应的 微服务应用也不断增加, 我们的静态配置就会变得越来越难以维护。 并且面对不断发展的业务, 我们的集群规模、 服务的位置 、 服务的命名等都有可能发生变化, 如果还是通过手 工维护的方式, 那么极易发生错误或是命名冲突等问题。 同时, 对于这类静态内容的维护 也必将消耗大量的人力。
为了解决微服务架构中的服务实例维护问题, 产生了大量的服务治理框架和产品。 这 些框架和产品的实现都围绕着服务注册与服务发现机制来完成对微服务应用实例的自动化 管理。
# 5.服务注册
在服务治理框架中, 通常都会构建一个注册中心, 每个服务单元向注册 中心登记自己提供的服务, 将主机与端口号、 版本号、 通信协议等一些附加信息告 知注册中心, 注册中心按服务名分类组织服务清单。 比如, 我们有两个提供服务 A 的进程分别运行于 192.168.0.100:8000 和 192.168.0.101:8000 位置上, 另外还有三个提供服务 B 的进程分别运行千 192.168.0.100:9000、 192.168.0.101:9000、 192.168.0.102:9000 位置上。 当这些进程均启动, 并向注册中心注册自己的服务之后, 注册中心就会维护类似下面的一个服务清单。 另外, 服务注册中心还需要以心跳的方式去监测清单中的服务是否可用, 若不可用 需要从服务清单中剔除, 达到排除故障服务的效果。
Spring Cloud支持得最好的是 Nacos,其次是 Eureka,其次是 Consul,再次是 Zookeeper。
# 6.服务发现
服务消费者向注册中心请求已经登记的服务列表,然后得到某个服务
由于在服务治理框架下运作, 服务间的调用不再通过指定具体的实例地 址来实现, 而是通过向服务名发起请求调用实现。 所以, 服务调用方在调用服务提 供方接口的时候, 并不知道具体的服务实例位置。 因此, 调用方需要向服务注册中 心咨询服务, 并获取所有服务的实例清单, 以实现对具体服务实例的访问。 比如, 现有服务 C 希望调用服务 A, 服务 C 就需要向注册中心发起咨询服务请求,服务注 册中心就会将服务 A 的位置清单返回给服务 C, 如按上例服务 A 的情况,C 便获得 了服务 A 的两个可用位置 192.168.0.100:8000 和 192.168.0.101:8000。 当服务 C 要发起调用的时候,便从该清单中以某种轮询策略取出一个位置来进行服 务调用,这就是后续我们将会介绍的客户端负载均衡。 这里我们只是列举了一种简 单的服务治理逻辑, 以方便理解服务治理框架的基本运行思路。 实际的框架为了性 能等因素, 不会采用每次都向服务注册中心获取服务的方式, 并且不同的应用场景 在缓存和服务剔除等机制上也会有一些不同的实现策略。
# 7.什么是 Spring Cloud?
Spring Cloud 是一个基于 Spring Boot 实现的云应用开发工具,它为基于 JVM 的云应用开发中的配置管理、服务发现、断路器、智能路由、微代理、控制总线、全局锁、决策竞选、分布式会话和集群状态管理等操作提供了一种简单的开发方式。
Spring Cloud 包含了多个子项目(针对分布式系统中涉及的多个不同开源产品),比如:Spring Cloud Config、Spring Cloud Netflix、Spring Cloud CloudFoundry、Spring Cloud AWS、Spring Cloud Security、Spring Cloud Commons、Spring Cloud Zookeeper、Spring Cloud CLI 等项目。
Spring Cloud 为开发人员提供了一些工具用来快速构建分布式系统中的一些常见模式和解决一些常见问题(例如配置管理、服务发现、断路器智能路由、微代理、控制总线、一次性令牌、全局锁、领导选举、分布式会话、群集状态)。
# 8.微服务与 Spring-Cloud?
微服务只是一种项目的架构方式、架构理念,或者说是一种概念,就如同我们的 MVC 架构一样
Spring Cloud 便是对这种架构方式的技术落地实现。
# 9.Spring Cloud 版本
为了避免大家对版本号的误解,避免与子项目版本号混淆,所以 Spring Cloud 发布的版本是一个按照字母顺序的伦敦地铁站的名字(“天使”是第一个版本,"布里克斯顿”是第二个),字母顺序是从 A-Z,目前最新稳定版本 Greenwich
SR3,当 Spring Cloud 里面的某些子项目出现关键性 bug 或重大更新,则发布序列将推出名称以“.SRX”结尾的版本,其中“X”是一个数字,比如:Greenwich SRl、Greenwich SR2、Greenwich SR3;
Spring Cloud 是微服务开发的一整套解决方案,采用 Spring Cloud 开发,每个项目依然是使用 Spring Boot
版本
Hoxton- Greenwich
- Finchley
- Edgware
- Dalston
- Camden
- Brixton
- Angel
# 10.Spring Cloud 整体架构?
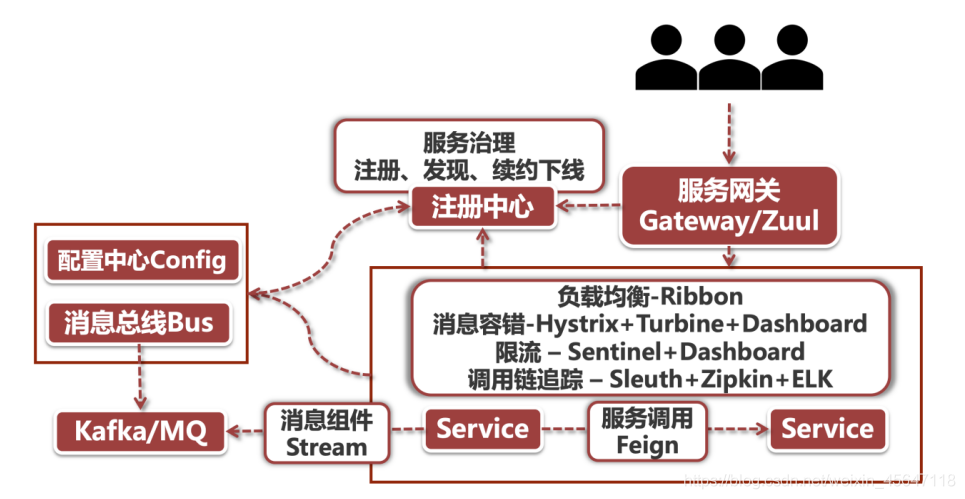
# 11.Spring Cloud 组件
它主要提供的模块包括:
- 服务发现(
Eureka) - 断路器(
Hystrix) - 智能路有(
Zuul) - 客户端负载均衡(
Ribbon)
# 12.Spring Cloud 注解
@EnableEurekaServer:用在 SpringBoot 启动类上,表示这是一个 eureka 服务注册中心;@EnableDiscoveryClient:用在 SpringBoot 启动类上,表示这是一个服务,可以被注册中心找到;@LoadBalanced:开启负载均衡能力;@EnableCircuitBreaker:用在启动类上,开启断路器功能;@HystrixCommand(fallbackMethod=”backMethod”):用在方法上,fallbackMethod 指定断路回调方法;@EnableConfigServer:用在启动类上,表示这是一个配置中心,开启 Config Server;@EnableZuulProxy:开启 zuul 路由,用在启动类上;- `@SpringCloudApplication:
- @SpringBootApplication
- @EnableDiscovertyClient
- @EnableCircuitBreaker
- 分别是
SpringBoot注解、注册服务中心Eureka注解、断路器注解。对于 SpringCloud 来说,这是每一微服务必须应有的三个注解,所以才推出了@SpringCloudApplication 这一注解集合。
@ConfigurationProperties:Spring 源码中大量使用了 ConfigurationProperties 注解,比如 server.port 就是由该注解获取到的,通过与其他注解配合使用,能够实现 Bean 的按需配置。
# 13.技术架构图
# 二.eureka
# 1.什么是 eureka?
Eureka服务治理体系中的三个核心角色:
- 服务注册中心
- 服务提供者
- 服务消费者
Spring Cloud Eureka, 使用 Netflix Eureka 来实现服务注册与发现, 它既包含了服务端组件,也包含了客户端组件,并且服务端与客户端均采用 Java 编写,所以 Eureka 主要适用 于通过 Java 实现的分布式系统,或是与 NM 兼容语言构建的系统。但是,由于 Eureka 服 务端的服务治理机制提供了完备的 RESTfulAPL 所以它也支持将非 Java 语言构建的微服 务应用纳入 Eureka 的服务治理体系中来。只是在使用其他语言平台的时候,需要自己来实 现 Euerka 的客户端程序。不过庆幸的是,在目前几个较为流行的开发平台上,都已经有了 一些针对 Eureka 注册中心的客户端实现框架,比如.NET 平台的 Steeltoe、 Node.js 的 euerkaj-sc-lient 等。
Eureka 服务端,我们也称为服务注册中心。它同其他服务注册中心一样,支持高可用 配置。它依托于强一致性提供良好的服务实例可用性,可以应对多种不同的故障场景。如 果 Eureka 以集群模式部署,当集群中有分片出现故障时,那么 Eureka 就转入自我保护模 式。它允许在分片故障期间继续提供服务的发现和注册,当故障分片恢复运行时,集群中 的其他分片会把它们的状态再次同步回来。以在 AWS 上的实践为例,Netflix 推荐每个可 用的区域运行一个 Eureka 服务端,通过它来形成集群。不同可用区域的服务注册中心通过 异步模式互相复制各自的状态,这意味着在任意给定的时间点每个实例关于所有服务的状 态是有细微差别的。
Eureka 客户端,主要处理服务的注册与发现。客户端服务通过注解和参数配置的方式, 嵌入在客户端应用程序的代码中,在应用程序运行时,Euerka 客户端向注册中心注册自身 提供的服务并周期性地发送心跳来更新它的服务租约。同时,它也能从服务端查询当前注 册的服务信息并把它们缓存到本地并周期性地刷新服务状态。

# 2.EurekaServer 架构
- 注册
- 续约
- 下线
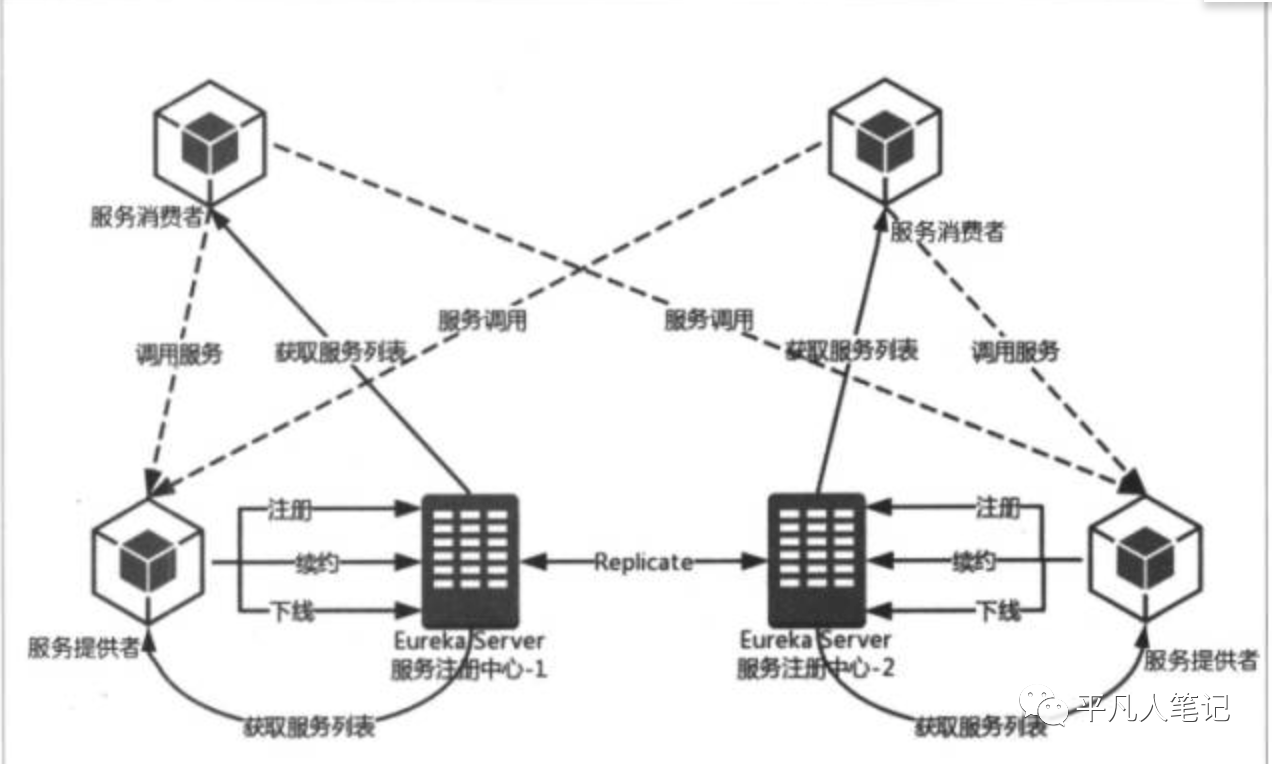
Service Provider:暴露服务的服务提供方。Service Consumer:调用远程服务的服务消费方。EureKa Server:服务注册中心和服务发现中心。
# 3.eureka 保护机制
在没有 Eureka 自我保护的情况下,如果 Eureka Server 在一定时间内没有接收到某个微服务实例的心跳,Eureka Server 将会注销该实例,但是当发生网络分区故障时,那么微服务与 Eureka Server 之间将无法正常通信,以上行为可能变得非常危险了因为微服务本身其实是正常的此时不应该注销这个微服务,如果没有自我保护机制,那么 Eureka Server 就会将此服务注销掉。
当 Eureka Server 节点在短时间内丢失过多客户端时(可能发生了网络分区故障),那么就会把这个微服务节点进行保护。一旦进入自我保护模式,Eureka Server 就会保护服务注册表中的信息,不删除服务注册表中的数据(也就是不会注销任何微服务)。当网络故障恢复后,该Eureka Server 节点会再自动退出自我保护模式。
所以,自我保护模式是一种应对网络异常的安全保护措施,它的架构哲学是宁可同时保留所有微服务(健康的微服务和不健康的微服务都会保留),也不盲目注销任何健康的微服务,使用自我保护模式,可以让 Eureka 集群更加的健壮稳定。
#禁用eurekd目我保护
eureka.server.enable-self-preservation=false
2
# 4.Eureka 与 Zookeeper?
著名的 CAP 理论指出,一个分布式系统不可能同时满足 C(一致性)、A(可用性)和 P(分区容错性)。
由于分区容错性在是分布式系统中必须要保证的,因此我们只能在 A 和 C 之间进行权衡,在此 Zookeeper 保证的是 CP,而 Eureka 则是 AP。
Eureka保证AP:Eureka 优先保证可用性,Eureka 各个节点是平等的,某节点异常,剩余的节点依然可以提供注册和服务查询功能。
在向某个 Eureka 注册时,如果发现连接失败,则只要有一台 Eureka 还在,就能保证注册服务可用,但是数据可能不是最新的(不保证强一致性)。
Zookeeper保证CP:在 ZooKeeper 中,当 master 节点因为网络故障与其他节点失去联系时,剩余节点会重新进行 leader 选举,但是问题在于,选举 leader 需要一定时间,且选举期间整个 ZooKeeper 集群都是不可用的,这就导致在选举期间注册服务瘫痪。在云部署的环境下,因网络问题使得 ZooKeeper 集群失去 master 节点是大概率事件,虽然服务最终能够恢复,但是在选举时间内导致服务注册长期不可用是难以容忍的。
# 5.Eureka 高可用集群?
相互注册,去中心化
#端口号
server:
port: 8769
spring:
application:
name: eurka-server
eureka:
instance:
hostname: eureka8769
client:
register-with-eureka: false #服务将不会注册自己到Eureka注册表中
fetch-registry: false #不需要去检索服务
serviceUrl:
defaultZone: http://eureka8767:8767/eureka/,http://eureka8768:8768/eureka/
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
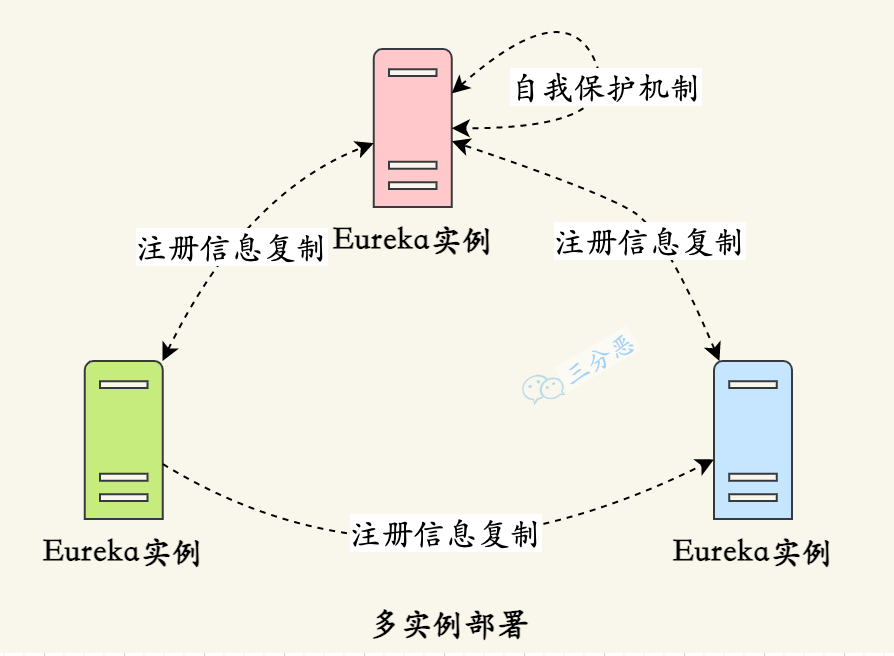
- 多实例部署: 通过将多个 Eureka Server 实例部署在不同的节点上,可以实现高可用性。当其中一个实例发生故障时,其他实例仍然可以提供服务,并保持注册信息的一致性。
- 服务注册信息的复制: 当一个服务实例向 Eureka Server 注册时,每个 Eureka Server 实例都会复制其他实例的注册信息,以保持数据的一致性。当某个 Eureka Server 实例发生故障时,其他实例可以接管其工作,保证整个系统的正常运行。
- 自我保护机制: Eureka 还具有自我保护机制。当 Eureka Server 节点在一定时间内没有接收到心跳时,它会进入自我保护模式。在自我保护模式下,Eureka Server 不再剔除注册表中的服务实例,以保护现有的注册信息。这样可以防止由于网络抖动或其他原因导致的误剔除,进一步提高系统的稳定性。
