
# 一.简单介绍
# 1.clickhouse 特点
- 查询速度快
- 支持 SQL
- 采用 MPP 架构
- 列式存储
- 向量化执行引擎
- 消除循环来提高效率,比如需要循环 3 次才能完成的工作,转化为 3 个工作并行处理。
- 适用于 OLAP 场景
- 相同场景的不同数据量使用不同算法, 比如
- 常量字符串查询,使用 volnitsky 算法。
- 非常量字符串,使用 CPU 的向量化 SIMD 指令。
- 字符串正则匹配,使用 re2 和 hyperscan 算法。
# 2.应用场景
- 大多数是读请求
- 数据总是以相当大的批(> 1000 rows)进行写入
- 不修改已添加的数据
- 每次查询都从数据库中读取大量的行,但是同时又仅需要少量的列
- 宽表,即每个表包含着大量的列
- 较少的查询(通常每台服务器每秒数百个查询或更少)
- 对于简单查询,允许延迟大约 50 毫秒
- 列中的数据相对较小: 数字和短字符串(例如,每个 UR60 个字节)
- 处理单个查询时需要高吞吐量(每个服务器每秒高达数十亿行)
- 事务不是必须的
- 对数据一致性要求低
- 每一个查询除了一个大表外都很小
- 查询结果明显小于源数据,换句话说,数据被过滤或聚合后能够被盛放在单台服务器的内存中
# 3.使用的存储引擎?
- MergeTree:基于时间排序
- ReplacingMergeTree
- SummingMergeTree
- AggregatingMergeTree
- CollapsingMergeTree
- VersionedCollapsingMergeTree
- GraphiteMergeTree
# 4.使用 clickhouse 注意事项
- 严格区分大小写,注意库名和字段的大小写
- 子查询的查询结果需要加 as 别名
- 不支持 ndv 函数,支持使用 count(distinct column)
- 使用方法,如果设置如下参数:
- set APPX_COUNT_DISTINCT=true;
- 则所有的 count(distinct col)会在底层计算的时候转成 ndv() 函数,也就是说,在 sql 中可以直接使用 count(distinct col),如果不配置上述参数,则在 sql 中直接写 ndv(col) 也可以
- ifnull 函数在 null 时需要有默认值 ifnull(ddopsd.all_sal_act_qty,0)
- 查询条件字段最好加上''单引号,避免类型不匹配
- 涉及到计算函数的字段,字段类型必须是 Number 类型,不能是 String
- 超过 50g 的表不能直接删除,需要添加一个空文件 sudo touch /data/clickhouse/flags/force_drop_table && sudo chmod 666 /data/clickhouse/flags/force_drop_table
- 创建表的 order by 会影响查询效率(相当于 mysql 的索引)
- left join 尽量使用 any left join
- 存在 null 值的字段不能指定为 order by 索引
- clickhouse 的字段是 Int32 时,插入数据不能为 null
- null 值不能转化为 Int32 类型,会报错
- clickhouse 在 21.3.1 以后的版本支持开窗函数
- clickhouse 的字段是 Int32 时,插入数据不能为 null
- 空值问题
- 空表,Nullable 与非空类型可以互转;
- Nullable 字段,如果记录不带有 Null 值,可以从 Nullable 转成非空类型;
- 含有 null 值的字段不允许转成非空类型;
- Nullable 字段不允许用于 order by;
# 5.clickhouse 支持的函数
# 二.系统 SQL
# 1.大于 50g 不能删除
sudo touch /data/clickhouse/flags/force_drop_table && sudo chmod 666 /data/clickhouse/flags/force_drop_table
# 2.查询表的数据量
要统计 ClickHouse 中数据量最大的表,并按数据量降序排列,可以执行以下 SQL 语句:
SELECT
table,
sum(bytes) AS size
FROM system.parts
GROUP BY table
ORDER BY size DESC;
2
3
4
5
6
查询表行数和数据量
SELECT database, name, total_rows, round(total_bytes / 1024 / 1024 / 1024, 4) as total_memory
from system.tables t
where t.database != 'system'
order by t.database, t.name
2
3
4
# 3.查看异步删除是否完成
SELECT
database,
table,
command,
create_time,
is_done
FROM system.mutations
order by create_time DESC
