
# 一.简单介绍
# 1.什么是 RDD?
RDD 是“Resilient Distributed Dataset”的缩写,翻译为“弹性分布式数据集”。它是 Apache Spark 分布式计算框架中的基本数据抽象,用于在集群上执行并行处理。
RDD 是 Spark 中的核心数据结构,它代表分布式的、不可变的、弹性的数据集合。这意味着 RDD 可以在集群的不同节点上进行并行处理,它们是只读的,一旦创建就不可更改,但可以通过一系列转换操作来生成新的 RDD。此外,RDD 具有弹性,意味着在计算失败时,Spark 能够自动恢复并重新计算丢失的数据。
使用 RDD,Spark 可以将数据分割成一系列的分区,每个分区可以在集群中的不同节点上并行处理。这种并行处理和容错机制使得 Spark 在大规模数据处理和分布式计算方面具有高效性和弹性。
在较新的 Spark 版本中,Dataset 和 DataFrame 已经取代了 RDD 成为更为推荐的数据抽象,因为它们提供了更高层次的抽象和更多的优化机会。但是,RDD 仍然是 Spark 的基石,用于底层的数据处理和分布式计算场景。
# 2.什么是 DataFrame
Spark 中的 DataFrame 是一种分布式数据集,它是一种高级抽象,构建在弹性分布式数据集(RDD)之上。DataFrame 提供了更丰富的数据结构和 API,使得在 Spark 中进行数据处理更加简单、方便、高效。
DataFrame 可以看作是具有命名列的分布式数据表,类似于传统数据库或数据处理工具中的表格。它具有以下特点:
- 结构化数据:DataFrame 是结构化的数据,每个列都有一个名称和数据类型。这样可以更好地组织和处理数据,使得数据分析和查询更加方便。
- 不可变性:DataFrame 是不可变的数据结构,一旦创建,其内容不能被直接修改。相比之下,你可以通过转换操作生成新的 DataFrame。
- 惰性执行:Spark 中的 DataFrame 具有惰性执行特性。这意味着在进行数据处理时,实际的计算并不会立即执行,而是在遇到行动操作(例如 collect、show、count 等)时才会触发实际的计算。
- 分布式计算:DataFrame 是分布式的数据集,可以在集群中的多个节点上进行并行处理。Spark 会自动优化执行计划,以便充分利用集群资源。
- 内置函数和优化:Spark 提供了许多内置的高级函数和优化器,用于数据处理、查询、聚合等操作。这些内置函数可以加速处理速度,并且通常比手动编写 RDD 代码更加高效。
创建DataFrame的常见方法包括:
- 从已有的数据源(如文件、数据库、Hive 表等)中读取数据。
- 通过在已有的 RDD 上添加模式信息来转换成 DataFrame。
- 通过编程方式构建数据集。
使用 DataFrame,你可以像 SQL 一样进行查询、过滤、聚合等操作,也可以进行复杂的数据处理和转换。此外,Spark 还提供了与许多其他数据处理库(如 Pandas)的集成,使得在 Spark 中进行数据分析和处理更加灵活和强大。DataFrame 的出现大大简化了 Spark 的数据处理编程,并提高了代码的可读性和可维护性。
# 3.什么是 DataSet
在 Spark 中,DataSet 是一种更高级的分布式数据集抽象,它是 DataFrame 的扩展,结合了强类型和面向对象的特性。DataSet 在 Spark 1.6 版本中引入,是对 DataFrame 的类型安全扩展。
DataSet 与 DataFrame 的区别在于类型信息:
- 强类型:DataSet 是强类型的数据集合,它使用 Scala 或 Java 的类来表示每个记录,这样在编译时就可以检查类型的一致性。这使得在处理数据时更加安全,减少了在运行时出现类型错误的可能性。
- 编译时检查:由于 DataSet 是强类型的,所以在对数据进行操作时,编译器可以在编译阶段检查数据的类型,而不是在运行时发现错误。这有助于在开发过程中更早地发现错误,提高代码的可靠性和性能。
- 面向对象:DataSet 中的数据被组织为一组对象,每个对象对应于一个记录。这使得在处理复杂数据结构时更加直观和方便。
虽然 DataSet 是 DataFrame 的扩展,但在实际使用中,可以将 DataSet 视为 DataFrame 的一种特殊形式。DataSet API 和 DataFrame API 非常相似,大部分操作都可以在两者之间互相转换。
DataSet的创建方式包括:
- 从已有的 DataFrame 中转换:可以通过调用
as方法,将 DataFrame 转换为 DataSet。这样可以利用强类型特性对数据进行类型安全的处理。 - 从已有的 RDD 中转换:可以通过调用
toDS方法,将 RDD 转换为 DataSet。需要提供一个 Encoder 来描述如何将 RDD 中的数据映射到 DataSet 中的类。 - 从数据源读取:可以通过 SparkSession 的 read API 从数据源(如文件、数据库、Hive 表等)中读取数据并创建 DataSet。
使用 DataSet,可以利用 Scala 或 Java 中的类和对象来表示数据,而不仅仅是简单的行和列。这使得在编写 Spark 应用程序时,能够更好地结合面向对象的编程范式,编写更具表现力和易于维护的代码。DataSet 对于需要类型安全和面向对象的数据处理场景非常有用。