# 6.eureka 三要素?
在服务治理示例中, 我们的示例虽然简单, 但是麻雀虽小,五脏俱全。 它已经包含了整个 Eureka 服务治理基础架构的三个核心要素。
服务注册中心: Eureka 提供的服务端, 提供服务注册与发现的功能, 也就是我们实现的 eureka-server。服务提供者:提供服务的应用, 可以是 SpringBoot 应用, 也可以是其他技术平台且遵循 Eureka 通信机制的应用。它将自己提供的服务注册到 Eureka, 以供其他应用发现, 也就是我们实现的 spring-boot-service 应用。服务消费者:消费者应用从服务注册中心获取服务列表, 从而使消费者可以知道去何处调用其所需要的服务,在面我们使用了 Ribbon 来实现服务消费,另外后续还会介绍使用 Feign 的消费方式。 很多时候, 客户端既是服务提供者也是服务消费者。
# 7.Eureka 本地缓存
Eureka 本地缓存,通常可以指的是在使用 Eureka 作为服务发现框架时,为了提高性能和减少网络开销,可以在服务实例的客户端(服务消费者)端使用本地缓存。这种缓存可以帮助避免频繁地向 Eureka 服务器发起查询请求,而是在本地保留一份已知的服务实例清单,以供消费者快速访问。
在使用 Eureka 的情况下,可以采取以下步骤来实现本地缓存:
注册:在服务启动时,将自己注册到 Eureka 服务器,以便其他服务可以发现它。查询:当服务需要调用其他服务时,它可以首先从本地缓存中查找所需的服务实例。如果缓存中没有,则可以发起一个查询请求来获取最新的服务实例列表。刷新:定期刷新本地缓存,以确保服务实例的信息保持最新。可以设置合适的缓存刷新策略,例如定时刷新或者在发生变更时触发刷新。失效:如果从本地缓存获取的服务实例在调用时出现问题(例如连接失败),可以考虑从新的实例中选择一个或者从 Eureka 服务器获取最新的实例列表。容错:在使用本地缓存时,需要考虑容错机制,以防止缓存失效或者包含过时的信息。可以设置合适的超时时间和重试策略。
需要注意的是,使用本地缓存可以提高性能,但也需要权衡缓存的一致性和实时性。如果对于实时性要求较高,可以考虑使用更复杂的缓存策略,如基于事件通知的机制。
# 8.服务提供者
1.服务注册:将服务所在主机、端口、版本号、通信协议等信息登记到注册中心上;
“服务提供者” 在启动的时候会通过发送 REST 请求的方式将自己注册到 EurekaServer 上, 同时带上了自身服务的一些元数据信息。Eureka Server 接收到这个 REST 请求之后, 将元数据信息存储在一个双层结构 Map中, 其中第一层的 key 是服务名, 第二层的 key 是 具体服务的实例名。
在服务注册时, 需要确认一下 eureka.client.register-with-eureka=true参数是否正确,该值默认为 true。若设置为 false 将不会启动注册操作。
//注册方法
boolean register() throws Throwable {
logger.info("DiscoveryClient_{}: registering service...", this.appPathIdentifier);
EurekaHttpResponse httpResponse;
try {
httpResponse = this.eurekaTransport.registrationClient.register(this.instanceInfo);
} catch (Exception var3) {
logger.warn("DiscoveryClient_{} - registration failed {}", new Object[]{this.appPathIdentifier, var3.getMessage(), var3});
throw var3;
}
if (logger.isInfoEnabled()) {
logger.info("DiscoveryClient_{} - registration status: {}", this.appPathIdentifier, httpResponse.getStatusCode());
}
return httpResponse.getStatusCode() == Status.NO_CONTENT.getStatusCode();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
2.服务同步
两个服务提供者分别注册到了两个不同的服务注册中心上, 也就是说, 它们的信息分别被两个服务注册中心所维护。 此时, 由于服务注册中心之间因互相注册为服务, 当服务提供者发送注册请求到一个服务注册中心时, 它会将该请求转发给集群中相连的其他注册中心,从而实现注册中心之间的服务同步。通过服务同步,两个服务提供者的服务信息就可以通过这两台服务注册中心中的任意一台获取到。
3.服务续约
在注册完服务之后,服务提供者会维护一个心跳用来持续告诉 Eureka Server自己的健康状态,以防止 Eureka Server将该服务实例从服务列表中排除出去,我们称该操作为服务续约(Renew)。
关千服务续约有两个重要属性,我们可以关注并根据需要来进行调整:
为了定期更新客户端的服务清单, 以保证客户端能够访问确实健康的服务实例, 服务获取的请求不会只限于服务启动, 而是一个定时执行的任务, 通过参数设置频率,eureka.client.registry-fetch-interval-seconds=30 配置参数,它默认为 30 秒。
#参数用于定义服务续约任务的调用间隔时间,默认为30秒。
eureka.instance.lease-renewal-interval-in-seconds=30
#参数用于定义服务失效的时间,默认为90秒。
eureka.instance.lease-expiration-duration-in-seconds=90
2
3
4
5
//后台线程定时任务,检测服务的健康状态
private void initScheduledTasks() {
int renewalIntervalInSecs;
int expBackOffBound;
if (this.clientConfig.shouldFetchRegistry()) {
renewalIntervalInSecs = this.clientConfig.getRegistryFetchIntervalSeconds();
expBackOffBound = this.clientConfig.getCacheRefreshExecutorExponentialBackOffBound();
this.scheduler.schedule(new TimedSupervisorTask("cacheRefresh", this.scheduler, this.cacheRefreshExecutor, renewalIntervalInSecs, TimeUnit.SECONDS, expBackOffBound, new DiscoveryClient.CacheRefreshThread()), (long)renewalIntervalInSecs, TimeUnit.SECONDS);
}
if (this.clientConfig.shouldRegisterWithEureka()) {
renewalIntervalInSecs = this.instanceInfo.getLeaseInfo().getRenewalIntervalInSecs();
expBackOffBound = this.clientConfig.getHeartbeatExecutorExponentialBackOffBound();
logger.info("Starting heartbeat executor: renew interval is: {}", renewalIntervalInSecs);
this.scheduler.schedule(new TimedSupervisorTask("heartbeat", this.scheduler, this.heartbeatExecutor, renewalIntervalInSecs, TimeUnit.SECONDS, expBackOffBound, new DiscoveryClient.HeartbeatThread()), (long)renewalIntervalInSecs, TimeUnit.SECONDS);
this.instanceInfoReplicator = new InstanceInfoReplicator(this, this.instanceInfo, this.clientConfig.getInstanceInfoReplicationIntervalSeconds(), 2);
this.statusChangeListener = new StatusChangeListener() {
public String getId() {
return "statusChangeListener";
}
public void notify(StatusChangeEvent statusChangeEvent) {
if (InstanceStatus.DOWN != statusChangeEvent.getStatus() && InstanceStatus.DOWN != statusChangeEvent.getPreviousStatus()) {
DiscoveryClient.logger.info("Saw local status change event {}", statusChangeEvent);
} else {
DiscoveryClient.logger.warn("Saw local status change event {}", statusChangeEvent);
}
DiscoveryClient.this.instanceInfoReplicator.onDemandUpdate();
}
};
if (this.clientConfig.shouldOnDemandUpdateStatusChange()) {
this.applicationInfoManager.registerStatusChangeListener(this.statusChangeListener);
}
this.instanceInfoReplicator.start(this.clientConfig.getInitialInstanceInfoReplicationIntervalSeconds());
} else {
logger.info("Not registering with Eureka server per configuration");
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
# 9.服务消费者
1.获取服务:在服务注册中心已经注册了一个服务,并且该服务有两个实例。 当我们启动 服务消费者的时候,它会发送一个 REST 请求给服务注册中心,来获取上面注册的服务清单。为了性能考虑,EurekaServer 会维护一份只读的服务清单来返回给客户端,同时该缓存清单会每隔 30 秒更新一次。
获取服务是服务消费者的基础,所以必须确保 eureka.client.fetch-registry= true 参数没有被修改成 false, 该值默认为 true。若希望修改缓存清单的更新时间,可 以通过 eureka.client.registry-fetch-interval-seconds=30 参数进行修改, 该参数默认值为 30, 单位为秒。
2.服务调用:服务消费者在获取服务清单后,通过服务名可以获得具体提供服务的实例名和该实例的元数据信息。 因为有这些服务实例的详细信息, 所以客户端可以根据自己的需要决定具体调用哪个实例,在 ribbon 中会默认采用轮询的方式进行调用,从而实现客户端的负载均衡。
3.服务下线:在系统运行过程中必然会面临关闭或重启服务的某个实例的情况, 在服务关闭期间, 我们自然不希望客户端会继续调用关闭了的实例。 所以在客户端程序中, 当服务实例进行正常的关闭操作时, 它会触发一个服务下线的 REST 请求给 Eureka Server, 告诉服务注册中心服务已经下线。服务端在接收到请求之后, 将该服务状态置为下线(DOWN), 并把该下线事件传播出去。
# 10.服务注册中心
1.失效剔除:有些时候, 我们的服务实例并不一定会正常下线, 可能由于内存溢出、 网络故障等原因使得服务不能正常工作, 而服务注册中心并未收到服务下线的请求。 为了从服务列表中将这些无法提供服务的实例剔除,EurekaSrevre 在启动的时候会创建一个定时任务, 默认每隔一段时间默认为 60 秒将当前清单中超时默认为 90 秒没有续约的服务剔除出去。
2.自我保护:当我们在本地调试基于 Eurkea 的程序时, 基本上都会碰到这样一个问题, 在服务注册中心的信息面板中出现类似下面的红色警告信息:
EMERGENCY! EUREKA MAY BE INCORRECTLY CLAIMING INSTANCES ARE UP WHEN THEY'RE NOT. RENEWALS ARE LESSER THAN THRESHOLD AND HENCE THE INSTANCES ARE NOT BEING EXPIRED JUST TO BE SAFE.
实际上, 该警告就是触发了 EurekaServer 的自我保护机制。 之前我们介绍过, 服务注 册到 EurekaSrevre 之后,会维护一个心跳连接,告诉 EurekaServer 自己还活着。EurkeaServer 在运行期间,会统计心跳失败的比例在 15 分钟之内是否低于 85%,如果出现低于的情况(在 单机调试的时候很容易满足, 实际在生产环境上通常是由于网络不稳定导致), Eureka Server 会将当前的实例注册信息保护起来, 让这些实例不会过期, 尽可能保护这些注册信 息。 但是, 在这段保护期间内实例若出现问题, 那么客户端很容易拿到实际已经不存在的 服务实例, 会出现调用失败的清况, 所以客户端必须要有容错机制, 比如可以使用请求重试、 断路器等机制。
由于本地调试很容易触发注册中心的保护机制, 这会使得注册中心维护的服务实例不那么准确。 所以, 我们在本地进行开发的时候, 可以使用参数来关闭保护机制, 以确保注册中心可以将不可用的实例正确剔除。
#关闭服务保护机制
eureka.server.enableself-preservation =false
2
# 11.什么是 Region?
在 Netflix 的 Eureka 服务发现框架中,"Region" 是一个用于划分和组织服务实例的概念。Eureka 的设计可以支持分布式的多区域(Region)架构,每个区域可以包含一组相关的服务实例。这有助于提高系统的可用性、性能和容错能力。
以下是一些关于 Eureka 中 "Region" 的要点:
区域划分:Eureka 允许将服务实例分组到不同的区域。每个区域可以对应于一个特定的数据中心、地理位置或者任何你想要的逻辑划分。这有助于在大规模系统中有效地管理和组织服务。
故障隔离:通过将服务实例划分到不同的区域,可以实现故障隔离。如果一个区域的服务出现问题,不会影响其他区域的服务。这有助于提高系统的容错性。
网络分区:当跨地理位置或数据中心部署服务时,可能会发生网络分区(Network Partition)的情况,即某些区域之间的网络连接中断。通过区域划分,可以降低网络分区对整个系统的影响,使得在一个区域中的服务实例可以继续相互通信。
本地性:对于某些应用场景,要求服务实例尽可能在相同的区域中。例如,某些服务可能需要访问区域内的共享资源,而不希望跨区域访问。
配置和策略:Eureka 允许针对不同的区域配置不同的参数和策略,例如心跳间隔、失效时间等。这有助于根据区域的特点来调整服务发现的行为。
需要注意的是,虽然 Eureka 支持区域的概念,但在一些较小的系统中,可能并不需要使用区域功能。区域功能更适用于大规模、跨地理位置部署的微服务架构。在设计和配置区域时,需要考虑到系统的整体架构、可用性要求以及网络拓扑等因素。
//获取region
public static String getRegion(EurekaClientConfig clientConfig) {
String region = clientConfig.getRegion();
if (region == null) {
region = "default";
}
region = region.trim().toLowerCase();
return region;
