
# 一.基础概念
# 1.Spring 模块

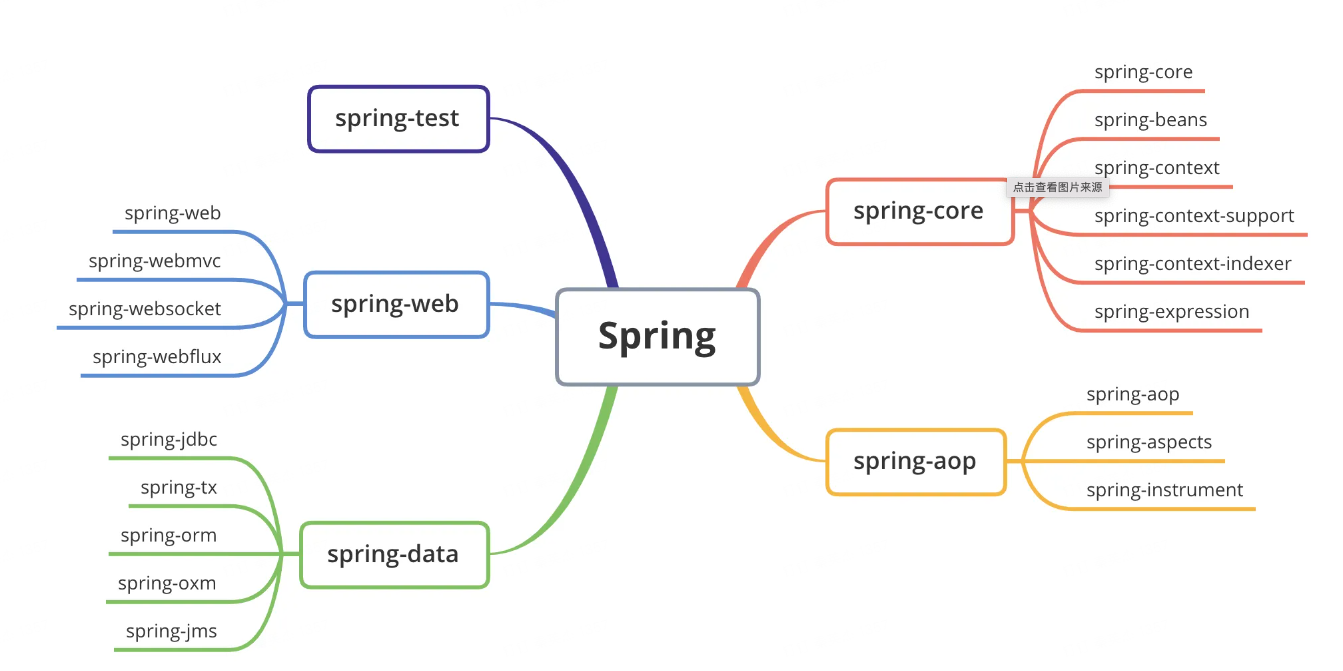
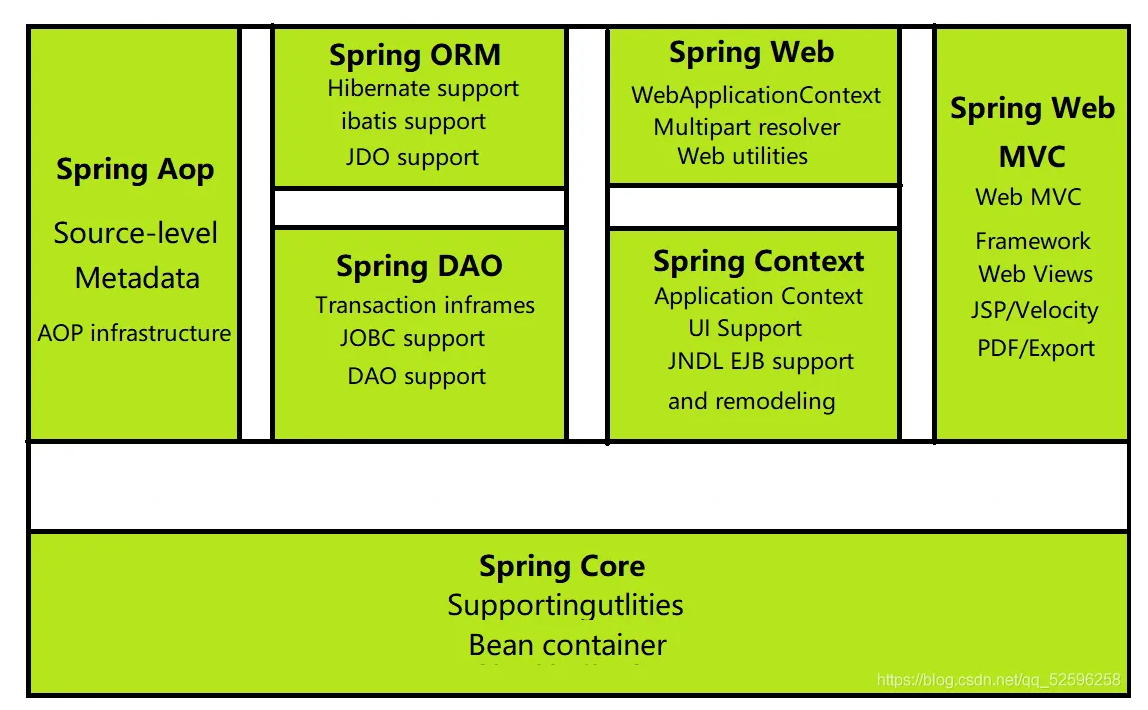
# 2.Spring 框架概述
Spring 框架概述
Spring 是轻量级的开源的 JavaEE 框架
Spring 可以解决企业应用开发的复杂性
Spring 有两个核心部分: IOC 和 AOP
IOC:控制反转,把创建对象过程交给 Spring 进行管理
Aop:面向切面,不修改源代码进行功能增强
为了降低 Java 开发的复杂性,Spring 采取了以下 4 种关键策略
- 基于 POJO 的轻量级和最小侵入性编程;
- 通过依赖注入和面向接口实现松耦合;
- 基于切面和惯例进行声明式编程;
- 通过切面和模板减少样板式代码。
# 3.Spring 特点
- 方便解耦,简化开发。
- Aop 编程支持。
- 方便程序测试。
- 方便和其他框架进行整合。
- 方便进行事务操作。
- 降低 API 开发难度。
# 4.常见依赖包
# 5.spring 中设计模式
工厂模式:BeanFactory 就是简单工厂模式的体现,用来创建对象的实例;- 工厂方法模式 FactoryBean
单例模式:Bean 默认为单例模式。- 适配器模式
包装器:一种是类名中含有 Wrapper,另一种是类名中含有 Decorator代理模式:Spring 的 AOP 功能用到了 JDK 的动态代理和 CGLIB 字节码生成技术;观察者模式:定义对象键一种一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都会得到通知被制动更新,如 Spring 中 listener 的实现–ApplicationListener。- 策略模式