# 4.RDD 和 DataFrame 和 DataSet?
在 SparkSQL 中 Spark 为我们提供了两个新的抽象,分别是 DataFrame 和 DataSet 。
首先从版本的产生上来看:
- Spark1.0 => RDD
- Spark1.3 => DataFrame
- Spark1.6 => Dataset
如果同样的数据都给到这三个数据结构,他们分别计算之后,都会给出相同的结果。不同是的他们的执行效率和执行方式。在后期的 Spark 版本中, DataSet 有可能会逐步取代 RDD 和 DataFrame 成为唯一的 API 接口。
三者的共性:
RDD 、 DataFrame 、 DataSet 全都是 spark 平台下的分布式弹性数据集,为处理超大型数 据提供便利;
三者都有惰性机制,在进行创建、转换,如 map 方法时,不会立即执行,只有在遇到 Action 如 foreach 时,三者才会开始遍历运算 ;
三者有许多共同的函数,如 filter ,排序等 ;
在对 DataFrame 和 Dataset 进行操作许多操作都需要这个包 : import spark.implicits._ (在 创建好 SparkSession 对象后尽量直接导入)
三者都会根据 Spark 的内存情况自动缓存运算,这样即使数据量很大,也不用担心会 内存溢出
三者都有 partition 的概念。
DataFrame 和 DataSet 均可使用模式匹配获取各个字段的值和类型
三者的区别:
- RDD
- RDD 一般和 spark mllib 同时使用
- RDD 不支持 sparksql 操作
- DataFrame
- 与 RDD 和 Dataset 不同, DataFrame 每一行的类型固定为 Row ,每一列的值没法直 接访问,只有通过解析才能获取各个字段的值
- DataFrame 与 DataSet 一般不与 spark mllib 同时使用
- DataFrame 与 DataSet 均支持 SparkSQL 的操作,比如 select , groupby 之类,还能 注册临时表/ 视窗,进行 sql 语句操作
- DataFrame 与 DataSet 支持一些特别方便的保存方式,比如保存成 csv ,可以带上表 头,这样每一列的字段名一目了然( 后面专门讲解 )
- DataSet
- Dataset 和 DataFrame 拥有完全相同的成员函数,区别只是每一行的数据类型不同 DataFrame 其实就是 DataSet 的一个特例 type DataFrame = Dataset[Row]
- DataFrame 也可以叫 Dataset[Row], 每一行的类型是 Row ,不解析,每一行究竟有哪 些字段,各个字段又是什么类型都无从得知,只能用上面提到的 getAS 方法或者共性中的第七条提到的模匹配拿出特定字段。而 Dataset 中,每一行是什么类型是 不一定的,在自定义了 case class 之后可以很自由的获得每一行的信息。
# 5.spark 部署模式
- Hadoop YARN
- Apache Mesos (deprecated)
- Kubernetes
- Standalone Mode (最简单的方式)
# 6.作业提交模版
./bin/spark-submit \
--class <main-class> \ # 应用程序主入口类
--master <master-url> \ # 集群的 Master Url
--deploy-mode <deploy-mode> \ # 部署模式
--conf <key>=<value> \ # 可选配置
... # other options
<application-jar> \ # Jar 包路径
[application-arguments] #传递给主入口类的参数
2
3
4
5
6
7
8
# 7.Local 模式
# 本地模式提交应用
spark-submit \
--class org.apache.spark.examples.SparkPi \
--master local[2] \
/usr/app/spark-2.4.0-bin-hadoop2.6/examples/jars/spark-examples_2.11-2.4.0.jar \
100 # 传给 SparkPi 的参数
2
3
4
5
6
# 8.Standalone 模式
1.底层设计
Standalone 是 Spark 提供的一种内置的集群模式,采用内置的资源管理器进行管理。下面按照如图所示演示 1 个 Mater 和 2 个 Worker 节点的集群配置,这里使用两台主机进行演示:
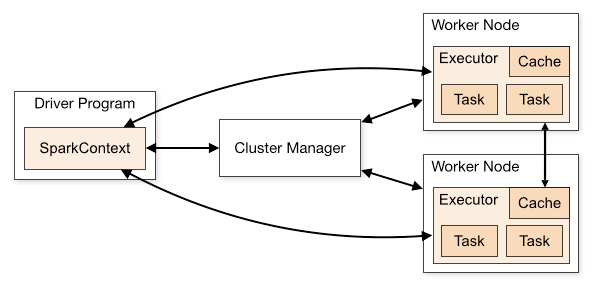
- hadoop001: 由于只有两台主机,所以 hadoop001 既是 Master 节点,也是 Worker 节点;
- hadoop002 : Worker 节点。
2.注意事项
主机名与 IP 地址的映射必须在 /etc/hosts 文件中已经配置,否则就直接使用 IP 地址;