}
2
3
4
5
6
7
8
9
# 12.什么是 Zone?
在 Netflix Eureka 中,"Zone" 是一种用于组织和划分服务实例的概念。Zone 可以被理解为一个逻辑上的分区,用于将服务实例划分成不同的组,以便更好地管理和控制服务的可用性、容错性和流量路由等方面。
每个服务实例都可以属于一个特定的 Zone,而一个 Zone 可以包含多个服务实例。通过在 Eureka 中使用 Zone 的概念,可以实现一些重要的目标:
可用性和容错性: 将服务实例划分为不同的 Zone 可以帮助实现跨地理位置的冗余和高可用性。如果某个 Zone 中的服务实例不可用,其他 Zone 中的实例仍然可以提供服务。
流量控制和路由: 可以基于 Zone 来控制流量的路由。例如,可以将来自特定区域的流量引导到相应 Zone 中的服务实例,以实现更优的用户体验或遵循特定的负载均衡策略。
部署和维护: 将不同的服务实例部署在不同的 Zone 中可以帮助管理和维护。当需要执行维护操作或者部署新版本时,可以逐个 Zone 进行操作,以减少对整个系统的影响。
性能监控和故障隔离: 通过将服务实例划分为不同的 Zone,可以更精细地监控性能和故障情况。如果某个 Zone 中的服务实例出现性能问题或故障,可以更容易地定位并隔离问题。
要使用 Zone 功能,通常需要在 Eureka 客户端和服务端的配置中指定 Zone 的信息。Eureka 客户端可以通过配置来标识自己所属的 Zone,而 Eureka 服务器可以使用这些信息来进行合适的服务实例管理和路由。
//获取Zone
public String[] getAvailabilityZones(String region) {
String value = (String)this.availabilityZones.get(region);
if (value == null) {
value = "defaultZone";
}
return value.split(",");
}
2
3
4
5
6
7
8
# 13.服务消费基础
服务消费基础实现方式,不是传统实现方式
@RestController
public class DcController {
@Autowired
LoadBalancerClient loadBalancerClient;
@Autowired
RestTemplate restTemplate;
@GetMapping("/consumer")
public String dc() {
ServiceInstance serviceInstance = loadBalancerClient.choose("eureka-server");
String url = "http://" + serviceInstance.getHost() + ":" + serviceInstance.getPort() + "/dc";
System.out.println(url);
return restTemplate.getForObject(url, String.class);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
可以看到这里,我们注入了LoadBalancerClient和RestTemplate,并在/consumer接口的实现中,先通过loadBalancerClient的choose函数来负载均衡的选出一个eureka-client的服务实例,这个服务实例的基本信息存储在ServiceInstance中,然后通过这些对象中的信息拼接出访问/dc接口的详细地址,最后再利用RestTemplate对象实现对服务提供者接口的调用。
# 14.eureka 源码
@EnableDiscoveryClient 是 Spring Cloud 提供的一个注解,用于在 Spring Boot 应用中启用服务发现客户端功能,以便将应用注册到服务注册中心(如 Eureka、Consul 等)并实现服务发现。
当在 Spring Boot 应用中添加 @EnableDiscoveryClient 注解时,应用将会具备以下功能:
注册到服务注册中心: 应用会将自身的信息(例如应用名称、主机地址、端口等)注册到配置的服务注册中心。这使得其他服务能够发现并调用该应用。
服务发现: 应用能够从服务注册中心获取其他服务的信息,包括它们的主机地址和端口等。这使得应用可以通过服务名来调用其他服务,而不需要硬编码具体的地址。
负载均衡: 如果应用要调用多个同名的服务实例,服务发现客户端可以实现负载均衡,将请求分发到不同的实例上,以达到负载均衡的效果。
服务健康检查: 服务发现客户端可以定期从注册中心获取服务实例的健康状态,以便进行故障检测和恢复。
要使用 @EnableDiscoveryClient 注解,通常需要在 Spring Boot 应用的主类上添加这个注解。以下是一个简单的示例:
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.client.discovery.EnableDiscoveryClient;
@SpringBootApplication
@EnableDiscoveryClient
public class MyApplication {
public static void main(String[] args) {
SpringApplication.run(MyApplication.class, args);
}
}
2
3
4
5
6
7
8
9
10
11
12
//EnableDiscoveryClient
@Target({ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
@Import({EnableDiscoveryClientImportSelector.class})
public @interface EnableDiscoveryClient {
boolean autoRegister() default true;
}
2
3
4
5
6
7
8
9
核心类图:
继承关系:

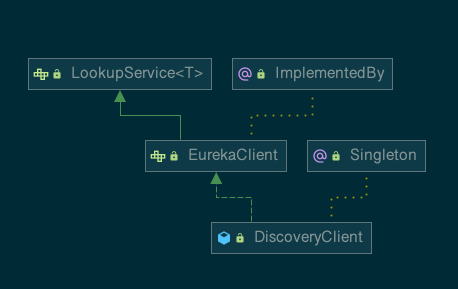
org.springframework.cloud.client.discovery.DiscoveryClient 是 SpringCloud 的接口, 它定义了用来发现服务的常用抽象方法, 通过该接口可以有效地 屏蔽服务治理的实现细节, 所以使用 SpringCloud 构建的微服务应用可以方便地切换不同服务治理框架, 而不改动程序代码, 只需要另外添加一些针对服务治理框架的配置即可。 org.springframework.cloud.netflix.eureka.EurekaDiscoveryClient 是对该接口的实现, 从命名来判断, 它实现的是对 Eureka 发现服务的封装。 所以 EurekaDiscoveryClient 依赖了 Netflix Eureka 的 com.netflix.discovery. EurekaClient 接口, EurekaClient 继承了 LookupService 接口, 它们都是 Netflix 开源包中的内容, 主要定义了针对 Eureka 的发现服务的抽象方法, 而真正实现发现服务的则是 Netflix 包中的 com.netftx.discovery.DiscoveryClient 类。
# 15.eureka 服务注册原理
服务提供者注册流程:
服务提供者(应用)在启动时,会通过 Eureka 客户端注册自己到 Eureka 服务器上。
在 Spring Boot 应用中,你会使用
@EnableDiscoveryClient注解来启用服务注册功能。Eureka 客户端会在应用启动时发送一个注册请求(HTTP POST 请求)到 Eureka 服务器的
/eureka/apps/接口,携带着服务实例的元数据,例如应用名称、主机地址、端口等。Eureka 服务器会将这些服务实例的信息存储在内部的注册表中,这样其他服务消费者就可以通过 Eureka 服务器发现这些服务实例。
关键类和方法:
com.netflix.discovery.EurekaClient: 这是 Eureka 客户端的核心类,用于与 Eureka 服务器通信,包括服务注册、发现、心跳等。com.netflix.appinfo.InstanceInfo: 表示一个服务实例的信息,包括应用名称、主机地址、端口、健康状态等。com.netflix.eureka.registry.AbstractInstanceRegistry.register(InstanceInfo instanceInfo, int leaseDuration, boolean isReplication): 这个方法用于在 Eureka 服务器上注册一个服务实例。instanceInfo参数包含了服务实例的信息,leaseDuration是租约时长,isReplication表示是否为复制操作。
注册过程要点:
服务注册是通过 HTTP 请求实现的。当服务提供者启动时,Eureka 客户端会向 Eureka 服务器发送一个 POST 请求,将服务实例信息注册到服务器上。
Eureka 客户端和服务器之间会通过心跳机制来保持通信。服务实例会周期性地向 Eureka 服务器发送心跳请求,以表明自己的健康状态。
Eureka 服务器会维护一个注册表,保存所有已注册的服务实例的信息。消费者可以向 Eureka 服务器查询服务实例信息。
Eureka 还提供了复制机制,以保证高可用性。不同的 Eureka 服务器之间可以相互复制注册信息,从而避免单点故障。
Eureka的实现原理,大概可以从这几个方面来看:
- 服务注册与发现: 当一个服务实例启动时,它会向 Eureka Server 发送注册请求,将自己的信息注册到注册中心。Eureka Server 会将这些信息保存在内存中,并提供 REST 接口供其他服务查询。服务消费者可以通过查询服务实例列表来获取可用的服务提供者实例,从而实现服务的发现。
- 服务健康检查: Eureka 通过心跳机制来检测服务实例的健康状态。服务实例会定期向 Eureka Server 发送心跳,也就是续约,以表明自己的存活状态。如果 Eureka Server 在一定时间内没有收到某个服务实例的心跳,则会将其标记为不可用,并从服务列表中移除,下线实例。
- 服务负载均衡: Eureka 客户端在调用其他服务时,会从本地缓存中获取服务的注册信息。如果缓存中没有对应的信息,则会向 Eureka Server 发送查询请求。Eureka Server 会返回一个可用的服务实例列表给客户端,客户端可以使用负载均衡算法选择其中一个进行调用。
# 16.DiscoveryClient
DiscoveryClient 是 Spring Cloud 中用于实现服务发现功能的一个核心接口。它定义了一组方法,允许应用程序在运行时从服务注册中心获取有关服务实例的信息,以便进行服务调用和负载均衡等操作。
在服务消费者应用中,你可以使用 DiscoveryClient 接口来发现和获取其他服务的实例信息。以下是 DiscoveryClient 的主要作用:
服务实例的发现:
DiscoveryClient允许你从服务注册中心(如 Eureka、Consul 等)获取注册的服务实例信息。通过查询注册中心,你可以获取特定服务名称的所有可用实例,以便在你的应用中进行服务调用。负载均衡: 通过查询
DiscoveryClient获取的服务实例列表,你可以实现基于负载均衡的服务调用。你可以根据一定的策略选择一个可用的服务实例进行请求,以分散负载并提高应用的性能和可靠性。获取元数据信息: 除了基本的主机和端口信息外,
DiscoveryClient通常还提供一些额外的元数据,如服务版本、标签、环境等。这些元数据可以帮助你更好地了解和使用服务实例。服务状态检查:
DiscoveryClient可以提供服务实例的健康状态信息,以帮助你进行服务实例的故障检测和故障隔离。动态更新: 注册中心中的服务实例信息可能会动态变化,例如服务实例的上线、下线、更新等。通过
DiscoveryClient,你可以及时获取这些变化,确保你的应用能够及时地适应服务拓扑的变化。
在 Spring Cloud 中,你可以使用 DiscoveryClient 接口的实现类来与不同的服务注册中心进行交互,例如使用 EurekaDiscoveryClient 来与 Eureka 服务器进行交互。
需要注意的是,Spring Cloud 还提供了更高级的抽象来简化服务发现和负载均衡的操作,例如使用 @LoadBalanced 注解和 RestTemplate 来实现负载均衡的 HTTP 调用。这些抽象可以在底层使用 DiscoveryClient 来实现服务发现。
# 17.eureka event
通过源码可以看到,注册,续约,取消都是通过事件机制来完成的。
# 18.什么是 consul?
Consul 是一个开源的分布式服务发现和配置管理系统,用于构建和管理微服务架构中的服务注册、发现、健康检查和配置。它由 HashiCorp 公司开发,旨在帮助解决微服务架构中的服务治理和配置管理问题。
Consul 提供了以下主要功能:
服务发现: Consul 允许服务在启动时注册自己到注册中心,同时也允许其他服务通过查询注册中心来发现可用的服务实例。这使得服务之间的通信可以更加动态和灵活。
健康检查: Consul 支持对服务实例进行健康检查,以确定它们是否正常运行。如果服务实例不健康,Consul 将不再将流量路由到该实例,从而提高系统的稳定性和可用性。
负载均衡: Consul 可以实现基于策略的负载均衡,将请求分发到可用的健康服务实例上,以平衡流量并提高性能。
分布式配置: Consul 允许将配置信息存储在中心化的键值存储中,并使多个服务实例可以共享和访问这些配置。这有助于实现配置的集中管理和更新。
多数据中心支持: Consul 支持多数据中心的架构,使得跨地理位置的服务可以进行发现和通信。
安全和加密: Consul 提供了一些安全功能,包括 ACL(访问控制列表)和支持 HTTPS 加密通信,以确保系统的安全性。
事件通知: Consul 可以发布服务状态变更等事件通知,让订阅的组件可以及时响应和处理。
Consul 通过客户端代理和服务器组成,客户端负责将服务注册、发现、健康检查等信息传递给服务器,而服务器则负责维护注册表、处理查询和协调各个组件之间的通信。
由于 Consul 自身提供了服务端,所以我们不需要像之前实现 Eureka 的时候创建服务注册中心,直接通过下载 consul 的服务端程序就可以使用。
# 19.consul 与 eureka 区别?
Consul 和 Eureka 都是用于实现服务发现和服务注册的工具,但它们在某些方面有一些区别。以下是 Consul 和 Eureka 的一些主要区别:
开发公司和社区:
- Consul 是 HashiCorp 公司开发的,是 HashiCorp 旗下的一个产品,拥有强大的背后技术支持和社区。
- Eureka 最初是由 Netflix 开发的,后来成为了 Spring Cloud 项目的一部分,它在 Spring 社区中得到广泛的支持。
功能丰富性:
- Consul 提供了更多的功能,包括服务发现、健康检查、分布式键值存储、多数据中心支持、安全加密等,适用于复杂的分布式系统架构。
- Eureka 主要关注服务发现和负载均衡,相对于 Consul,在其他领域的功能可能较少。
多数据中心支持:
- Consul 在设计之初就考虑了多数据中心的支持,并且在多数据中心的部署和通信方面表现出色。
- Eureka 也可以通过配置实现多数据中心的支持,但相比于 Consul,其多数据中心的功能较为有限。
服务健康检查:
- Consul 提供了更灵活和强大的健康检查机制,允许定义多种类型的健康检查,包括 HTTP、TCP、脚本等。
- Eureka 也支持健康检查,但其检查方式相对简单,通常使用 HTTP 请求。
部署复杂性:
- Consul 在部署方面相对较为复杂,需要额外的配置和组件,尤其在多数据中心和安全性方面。
- Eureka 的部署相对简单,特别适合在 Spring Cloud 环境下使用。
生态系统和集成:
- Eureka 更紧密地集成到 Spring Cloud 中,因此对于使用 Spring 框架的应用而言,集成和使用相对更加无缝。
- Consul 在生态系统方面也有很好的支持,但可能需要在一些情况下进行额外的配置和集成。
总的来说,Consul 适用于更复杂、多功能和多数据中心的分布式系统架构,而 Eureka 则更适合轻量级的微服务架构,特别是在 Spring Cloud 中。选择使用哪个取决于你的项目需求、技术栈和复杂性水平。
# 三.Ribbon 和 feign
# 1.什么是负载均衡?
负载均衡分为硬件负载均衡和软件负载均衡:
- 硬件负载均衡:比如 F5、深信服、Array 等;
- 软件负载均衡:比如 Nginx、LVS、HAProxy 等;
# 2.服务端负载均衡

# 3.什么是 Ribbon?
Ribbon 是 Netfliⅸ 公司发布的开源项目(组件、框架、jar 包),主要功能是提供客户端的软件负载均衡算法,它会从 eureka 中获取一个可用的服务端清单通过心跳检测来剔除故障的服务端节点以保证清单中都是可以正常访问的服务端节点。
当客户端发送请求,则 ribbon 负载均衡器按某种算法(比如轮询、权重、最小连接数等从维护的可用服务端清单中取出一台服务端的地址然后进行请求。
Ribbon 是一个基于 HTTP 和 TCP 客户端的负载均衡器。Ribbon 非常简单,可以说就是一个 jar 包,这个 jar 包实现了负载均衡算法,Spring Cloud 对 Ribbon 做了二次封装,可以让我们使用 RestTemplate 的服务请求,自动转换成客户端负载均衡的服务调用。
Ribbon 支持多种负载均衡算法,还支持自定义的负载均衡算法。
使用 Ribbon 实现负载均衡的调用(Spring Cloud -> 封装 ribbon + eureka + restTemplate)
Ribbon 默认是采用懒加载,即第一次访问时才会去创建 LoadBalanceClient,请求时间会很长。
而饥饿加载则会在项目启动时创建,降低第一次访问的耗时,通过下面配置开启饥饿加载:
ribbon:
eager-load:
enabled: true
clients: user
2
3
4
# 4.IRule 的作用?
自定义负载均衡的规则,其中轮训,权重,随机等负载均衡算法都是通过 IRule 的实现类来实现的。
//负载均衡的规则
public interface IRule {
Server choose(Object var1);
void setLoadBalancer(ILoadBalancer var1);
ILoadBalancer getLoadBalancer();
}
2
3
4
5
6
7
8
9
/**
* 自定义负载均衡
*/
@Bean
public IRule microIrule() {
return new RoundRobinRule(); //轮训
//return new RandomRule(); //随机
//return new BestAvailableRule();
//return new ZoneAvoidanceRule(); //新版本默认的策略
}
2
3
4
5
6
7
8
9
10
# 5.ILoadBalancer 的作用?
public interface ILoadBalancer {
void addServers(List<Server> var1);
Server chooseServer(Object var1);
void markServerDown(Server var1);
/** @deprecated */
@Deprecated
List<Server> getServerList(boolean var1);
List<Server> getReachableServers();
List<Server> getAllServers();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
一个服务对应一个 LoadBalancer,一个 LoadBalancer 只有一个 Rule,LoadBalancer 记录服务的注册地址,Rule 提供从服务的注册地址中找出一个地址的规则。
通过 LoadBalancerIntercepor 拦截器,可以拦截请求 url 和服务 id,然后结合 IRule 进行路由处理
# 6.负载均衡策略
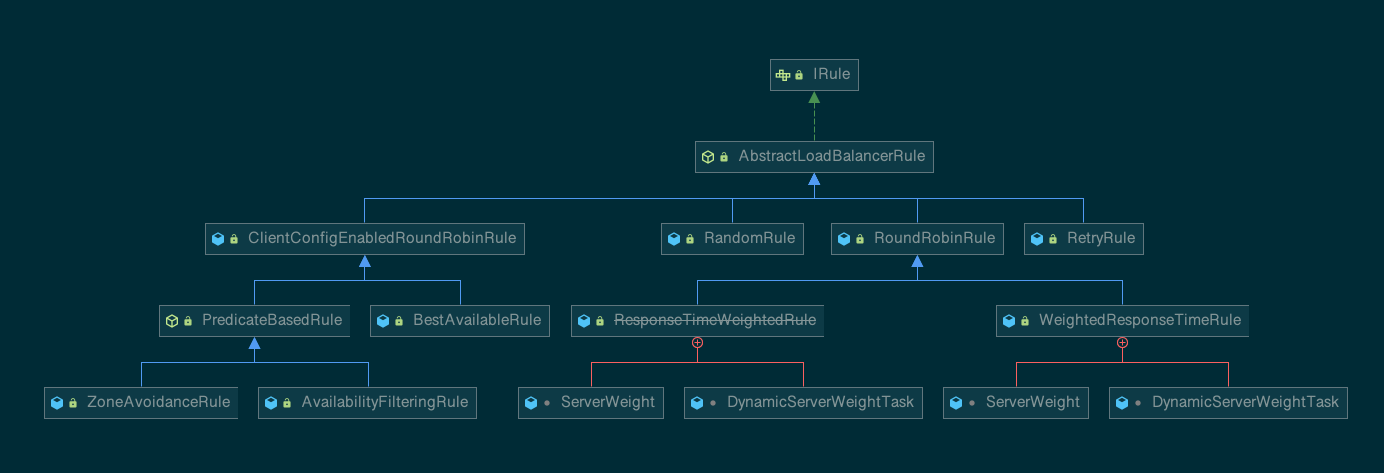
Ribbon 提供七种负载均衡策略,默认的负载均衡策略是轮训策略RoundRobinRule。
public class BaseLoadBalancer extends AbstractLoadBalancer implements PrimeConnectionListener, IClientConfigAware {
private static final IRule DEFAULT_RULE = new RoundRobinRule();
}
2
3
通过 choose 方法选择指定的算法。完整的算法包含如下:
| 策略名称 | 解释描述 |
|---|---|
| RandomRule | 随机算法实现 |
| RoundRobinRule | 默认策略,轮询负载均衡策略,依次轮询所有可用服务器列表 |
| RetryRule | 先按照 RoundRobinRule 策略获取服务,如果获取服务失败会在指定时间内重试 |
| AvaliabilityFilteringRule | 过滤掉那些因为一直连接失败的被标记为 circuit tripped 的后端 server,并过滤掉那些高并发的的后端 server(active connections 超过配置的阈值) |
| BestAvailableRule | 会先过滤掉由于多次访问故障二处于断路器跳闸状态的服务,然后选择一个并发量最小的服务 |
| WeightedResponseTimeRule | 根据响应时间分配一个 weight,响应时间越长,weight 越小,被选中的可能性越低 |
| ZoneAvoidanceRule | 复合判断 server 所在区域的性能和 server 的可用性选择 server,新版本默认的负载均衡策略 |
# 7.负载均衡底层原理
基本用法就是注入一个 RestTemplate,并使用 @LoadBalance 注解标注 RestTemplate,从而使 RestTemplate 具备负载均衡的能力。当 Spring 容器启动时,使用 @LoadBalanced 注解修饰的 RestTemplate 会被添加拦截器 LoadBalancerInterceptor,拦截器会拦截 RestTemplate 发送的请求,转而执行 LoadBalancerInterceptor 中的 intercept() 方法,并在 intercept() 方法中使用 LoadBalancerClient 处理请求,从而达到负载均衡的目的。
那么 RestTemplate 添加 @LoadBalanced 注解后,为什么会被拦截呢?