LIMIT 10
2
3
4
5
6
7
8
9
# 4.查询执行计划
select * from system.query_log
WHERE query_kind ='Alter'
order by query_start_time desc
2
3
# 5.查看版本号
SELECT version();
# 6.查询 ck 下的所有数据库
SELECT * from system.databases d ;
# 7.查询是否开启开窗函数
SELECT * from `system`.settings s where name = 'allow_experimental_window_functions'
- allow_experimental_window_functions=1 代表开启
- allow_experimental_window_functions=0 未开启
# 8.开窗函数配置
, sum(ifnull(hot_size_sal_qty, 0)) over (partition by product_code order by period_sdate asc rows between unbounded preceding and current row) as total_hot_size_sal_qty
,rank() over (partition by period_sdate order by total360_sal_qty_store_rate desc) as day_360_sal_qty_store_rate_rank
2
# 9.查询数据量
通过以下 sql 可以按表的数据数据大小降序排列
SELECT
database,
table,
round(sum(bytes)/1024/1024, 2) as size_in_mb,
round(sum(bytes)/1024/1024/1024, 2) as size_in_gb,
disk_name
FROM system.parts
where (table like '%_v2%')
GROUP BY database,table,disk_name
ORDER BY size_in_mb DESC;
2
3
4
5
6
7
8
9
10
# 10.查询磁盘大小
# 查询磁盘大小
SELECT name, path, formatReadableSize(free_space) AS free, formatReadableSize(total_space) AS total,
formatReadableSize(keep_free_space) AS reserved FROM system.disks;
2
3
# 三.新增操作
# 1.创建库
#使用默认库引擎创建库
CREATE DATABASE IF NOT EXISTS chtest;
2
# 2.创建表
CREATE TABLE default.boss
(
row_id String,
user_id Int32
) ENGINE = MergeTree() ORDER BY
(row_id) SETTINGS index_granularity = 16384;
2
3
4
5
6
设置策略
CREATE TABLE your_table_name (
column1 data_type,
column2 data_type,
columnN data_type
) SETTINGS (
index_granularity = 8192,
storage_policy = 'beinsight'
);
2
3
4
5
6
7
8
# 3.select 建表
create table t_name_8888
ENGINE = MergeTree
ORDER BY
tuple()
SETTINGS index_granularity = 8192
as
select
*
from
dw_1_sad limit 0,1;
2
3
4
5
6
7
8
9
10
# 4.clickhouse 多个 order
CREATE TABLE bi.boss_info2
(
row_id String,
user_id Int32,
offline_props_time String,
offline_vip_distribute String,
offline_vip_time String,
pay_now String,
data_dt Date
) ENGINE = MergeTree() PARTITION BY data_dt ORDER BY
(industry, l1_name, l2_name, l3_name, job_city, job_area)
SETTINGS index_granularity = 16384;
2
3
4
5
6
7
8
9
10
11
12
# 5.创建物化视图
create materialized view views.o6
engine = MergeTree
order by period_sdate
POPULATE
as
select xxxx
2
3
4
5
6