每个主机名必须独占一行;
Spark 的 Master 主机是通过 SSH 访问所有的 Worker 节点,所以需要预先配置免密登录。
3.独立模式服务器地址
#spark目录
cd /data/spark/spark-3.1.2-bin-hadoop3.2
2
4.cluster 模式启动
HiveExercise
./bin/spark-submit \
--class com.deepexi.toreador.spark.sql.HiveExercise \
--master spark://deep01.cdh:17077 \
--deploy-mode cluster \
--executor-memory 1G \
--total-executor-cores 2 \
--conf spark.sql.hive.metastore.version=2.1.1 \
--conf spark.sql.hive.metastore.jars=/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/hive/lib/* \
/data/spark/jars/toreador-spark-0.0.1-SNAPSHOT.jar \
file:/data/spark/datasets/dealer.json
2
3
4
5
6
7
8
9
10
# 独立模式cluster模式日志存放位置
spark.eventLog.enabled true
spark.eventLog.dir hdfs://deep03.cdh:8020/spark/standalong/logs
2
3
MysqlExercise
./bin/spark-submit \
--class com.deepexi.toreador.spark.sql.MysqlExercise \
--master spark://deep01.cdh:17077 \
--deploy-mode cluster \
--executor-memory 1G \
--total-executor-cores 2 \
--conf spark.sql.hive.metastore.version=2.1.1 \
--conf spark.sql.hive.metastore.jars=/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/hive/lib/* \
/data/spark/jars/toreador-spark-0.0.1-SNAPSHOT.jar \
file:/data/spark/datasets/dealer.json
2
3
4
5
6
7
8
9
10
State of driver-20220830191420-0001 is RUNNING
GroupByExercise
./bin/spark-submit \
--class com.deepexi.toreador.spark.sql.GroupByExercise \
--master spark://deep01.cdh:17077 \
--deploy-mode cluster \
--executor-memory 1G \
--total-executor-cores 2 \
--conf spark.sql.hive.metastore.version=2.1.1 \
--conf spark.sql.hive.metastore.jars=/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/hive/lib/* \
/data/spark/jars/toreador-spark-0.0.1-SNAPSHOT.jar \
file:/data/spark/datasets/dealer.json
2
3
4
5
6
7
8
9
10
5.client 模式启动
./bin/spark-submit \
--class com.deepexi.toreador.spark.sql.HiveExercise \
--master spark://deep01.cdh:17077 \
--deploy-mode client \
--executor-memory 1G \
--total-executor-cores 2 \
--conf spark.sql.hive.metastore.version=2.1.1 \
--conf spark.sql.hive.metastore.jars=/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/hive/lib/* \
/data/spark/jars/toreador-spark-0.0.1-SNAPSHOT.jar \
file:/data/spark/datasets/dealer.json
2
3
4
5
6
7
8
9
10
6.杀掉任务