这是因为 LoadBalancerAutoConfiguration 类维护了一个被 @LoadBalanced 修饰的 RestTemplate 列表,在初始化过程中,通过调用 customizer.customize(restTemplate) 方法为 RestTemplate 添加了 LoadBalancerInterceptor 拦截器,该拦截器中的方法将远程服务调用的方法交给了 LoadBalancerClient 去处理,从而达到了负载均衡的目的。
@Configuration(
proxyBeanMethods = false
)
@ConditionalOnClass({RestTemplate.class})
@ConditionalOnBean({LoadBalancerClient.class})
@EnableConfigurationProperties({LoadBalancerRetryProperties.class})
public class LoadBalancerAutoConfiguration {
@LoadBalanced
@Autowired(
required = false
)
private List<RestTemplate> restTemplates = Collections.emptyList();
@Autowired(
required = false
)
private List<LoadBalancerRequestTransformer> transformers = Collections.emptyList();
public LoadBalancerAutoConfiguration() {
}
@Bean
public SmartInitializingSingleton loadBalancedRestTemplateInitializerDeprecated(final ObjectProvider<List<RestTemplateCustomizer>> restTemplateCustomizers) {
return () -> {
restTemplateCustomizers.ifAvailable((customizers) -> {
Iterator var2 = this.restTemplates.iterator();
while(var2.hasNext()) {
RestTemplate restTemplate = (RestTemplate)var2.next();
Iterator var4 = customizers.iterator();
while(var4.hasNext()) {
RestTemplateCustomizer customizer = (RestTemplateCustomizer)var4.next();
customizer.customize(restTemplate);
}
}
});
};
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
# 8.负载均衡流程

# 9.ribbon 组件有哪些?
主要有以下组件:
IRule,定义如何选择规则和策略IPing,接口定义了我们如何“ping”服务器检查是否活着ServerList,定义了获取服务器的列表接口,存储服务列表ServerListFilter,接口允许过滤配置或动态获得的候选列表服务器ServerListUpdater,接口使用不同的方法来做动态更新服务器列表IClientConfig,定义了各种 api 所使用的客户端配置,用来初始化 ribbon 客户端和负载均衡器,默认实现是 DefaultClientConfigImpl ILoadBalancer, 接口定义了各种软负载,动态更新一组服务列表及根据指定算法从现有服务器列表中选择一个服务
LoadBalancerClient 是 SpringCloud 提供的一种负载均衡客户端,LoadBalancerClient 在初始化时会通过 Eureka Client 向 Eureka 服务端获取所有服务实例的注册信息并缓存在本地,并且每 10 秒向 EurekaClient 发送“ ping ”(IPing 的作用),来判断服务的可用性。如果服务的可用性发生了改变或者服务数量和之前的不一致,则更新或者重新拉取。最后,在得到服务注册列表信息后,ILoadBalancer 根据 IRule 的策略进行负载均衡(默认策略为轮询)
# 10.@LoadBalanced 注解使用
@LoadBalanced
@Bean
public RestTemplate restTemplate() {
return new RestTemplate();
}
2
3
4
5
@LoadBalanced 注解和 RestTemplate 是 Spring Cloud 中用于实现客户端负载均衡的重要组件。通过结合使用这两个组件,你可以在微服务架构中实现负载均衡的效果。
RestTemplate 是 Spring 提供的用于进行 HTTP 请求的客户端工具,可以发送 HTTP 请求并处理响应。在微服务架构中,一个服务可能有多个实例运行,为了实现负载均衡,可以使用 RestTemplate 发送请求到同一个服务的不同实例上,从而分散请求负载。
然而,默认情况下,RestTemplate 并不具备负载均衡的能力,它会直接请求指定的目标地址,无法自动选择不同的实例。这时就需要使用 @LoadBalanced 注解来启用负载均衡功能。
@LoadBalanced 注解会为 RestTemplate 添加一个拦截器LoadBalancerInterceptor,它会在请求发送前根据服务名来选择一个可用的实例进行请求。这个选择过程是通过服务发现来实现的,具体步骤如下:
- 当
@LoadBalanced注解被应用到RestTemplate上时,Spring Cloud 会自动为其创建一个代理。 - 当你使用这个
RestTemplate发送请求时,代理会拦截请求,然后根据服务名去服务注册中心(例如 Eureka、Consul)查询可用的实例列表。 - 代理会根据负载均衡策略从可用实例列表中选择一个实例,然后将请求发送到该实例。
这样,通过结合 @LoadBalanced 注解和 RestTemplate,你可以轻松实现客户端负载均衡,将请求分发到不同的服务实例上,以达到平衡负载、提高性能和可用性的目的。
需要注意的是,Spring Cloud 默认使用的负载均衡策略是轮询(Round-Robin),但你也可以根据需求配置其他负载均衡策略,如随机、权重等。
# 11.@LoadBalanced 注解原理
@LoadBalanced注解,开启客户端的负载均衡主要依赖三个类:
LoadBalancerInterceptor拦截客户端请求LoadBalancerClient获取服务列表BaseLoadBalancer根据规则获取真实 ip 和 port
在负载均衡的过程中,是如何找到正确的请求地址的呢?
根据 service 名称,获取到了服务实例的 ip 和端口。它就是LoadBalancerInterceptor,这个类会在对RestTemplate的请求进行拦截,然后从 Eureka 根据服务 id 获取服务列表,随后利用负载均衡算法得到真实的服务地址信息,替换服务 id。
LoadBalancerInterceptor源码:
public class LoadBalancerInterceptor implements ClientHttpRequestInterceptor {
private LoadBalancerClient loadBalancer;
private LoadBalancerRequestFactory requestFactory;
public LoadBalancerInterceptor(LoadBalancerClient loadBalancer, LoadBalancerRequestFactory requestFactory) {
this.loadBalancer = loadBalancer;
this.requestFactory = requestFactory;
}
public LoadBalancerInterceptor(LoadBalancerClient loadBalancer) {
this(loadBalancer, new LoadBalancerRequestFactory(loadBalancer));
}
public ClientHttpResponse intercept(final HttpRequest request, final byte[] body, final ClientHttpRequestExecution execution) throws IOException {
URI originalUri = request.getURI();//获取请求地址
String serviceName = originalUri.getHost();//获取服务名称
Assert.state(serviceName != null, "Request URI does not contain a valid hostname: " + originalUri);
return (ClientHttpResponse)this.loadBalancer.execute(serviceName, this.requestFactory.createRequest(request, body, execution));
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
可以看到这里的 intercept 方法,拦截了用户的 HttpRequest 请求,然后做了几件事:
request.getURI():获取请求 uri,本例中就是 http://user-service/user/8originalUri.getHost():获取 uri 路径的主机名,其实就是服务 id,user-servicethis.loadBalancer.execute():处理服务 id,和用户请求。
LoadBalancerClient源码:
//默认实现是RibbonLoadBalancerClient
public <T> T execute(String serviceId, LoadBalancerRequest<T> request, Object hint) throws IOException {
//从注册中心获取服务列表
ILoadBalancer loadBalancer = this.getLoadBalancer(serviceId);
Server server = this.getServer(loadBalancer, hint);//获取实际ip和端口号
if (server == null) {
throw new IllegalStateException("No instances available for " + serviceId);
} else {
RibbonLoadBalancerClient.RibbonServer ribbonServer = new RibbonLoadBalancerClient.RibbonServer(serviceId, server, this.isSecure(server, serviceId), this.serverIntrospector(serviceId).getMetadata(server));
return this.execute(serviceId, (ServiceInstance)ribbonServer, (LoadBalancerRequest)request);
}
}
2
3
4
5
6
7
8
9
10
11
12
BaseLoadBalancer源码:
//默认是轮训算法
private static final IRule DEFAULT_RULE = new RoundRobinRule();
private static final String DEFAULT_NAME = "default";
public Server chooseServer(Object key) {
if (this.counter == null) {
this.counter = this.createCounter();
}
this.counter.increment();
if (this.rule == null) {
return null;
} else {
try {
return this.rule.choose(key);//在这里选择rule
} catch (Exception var3) {
logger.warn("LoadBalancer [{}]: Error choosing server for key {}", new Object[]{this.name, key, var3});
return null;
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 12.什么是 Feign?
Feign 是一个声明式的 Web Service 客户端,它使得编写 Web Serivce 客户端变得更加简单。我们只需要使用 Feign 来创建一个接口并用注解来配置它既可完成。它具备可插拔的注解支持,包括 Feign 注解和 JAX-RS 注解。Feign 也支持可插拔的编码器和解码器。Spring Cloud 为 Feign 增加了对 Spring MVC 注解的支持,还整合了 Ribbon 和 Eureka 来提供均衡负载的 HTTP 客户端实现。
Feign 在 Ribbon+RestTemplate 的基础上做了进一步封装,在 Feign 封装之后,我们只需创建一个接口并使用注解的方式来配置,即可完成对服务提供方的接口绑定简化了使用 Ribbon + RestTemplate 的调用,自动封装服务调用客户端。Feign 只是对 HTTP 调用组件进行了易用性封装,底层还是使用我们常见的 OkHttp、HttpClient 等组件。 Feign 的目标之一就让这些 HTTP 客户端更好用,使用方式更统一,更像 RPC。
Feign 中也使用 Ribbon,自动集成了 ribbon。
# 13.Feign 与 OpenFeign?
Feign:是 Spring Cloud 组件中一个轻量级 RESTful 的 HTTP 服务客户端,Feign 内置了 Ribbon,用来做客户端负载均衡,去调用服务注册中心的服务。Feign 的使用方式是:使用 Feign 的注解定义接口,调用接口,就可以调用服务注册中心的服务。
1 <dependency>
2 <groupId>org.springframework.cloud</groupId>
3 <artifactId>spring-cloud-starter-feign</artifactId>
4 </dependency>
2
3
4
OpenFeign:是 Spring Cloud 在 Feign 的基础上支持了 SpringMVC 的注解,如@RequestMapping 等等。OpenFeign 的@FeignClient 可以解析 SpringMVC 的@RequestMapping 注解下的接口,并通过动态代理的方式产生实现类,实现类中.
1 <dependency>
2 <groupId>org.springframework.cloud</groupId>
3 <artifactId>spring-cloud-starter-openfeign</artifactId>
4 </dependency>
2
3
4
说明: springcloud F 及 F 版本以上 springboot 2.0 以上基本上使用 openfeign,openfeign 如果从框架结构上看就是 2019 年 feign 停更后出现版本,也可以说大多数新项目都用 openfeign ,2018 年以前的项目在使用 feign
# 14.FeignClient 幂等性
Retryer 是重试器,其实现方法有两种,第一种是系统默认实现方式,第二种是可以自定义重试器,一般少用,通过默认实现重试类 Default 可以看到其构造函数中的重试次数为 5。
public Default() {
this(100, SECONDS.toMillis(1), 5);
}
public Default(long period, long maxPeriod, int maxAttempts) {
this.period = period;
this.maxPeriod = maxPeriod;
this.maxAttempts = maxAttempts;
this.attempt = 1;
}
2
3
4
5
6
7
8
9
10
因此解决 Feign 调用的幂等性问题最简单也就最常用的就是让 Feign 不重试。
# 15.ip 不能访问
使用了@LoadBalanced 注解后不能再使用 192.168.28.1(ip)调用,必须要使用注册中心中注册的服务名称
所以在使用 RestTemplate 的时候,有些场景下我们只是单纯的用 ip 进行调用(如调用第三方接口服务),此时的 RestTemplate 就不能够加@LoadBanlanced 注解。还有一种办法是直接在需要使用 RestTemplate 的地方,直接 new 一个新的 RestTemplate 对象。如下
public void test(){
RestTemplate restTemplate = new RestTemplate();
//这里的接口地址就可以直接放协议+ip+端口,原理与上面一样
restTemplate.exchange("接口地址",xxx,xxx,xxx);
}
2
3
4
5
# 16.feign 超时
Spring Cloud 中 Feign 客户端是默认开启支持 Ribbon 的,最重要的两个超时就是连接超时 ConnectTimeout 和读超时 ReadTimeout,在默认情况下,也就是没有任何配置下,Feign 的超时时间会被 Ribbon 覆盖,两个超时时间都是 1 秒。
#ribbon配置
ribbon:
#建立连接超时时间
ConnectTimeout: 5000
#建立连接之后,读取响应资源超时时间
ReadTimeout: 5000
#Feign配置
feign:
client:
config:
#这里填具体的服务名称(也可以填default,表示对所有服务生效)
app-order:
#connectTimeout和readTimeout这两个得一起配置才会生效
connectTimeout: 5000
readTimeout: 5000
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 17.feign 流程与原理
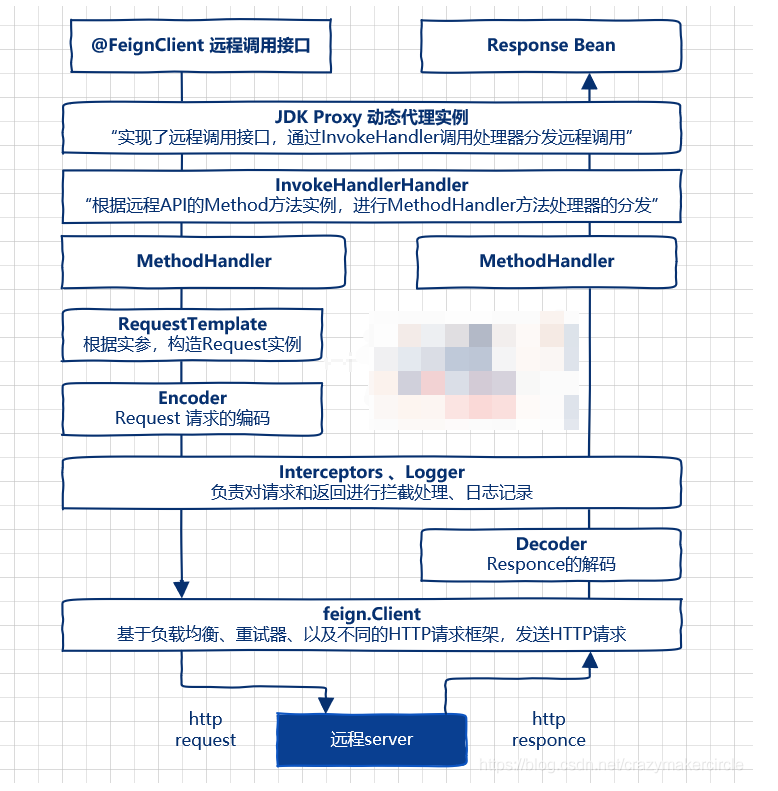
从下图可以看到,Feign 通过处理注解,将请求模板化,当实际调用的时候,传入参数,根据参数再应用到请求上,进而转化成真正的 Request 请求。通过 Feign 以及 JAVA 的动态代理机制,使得 Java 开发人员,可以不用通过 HTTP 框架去封装 HTTP 请求报文的方式,完成远程服务的 HTTP 调用。
在微服务启动时,Feign 会进行包扫描,对加@FeignClient注解的接口,按照注解的规则,创建远程接口的本地 JDK Proxy 代理实例。然后,将这些本地 Proxy 代理实例,注入到 Spring IOC 容器中。当远程接口的方法被调用,由 Proxy 代理实例去完成真正的远程访问,并且返回结果。
# 18.InvocationHandler
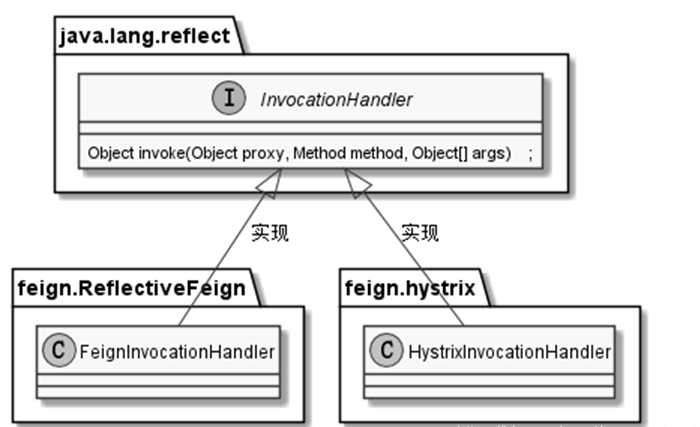
通过 JDK Proxy 生成动态代理类,核心步骤就是需要定制一个调用处理器,具体来说,就是实现 JDK 中位于 java.lang.reflect 包中的 InvocationHandler 调用处理器接口,并且实现该接口的 invoke() 抽象方法。
为了创建 Feign 的远程接口的代理实现类,Feign 提供了自己的一个默认的调用处理器,叫做 FeignInvocationHandler 类,该类处于 feign-core 核心 jar 包中。当然,调用处理器可以进行替换,如果 Feign 与 Hystrix 结合使用,则会替换成 HystrixInvocationHandler 调用处理器类,类处于 feign-hystrix 的 jar 包中。
默认的调用处理器 FeignInvocationHandler 是一个相对简单的类,有一个非常重要 Map 类型成员 dispatch 映射,保存着远程接口方法到 MethodHandler 方法处理器的映射。
# 19.FeignInvocationHandler
//FeignInvocationHandler是ReflectiveFeign的内部类
static class FeignInvocationHandler implements InvocationHandler {
private final Target target;
private final Map<Method, MethodHandler> dispatch;//缓存方法映射
FeignInvocationHandler(Target target, Map<Method, MethodHandler> dispatch) {
this.target = (Target)Util.checkNotNull(target, "target", new Object[0]);
this.dispatch = (Map)Util.checkNotNull(dispatch, "dispatch for %s", new Object[]{target});
}
//关键方法,实际执行的方法
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
if (!"equals".equals(method.getName())) {
if ("hashCode".equals(method.getName())) {
return this.hashCode();
} else {
return "toString".equals(method.getName()) ? this.toString() : ((MethodHandler)this.dispatch.get(method)).invoke(args);
}
} else {
try {
Object otherHandler = args.length > 0 && args[0] != null ? Proxy.getInvocationHandler(args[0]) : null;
return this.equals(otherHandler);
} catch (IllegalArgumentException var5) {
return false;
}
}
}
public boolean equals(Object obj) {
if (obj instanceof ReflectiveFeign.FeignInvocationHandler) {
ReflectiveFeign.FeignInvocationHandler other = (ReflectiveFeign.FeignInvocationHandler)obj;
return this.target.equals(other.target);
} else {
return false;
}
}
public int hashCode() {
return this.target.hashCode();
}
public String toString() {
return this.target.toString();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
# 20.RestTemplate 源码
执行 doExecute 方法,封装 http 请求,构造 ClientHttpRequest,然后执行 execute 方法。