# 6.新增列
ALTER TABLE `default`.belle_out ADD COLUMN product_year_name Nullable(String);
ALTER TABLE `default`.belle_out ADD COLUMN season_name Nullable(String);
2
# 7.插入语句
INSERT INTO
default.sales_w (`suppkey`, `brand`, `AA`, `AB`, `AC`, `AD`)
VALUES
(1, 'nike', 99, 98, 97, 96);
INSERT INTO
default.sales_w (`suppkey`, `brand`, `AA`, `AB`, `AC`, `AD`)
VALUES
(2, 'nike', 99, 98, 97, 96);
INSERT INTO
default.sales_w (`suppkey`, `brand`, `AA`, `AB`, `AC`, `AD`)
VALUES
(3, 'nike', 99, 98, 97, 96);
2
3
4
5
6
7
8
9
10
11
12
13
# 8.通过查询新增
insert into default.tmp_dws_day_org_pro_size_inv_ds select t1.period_sdate as period_sdate,t3.PRODUCT_CODE as PRODUCT_CODE, t1.size_code as size_code, t1.store_key as store_key from default.dws_day_org_pro_size_inv_ds t1 any left join default.dim_org_allinfo t2 on (t1.store_key = t2.organ_key) any left join default.dim_pro_allinfo t3 on (t1.product_key = t3.PRODUCT_KEY) where t1.period_sdate >= '$year-$month-01' and t1.period_sdate <= '$year-$month-31';
# 9.create table
1.普通建表
CREATE TABLE dis_j.D_F1_shard on cluster cluster_demo (
`product_code` String,
`package_name` String
) ENGINE = MergeTree ORDER BY package_name SETTINGS index_granularity = 8192
2
3
4
2.分布表
CREATE TABLE dis_j.D_F1_all on cluster cluster_demo as dis_j.D_F1_shard
ENGINE = Distributed('cluster_demo', 'dis_j', D_F1_shard, rand())
2
3.复制表
复制已有的一个表创建表。如果不指定 engine,默认会复制源表 engine。
CREATE TABLE dis_j.tmp1 as dis_j.D_F1_shard
4.集群上复制表
复制已有的一个表创建表。在集群上执行,要把 on cluster 写在 as 前面。
CREATE TABLE dis_j.tmp1 on cluster cluster_demo as dis_j.D_F1_shard
5.select 创建表
使用 select 查询结果来创建一个表,需要指定 engine。字段列表会使用查询结果的字段列表。
CREATE TABLE dis_j.tmp1 ENGINE = MergeTree ORDER BY package_name AS select * from dis_j.D_F1_shard
6.分区表上再分区
最后,在分区表之上再创建分区表可以吗?
–在 ck 中创建表:
create table dis_j.t_area_shard on cluster cluster_demo
(
area_id String,
area_name String
)ENGINE = MergeTree ORDER BY area_id SETTINGS index_granularity = 8192
2
3
4
5
–分布表
CREATE TABLE dis_j.t_area_all on cluster cluster_demo as dis_jiakai.t_area_shard
ENGINE = Distributed('cluster_demo', 'dis_j', t_area_shard, rand())
2
CREATE TABLE dis_jiakai.t_area_all2 on cluster cluster_demo as dis_jiakai.t_area_all
ENGINE = Distributed('cluster_demo', 'dis_jiakai', t_area_all, rand())
2
执行成功!
试着查询一下:表可建,但不可用!