./bin/spark-class org.apache.spark.deploy.Client kill spark://deep01.cdh:17077 driver-20220830191420-0001
# 9.yarn 模式
1.服务器地址
#账号
ssh -p 22 root@deep03.cdh
#spark目录
cd /data/spark/spark-3.1.2-onyarn
#历史服务器
http://deep03.cdh:28082
2
3
4
5
6
7
8
2.cluster 模式启动
./bin/spark-submit \
--class com.deepexi.toreador.spark.sql.HiveExercise \
--master yarn \
--deploy-mode cluster \
--executor-memory 1G \
--executor-cores 2 \
--queue root.default \
--conf spark.sql.hive.metastore.version=2.1.1 \
--conf spark.sql.hive.metastore.jars=/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/hive/lib/* \
/data/spark/jars/toreador-spark-0.0.1-SNAPSHOT.jar
2
3
4
5
6
7
8
9
10
./bin/spark-submit \
--class com.deepexi.toreador.spark.sql.HiveExercise3 \
--master yarn \
--deploy-mode cluster \
--executor-memory 1G \
--executor-cores 2 \
--queue root.default \
--conf spark.sql.hive.metastore.version=2.1.1 \
--conf spark.sql.hive.metastore.jars=/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/hive/lib/* \
/data/spark/jars/toreador-spark-0.0.1-SNAPSHOT.jar \
file:/data/spark/datasets/dealer.json
2
3
4
5
6
7
8
9
10
11
3.client 模式启动
./bin/spark-submit \
--class com.deepexi.toreador.spark.sql.HiveExercise \
--master yarn \
--deploy-mode client \
--executor-memory 1G \
--executor-cores 2 \
--queue root.default \
--conf spark.sql.hive.metastore.version=2.1.1 \
--conf spark.sql.hive.metastore.jars=/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/hive/lib/* \
/data/spark/jars/toreador-spark-0.0.1-SNAPSHOT.jar
2
3
4
5
6
7
8
9
10
# 10.spark 调研信息
SQL (Data Retrieval Statements 部分) (opens new window)
UDF (User-Defined Functions)部分 (opens new window)
https://spark.apache.org/docs/latest/sql-ref-syntax.html SQL (Data Retrieval Statements部分)
https://spark.apache.org/docs/latest/running-on-yarn.html (yarn部署模式)
https://spark.apache.org/docs/latest/spark-standalone.html(独立部署模式)
https://spark.apache.org/docs/latest/monitoring.html (web api)
https://spark.apache.org/docs/latest/configuration.html (配置)
https://spark.apache.org/docs/latest/sql-ref-functions.html(UDFs (User-Defined Functions)部分)
2
3
4
5
6
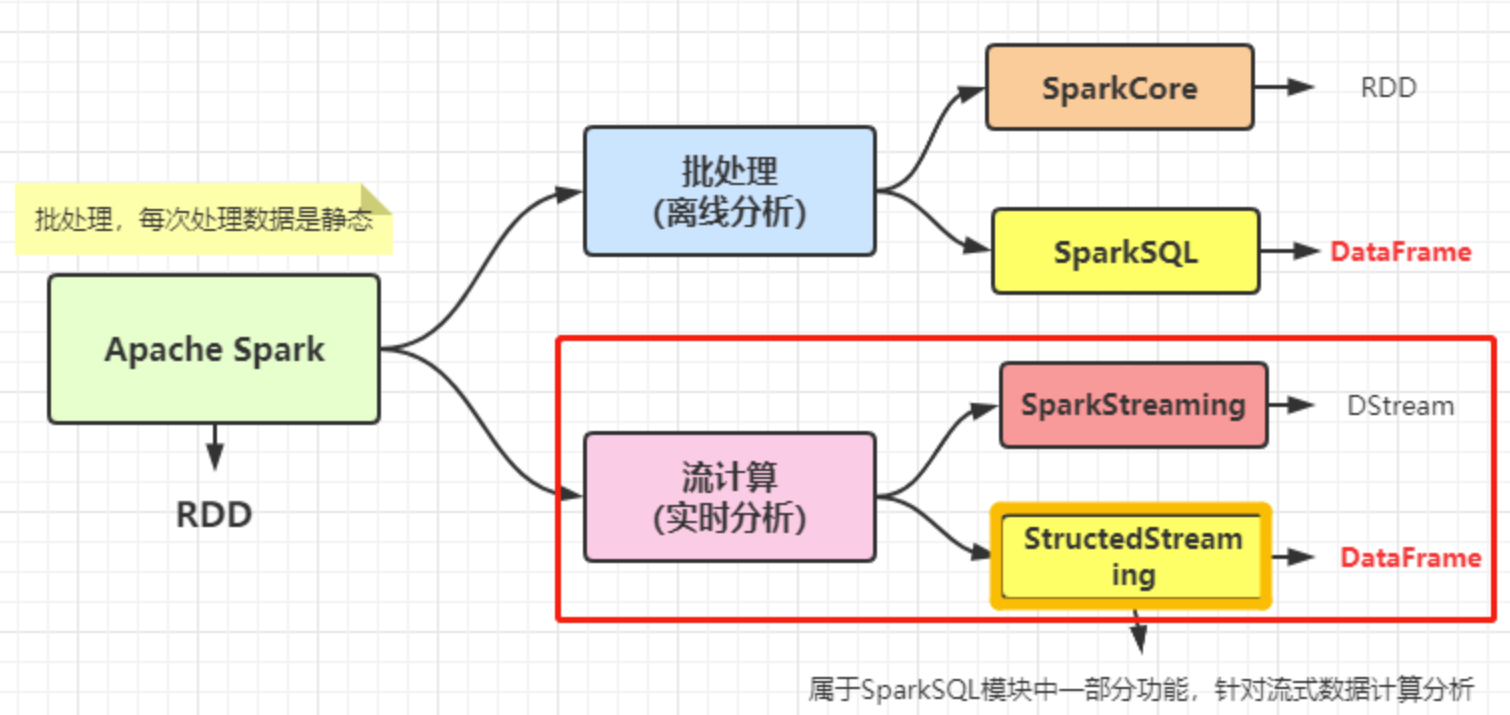
RDD,全称为 Resilient Distributed Datasets,是一个容错的、并行的数据结构,弹性分布式数据集.