@Nullable
protected <T> T doExecute(URI url, @Nullable HttpMethod method, @Nullable RequestCallback requestCallback, @Nullable ResponseExtractor<T> responseExtractor) throws RestClientException {
Assert.notNull(url, "URI is required");
Assert.notNull(method, "HttpMethod is required");
ClientHttpResponse response = null;
Object var14;
try {
ClientHttpRequest request = this.createRequest(url, method);
if (requestCallback != null) {
requestCallback.doWithRequest(request);
}
response = request.execute();
this.handleResponse(url, method, response);
var14 = responseExtractor != null ? responseExtractor.extractData(response) : null;
} catch (IOException var12) {
String resource = url.toString();
String query = url.getRawQuery();
resource = query != null ? resource.substring(0, resource.indexOf(63)) : resource;
throw new ResourceAccessException("I/O error on " + method.name() + " request for \"" + resource + "\": " + var12.getMessage(), var12);
} finally {
if (response != null) {
response.close();
}
}
return var14;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
# 21.OpenFeign 源码分析
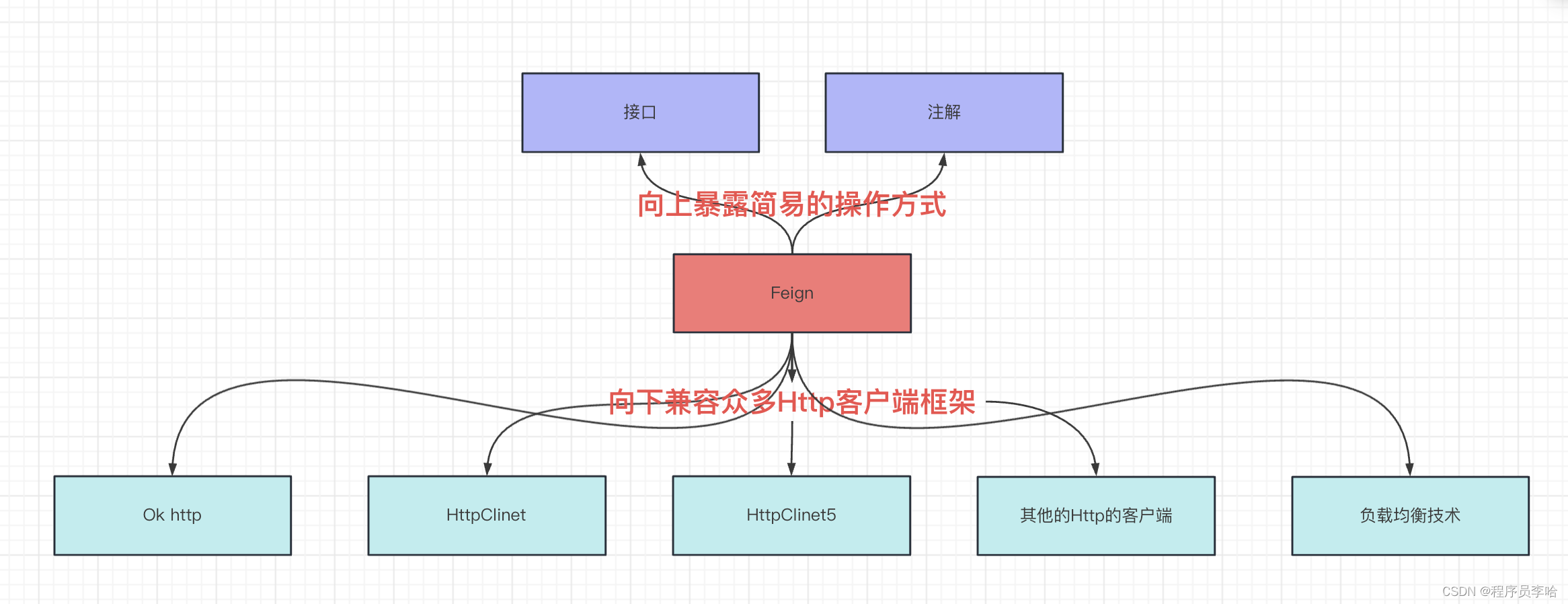
简化 Http 客户端的操作,兼容众多 Http 客户端框架,向上暴露出接口+注解+配置的简易操作方式。
//@EnableFeignClients注解
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.TYPE)
@Documented
@Import(FeignClientsRegistrar.class)
public @interface EnableFeignClients {
2
3
4
5
6
此注解配合@Configuration 注解一起使用,一般是配合@SpringBootApplication 注解(也是一个@Configuration)使用,而@EnableFeignClients 注解又使用了@Import 注解。所以需要找到 FeignClientsRegistrar 类的 registerBeanDefinitions 回掉方法。
class FeignClientsRegistrar implements ImportBeanDefinitionRegistrar, ResourceLoaderAware, EnvironmentAware {
@Override
public void registerBeanDefinitions(AnnotationMetadata metadata, BeanDefinitionRegistry registry) {
registerDefaultConfiguration(metadata, registry);
registerFeignClients(metadata, registry);
}
public void registerFeignClients(AnnotationMetadata metadata, BeanDefinitionRegistry registry) {
LinkedHashSet<BeanDefinition> candidateComponents = new LinkedHashSet<>();
Map<String, Object> attrs = metadata.getAnnotationAttributes(EnableFeignClients.class.getName());
final Class<?>[] clients = attrs == null ? null : (Class<?>[]) attrs.get("clients");
// 扫描当前目录下所有的@FeignClient类。
if (clients == null || clients.length == 0) {
ClassPathScanningCandidateComponentProvider scanner = getScanner();
scanner.setResourceLoader(this.resourceLoader);
scanner.addIncludeFilter(new AnnotationTypeFilter(FeignClient.class));
Set<String> basePackages = getBasePackages(metadata);
for (String basePackage : basePackages) {
candidateComponents.addAll(scanner.findCandidateComponents(basePackage));
}
}
else {
for (Class<?> clazz : clients) {
candidateComponents.add(new AnnotatedGenericBeanDefinition(clazz));
}
}
// 遍历当前目录下所有的@FeignClient类生成的BeanDefinition
for (BeanDefinition candidateComponent : candidateComponents) {
if (candidateComponent instanceof AnnotatedBeanDefinition) {
// verify annotated class is an interface
AnnotatedBeanDefinition beanDefinition = (AnnotatedBeanDefinition) candidateComponent;
AnnotationMetadata annotationMetadata = beanDefinition.getMetadata();
Assert.isTrue(annotationMetadata.isInterface(), "@FeignClient can only be specified on an interface");
Map<String, Object> attributes = annotationMetadata
.getAnnotationAttributes(FeignClient.class.getCanonicalName());
String name = getClientName(attributes);
registerClientConfiguration(registry, name, attributes.get("configuration"));
// 给当前目录下所有的@FeignClient类生成的BeanDefinition添加Feign动态代理后的代理Class
registerFeignClient(registry, annotationMetadata, attributes);
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
Spring Cloud Openfein 的核心原理大致就在这里了,所以对以上做个总结:
- 使用
@EnableFeignClients注解,Spring 底层会解析@Import注解,最终会回掉registerBeanDefinitions方法,此方法中调用registerFeignClients registerFeignClients方法中会去扫描当前路径下所有的类,如果类上带有@FeignClient注解就会生成BeanDefition。- 遍历所有带有@FeignClient 注解的类,反射拿到
@FeignClient注解的元数据信息,然后调用registerFeignClient方法 registerFeignClient方法会解析带有@FeignClient注解元数据信息当作燃料往 Feign 里面填充,然后 Feign 会去动态代理创建出带有@FeignClient注解的类的动态代理类。
# 22.为什么 Feign 第一次调用耗时很长?
主要原因是由于 Ribbon 的懒加载机制,当第一次调用发生时,Feign 会触发 Ribbon 的加载过程,包括从服务注册中心获取服务列表、建立连接池等操作,这个加载过程会增加首次调用的耗时。
ribbon:
eager-load:
enabled: true
clients: service-1
2
3
4
那怎么解决这个问题呢?
可以在应用启动时预热 Feign 客户端,自动触发一次无关紧要的调用,来提前加载 Ribbon 和其他相关组件。这样,就相当于提前进行了第一次调用。
# 四.hystrix
# 1.什么是 Hystrix?
在 Spring Cloud 中使用了 Hystrix 来实现断路器的功能。Hystrix 是 Netflix 开源的微服务框架套件之一,该框架目标在于通过控制那些访问远程系统、服务和第三方库的节点,从而对延迟和故障提供更强大的容错能力。Hystrix 具备拥有回退机制和断路器功能的线程和信号隔离,请求缓存和请求打包,以及监控和配置等功能。
Hystrix 原理是命令模式,在遇到不同的情况下,请求 fallback,降级处理
@Target({ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
@EnableCircuitBreaker
public @interface EnableHystrix {
}
2
3
4
5
6
7
# 2.Hystrix 有哪些功能?
Hystrix 是 Netflix 开源的一款用于构建容错和弹性的库,主要用于分布式系统中处理服务之间的故障和延迟问题。它提供了许多功能来帮助开发人员实现容错和弹性策略。以下是 Hystrix 的一些主要功能:
断路器模式(Circuit Breaker Pattern):Hystrix 实现了断路器模式,可以在服务调用失败或延迟超过阈值时自动断开服务调用。这可以防止不稳定的服务影响整个系统。
降级策略(Fallback):Hystrix 可以为服务定义降级策略,当主要服务不可用时,自动切换到备用的降级逻辑,以保证系统的基本功能可用。
超时控制:Hystrix 可以设置请求的超时时间,如果请求在指定时间内未完成,Hystrix 将自动终止请求并执行降级逻辑。
请求缓存:Hystrix 可以对相同的请求进行缓存,从而减少重复请求,提高性能。
请求合并和并发控制:Hystrix 可以自动合并相同类型的请求,从而减少对后端服务的并发请求。它还提供了并发请求的控制,以防止过多的请求同时访问服务。
实时监控和指标收集:Hystrix 提供了实时的监控面板,可以查看各个服务的健康状态、断路器状态、请求量等指标。这对于系统的可视化监控和故障排查非常有帮助。
自动恢复:当断路器打开一段时间后,Hystrix 可以尝试自动地关闭断路器并重新尝试请求,以便检测服务是否已经恢复正常。
线程隔离和资源隔离:Hystrix 通过线程池隔离和信号量隔离来控制对服务的访问。这可以防止一个故障的服务影响到整个系统。
自定义配置:Hystrix 允许开发人员根据具体的业务场景进行自定义配置,以满足不同的容错和弹性需求。
Hystrix 提供了一套强大的工具和策略,帮助构建稳定、可靠的分布式系统,在面对故障和延迟时能够更加优雅地处理和适应。
# 3.Hystrix 超时配置
#开启feign开启hystrix的支持
feign:
hystrix:
enabled: true
hystrix:
command:
default:
execution:
isolation:
thread:
timeoutInMilliseconds: 5000 #hystrix超时时间
timeout:
enabled: true #开启hystrix超时管理
ribbon:
ReadTimeout: 2000 #请求超时时间
http:
client:
enabled: true #开启ribbon超时管理
ConnectTimeout: 2000 #连接超时时间
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
Dalston版本之后默认关闭,注意开启 feign 的hystrix的功能ribbon和hystrix都要设置,谁小以谁为准
# 4.断路器的作用
- 防止单个服务的故障导致器依赖和相关的服务容器的线程资源被耗尽:
- 减少负载,并负责通过请求的快速失败功能而不是让请求进行排队.
- 尽可能提供服务降级的功能,以免用户免受故障影响
- 使用隔离技术来限制某个服务出现问题所带来的影响
- 尽可能提供实时监控信息,提供监控和警报来优化发现故障的时间
- 允许使用配置修改相关的参数(如请求超时时可以触发熔断)
- 对服务调用消费者内部的故障进行保护,而不仅仅是在网络流量上进行保护降级,限流
一个简单的场景就是家里的保险丝,当电流过大时保险丝熔断,使得家里的其他电器不至于造成大规模的损坏。 在微服务中,当大量请求到达产品微服务,这会导致其服务响应变得缓慢,或者因为内存不足等原因使得服务器出现宕机或者数据库出现问题。
另一个原因,当一个微服务中有很多请求时,会导致他调用其他微服务的时候(正常的服务线程)造成积压,产生雪崩。
# 5.熔断降级
- 可以监听你的请求有没有超时;(默认是 1 秒,时间可以改)
- 异常或报错了可以快速让请求返回,不会一直等待;(避免线程累积)
- 当的系统马上迎来大量的并发(双十一秒杀这种或者促销活动)
此时如果系统承载不了这么大的并发时,可以考虑先关闭一些不重要的微服务(在降级方法中返回一个比较友好的信息),把资源让给核心微服务,待高峰流量过去,再开启回来。
# 6.服务限流
通过 2 种方式进行限流
线程数限制信号量限制
限流配置,通过限制线程数进行限流,限流就是限制你某个微服务的使用量(可用线程),
hystriⅸ 通过线程池的方式来管理微服务的调用,它默认是一个线程池(大小 10 个)管理你的所有微服务,你可以给某个微服务开辟新的线程池.
@HystrixCommand(
fallbackMethod = "addServiceFallback",
commandProperties = {
@HystrixProperty(name = "execution.timeout.enabled", value = "true"),
@HystrixProperty(name = "execution.isolation.thread.timeoutInMilliseconds", value = "6000")
},
threadPoolProperties = {
@HystrixProperty(name = "coreSize", value = "2"),
@HystrixProperty(name = "maxQueueSize", value = "1"),
@HystrixProperty(name = "keepAliveTimeMinutes", value = "2"),
@HystrixProperty(name = "queueSizeRejectionThreshold", value = "100")
}
)
2
3
4
5
6
7
8
9
10
11
12
13
commandProperties可以配置 hystrix 的各种配置threadPoolProperties属性用于控制线程池的行为,要求为我们建立一个大小为 coreSize 的,且在之前创建一个队列的线程池,队列大小为 maxQueueSize 对应的 value 的值
这个队列的作用是:控制在线程池中线程繁忙时允许堵塞的请求数(即 value 值),一旦请求数超过了队列大小,对线程池的任何请求都将失败,直到队列中有空间为止。此外,对于 maxQueueSize 的值也有说明,当 value=-1 时,则将使用 Java SynchronousQueue 来保存所有传入的请求,同步队列本质上会强制要求正在处理中的请求数量永远不要超过线程池中的可用数量;将 maxQueueSize 设置为大于 1 的值将导致 Hystrix 使用 Java LinkedBlockingQueue。这使得即使所有的线程都忙于处理请求,也能对请求进行排队。
# 7.commandProperties
commandProperties 是 Hystrix 中用于配置命令(Command)的属性集合。在 Hystrix 中,一个命令代表着一个需要进行容错和弹性处理的操作,通常是对一个远程服务的调用。commandProperties 允许您通过设置不同的属性来控制命令的行为和策略。以下是一些常见的 commandProperties 属性及其含义:
execution.isolation.strategy:配置命令的隔离策略,可以是线程池隔离(
THREAD)或信号量隔离(SEMAPHORE)。线程池隔离会将命令的执行放在独立的线程池中,而信号量隔离则会通过信号量来控制并发访问。execution.isolation.thread.timeoutInMilliseconds:设置命令执行的超时时间,超过此时间将触发降级逻辑。
circuitBreaker.enabled:是否启用断路器模式,如果启用,当命令失败率达到一定阈值时,断路器将打开,后续请求将自动触发降级逻辑。
circuitBreaker.requestVolumeThreshold:断路器在打开之前要求的最小请求数。例如,设置为 20 表示前 20 个请求将用于判断是否应该打开断路器。
circuitBreaker.sleepWindowInMilliseconds:断路器打开后的休眠时间窗口,在此期间所有请求都将被快速失败,以检查服务是否恢复正常。
circuitBreaker.errorThresholdPercentage:断路器打开的错误率阈值。例如,设置为 50 表示当错误率达到 50% 时,断路器将打开。
metrics.rollingStats.timeInMilliseconds:指定滚动统计窗口的时间长度,用于计算错误率、请求量等指标。
metrics.rollingStats.numBuckets:指定滚动统计窗口中的桶数,用于细分统计。
fallback.isolation.semaphore.maxConcurrentRequests:如果使用信号量隔离,此属性可以设置在降级逻辑中允许的最大并发请求数。
requestCache.enabled:是否启用请求缓存,启用后相同的请求将从缓存中获取结果,而不再执行实际的命令。
requestLog.enabled:是否启用请求日志,启用后会记录每个命令的执行情况。
# 8.threadPoolProperties
threadPoolProperties = {
@HystrixProperty(name = "coreSize",value = "2"),
@HystrixProperty(name = "allowMaximumSizeToDivergeFromCoreSize",value="true"),
@HystrixProperty(name = "maximumSize",value="2"),
@HystrixProperty(name = "maxQueueSize",value="2")
},
2
3
4
5
6
在 Hystrix 中,threadPoolProperties 是用于配置线程池的属性集合。线程池用于执行 Hystrix 命令(Command)的任务,使得这些任务可以在独立的线程中运行,从而实现隔离和并发控制。通过配置 threadPoolProperties,您可以调整线程池的行为以满足应用的容错和弹性需求。以下是一些常见的 threadPoolProperties 属性及其含义:
coreSize:线程池的核心线程数,表示线程池中保持的活动线程数量。这些线程会一直存在,不会被回收。
maximumSize:线程池的最大线程数,表示线程池中允许的最大线程数量。当队列满了且已有的线程数小于最大线程数时,新的任务会创建新的线程。
maxQueueSize:线程池的队列大小,表示线程池中可以容纳等待执行的任务的队列大小。如果任务超过队列大小,新的任务将被拒绝。
queueSizeRejectionThreshold:如果设置了
maxQueueSize,此属性表示队列中允许的最大任务数。当等待队列中的任务数量达到此阈值时,新的任务将被拒绝。keepAliveTimeMinutes:当线程池中的线程数超过核心线程数时,多余的线程在空闲一段时间后会被销毁,此属性指定了空闲时间。
allowMaximumSizeToDivergeFromCoreSize:是否允许线程池的最大线程数超过核心线程数。如果设置为 true,线程池可以动态地增加或减少线程数以适应负载。
metrics.rollingStats.timeInMilliseconds:指定滚动统计窗口的时间长度,用于计算线程池的指标,如线程池的活动线程数、队列大小等。
metrics.rollingStats.numBuckets:指定滚动统计窗口中的桶数,用于细分统计。
这些属性可以帮助您在 Hystrix 中配置线程池,以控制并发执行的任务数量、等待队列的大小以及线程的生命周期等。适当的线程池配置可以提高系统的性能、稳定性和容错能力。当然,线程池的配置需要根据具体的应用场景和系统特点进行调整。
# 9.常用限流方式?
- Nginx 限流 基础
- Sentinel 限流 主流
- Hystriⅸ 限流
- Redis+Lua 限流
- Apisix 限流
# 10.限流算法
限流是一种重要的分布式系统设计策略,用于控制系统的请求流量,防止过载和资源耗尽。以下是一些常用的限流方式:
令牌桶算法(Token Bucket Algorithm):在令牌桶中,固定数量的令牌以固定的速率被放入桶中。每当有请求到达时,需要获取一个令牌,如果桶中没有足够的令牌,则请求被拒绝。这个算法允许短期突发流量,但是可以通过调整放入令牌的速率来平滑流量。
漏桶算法(Leaky Bucket Algorithm):类似于令牌桶算法,漏桶也有固定的容量,但是请求以恒定的速率被处理。如果请求到达时桶已满,则请求被拒绝。漏桶算法可以用于平滑流量和控制请求速率。
计数器算法:在一段时间内计数请求的数量,如果数量超过了设定的阈值,则请求被拒绝。这种方法简单直接,但可能无法应对突发流量。
滑动窗口算法:将一段时间划分为多个时间窗口,每个窗口内记录请求的数量。通过不断滑动时间窗口,可以统计不同时间段内的请求频率,从而进行限流。
基于队列的限流:将请求放入队列中进行排队,当队列满了时,后续的请求被拒绝。这种方法可以平滑流量,但需要注意队列的大小和性能。
动态限流:根据系统的负载、资源使用情况等动态地调整限流策略。例如,根据服务器的 CPU 使用率、内存占用等情况自动调整请求速率。
分布式限流:将限流策略扩展到多个服务节点,确保整个系统都能受益于限流。分布式限流可以使用共享的令牌桶或漏桶,或者使用集中式的限流服务。
这些限流方式可以根据实际需求和系统特点进行选择和组合。限流是保护系统稳定性和可用性的重要手段,可以防止恶意攻击、突发流量以及资源耗尽等问题。在选择限流策略时,需要综合考虑系统的负载、性能、资源消耗等多个因素。