select * from dis_jiakai.t_area_all2
SQL 错误 [48]: [ClickHouse](https://so.csdn.net/so/search?q=ClickHouse) exception, code: 48, host: 10.9.20.231, port:
8123; Code: 48, e.displayText() = DB::Exception: Distributed on
Distributed is not supported (version 19.9.2.4 (official build))
2
3
# 四.查询 SQL
# 1.查询年月
#查询年月
SELECT
DISTINCT year(period_sdate) as years,
month(period_sdate) as months
from
tmp_dws_day_org_pro_size_inv_ds_r1
order by
years,
months;
2
3
4
5
6
7
8
9
#查询分
-- 获取日期分
SELECT formatDateTime(now(),'%Y-%M-%d %H:%M');
-- 获取开始的分钟
SELECT toStartOfMinute(NOW()) as event_time;
2
3
4
5
6
# 2.计数 sql
SELECT
COUNT(1)
from
default.tmp_dws_day_org_pro_size_inv_ds_r1
WHERE
period_sdate >= '2019-03-01'
and period_sdate <= '2019-03-31';
2
3
4
5
6
7
# 3.排序函数
SELECT
rowNumberInAllBlocks()+ 1 AS total_SAL_rank
FROM
(
SELECT
o2.PERIOD_SDATE,
o2.total_SAL_QTY
FROM
o2
ORDER BY o2.total_SAL_QTY DESC
LIMIT 1 BY o2.PERIOD_SDATE
);
2
3
4
5
6
7
8
9
10
11
12
# 4.日期处理
将 int 类型转为 date 类型
parseDateTimeBestEffort(toString(20191201000407)) as wet
# 5.clickhouse 中的 join
ClickHouse JOIN 查询语法如下:
SELECT <expr_list>FROM <left_table>[GLOBAL] [INNER|LEFT|RIGHT|FULL|CROSS] [OUTER|SEMI|ANTI|ANY|ASOF] JOIN <right_table>(ON <expr_list>)|(USING <column_list>) ...
- 从 right_table 读取该表全量数据,在内存中构建 HASH MAP;
- 从 left_table 分批读取数据,根据 JOIN KEY 到 HASH MAP 中进行查找,如果命中,则该数据作为 JOIN 的输出;

从这个实现中可以看出,如果 right_table 的数据量超过单机可用内存空间的限制,则 JOIN 操作无法完成。通常,两表 JOIN 时,将较小表作为 right_table.
1.创建表
CREATE TABLE default.tmp_pro_size_contribution_rate
(
`product_key` String,
`size_code` String,
`sal_rank` UInt64,
`total_sal_qty` Nullable(Int64),
`total_sal_size_qty` Nullable(Int64),
`contribution_rate` Nullable(Float64)
)
ENGINE = MergeTree
ORDER BY (product_key,
size_code)
SETTINGS index_granularity = 8192;
CREATE TABLE default.tmp_pro_size_t12
(
`product_key` String,
`size_code` String,
`name` String
)
ENGINE = MergeTree
ORDER BY (product_key,
size_code)
SETTINGS index_granularity = 8192;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
2.插入数据
INSERT INTO default.tmp_pro_size_contribution_rate (`product_key`, `size_code`, `sal_rank`, `total_sal_qty`,
`total_sal_size_qty`, `contribution_rate`)
VALUES ('1', '215', 99, 98, 97, 50);
INSERT INTO default.tmp_pro_size_contribution_rate (`product_key`, `size_code`, `sal_rank`, `total_sal_qty`,
`total_sal_size_qty`, `contribution_rate`)
VALUES ('1', '220', 99, 98, 97, 50);
INSERT INTO default.tmp_pro_size_contribution_rate (`product_key`, `size_code`, `sal_rank`, `total_sal_qty`,
`total_sal_size_qty`, `contribution_rate`)
VALUES ('1', '225', 99, 98, 97, 50);
INSERT INTO default.tmp_pro_size_contribution_rate (`product_key`, `size_code`, `sal_rank`, `total_sal_qty`,
`total_sal_size_qty`, `contribution_rate`)
VALUES ('1', '230', 99, 98, 97, 50);
INSERT INTO default.tmp_pro_size_contribution_rate (`product_key`, `size_code`, `sal_rank`, `total_sal_qty`,