运行状态
- active
- complete
- pending
- failed
task 状态
- RUNNING
- SUCCESS
- FAILED
- KILLED
- PENDING
# 二.YARN
# 1.YARN 介绍
Yarn 的框架也是经典的主从结构,和 HDFS 的一样,大体上 yarn 由一个 ResourceManager 和多个 NodeManager 构成,RM 为主节点,NM 为从节点。
| 组件名 | 作用 |
|---|---|
| ResourceManager | 是 Master 上一个独立运行的进程,负责集群统一的资源管理、调度、分配等等; |
| ApplicationManager | 相当于这个 Application 的监护人和管理者,负责监控、管理这个 Application 的所有 Attempt 在 cluster 中各个节点上的具体运行,同时负责向 Yarn ResourceManager 申请资源、返还资源等; |
| NodeManager | 是 Slave 上一个独立运行的进程,负责上报节点的状态(磁盘,内存,cpu 等使用信息); |
| Container | 是 yarn 中分配资源的一个单位,包涵内存、CPU 等等资源,YARN 以 Container 为单位分配资源; |
ResourceManager: 1、接收客户端请求 2、为系统资源分配 3、与 NM 进行心跳交互,监控集群 4、调度组件 Scheduler RM 挂掉: 单点故障:基于 Zookeeper 实现 HA,主提供服务, 备同步主的信息,如果主挂掉,立即主备切换 ApplicationManager/ApplicationMaster (MR 任务启动时候 jps 有 MRAppmaster,任务完成就没了) 1、应用程序的 Master 2、每一个 Job 对应一个 AM 3、AM 和 RM 不在一个机器 4、AM 申请 RM 资源调度 5、AM 联合 NM 监控 job AM 挂掉: RM 负责重启 无需重新运行已完成的任务 NodeManager:(只管内存资源) 1、对应 1.0TaskTracker 的角色 2、负责启动应用程序的 Container 3、监控内部容器资源使用情况,心跳 RM NM 挂掉: 心跳消失,RM 通知 AM 进一步处理 Container: 1、任务运行环境的封装 2、AM 及普通任务均运行在 Container 中 3、资源代表
工作流程
应用程序提交 --> 申请资源 --> 启动 ApplicationMaster --> 申请运行任务的 Container --> 分发 Container --> 运行 task 任务 --> task 任务结束 --> 回收 Container。
# 2.以集群模式启动
$ ./bin/spark-submit --class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
--driver-memory 4g \
--executor-memory 2g \
--executor-cores 1 \
--queue thequeue \
examples/jars/spark-examples*.jar \
10
2
3
4
5
6
7
8
9
# 3.客户机模式启动
$ ./bin/spark-shell --master yarn --deploy-mode client
# 4.查看日志
yarn logs -applicationId <app ID>
# 三.spark 配置
# 1.Spark 配置系统
- 可以通过 SparkConf 进行配置.
- conf/park-env 设置每台机器的设置
- log4j2.properties 配置日志记录
# 2.具体配置
Application Properties 里面是配置参数.
val conf = new SparkConf()
.setMaster("local[2]")
.setAppName("CountingSheep")
val sc = new SparkContext(conf)
2
3
4
# 3.运行时配置
val sc = new SparkContext(new SparkConf())
./bin/spark-submit --name "My app" --master local[4] --conf spark.eventLog.enabled=false
--conf "spark.executor.extraJavaOptions=-XX:+PrintGCDetails -XX:+PrintGCTimeStamps" myApp.jar
2
# 四.spark 函数
# 1.数组函数
SELECT array(1, 2, 3);
SELECT array_distinct(array(1, 2, 3, null, 3));
SELECT array_except(array(1, 2, 3), array(1, 3, 5));
SELECT array_join(array('hello', 'world'), ' ');
2
3
4
5
6
7
# 2.Map Functions
SELECT map(1.0, '2', 3.0, '4');
SELECT map_concat(map(1, 'a', 2, 'b'), map(3, 'c'));
SELECT map_contains_key(map(1, 'a', 2, 'b'), 1);
2
3
4
5
# 3.日期函数
SELECT add_months('2016-08-31', 1);
SELECT current_date();
SELECT current_date;
SELECT current_timestamp();
SELECT date_add('2016-07-30', 1);
SELECT date_sub('2016-07-30', 1);
SELECT datediff('2009-07-31', '2009-07-30');
SELECT day('2009-07-30');
SELECT dayofmonth('2009-07-30');
SELECT dayofweek('2009-07-30');
SELECT dayofyear('2016-04-09');
SELECT last_day('2009-01-12');
SELECT year('2016-07-30');
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# 4.JSON Functions
SELECT from_json('{"a":1, "b":0.8}', 'a INT, b DOUBLE');
SELECT get_json_object('{"a":"b"}', '$.a');
SELECT json_array_length('[1,2,3,4]');
2
3
4
5
6
7
# 5.聚合函数
- MAX
- MIN
- SUM
- AVG
- EVERY
- ANY
- SOME
SELECT any(col) FROM VALUES (true), (false), (false) AS tab(col);
SELECT avg(col) FROM VALUES (1), (2), (3) AS tab(col);
SELECT collect_list(col) FROM VALUES (1), (2), (1) AS tab(col);
SELECT collect_set(col) FROM VALUES (1), (2), (1) AS tab(col);
-- 方差
SELECT corr(c1, c2) FROM VALUES (3, 2), (3, 3), (6, 4) as tab(c1, c2);
SELECT count(*) FROM VALUES (NULL), (5), (5), (20) AS tab(col);
SELECT count(DISTINCT col) FROM VALUES (NULL), (5), (5), (10) AS tab(col);
2
3
4
5
6
7
8
9
10
11
12
13
14
# 6.窗口函数
-- cume_dist() over() 计算一个值相对于分区中所有值的位置。