# 11.熔断器什么场景下会失效
- feign 未开启 hystrix 功能
- 超时时间配置不正确
- 未开启熔断器的功能,false
- 超时时间没有考虑 ribbon 的情况
# 12.hystrix Dashboard?
Hystrix Dashboard 是一个用于监控 Hystrix 断路器和依赖服务的仪表板。它提供了一个实时的可视化界面,可以让您更直观地查看系统中各个 Hystrix 命令的执行情况、断路器状态、请求量、错误率等指标。通过 Hystrix Dashboard,您可以实时地监控系统的健康状况,及时发现和解决潜在的问题,从而提高系统的稳定性和可靠性。
一般来说,Hystrix Dashboard 会显示以下内容:
实时状态监控:您可以看到每个 Hystrix 命令的实时状态,包括成功、失败、超时等情况。这有助于了解每个命令的执行情况。
断路器状态:您可以看到每个断路器的状态,包括打开、关闭、半开等状态。这有助于判断系统是否正在处理过载或故障情况。
请求量和响应时间:您可以看到每个命令的请求量以及平均响应时间。这有助于了解系统的负载情况和性能状况。
错误率:您可以查看每个命令的错误率,帮助您发现问题并及时采取措施。
熔断情况:您可以监控断路器是否打开以及打开的原因,从而了解系统的容错和恢复情况。
为了使用 Hystrix Dashboard,您需要在项目中引入 Hystrix Dashboard 依赖,并将相应的监控数据暴露出来。监控数据通常会通过 JMX 或者 HTTP 等方式被 Hystrix Dashboard 获取并展示在界面上。
# 13.Dashboard 使用
#监控链接
http://localhost:8080/hystrix.stream
http://localhost:8080/actuator/hystrix.stream
#请求下hystrix的接口
http://localhost:8080/portal/hystrix/1
2
3
4
5
6

#访问链接
http://localhost:9909/hystrix
2
portal中需要加入
@Bean
public ServletRegistrationBean getServlet() {
HystrixMetricsStreamServlet streamServlet = new HystrixMetricsStreamServlet();
ServletRegistrationBean registrationBean = new ServletRegistrationBean(streamServlet);
registrationBean.setLoadOnStartup(1);
registrationBean.addUrlMappings("/hystrix.stream");
registrationBean.setName("HystrixMetricsStreamServlet");
return registrationBean;
}
2
3
4
5
6
7
8
9
dashboard中需要加入
hystrix:
dashboard:
proxy-stream-allow-list: "localhost"
2
3
# 14.仪表盘解读
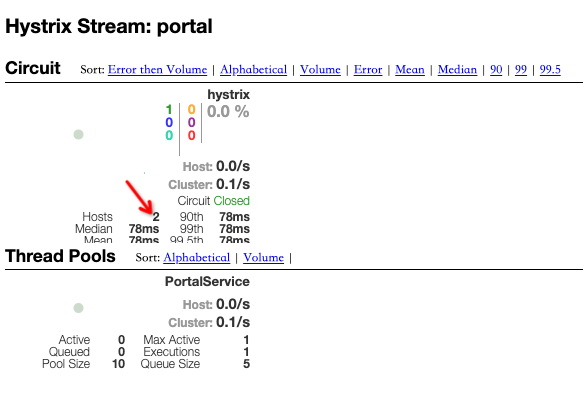
实心圆:共有两种含义。它通过颜色的变化代表了实例的健康程度该实心圆除了
颜色的变化之外,它的大小也会根据实例的请求流量发生变化,流量越大该实心圆就越大。所以通过该实心圆的展示,就可以在大量的实例中快速的发现故障实例和高压力实例。曲线:用来记录 2 分钟内流量的相对变化,可以通过它来观察到流量的上升和下降趋势。
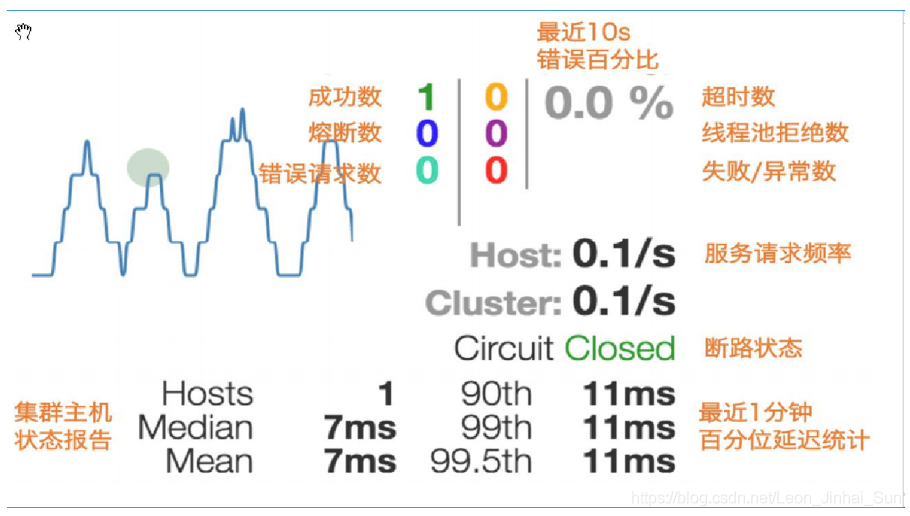
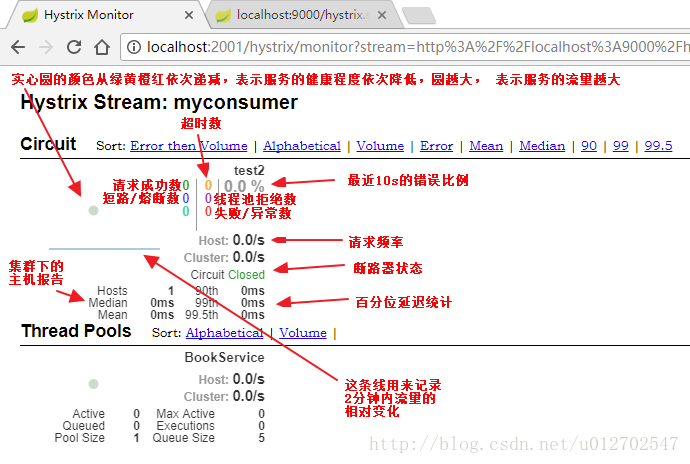
右上角的计数器(三列数字):
第一列从上到下
绿色代表当前成功调用的数量
蓝色代表短路请求的数量
蓝绿色代表错误请求的数量
第二列从上到下
黄色代表超时请求的数量
紫色代表线程池拒绝的数量
红色代表失败请求的数量
第三列
- 过去 10s 的错误请求百分比
Thread Pools:
Hystrix 会针对一个受保护的类创建一个对应的线程池,这样做的目的是 Hystrix 的命令被调用的时候,不会受方法请求线程的影响(或者说 Hystrix 的工作线程和调用者线程相互之间不影响)
左下角从上至下
Active代表线程池中活跃线程的数量Queued代表排队的线程数量,该功能默认禁止,因此默认情况下始终为 0Pool Size代表线程池中线程的数量
右下角从上至下
Max Active代表最大活跃线程,这里展示的数据是当前采用周期中,活跃线程的最大值Execcutions代表线程池中线程被调用执行 Hystrix 命令的次数Queue Size代表线程池队列的大小,默认禁用,无意义
# 15.turbine 的作用
Turbine 是 Netflix 开源的一个用于聚合多个 Hystrix Dashboard 的工具,它主要用于监控分布式系统中的断路器状态和依赖服务的健康状况。通过 Turbine,您可以将多个微服务的 Hystrix Dashboard 数据集中到一个统一的仪表板中,从而更方便地进行分布式系统的监控和故障排查。
Turbine 的主要作用包括:
集中式监控:在分布式系统中,可能会有多个微服务使用 Hystrix 断路器进行容错处理。使用 Turbine,您可以将这些微服务的断路器数据集中到一个统一的监控仪表板中,从而实现集中式的监控和管理。
实时聚合:Turbine 可以实时地聚合多个微服务的 Hystrix 数据,包括断路器状态、请求量、错误率等指标。这有助于您更方便地了解整个系统的健康状况。
统一视图:通过 Turbine,您可以在一个单独的仪表板上同时查看多个微服务的断路器状态,而无需逐个访问每个微服务的 Hystrix Dashboard。
快速发现问题:通过 Turbine,您可以更快地发现系统中的故障和问题,从而及时采取措施进行修复,提高系统的稳定性和可靠性。
降低维护成本:Turbine 可以帮助减少维护多个 Hystrix Dashboard 的成本,通过集中管理和监控,简化了监控系统的架构。
# 16.turbine 使用
http://localhost:8081/portal/hystrix/1
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-turbine</artifactId>
</dependency>
2
3
4
@EnableTurbine
@EnableEurekaClient
@EnableHystrixDashboard
@SpringBootApplication
public class HystrixTurbineApplication {
public static void main(String[] args) {
SpringApplication.run(HystrixTurbineApplication.class, args);
}
}
2
3
4
5
6
7
8
9

#端口号
server:
port: 9999
spring:
application:
name: hystrix-turbine-service #服务名称
#服务提供者
eureka:
client:
service-url:
defaultZone: http://eureka8767:8767/eureka/,http://eureka8768:8768/eureka/,http://eureka8769:8769/eureka/
instance:
lease-renewal-interval-in-seconds: 2 #每间隔2s,向服务端发送一次心跳,证明自己依然"存活”
lease-expiration-duration-in-seconds: 10 #告诉服务端,如果我10s之内没有给你发心跳,就代表我故障了,将我踢出掉
prefer-ip-address: true #告诉服务端,服务实例以IP作为链接,而不是取机器名
instance-id: springcloud-service-turbine-9999 #告诉服务端,服务实例的id,id要是唯一的
# 开启Feign对Hystrix的支持
feign:
hystrix:
enabled: true
client:
config:
default:
connectTimeout: 5000 # 指定Feign连接提供者的超时时限
readTimeout: 5000 # 指定Feign从请求到获取提供者响应的超时时限
# 开启actuator的所有web终端
management:
endpoints:
web:
exposure:
include: "*"
# 设置服务熔断时限
hystrix:
dashboard:
proxy-stream-allow-list: "localhost"
command:
default:
execution:
isolation:
thread:
timeoutInMilliseconds: 3000
turbine:
app-config: portal-service
cluster-name-expression: new String("default")
combine-host-port: true
instanceUrlSuffix: /actuator/hystrix.stream #turbine默认监控actuator/路径下的端点,修改直接监控hystrix.stream
#cluster-name-expression: metadata['cluster']
#aggregator:
# cluster-config: ribbon
#instanceUrlSuffix: /hystrix.stream #turbine默认监控actuator/路径下的端点,修改直接监控hystrix.stream
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
# 17.超时时间
Ribbon 和 Hystrix 和 Feign 的超时时间配置的关系
- 在 Spring Cloud 中使用 Feign 进行微服务调用分为两层:
Hystrix的调用和Ribbon的调用,Feign 自身的配置会被覆盖。 Hystrix的超时时间和ribbon的超时时间存在一定的关系- 说明下,如果不启用
Hystrix,Feign的超时时间则是Ribbon的超时时间,Feign自身的配置也会被覆盖
Hystrix的超时时间=Ribbon的重试次数(包含首次) * (ribbon.ReadTimeout + ribbon.ConnectTimeout)
Ribbon重试次数(包含首次)= 1 + ribbon.MaxAutoRetries + ribbon.MaxAutoRetriesNextServer + (ribbon.MaxAutoRetries * ribbon.MaxAutoRetriesNextServer)
2
3
# 18.Hystrix 全局配置
Hystrix 是 Netflix 开发的一种用于处理分布式系统中的服务故障和延迟问题的库。它允许你通过隔离、降级、限流等机制来增强系统的弹性。在 Hystrix 中,可以设置全局的流量控制配置来限制服务的请求流量。以下是如何设置全局的流量控制配置的一般步骤:
配置 Hystrix 全局属性:你可以在应用程序的配置文件中设置 Hystrix 的全局属性。这些属性可以控制 Hystrix 的行为,包括流量控制。
# Hystrix 全局配置
hystrix.command.default.execution.isolation.thread.timeoutInMilliseconds=1000
hystrix.command.default.circuitBreaker.requestVolumeThreshold=20
hystrix.command.default.circuitBreaker.errorThresholdPercentage=50
2
3
4
这些属性的含义如下:
hystrix.command.default.execution.isolation.thread.timeoutInMilliseconds:默认的 Hystrix 命令执行超时时间(以毫秒为单位)。hystrix.command.default.circuitBreaker.requestVolumeThreshold:触发断路器的最小请求数。hystrix.command.default.circuitBreaker.errorThresholdPercentage:断路器打开的错误百分比阈值。
在 Hystrix 命令中设置流量控制属性:在 Hystrix 命令的构造函数或执行方法中,你可以设置特定于该命令的流量控制属性,例如超时时间、断路器阈值等。
public class MyServiceCommand extends HystrixCommand<String> {
public MyServiceCommand() {
super(HystrixCommandGroupKey.Factory.asKey("MyServiceGroup"));
// 设置超时时间
this.properties.executionTimeoutInMilliseconds().set(1000);
}
// ...
}
2
3
4
5
6
7
8
9
10
通过这些步骤,你可以在应用程序中使用 Hystrix 来设置全局的流量控制配置,并为每个服务调用创建自定义的 Hystrix 命令,以控制各个服务的流量行为。请根据你的具体需求调整配置和命令设置。注意,Hystrix 在最新版本中已不再被 Netflix 主动维护,推荐使用更现代的替代品,如 Resilience4J 或 Spring Cloud Circuit Breaker。
# 五.zuul
# 1.微服务网关?
服务网关是微服务架构中一个不可或缺的部分。通过服务网关统一向外系统提供 REST API 的过程中,除了具备服务路由、均衡负载功能之外,它还具备了权限控制等功能。Spring Cloud Netflix 中的 Zuul 就担任了这样的一个角色,为微服务架构提供了前门保护的作用,同时将权限控制这些较重的非业务逻辑内容迁移到服务路由层面,使得服务集群主体能够具备更高的可复用性和可测试性。
Zuu 包含了对请求的路由和过滤两个最主要的功能:
其中路由功能负责将外部请求转发到具体的微服务实例上是实现外部访问统一入口的基础,过滤功能则负责对请求的处理过程进行干预,是实现请求校验、服务聚合等功能的基础。
Zuul 和 Eureka 进行整合,将 Zuul 自身注册为 Eureka 服务治理下的应用,同时从 Eureka 中获得其他微服务的信息,也即以后的访问微服务都是通过 Zuul。
# 2.Zuul 网关的作用
网关有以下几个作用:
统一入口:未全部为服务提供一个唯一的入口,网关起到外部和内部隔离的作用,保障了后台服务的安全性。鉴权校验:识别每个请求的权限,拒绝不符合要求的请求。动态路由:动态的将请求路由到不同的后端集群中。- 减少客户端与服务端的
耦合:服务可以独立发展,通过网关层来做映射。
# 3.zuul 的功能?
使用 Zuul 的过滤器, 可以对请求的一些列信息进行安全认证/权限认证/身份识别/限流/记录日志等功能。只需要自定义 Filter 后继承 ZuulFilter 类即可。重写其 filterType、filterOrder、shouldFilter 以及 run 方法。 filterType 表示 filter 执行的时机,其 value 值含义如下所示:
pre:在请求被路由之前调用 比如:登录验证routing: 在请求被路由之中调用post: 在请求被路由之后调用error: 处理请求发生错误时调用filterOrder表示执行的优先级,值越小表示优先级越高shouldFilter则表示该 filter 是否需要执行
# 4.路由配置
zuul 的配置
zuul:
sensitiveHeaders: Cookie,Set-Cookie,Authorization
routes:
portal:
path: /portal-service/** #访问路径:http:/localhost:8888/portal-service/portal/1
service-id: portal-service
goods:
path: /goods-service/** #http:/localhost:8888/goods-service/kwanGoodsInfo/1
service-id: goods-service
host:
connect-timeout-millis: 5000 #超时时间
prefix: /api #访问路径:http:/localhost:8888/api/portal-service/portal/1 http:/localhost:8888/api/goods-service/kwanGoodsInfo/1
retryable: true
ignored-services: portal-service #感略某个服务名,禁止通过该服务名访可
# ignored-services: * #禁止通过所有的服务名访间
ignored-patterns: /**/feign/** #不给匹配此棋式的路径进行路由·那么你到时候访间不到
LogFilter:
route:
disable: true #用LogFilter过滤器
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 5.过滤器
filter 是 zuul 的核心组件,zuul 大部分功能都是通过过滤器来实现的。zuul 中定义了 4 种标准过滤器类型,这些过滤器类型对应于清求的典型生命周期。
PRE:这种过滤器在请求被路由之前调用。可利用这种过滤器实现身份验证、在集群中选择请求的微服务、记录调试信息等。ROUTING:这种过滤器将请求路由到微服务。这种过滤器用于构建发送给微服务的请求,并使用 Apache HttpClient:或 Netfilx Ribbon 请求微服务POST:这种过滤器在路由到微服务以后执行。这种过滤器可用来为响应添加标准的 HTTP Header 收集统计信息和指标、将响应从微服务发送给客户端等。ERROR:在其他阶段发生错误时执行该过滤器。
# 6.过滤器禁用
zuul 过滤器的禁用,Spring Cloud 默认为 Zuul 编写并启用了一些过滤器,例妆如 DebugFilter,
FormBodyWrapperFilter 等,这些过滤器都存放在 spring-cloud-netflix-zuul 这个 jr 包里,一些场景下,想要禁用掉部分过滤器,该怎么办呢?