`total_sal_size_qty`, `contribution_rate`)
VALUES ('1', '235', 99, 98, 97, 50);
INSERT INTO default.tmp_pro_size_contribution_rate (`product_key`, `size_code`, `sal_rank`, `total_sal_qty`,
`total_sal_size_qty`, `contribution_rate`)
VALUES ('1', '240', 99, 98, 97, 50);
INSERT INTO default.tmp_pro_size_contribution_rate (`product_key`, `size_code`, `sal_rank`, `total_sal_qty`,
`total_sal_size_qty`, `contribution_rate`)
VALUES ('1', '245', 99, 98, 97, 50);
INSERT INTO default.tmp_pro_size_contribution_rate (`product_key`, `size_code`, `sal_rank`, `total_sal_qty`,
`total_sal_size_qty`, `contribution_rate`)
VALUES ('1', '250', 99, 98, 97, 50);
INSERT INTO default.tmp_pro_size_t12
(product_key, size_code, name)
VALUES('1', '215', '1');
INSERT INTO default.tmp_pro_size_t12
(product_key, size_code, name)
VALUES('1', '215', '2');
INSERT INTO default.tmp_pro_size_t12
(product_key, size_code, name)
VALUES('1', '220', '');
INSERT INTO default.tmp_pro_size_t12
(product_key, size_code, name)
VALUES('1', '225', '');
INSERT INTO default.tmp_pro_size_t12
(product_key, size_code, name)
VALUES('1', '230', '');
INSERT INTO default.tmp_pro_size_t12
(product_key, size_code, name)
VALUES('1', '235', '');
INSERT INTO default.tmp_pro_size_t12
(product_key, size_code, name)
VALUES('1', '240', '');
INSERT INTO default.tmp_pro_size_t12
(product_key, size_code, name)
VALUES('1', '245', '');
INSERT INTO default.tmp_pro_size_t12
(product_key, size_code, name)
VALUES('1', '250', '');
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
3.不带 any 查询
select * from default.tmp_pro_size_contribution_rate t1 left join default.tmp_pro_size_t12 t2 on t1.size_code = t2.size_code;
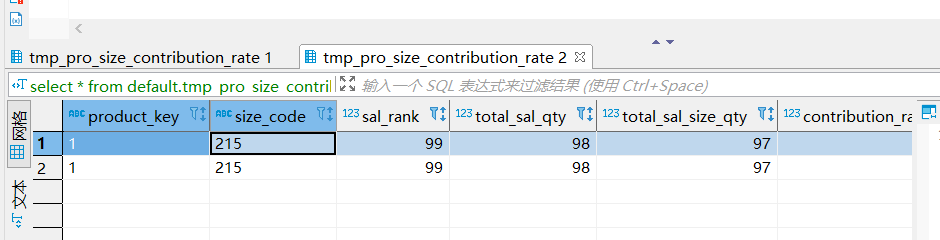
4.带 any 查询
select * from default.tmp_pro_size_contribution_rate t1 left any join default.tmp_pro_size_t12 t2 on t1.size_code=t2.size_code where size_code ='215';

5.总结
消除笛卡尔乘积最根本的原因不是在于连接,而是在于唯一 ID,就像学号,一个学生就只有一个学号,学号就是这个学生的唯一标识码。 左连接只是以左边的表为基准,左边的 ID 和右边 ID 都是唯一,就不会产生笛卡尔现象,如果右边有两个 ID 对应左边一个 ID,就算你是左连接,一样会产生 1 对多的现象。
使用 any 可以消除笛卡尔积,对结果集有一定的影响
# 6.case when
case when 在 clickhouse 中的使用
select case when new_old_product = 1 then '新货'
when new_old_product=2 then '旧货' else '新旧货'
end
,*
from default.table
where financial_year = '2023'
and financial_year_week = '1'
and new_old_product = 0
order by un_sal_week
;
2
3
4
5
6
7
8
9
10
# 7.日期加一
SELECT DATE_ADD('2023-07-11', INTERVAL 1 DAY) AS next_day;
# 8.除法小数
SELECT ROUND(column1 / column2, 4) AS division_result FROM your_table;
# 9.判断 null
SELECT * FROM your_table WHERE column1 IS NULL;
SELECT * FROM your_table WHERE column1 IS NOT NULL;
2
# 10.转换为整数
SELECT CAST(12.34 AS Int64) AS integer_value;
# 11.重复数据
SELECT period_sdate, product_key, size_code, managing_city_no
FROM ads_sense_rep.ads_day_city_brand_sku_size_rep