SELECT a, b, rank(b) OVER (PARTITION BY a ORDER BY b) FROM VALUES ('A1', 2), ('A1', 1), ('A2', 3), ('A1', 1) tab(a, b);
SELECT a, b, row_number() OVER (PARTITION BY a ORDER BY b) FROM VALUES ('A1', 2), ('A1', 1), ('A2', 3), ('A1', 1) tab(a, b);
2
3
4
5
# 7.自定义函数
//获取SparkSession
SparkSession spark = SparkSession
.builder()
.appName("Java Spark SQL UDF scalar example")
.getOrCreate();
//定义函数
UserDefinedFunction random = udf(
() -> Math.random(), DataTypes.DoubleType
);
random.asNondeterministic();
//注册函数
spark.udf().register("random", random);
//执行自定义函数
spark.sql("SELECT random()").show();
spark.udf().register("plusOne",
(UDF1<Integer, Integer>) x -> x + 1, DataTypes.IntegerType);
spark.sql("SELECT plusOne(5)").show();
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 五.spark-sql
# 1.Datasets 和 DataFrames
- Datasets:据集是数据的分布式集合。RDD 算子
- DataFrames:DataFrame 是组织成命名列的数据集。
而在 JavaAPI 中,用户需要使用 Dataset < Row > 来表示 DataFrame。
# 2.spark-java 入口
import org.apache.spark.sql.SparkSession;
SparkSession spark = SparkSession
.builder()
.appName("Java Spark SQL basic example")
.config("spark.some.config.option", "some-value")
.getOrCreate();
2
3
4
5
6
7
# 3.创建 DataFrame
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
Dataset<Row> df = spark.read().json("examples/src/main/resources/people.json");
// Displays the content of the DataFrame to stdout
df.show();
2
3
4
5
6
7
# 4.DataFrame 操作
df.printSchema();
df.select("name").show();
df.select(col("name"), col("age").plus(1)).show();
df.filter(col("age").gt(21)).show();
df.groupBy("age").count().show();
df.createOrReplaceTempView("people");
Dataset<Row> sqlDF = spark.sql("SELECT * FROM people");
sqlDF.show();
//添加对象
Encoder<Person> personEncoder = Encoders.bean(Person.class);
Dataset<Person> javaBeanDS = spark.createDataset(
Collections.singletonList(person),
personEncoder
);
javaBeanDS.show();
//获取属性值
Dataset<Row> teenagersDF = spark.sql("SELECT name FROM people WHERE age BETWEEN 13 AND 19");
Encoder<String> stringEncoder = Encoders.STRING();
Dataset<String> teenagerNamesByIndexDF = teenagersDF.map(
(MapFunction<Row, String>) row -> "Name: " + row.getString(0),
stringEncoder);
teenagerNamesByIndexDF.show();
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
# 5.获取数据源
- 读取文件
- 读取 hive 库
spark.sql("SELECT * FROM src").show();
# 6.写入数据库
Dataset<Row> jdbcDF = spark.read()
.format("jdbc")
.option("url", "jdbc:postgresql:dbserver")
.option("dbtable", "schema.tablename")
.option("user", "username")
.option("password", "password")
.load();
Properties connectionProperties = new Properties();
connectionProperties.put("user", "username");
connectionProperties.put("password", "password");
Dataset<Row> jdbcDF2 = spark.read()
.jdbc("jdbc:postgresql:dbserver", "schema.tablename", connectionProperties);
// Saving data to a JDBC source
jdbcDF.write()
.format("jdbc")
.option("url", "jdbc:postgresql:dbserver")
.option("dbtable", "schema.tablename")
.option("user", "username")
.option("password", "password")
.save();
jdbcDF2.write()
.jdbc("jdbc:postgresql:dbserver", "schema.tablename", connectionProperties);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# 7.数据类型
| Data type | Value type in Java | API to access or create a data type |
|---|---|---|
| ByteType | byte or Byte | DataTypes.ByteType |
| ShortType | short or Short | DataTypes.ShortType |
| IntegerType | int or Integer | DataTypes.IntegerType |
| LongType | long or Long | DataTypes.LongType |
| FloatType | float or Float | DataTypes.FloatType |
| DoubleType | double or Double | DataTypes.DoubleType |
| DecimalType | java.math.BigDecimal | DataTypes.createDecimalType() DataTypes.createDecimalType(precision, scale). |
| StringType | String | DataTypes.StringType |
| BinaryType | byte[] | DataTypes.BinaryType |