只需在 application.properties 里设置 zuul.disable=true 例如,要禁用上面我们写的过滤器,这样配置就行了
zuul.LogFilter.route.disable=true
# 7.Zuul 的熔断降级
zuul 是一个代理服务,但如果被代理的服务突然断了,这个时候 zuul 上面会有出错信息,例如,停止了被调用的微服务;一般服务方自己会进行服务的熔断降级,但对于 zuul 本身,也应该进行 zuul 的降级处理:
Zuul 的 fallback 容错处理逻辑,只针对 timeout 异常处理,当请求被 Zuul 路由后,只要服务有返回(包括异常),都不会触发Zuul的fallback容错逻辑。
- 因为对于 Zuul 网关来说,做请求路由分发的时候,结果由远程服务运算的。那么远程服务反馈了异常信息,Zuul 网关
不会处理异常,因为无法确定这个错误是否是应用真实想要反馈给客户端的。简单来说,zuul 的服务降级是微服务级别的,不是方法级别的。
# 六.config
# 1.分布式配置中心
Spring Cloud Config 为服务端和客户端提供了分布式系统的外部化配置支持。
配置服务器默认采用 git 来存储配置信息,这样就有助于对环境配置进行版本管理,并且可以通过 git 客户端工具来方便的管理和访问配置内容。当然他也提供本地化文件系统的存储方式
配置中心用途:
- 变量获取
- 自动刷新
- 高可用
- 安全认证
- 加解密
# 2.为什么需要配置中心
在分布式微服务体系中,服务的数量以及配置信息日益增多,比如各种服务器参数配置、各种数据库访问参数配置、各种环境下配置信息的不同、配置信息修改之后实时生效等等,传统的配置文件方式或者将配置信息存放于数据库中的方式已无法满足开发人员对配置管理的要求,如:
安全性:配置跟随源代码保存在代码库中,容易造成配置泄漏时效性:修改配置,需要重启服务才能生效局限性:无法支持动态调整:例如日志开关、功能开关
# 3.常用配置中心框架
Apollo(阿波罗):携程框架部门研发的分布式配置中心,能够集中化管理应用不同环境、不同集群的配置,配置修改后能够实时推送到应用端,并且具备规范的权限、流程治理等特性,适用于微服务配置管理场景Spring Cloud Alibaba Nacos: 分布式注册中心。Spring Cloud Config:Spring Cloud 微服务开发的配置中心,提供服务端和客户端支持;diamond:淘宝开源的持久配置中心,支持各种持久信息(比如各种规则,数据库配置等)的发布和订阅XDiamond:全局配置中心,存储应用的配置项,解决配置混乱分散的问题,名字来源于淘宝的开源项目 diamond,前面加上一个字母 X 以示区别。Qconf:奇虎 360 内部分布式配置管理工具,用来替代传统的配置文件,使得配置信息和程序代码分离,同时配置变化能够实时同步到客户端,而且保证用户高效读取配置,这使的工程师从琐碎的配置修改、代码提交、配置上线流程中解放出来,极大地简化了配置管理工作;Disconf:百度的分布式配置管理平台,专注于各种分布式系统配置管理的通用组件和通用平台,提供统一的配置管理服务;
# 4. Spring Cloud Config?
Spring Cloud Config 是一个解决分布式系统的配置管理方案。它包含 Client 和 Server 两个部分,Server 提供配置文件的存储、以接口的形式将配置文件的内容提供出去,Client 通过接口获取数据、并依据此数据初始化自己的应用。
Spring cloud 使用 git 或 svn、也可以是本地存放配置文件,默认情况下使用 git。
# 5.配置路由规则
/{application)-{profile}.properties
http://localhost:8888/application-dev.properties
/{label}/{application}-{profile}.properties
http://localhost:8888/master/application-dev.properties
/[application}-{profile}.yml
http://localhost:8888/master/application-dev.yml
/{label}/{application}-{profile}.yml
http://localhost:8888/master/application-dev.properties
其中:
{application}表示配置文件的名字,对应的配置文件即 application,
{profile}表示环境,有dev、test、online及默认,
{label}表示分支,默认我们放在 master 分支上,
通过浏览器上访问http:/localhost:8888/application,/dev/master
# 6.config 加解密
加解密是借助 JCE 实现的,默认情况下我们的 JRE 中自带了 JCE(Java Cryptography Extension),但是默认是一个有限长度的版本,我们这里需要一个不限长度的 JCE,JCE 是对称加密,安全性相对非对称加密低一点,但是使用更加方便一点。
下载完成之后解压,把得到到两个 Jar 包复制到$JAVA_HOME\jre\lib\security 目录下。
在我们的 configserver 项目中的 bootstrap.yml 配置文件中加入如下配置项:
encrypt:
key: Thisismysecretkey
2
访问下面连接进行单个数据加密,这里是 post 请求,不是 get
#加密
http://localhost:7001/encrypt
#解密
http:/192.168.6.817001/decrypt
2
3
4
5
可能会报错,需要添加账号密码

username='{cipher)516269d5f6af298bf843b31c847ad705d8305e784c394c7395a55a0742d8b69d'
需要使用{cipher}的密文形式,单引号不要忘记了。然后 push 到远程。
加解密在config-server 服务中进行的,解密过程不需要在客户端进行配置
# 7.加密过程安全认证
1.添加依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-security</artifactId>
</dependency>
2
3
4
2.config 配置
在 config 的配置文件中配置
spring:
security:
user:
password: user123 #配置登陆的密码是user123
name: user #配置登陆的账户是user
2
3
4
5
或者
显式指定账号密码,指定账户密码的优先级要高于 URI
spring:
cloud:
config:
label: ${spring.profiles.active} #指定Git仓库的分支,对应config server 所获取的配置文件的{label}
discovery:
enabled: true #表示使用服务发现组件中的configserver ,而不是自己指定config server的uri,默认为false
service-id: microservice-config-server #服务发现中configserver的serverId
fail-fast: true #失败快速响应
username: user
password: user123
2
3
4
5
6
7
8
9
10
3.客户端配置
spring:
cloud:
config:
uri: http://user:user123@localhost:7001/
2
3
4
# 8.局部刷新
Spring Boot 的 actuator 提供了一个刷新端点/refresh,添加依赖
spring-boot-starter-actuator可用于配置的刷新;
<!--springboot的一个监控actuator-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
2
3
4
5
在 Controller 上添加注解@RefreshScope,添加这个注解的类会在配置更新时得到特殊的处理;
打开 web 访问端点
management,endpoints.web.exposure.include='*'
访问http:/localhost:8080/actuator/refresh进行手动刷新配置;必须要 post 方式访问这个接口。
# 9.全局刷新
全局刷新:需要使用到消息总线。
前面使用/actuator/refresh 端点手动刷新配置虽然可以实现刷新,但所有微服务节点的配置都需要手动去刷新,如果微服务非常多,其工作量非常庞大。因此实现配置的自动刷新是志在必行,Spring Cloud Bus 就可以用来实现配置的自动刷新;
Spring Cloud Bus 使用轻量级的消息代理(例如 RabbitMQ、Kafka 等)广播传播状态的更改(例如配置的更新)或者其他的管理指令,可以将 Spring Clou Bus 想象成一个分布式的 Sprina Boot Actuator;
#形置rabbitmq
spring.rabbitmq.host=192.168.10.128
spring.rabbitmq.port=5672
spring.rabbitmq.username=guest
spring.rabbitmq.password-guest
#开启spring cloud bus默认是开启的,也可以省略速形置
spring.cloud.bus.enabled=true
#打开所有的web访问端点
management.endpoints.web.exposure.include='*'
2
3
4
5
6
7
8
9
10
11
各个微服务(客户端),其他各个微服务用于接收消息,那么也需要有spring cloud bus的依赖和 RabbitMQ 的连接信息。
然后 post 方式请求地址,如果返回成功,则 RabbitMQ 将收到消息,然后微服务会消费消息,config 的所有客户端的微服务配置都会动态刷新。
http:/localhost::8888/actuator/bus-refresh
# 10.什么是总线?
在微服务架构的系统中,通常会使用轻量级的消息代理来构建一个共用的消息主题,并让系统中所有微服务实例都连接上来。由于该主题中产生的消息会被所有实例监听和消费,所以称它为消息总线。在总线上的各个实例,都可以方便地广播一些需要让其他连接在该主题上的实例都知道的消息。
在 Spring Cloud 中,"总线"(Bus)通常指的是 Spring Cloud Bus,它是一种用于在分布式系统中传播状态变化的工具。Spring Cloud Bus 可以将配置的变化或其他管理指令传播到整个微服务架构中的各个实例,从而实现配置的动态刷新和管理命令的分发。
Spring Cloud Bus 主要由以下几个组件组成:
消息代理(Message Broker):Spring Cloud Bus 使用消息代理来传播消息。常用的消息代理包括 RabbitMQ 和 Apache Kafka,它们负责将消息从一个端点传递到另一个端点。
消息生成器(Message Generator):在配置发生变化或执行管理指令时,Spring Cloud Bus 会生成相应的消息并发送到消息代理。
消息监听器(Message Listener):微服务中的各个实例会监听消息代理上的消息,一旦有新消息到达,它们会接收并执行相应的操作,如刷新配置。
通过 Spring Cloud Bus,您可以在微服务架构中实现一些有用的功能,例如:
动态刷新配置:通过 Spring Cloud Config 和 Spring Cloud Bus 的结合,您可以在配置中心更改配置后,使用 Spring Cloud Bus 广播配置更改消息,然后各个微服务实例可以接收并刷新配置,无需重启服务。
集中式管理命令:您可以使用 Spring Cloud Bus 广播管理指令,例如强制所有微服务实例重新加载配置、重新注册等操作。
事件传播:除了配置变更,您还可以使用 Spring Cloud Bus 在微服务之间传播自定义事件,以便实现更复杂的应用场景。
需要注意的是,Spring Cloud Bus 并不是用于实现总线(Bus)的物理通道或虚拟通道,而是一个在分布式系统中传播消息和管理指令的工具。它有助于提高微服务架构中配置的灵活性和管理的便捷性。
# 11.消息总线原理
ConfigClient 实例都监听 MQ 中同一个 topic(默认是 springCloudBus)。当一个服务刷新数据的时候,它会把这个信息放入到 Topic 中,这样其它监听同一 Topic 的服务就能得到通知,然后去更新自身的配置。
通过使用 Spring Cloud Bus 与 Spring Cloud Config 的整合,并以 RabbitMQ 作为消息代理,实现了应用配置的动态更新。
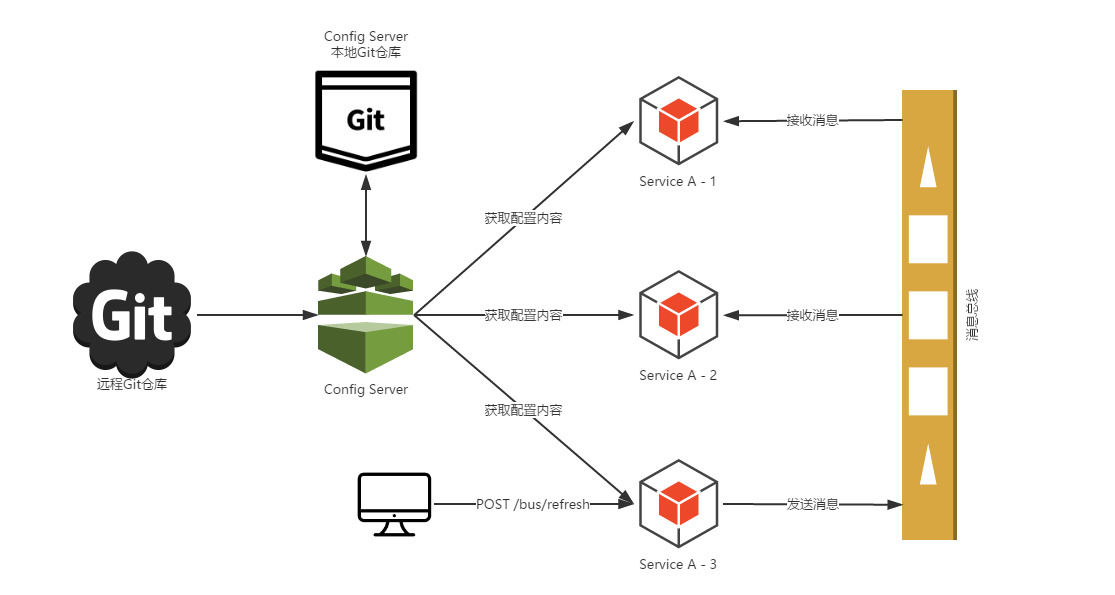
# 12.SpringCloudBus
Spring Cloud Bus 是用来将分布式系统的节点与轻量级消息系统链接起来的框架,它整合了 Java 的事件处理机制和消息中间件的功能。
Spring Clud Bus 目前支持 RabbitMQ 和 Kafka。
Spring Cloud Bus 能管理和传播分布式系统间的消息,就像一个分布式执行器,可用于广播状态更改、事件推送等,也可以当作微服务间的通信通道。
利用消息总线触发一个服务端 ConfigServer 的/bus/refresh 端点,而刷新所有客户端的配置

当我们将系统启动起来之后,“Service A”的三个实例会请求 Config Server 以获取配置信息,Config Server 根据应用配置的规则从 Git 仓库中获取配置信息并返回。
此时,若我们需要修改“Service A”的属性。首先,通过 Git 管理工具去仓库中修改对应的属性值,但是这个修改并不会触发“Service A”实例的属性更新。我们向“Service A”的实例 3 发送 POST 请求,访问/bus/refresh接口。此时,“Service A”的实例 3 就会将刷新请求发送到消息总线中,该消息事件会被“Service A”的实例 1 和实例 2 从总线中获取到,并重新从 Config Server 中获取他们的配置信息,从而实现配置信息的动态更新。
而从 Git 仓库中配置的修改到发起/bus/refresh的 POST 请求这一步可以通过 Git 仓库的 Web Hook 来自动触发。由于所有连接到消息总线上的应用都会接受到更新请求,所以在 Web Hook 中就不需要维护所有节点内容来进行更新,从而解决了通过 Web Hook 来逐个进行刷新的问题。
通过destination参数来指定需要更新配置的服务或实例。
# 七.Sleuth
# 1.什么是 Sleuth?
Spring Cloud Sleuth 是 Spring Cloud 提供的分布式系统服务链追踪组件,它大量借用了 Google 的 Dapper,Twitter 的 Zipkin。
Sleuth 是 Spring Cloud 生态中的一个分布式跟踪解决方案,用于在微服务架构中追踪和监控请求的传递路径,帮助开发人员诊断和解决分布式系统中的性能问题和故障。Sleuth 可以协助您跟踪请求在多个微服务之间的流转,记录请求的处理时间、调用关系和其他相关信息,从而提供对系统性能和行为的深入了解。
Sleuth 主要提供以下功能:
分布式追踪:Sleuth 为每个请求生成一个唯一的跟踪 ID,并将这个 ID 注入到请求头中。在微服务之间传递时,Sleuth 会自动将跟踪信息传递下去,从而构建整个请求的调用链路。
调用链路跟踪:Sleuth 将每个请求的调用链路记录下来,包括请求的起始和结束时间,每个微服务的处理时间,以及调用关系。这有助于诊断性能瓶颈和故障原因。
集成支持:Sleuth 可以与其他 Spring Cloud 组件无缝集成,如 Eureka、Zipkin 等,从而提供更强大的监控和分析能力。
错误跟踪:Sleuth 还可以记录请求中的错误信息,包括异常和错误码,帮助您定位和排查问题。
可定制性:Sleuth 允许您根据需要自定义跟踪的内容和格式,以满足不同场景的需求。
Sleuth 使用了 OpenTracing 标准,并提供了与 Zipkin(一个开源的分布式跟踪系统)的集成,从而可以将跟踪信息发送到 Zipkin 进行存储和可视化。通过 Sleuth 和 Zipkin 的组合,您可以实现全面的分布式系统跟踪和监控。
# 2.为什么需要 Sleuth?
链路追踪:通过 Sleuth 可以很清楚的看出一个请求都经过了那些服务,可以很方便的理清服务间的调用关系等。
性能分析:通过 Sleuth 可以很方便的看出每个采样请求的耗时,分析哪些服务调用耗时,当服务调用的耗时随着请求量的增大而增大时, 可以对服务的扩容提供一定的提醒。
数据分析,优化链路:对于频繁调用一个服务,或并行调用等,可以针对业务做一些优化措施。
可视化错误:对于程序未捕获的异常,可以配合 Zipkin 查看。
- 快速发现问题
- 判断故障影响范围
- 梳理服务依赖以及依赖的合理性
- 分析链路性能问题以及实时容量规划
单纯的理解链路追踪,就是将一次分布式请求还原成调用链路,进行日志记录,性能监控并将一次分布式请求的调用情况集中展示。比如各个服务节点上的耗时、请求具体到达哪台机器上、每个服务节点的请求状态等等。
# 3.链路追踪相关产品
常见的链路追踪技术有下面这些:
skywalking:本土开源的基于字节码注入的调用链分析,以及应用监控分析工具。特点是支持多种插件, UI 功能较强,接入端无代码侵入。目前已加入 Apache 孵化器。
Sleuth:SpringCloud 提供的分布式系统中链路追踪解决方案。
cat:由大众点评开源,基于 Java 开发的实时应用监控平台,包括实时应用监控,业务监控 。 集成方案是通过代码埋点的方式来实现监控,比如: 拦截器,过滤器等。 对代码的侵入性很大,集成成本较高。风险较大。
zipkin:由 Twitter 公司开源,开放源代码分布式的跟踪系统,用于收集服务的定时数据,以解决微服务架构中的延迟问题,包括:数据的收集、存储、查找和展现。该产品结合 spring-cloud-sleuth 使用较为简单, 集成很方便, 但是功能较简单。
pinpoint:Pinpoint 是韩国人开源的基于字节码注入的调用链分析,以及应用监控分析工具。特点是支持多种插件, UI 功能强大,接入端无代码侵入。
注意: SpringCloud alibaba 技术栈中并没有提供自己的链路追踪技术的,我们可以采用Sleuth +Zinkin来做链路追踪解决方案,或者接入 skywalking 第三方插件。