GROUP BY period_sdate, product_key, size_code, managing_city_no
HAVING COUNT(*) > 1;
2
3
4
# 五.修改操作
# 1.修改字段 sql
ALTER TABLE qac RENAME COLUMN provId TO `爽`
# 2.clickhouse 修改字段名
ALTER TABLE test_8 RENAME COLUMN teacher_name TO class_teacher_name;
# 3.clickhosue 复制数据
create table newtest as test;#先创建表
insert into newtest select * from test;#再插入数据
2
# 4.修改数据类型
ALTER table default.dws_day_mgmt_pro_sal_ds MODIFY COLUMN period_sdate Date COMMENT '日期(yyyy-mm-dd)'
# 5.修改备注
ALTER table default.dim_pro_allinfo modify COMMENT 'dim_商品信息表【商品】'
# 6.修改表名
RENAME TABLE back.dsd_back TO back.dsd_back_01;
# 六.删除相关
# 1.删除库
drop database IF EXISTS base_db
# 2.删除表
DROP table if EXISTS `default`.`test`
# 3.删除数据
alter table
default.table_name
delete
where
period_sdate >= '2020-03-01'
and period_sdate <= '2020-12-31';
2
3
4
5
6
# 4.清空数据
通过筛选条件:
-- ck清空表
ALTER table tmp.dim_pro_allinfo_bak delete where 1=1;
2
3
通过 TRUNCATE:
(clickhouse-hive-mysql 都是通用的)
TRUNCATE TABLE dbname.table
# 5.查询表大小
查询表大小
SELECT
sum(rows) AS `总行数`,
formatReadableSize(sum(data_uncompressed_bytes)) AS `原始大小`,
formatReadableSize(sum(data_compressed_bytes)) AS `压缩大小`,
round((sum(data_compressed_bytes) / sum(data_uncompressed_bytes)) * 100, 0) AS `压缩率`,
`table` AS `表名`
FROM system.parts where database = 'system' group by `table`
2
3
4
5
6
7
# 6.清理日志
方法一:使用clickhouse的mutation语句
alter table system.query_log delete where event_date < '2022-01-01'
方法二:直接删除分区
# 根据分区删除
alter table system.query_log drop partition '202201';
# 查看分区情况
SELECT * FROM system.parts where database = 'system' and `table`= 'query_log'
2
3
4
5
方式三:定期删除
ALTERTABLE query_log MODIFY TTL event_date + toIntervalDay(15);
方式四:配置文件
<query_log>
<database>system</database>
<table>query_log</table>
<engine>Engine = MergeTree PARTITION BY event_date ORDER BY event_time TTL event_date + INTERVAL 30 day</engine>
<flush_interval_milliseconds>7500</flush_interval_milliseconds>
</query_log>
2
3
4
5
6
# 七.时间日期函数
# 1.时间日期
SELECT
toDateTime('2016-06-15 23:00:00') AS time,
toDate(time) AS date_local,
toDate(time, 'Asia/Yekaterinburg') AS date_yekat,
toString(time, 'US/Samoa') AS time_samoa
┌────────────────time─┬─date_local─┬─date_yekat─┬─time_samoa──────────┐
│ 2016-06-15 23:00:00 │ 2016-06-15 │ 2016-06-16 │ 2016-06-15 09:00:00 │
└─────────────────────┴────────────┴────────────┴─────────────────────┘
2
3
4
5
6
7
8
9
# 2.时间函数
now() // 2020-04-01 17:25:40 取当前时间
toYear() // 2020 取日期中的年份
toMonth() // 4 取日期中的月份
today() // 2020-04-01 今天的日期
yesterday() // 2020-03-31 昨天的额日期
toDayOfYear() // 92 取一年中的第几天
toDayOfWeek() // 3 取一周中的第几天
toHour() //17 取小时
toMinute() //25 取分钟
toSecond() //40 取秒
toStartOfYear() //2020-01-01 取一年中的第一天
toStartOfMonth() //2020-04-01 取当月的第一天
formatDateTime(now(),'%Y-%m-%d') // 2020*04-01 指定时间格式
toYYYYMM() //202004
toYYYYMMDD() //20200401
toYYYYMMDDhhmmss() //20200401172540
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 3.当前日期相关