| BooleanType | boolean or Boolean | DataTypes.BooleanType |
| TimestampType | java.sql.Timestamp | DataTypes.TimestampType |
| DateType | java.sql.Date | DataTypes.DateType |
| YearMonthIntervalType | java.time.Period | YearMonthIntervalType |
| DayTimeIntervalType | java.time.Duration | DayTimeIntervalType |
| ArrayType | java.util.List | DataTypes.createArrayType(elementType) Note: The value of containsNull will be true. DataTypes.createArrayType(elementType, containsNull). |
| MapType | java.util.Map | DataTypes.createMapType(keyType, valueType) Note: The value of valueContainsNull will be true. DataTypes.createMapType(keyType, valueType, valueContainsNull) |
| StructType | org.apache.spark.sql.Row | DataTypes.createStructType(fields) Note: fields is a List or an array of StructFields.Also, two fields with the same name are not allowed. |
| StructField | The value type in Java of the data type of this field (For example, int for a StructField with the data type IntegerType) | DataTypes.createStructField(name, dataType, nullable) |
# 六.SQL 语法
# 1.ALTER DATABASE
-- 创建数据库
CREATE DATABASE inventory;
CREATE DATABASE IF NOT EXISTS customer_db;
CREATE DATABASE inventory_db COMMENT 'This database is used to maintain Inventory';
-- 选用数据库
USE userdb;
-- 修改数据库的编辑人和编辑时间
ALTER DATABASE inventory SET DBPROPERTIES ('Edited-by' = 'John', 'Edit-date' = '01/01/2001');
-- 展示库的描述信息
DESCRIBE DATABASE EXTENDED inventory;
-- 修改库的存储位置
ALTER DATABASE inventory SET LOCATION 'file:/temp/spark-warehouse/new_inventory.db';
-- 删除库
DROP DATABASE IF EXISTS inventory_db CASCADE;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 2.ALTER TABLE
-- 显示表描述
DESC student;
-- 修改表名
ALTER TABLE Student RENAME TO StudentInfo;
-- 显示表分区
SHOW PARTITIONS StudentInfo;
-- 修改表分区
ALTER TABLE default.StudentInfo PARTITION (age='10') RENAME TO PARTITION (age='15');
-- 添加列
ALTER TABLE StudentInfo ADD columns (LastName string, DOB timestamp);
-- 删除列
ALTER TABLE StudentInfo DROP columns (LastName, DOB);
-- 修改列名
ALTER TABLE StudentInfo RENAME COLUMN name TO FirstName;
-- 修改字段备注信息
ALTER TABLE StudentInfo ALTER COLUMN FirstName COMMENT "new comment";
-- 替换字段
ALTER TABLE StudentInfo REPLACE COLUMNS (name string, ID int COMMENT 'new comment');
-- 添加分区
ALTER TABLE StudentInfo ADD IF NOT EXISTS PARTITION (age=18);
-- 删除分区
ALTER TABLE StudentInfo DROP IF EXISTS PARTITION (age=18);
-- 添加多个分区
ALTER TABLE StudentInfo ADD IF NOT EXISTS PARTITION (age=18) PARTITION (age=20);
-- 删除表
DROP TABLE IF EXISTS employeetable;
-- 修复表
MSCK REPAIR TABLE t1;
-- 清空表
TRUNCATE TABLE Student;
-- 创建表
CREATE TABLE students (name VARCHAR(64), address VARCHAR(64))
USING PARQUET PARTITIONED BY (student_id INT);
-- 插入一条数据
INSERT INTO students VALUES
('Amy Smith', '123 Park Ave, San Jose', 111111);
-- 插入多条
INSERT INTO students VALUES
('Bob Brown', '456 Taylor St, Cupertino', 222222),
('Cathy Johnson', '789 Race Ave, Palo Alto', 333333);
-- 插入select的数据
INSERT INTO students PARTITION (student_id = 444444)
SELECT name, address FROM persons WHERE name = "Dora Williams";
-- 插入指定分区
INSERT INTO students PARTITION (birthday = date'2019-01-02')
VALUES ('Amy Smith', '123 Park Ave, San Jose');
-- 覆盖插入
INSERT OVERWRITE students PARTITION (student_id = 222222)
SELECT name, address FROM persons WHERE name = "Dora Williams";
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
# 3.ALTER VIEW
ALTER VIEW tempdb1.v1 RENAME TO tempdb1.v2;
DESCRIBE TABLE EXTENDED tempdb1.v2;
ALTER VIEW tempdb1.v2 AS SELECT * FROM tempdb1.v1;
-- 创建视图
CREATE GLOBAL TEMPORARY VIEW IF NOT EXISTS subscribed_movies
AS
SELECT mo.member_id, mb.full_name, mo.movie_title
FROM movies AS mo
INNER JOIN members AS mb
ON mo.member_id = mb.id;
-- 删除视图