模板方法:用来解决代码重复的问题。比如. RestTemplate, JmsTemplate, JpaTemplate。- 发布订阅模式
# 6.Spring5 的新特性?
- 整合日志 Log4j-2
- @Nullable 注解
- 函数式注册对象
- 整合 junit5
- WebFlux
# 7.Spring6 新特性?
SpringBoot3 和 Spring6 的最低依赖就是 JDK17,主要是因为它是一个 Oracle 官宣可以免费商用的 LTS 版本,所谓 LTS,是 Long Term Support,也就是官方保证会长期支持的版本。
JDK 17 中的新特性和改进:
Sealed Classes(封闭类): 这个特性允许类或接口声明哪些其他类可以成为它的子类或实现类,以限制继承和实现的范围。
Pattern Matching for switch(switch 表达式模式匹配): 这个特性可以让 switch 表达式更加强大和灵活,可以在不同的分支中进行模式匹配和提取。
Foreign Function & Memory API(外部函数和内存 API): 这个特性旨在提供 Java 与本地代码进行更加紧密集成的能力,包括调用外部函数和直接操作内存。
Deprecating and Removing Features(弃用和移除特性): JDK 17 有望继续清理和移除不推荐使用或已经过时的特性,以提高代码质量和维护性。
AppCDS Improvements(应用类数据共享改进): JDK 17 可能会进一步改进应用类数据共享(AppCDS)机制,以提升应用程序的启动性能。
新的垃圾回收器和性能改进: JDK 17 可能会引入一些新的垃圾回收器或者对现有的垃圾回收器进行改进,以提升 Java 程序的性能和吞吐量。
项目 Loom 的进一步发展: 项目 Loom 旨在改进 Java 虚拟机的线程和并发模型,可能会在 JDK 17 中进一步发展和引入新的功能。
# 8.Spring 中 Filter 的优先级规则?
在 Spring 框架中,过滤器(Filter)是用于在 Servlet 容器中对 HTTP 请求和响应进行预处理和后处理的组件。Spring 允许开发者使用自定义的过滤器来处理特定的请求和响应逻辑。当在一个 Spring 应用程序中使用多个过滤器时,它们的执行顺序是有一定规则的。
Spring 中过滤器的优先级规则如下:
Filter 在 web.xml 中的声明顺序: 如果你在
web.xml中声明过滤器,并按照一定的顺序列出它们,那么它们会按照在web.xml中的声明顺序被调用。在这种情况下,首先声明的过滤器会首先执行,然后是后续的过滤器。基于 Ordered 接口: Spring 允许过滤器实现