SELECT
toDateTime('2019-07-30 10:10:10') AS time,
-- 将DateTime转换成Unix时间戳
toUnixTimestamp(time) as unixTimestamp,
-- 保留 时-分-秒
toDate(time) as date_local,
toTime(time) as date_time, -- 将DateTime中的日期转换为一个固定的日期,同时保留时间部分。
-- 获取年份,月份,季度,小时,分钟,秒钟
toYear(time) as get_year,
toMonth(time) as get_month,
-- 一年分为四个季度。1(一季度:1-3),2(二季度:4-6),3(三季度:7-9),4(四季度:10-12)
toQuarter(time) as get_quarter,
toHour(time) as get_hour,
toMinute(time) as get_minute,
toSecond(time) as get_second,
-- 获取 DateTime中的当前日期是当前年份的第几天,当前月份的第几日,当前星期的周几
toDayOfYear(time) as "当前年份中的第几天",
toDayOfMonth(time) as "当前月份的第几天",
toDayOfWeek(time) as "星期",
toDate(time, 'Asia/Shanghai') AS date_shanghai,
toDateTime(time, 'Asia/Shanghai') AS time_shanghai,
-- 得到当前年份的第一天,当前月份的第一天,当前季度的第一天,当前日期的开始时刻
toStartOfYear(time),
toStartOfMonth(time),
toStartOfQuarter(time),
toStartOfDay(time) AS cur_start_daytime,
toStartOfHour(time) as cur_start_hour,
toStartOfMinute(time) AS cur_start_minute,
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
# 4.未来时间
-- 第一种,日期格式(指定日期,需注意时区的问题)
WITH
toDate('2019-09-09') AS date,
toDateTime('2019-09-09 00:00:00') AS date_time
SELECT
addYears(date, 1) AS add_years_with_date,
addYears(date_time, 0) AS add_years_with_date_time;
-- 第二种,日期格式(当前,本地时间)
WITH
toDate(now()) as date,
toDateTime(now()) as date_time
SELECT
now() as now_time,-- 当前时间
-- 之后1年
addYears(date, 1) AS add_years_with_date,
addYears(date_time, 1) AS add_years_with_date_time,
-- 之后1月
addMonths(date, 1) AS add_months_with_date,
addMonths(date_time, 1) AS add_months_with_date_time,
--之后1周
addWeeks(date, 1) AS add_weeks_with_date,
addWeeks(date_time, 1) AS add_weeks_with_date_time,
-- 之后1天
addDays(date, 1) AS add_days_with_date,
addDays(date_time, 1) AS add_days_with_date_time,
--之后1小时
addHours(date_time, 1) AS add_hours_with_date_time,
--之后1分中
addMinutes(date_time, 1) AS add_minutes_with_date_time,
-- 之后10秒钟
addSeconds(date_time, 10) AS add_seconds_with_date_time,
-- 之后1个季度
addQuarters(date, 1) AS add_quarters_with_date,
addQuarters(date_time, 1) AS add_quarters_with_date_time;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
# 5.获取最后 2 天
#日期年月日
SELECT *
FROM your_table
WHERE your_date_column >= today() - INTERVAL 2 DAY
;
#日期年月日时分秒
SELECT *
FROM your_table
WHERE toDate(your_date_column) >= today() - INTERVAL 2 DAY
;
2
3
4
5
6
7
8
9
10
# 6.获取前 n 天
#获取当前时间的N天前
select subtractDays(now(),n)
#获取指定日期的N天前
select subtractDays(toDateTime('2020-11-29 09:15:00'),n)
2
3
4
5
# 八.java 代码
# 1.代码分页
@Override
public PreviewData preview(Integer pageSize, Integer pageNo) {
DdlNode ddlNode = currentNode();
//输出节点运行直接写数据到目标表||非输出节点运行就是预览数据
if (NodeTypeEnum.OUT.name().equalsIgnoreCase(ddlNode.getType())) {
log("空,输出节点没有预览");
return PreviewData.builder().build();
} else {
this.checkNode();
PlainSelect plainSelect = this.sql();
//原始sql
String originalSql = plainSelect.toString();