DROP VIEW IF EXISTS employeeView;
2
3
4
5
6
7
8
9
10
11
12
13
# 4.CREATE FUNCTION
CREATE FUNCTION simple_udf AS 'SimpleUdf' USING JAR '/tmp/SimpleUdf.jar';
SHOW USER FUNCTIONS;
DROP TEMPORARY FUNCTION IF EXISTS test_avg;
DROP FUNCTION test_avg;
2
3
4
# 5.查询相关
[ WITH with_query [ , ... ] ]
select_statement [ { UNION | INTERSECT | EXCEPT } [ ALL | DISTINCT ] select_statement, ... ]
[ ORDER BY { expression [ ASC | DESC ] [ NULLS { FIRST | LAST } ] [ , ... ] } ]
[ SORT BY { expression [ ASC | DESC ] [ NULLS { FIRST | LAST } ] [ , ... ] } ]
[ CLUSTER BY { expression [ , ... ] } ]
[ DISTRIBUTE BY { expression [, ... ] } ]
[ WINDOW { named_window [ , WINDOW named_window, ... ] } ]
[ LIMIT { ALL | expression } ]
2
3
4
5
6
7
8
-- with as语法
WITH t(x, y) AS (SELECT 1, 2)
SELECT *
FROM t
WHERE x = 1
AND y = 2;
-- 内层with as
WITH t AS (
WITH t2 AS (SELECT 1)
SELECT *
FROM t2
)
SELECT *
FROM t;
-- 分区和排序字段相同
SELECT age, name
FROM person CLUSTER BY age;
-- 分区
SELECT age, name
FROM person DISTRIBUTE BY age;
-- 分组
SELECT id, SUM(quantity)
FROM dealer
GROUP BY id
ORDER BY id;
-- HAVING子句
SELECT city, SUM(quantity) AS SUM
FROM dealer
GROUP BY city
HAVING SUM (quantity) > 15;
-- hints
SELECT /*+ COALESCE(3) */ *
FROM t;
SELECT /*+ REPARTITION(3) */ *
FROM t;
SELECT /*+ REPARTITION_BY_RANGE(c) */ *
FROM t;
SELECT /*+ REBALANCE */ *
FROM t;
-- 内联表
SELECT *
FROM VALUES("one", 1)
, ("two", 2)
, ("three", NULL) AS data(a, b);
-- 连接
SELECT id, name, employee.deptno, deptname
FROM employee
INNER JOIN department ON employee.deptno = department.deptno;
-- like使用
SELECT *
FROM person
WHERE name LIKE 'M%';
-- limit 使用
SELECT name, age
FROM person
ORDER BY name LIMIT 2;
-- 排序
SELECT *
FROM person
ORDER BY name ASC, age DESC;
-- UNION去重
(SELECT c FROM number1)
UNION
DISTINCT
(
SELECT C
FROM number2);
-- UNION不去重
SELECT c
FROM number1
UNION ALL
(SELECT c FROM number2);
-- 按分区,排序
SELECT /*+ REPARTITION(zip_code) */ name, age, zip_code
FROM person SORT BY NAME;
-- where 使用
SELECT *
FROM person
WHERE id BETWEEN 200 AND 300
ORDER BY id;
-- 窗口函数
SELECT name, dept, salary, MIN(salary) OVER (PARTITION BY dept ORDER BY salary) AS MIN
FROM employees;
-- case when使用
SELECT *
FROM person
WHERE CASE 1 = 1
WHEN 100 THEN 'big'
WHEN 200 THEN 'bigger'
WHEN 300 THEN 'biggest'
ELSE 'small'
END = 'small';
-- 行转列
SELECT *
FROM person PIVOT (
SUM(age) AS a, AVG(class) AS C
FOR NAME IN ('John' AS john, 'Mike' AS mike)
);
-- 列转行
SELECT c_age, COUNT(1)
FROM person LATERAL VIEW EXPLODE(ARRAY(30, 60)) AS c_age
LATERAL VIEW EXPLODE(ARRAY(40, 80)) AS d_age
GROUP BY c_age;
-- 执行计划
EXPLAIN
SELECT k, SUM(v)
FROM values(1, 2), (1, 3) t(k, v)
GROUP BY k;
EXPLAIN
EXTENDED
SELECT k, SUM(v)
FROM values(1, 2), (1, 3) t(k, v)
GROUP BY k;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
# 6.辅助信息
-- 添加jar包
ADD JAR /tmp/test.jar;
-- 分析表
ANALYZE
TABLE students COMPUTE STATISTICS FOR COLUMNS NAME;
-- 所有jar文件
LIST
JAR;
-- 刷新表
REFRESH
TABLE tempDB.view1;
-- 展示列
SHOW
COLUMNS IN salesdb.customer;
-- 展示建表信息
SHOW
CREATE TABLE test;
-- 展示分区
SHOW
PARTITIONS salesdb.customer;
-- 显示所有表
SHOW
TABLES IN userdb;
-- 显示视图
SHOW
VIEWS FROM userdb;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
# 七.ddl-spark
# 1.获取节点关系
Map<String, Set<String>> flowCache = dag.getFlows().stream()
.collect(Collectors.groupingBy(Flow::getTo, Collectors.mapping(Flow::getFrom, Collectors.toSet())));
2
# 2.获取实现 node
//通过反射获取到实现类并调用initFromDdlNode方法
AbstractNode node = Reflect.onClass(nodeTypeEnum.getClassName()).create().call("initFromDdlNode", ddlNode, flowCache.get(ddlNode.getNodeKey())).get();
nodeCache.put(node.getNodeKey(), node);
2
3
# 3.java-api
在 Dataset 中有算子的 api
Dataset<T>
# 4.agg 函数
//agg函数不能直接传入Columns
result = groupDs.agg(first, rest);
2
← 02-Hive