# 4.基本术语?
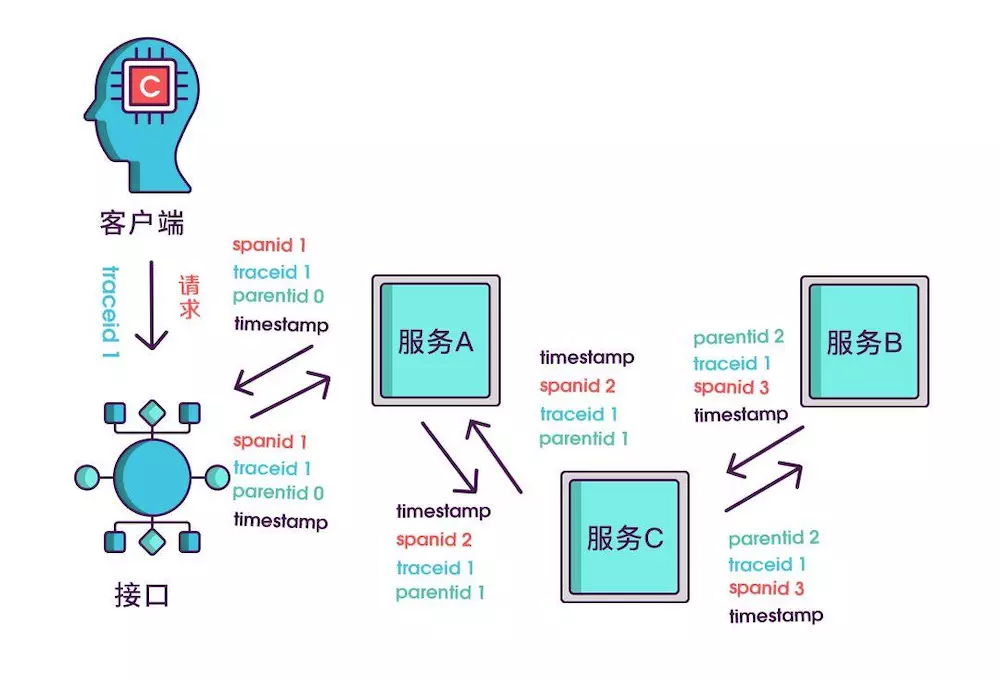
Sleuth 基本概念涉及到三个专业术语: span、Trace、Annotations。
span:基本工作单位,每次发送一个远程调用服务就会产生一个 Span。Span 是一个 64 位的唯一 ID。通过计算 Span 的开始和结束时间,就可以统计每个服务调用所花费的时间。。
Trace:一系列 Span 组成的树状结构,一个 Trace 认为是一次完整的链路,内部包含 n 多个 Span。Trace 和 Span 存在一对多的关系,Span 与 Span 之间存在父子关系。
Annotations:用来及时记录一个事件的存在,一些核心 annotations 用来定义一个请求的开始和结束。
开始与结束:
cs(Client Sent):客户端发起一个请求,这个 annotation 描述了这个 span 的开始;sr(Server Received):服务端获得请求并准备开始处理它,如果 sr 减去 cs 时间戳便可得到网络延迟;ss(Server Sent):请求处理完成(当请求返回客户端),如果 ss 减去 sr 时间戳便可得到服务端处理请求需要的时间;cr(Client Received):表示 span 结束,客户端成功接收到服务端的回复,如果 cr 减去 cs 时间戳便可得到客户端从服务端获取回复的所有所需时间。
# 5.跟踪原理
核心: 为什么能够进行整条链路的追踪?
其实就是一个 Trace ID 将 一连串的 Span 信息连起来了。根据 Span 记录的信息再进行整合就可以获取整条链路的信息。
# 6.什么是 Zipkin
Zipkin 是一种分布式跟踪系统。它有助于收集解决微服务架构中的延迟问题所需的时序数据。它管理这些数据的收集和查找。Zipkin 的设计基于 Google Dapper 论文。应用程序用于向 Zipkin 报告时序数据。Zipkin UI 还提供了一个依赖关系图,显示了每个应用程序通过的跟踪请求数。如果要解决延迟问题或错误,可以根据应用程序,跟踪长度,注释或时间戳对所有跟踪进行筛选或排序。选择跟踪后,您可以看到每个跨度所需的总跟踪时间百分比,从而可以识别有问题的应用程序。
# 7.Zipkin 下载安装
1.下载地址
https://repo1.maven.org/maven2/io/zipkin/zipkin-server/
2.下载 jar 包
可以使用迅雷下载,或者科学上网
3.启动服务端
启动报错,看看端口是否被占用
java -jar zipkin-server-2.23.9-exec.jar
4.访问控制台
http://127.0.0.1:9411/zipkin
# 8.Zipkin 客户端配置
1.pom 依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
2
3
4
2.配置文件
#端口号,指定端口,不然默认是8080,会出现冲突
server:
port: 8081
spring:
cloud:
config:
fail-fast: false #客户端连接失败时开启重试,需要结合spring-retry、spring-aop
label: main #获取配置文件的分支名
name: application-portal8081 #获取的文件名
profile: portal8081 #文件后缀
uri: http://localhost:7001 #配置中心服务端地址
zipkin:
base-url: http://localhost:9411 #zipkin地址 默认值就是0.1,代表收集10%的请求追踪信息。
discovery-client-enabled: false
sender:
type: web
sleuth:
sampler:
percentage: 0.1 #收集百分比
eureka:
client:
service-url:
defaultZone: http://eureka8767:8767/eureka/,http://eureka8768:8768/eureka/,http://eureka8769:8769/eureka/
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# 9.Zipkin 控制台
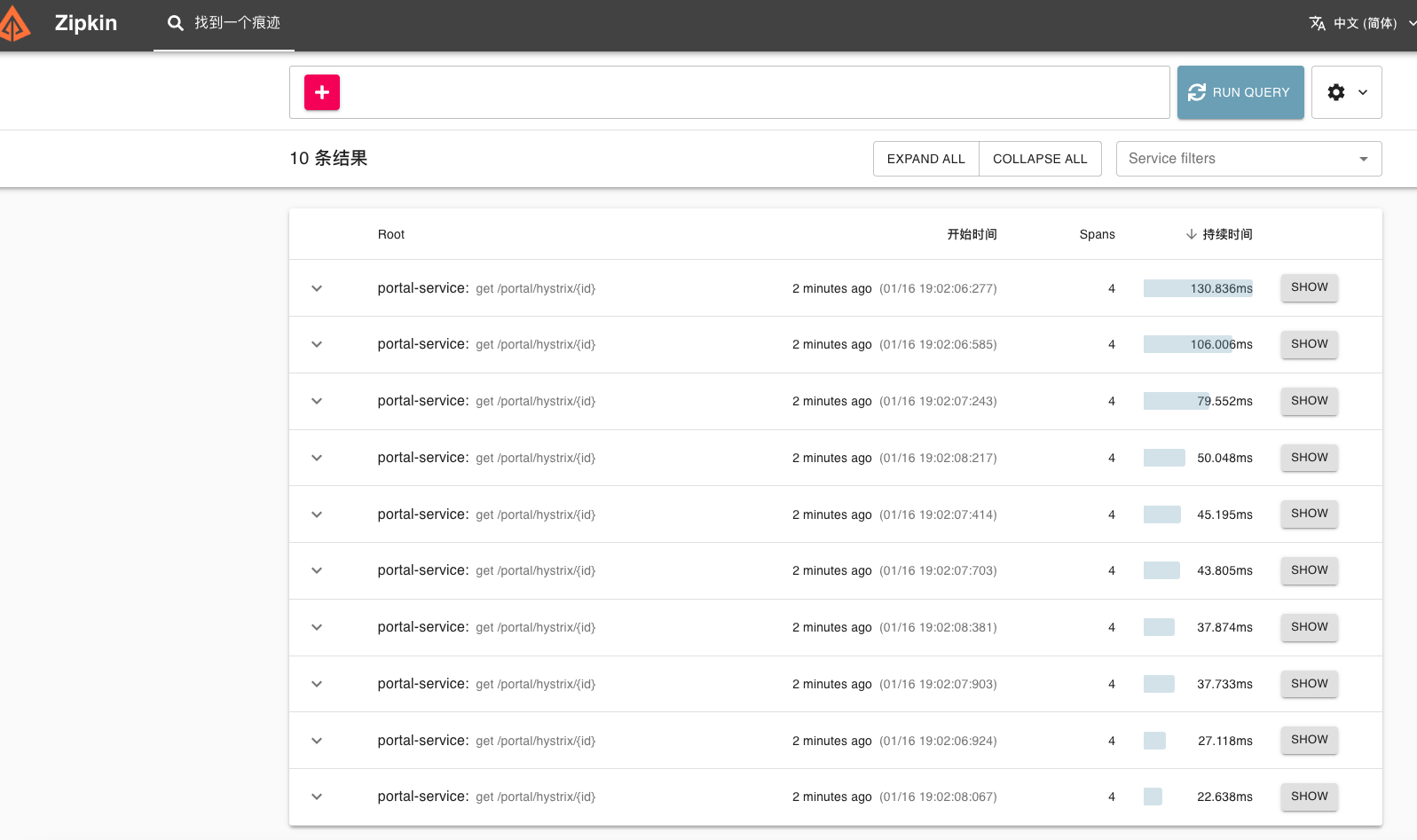
需要调用一下服务,才能在控制台查询到链路调用信息以及服务健康状态。
- 可以看到请求过的链路信息
- 包含的微服务
- 耗时信息
- 还能通过筛选条件进行查询
- 可以通过 trace id 进行查询
http://127.0.0.1:9411/zipkin
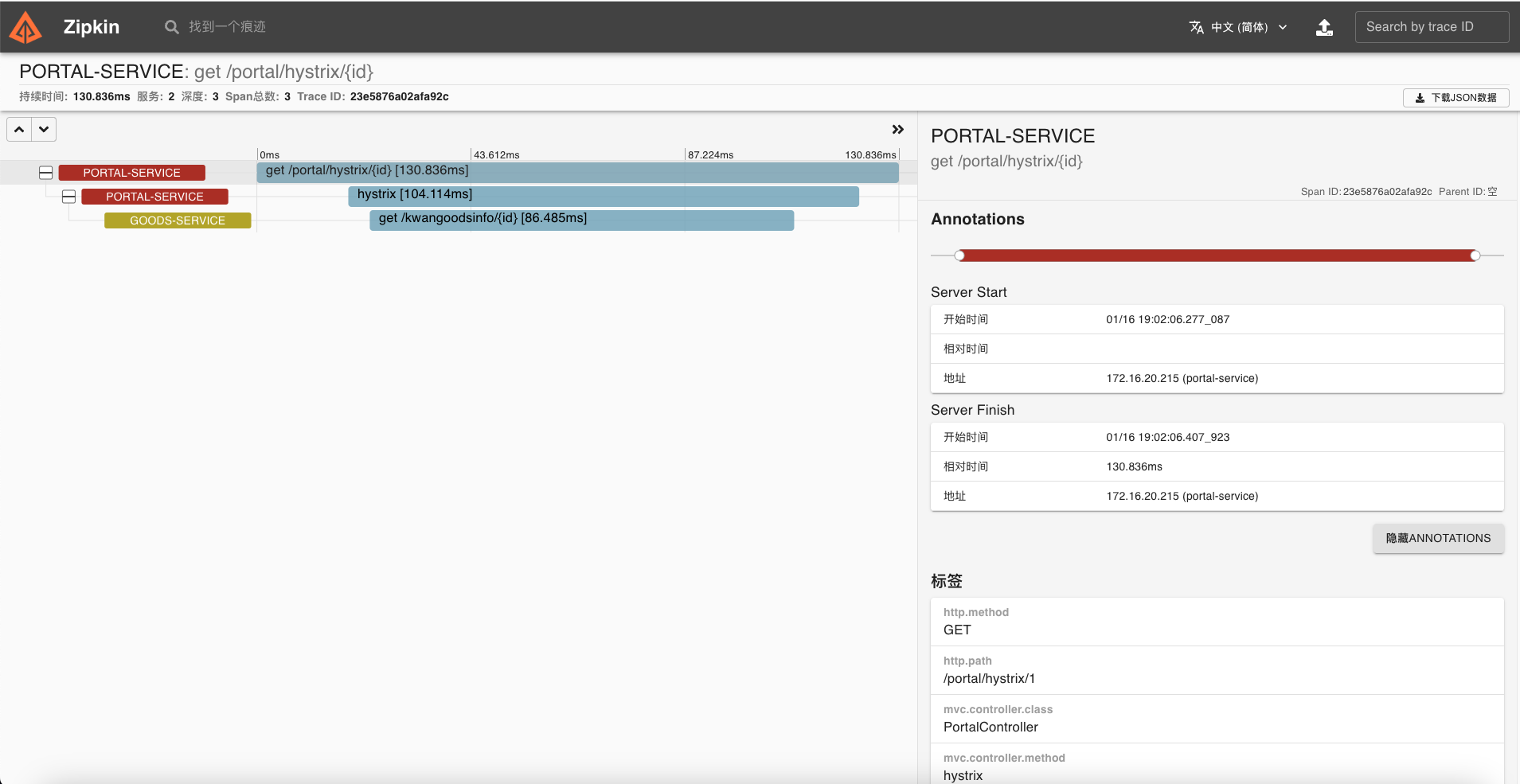
详细面板可以看到:
- 具体的统计信息
- 统计耗时信息,开始时间以及结束时间,以及每一段的耗时信息
- 标签信息,接口信息
- 请求方式,请求方法
- Span ID
- Trace ID
- 服务名
- 服务数
- 深度
- 跨度总数
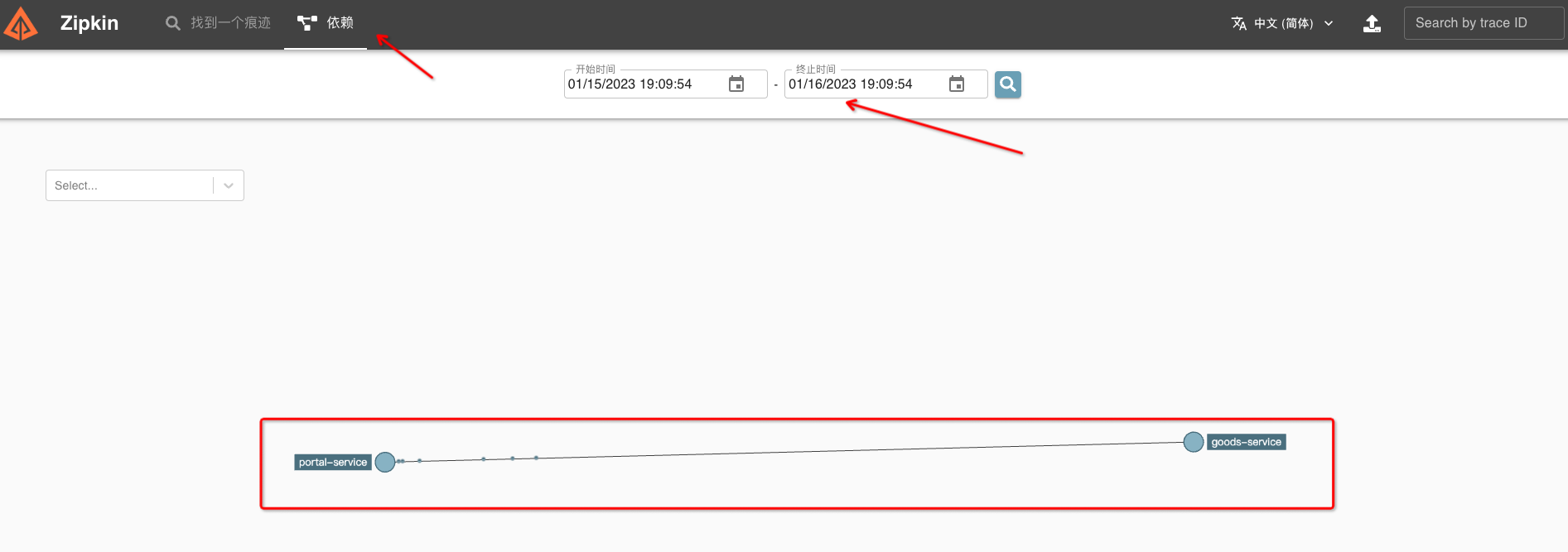
# 10.Zipkin 依赖关系图
可以查看服务调用时,服务之间的依赖关系,清晰明了。
# 11.Zipkin 数据采样
zipkin 日志采样率设置为0.1,就是 10 次只能有一次被记录下来。
日志其实是完整的,日志可以用 logback 收集并保存成文件。所有的请求信息 都会被这个文件所记录,只是 zikpin 侧重于链路追踪,并不是排查错误,更多的是我们知道服务直接调用耗时和服务直接依赖关系而已。所以不需要完整日志,只需要 0.1 的 比例就够了。
sleuth:
sampler:
probability: 0.1
2
3
而这个采样其实只是对 zipkin有效,只是在 zipkin 界面显示 0.1 的日志而已,并不是后台日志也都是只收集 0.1。而 logback 会把我们所有请求信息全部记录下来,不会遗漏,这样的话就可以顺利排错。
# 12.Zipkin 数据持久化
Zipkin 中的数据默认是保存在内存中的,重启 sleuth 服务,数据会被清空,这显然是不合适的。
Zipkin 可以集成 elasticsearch,或者 mysql 进行数据的持久化,这样服务重启,数据不丢失。
Zipkin 支持多种持久化方式,常见的包括:
- Elasticsearch 存储:您可以将跟踪数据存储到 Elasticsearch 中,从而利用其强大的搜索和分析功能进行查询和分析。Elasticsearch 存储可以与 Kibana 一起使用,提供丰富的数据可视化能力。
- Kafka 存储:您可以将跟踪数据存储到 Apache Kafka 中,然后使用其他工具对数据进行处理和分析。
- In-Memory 存储:这种方式将跟踪数据存储在内存中,适合于开发和测试环境。虽然简单快速,但不适合长期存储和大规模应用。
- MySQL 存储:Zipkin 提供了对 MySQL 数据库的支持,您可以将跟踪数据存储到 MySQL 数据库中。要使用 MySQL 存储,您需要创建相应的数据库表,然后配置 Zipkin 使用 MySQL 存储。
- Cassandra 存储:Zipkin 也支持使用 Apache Cassandra 进行数据存储。Cassandra 是一个高度可扩展的分布式 NoSQL 数据库,适用于存储大规模的跟踪数据。
配置 Zipkin 数据的持久化方式通常涉及以下步骤:
安装和配置相应的数据库或存储系统,如 MySQL、Cassandra、Elasticsearch 等。
配置 Zipkin 以使用您选择的
持久化方式。这通常涉及在 Zipkin 配置文件中设置相关的数据源信息和属性。启动
Zipkin服务,使其能够将跟踪数据存储到所选择的存储系统中。使用
Zipkin Web UI或其他工具对存储的跟踪数据进行查询、分析和可视化。