String countSqlFormat = "select count(1) as count from (%s) ";
//计算总行数sql
String countSql = String.format(countSqlFormat, originalSql);
Integer readNum = mutableGraph().getReadNum();
readNum = readNum == null ? 1000 : readNum;
//计算起始行
int start = (pageNo - 1) * pageSize;
String preSql = originalSql;
//start 是起始行
//pageSize 是偏移量
if (!NodeTypeEnum.AGG.name().equalsIgnoreCase(ddlNode.getType())) {
preSql = preSql + " limit " + start + "," + pageSize;
} else {
preSql = "select * from (" + preSql + ") limit " + start + "," + pageSize;
}
List<DdlColumn> ddlColumns = this.columns();
List<Map<String, Object>> maps = getDdlClickHouseJdbcService().queryForList(preSql);
PreviewData previewData = convert(ddlColumns, maps);
List<Map<String, Object>> maps1 = getDdlClickHouseJdbcService().queryForList(countSql);
if (!CollectionUtils.isEmpty(maps1)) {
BigInteger count = (BigInteger) (maps1.get(0).get("count"));
if (count == null) {
previewData.setTotal(0L);
} else {
previewData.setTotal(count.longValue() <= readNum ? count.longValue() : readNum);
}
}
previewData.setSql(originalSql);
return previewData;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
# 2.代码建表
public Boolean createTable(CreateTableRequestDTO dto) {
StringBuilder createTableSql = new StringBuilder("create table ");
createTableSql.append("`")
.append(dto.getTableName())
.append("`")
.append("(");
List<CreateTableRequestDTO.Field> fields = dto.getFields();
String sql = fields.stream().map(t -> warpName(t.getFieldName()) + " " + "Nullable(" + t.getFieldType() + ")")
.collect(Collectors.joining(","));
createTableSql.append(sql).append(") engine = MergeTree() ORDER BY tuple()");
try {
jdbcTemplate.execute(createTableSql.toString());
} catch (DataAccessException e) {
throw new DdlException("创建表失败:" + e);
}
return true;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 3.代码增删改查
//生成备份表
String tempName = "temp_" + tableName + "_temp";
String sql1 = "create table " + warpName(dbName) + "." + warpName(tempName) + " as " + warpName(dbName) + "." + warpName(tableName);
super.getDdlClickHouseJdbcService().execute(sql1);
//处理for循环变量
this.handleCyclicVariate(connection, newSql, outputFields, tempName);
//修改原表的表名
String tempNameRemove = "temp_" + tableName + "_temp_remove";
String sql2 = "RENAME TABLE " + warpName(dbName) + "." + warpName(tableName) + " TO " + warpName(dbName) + "." + warpName(tempNameRemove);
super.getDdlClickHouseJdbcService().execute(sql2);
//将备份表表名改为原表表名
String sql3 = "RENAME TABLE " + warpName(dbName) + "." + warpName(tempName) + " TO " + warpName(dbName) + "." + warpName(tableName);
super.getDdlClickHouseJdbcService().execute(sql3);
//删除修改的原表
String sql4 = "DROP table "+ warpName(dbName) + "." + warpName(tempNameRemove);
super.getDdlClickHouseJdbcService().execute(sql4);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
02-Hive →