org.springframework.core.Ordered接口,该接口定义了一个getOrder()方法,用于返回一个整数值,表示过滤器的执行顺序。数字越小,优先级越高。实现了Ordered接口的过滤器会按照它们的顺序进行执行。使用@Order 注解: 如果过滤器使用了 Spring 的
@Order注解,你可以在注解中指定一个优先级顺序,与Ordered接口的方式类似。同样,数值越小,优先级越高。没有指定优先级的情况: 如果过滤器既没有在
web.xml中声明顺序,也没有实现Ordered接口或使用@Order注解,那么它们的执行顺序可能会受到 Servlet 容器的默认行为影响,这可能会因容器的不同而有所不同。当 Order 的值相同时。按照加载到
FilterChain的先后顺序决定优先级。
# 9.Spring 的启动流程和原理
首先,Spring 通过读取配置文件,解析配置信息,生成相应的 BeanDefinition,并注册到 BeanFactory 中。
接着,Spring 根据 BeanDefinition 创建和初始化 Bean,并进行依赖注入。
最后,Spring 触发 BeanPostProcessor 和 BeanFactoryPostProcessor 进行一些自定义的处理和扩展操作。
整个过程中,Spring 会涉及到类加载、反射、AOP、事件管理等技术,从而实现了高度灵活的IOC和AOP`机制。
# 二.Bean 的生命周期
# 1.Bean 的生命周期
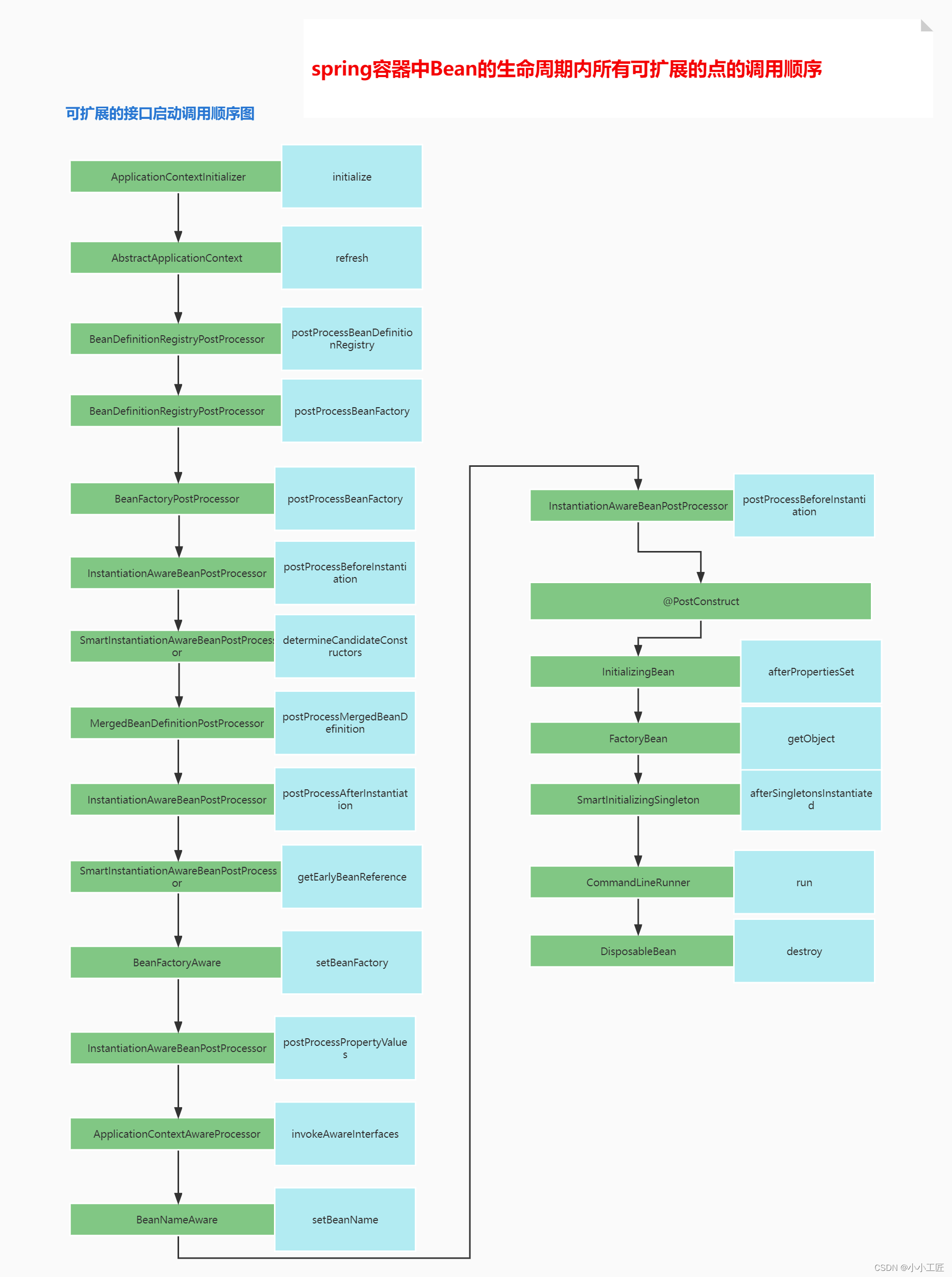
在 Spring 框架中,Bean 的生命周期涉及从它们的创建到销毁的整个过程。以下是 Spring Bean 的生命周期的主要阶段:
实例化(Instantiation):容器根据配置信息通过反射的方式创建 Bean 的实例。这可以通过构造函数或者工厂方法来完成。此时的创建只是在堆空间中申请空间,属性都是默认值。
填充属性(Population of properties):在实例化之后,Spring 容器会将配置的属性值以及引用注入到 Bean 中。
初始化(Initialization):一旦 Bean 的属性被填充,Spring 会调用初始化方法。这可以是实现了
InitializingBean接口的afterPropertiesSet方法,或者使用 XML 配置中的init-method属性。使用(In use):Bean 现在可以被容器及其他 Bean 使用。这是 Bean 的主要操作阶段。
销毁(Destruction):当 Bean 不再需要时,容器会调用销毁方法。这可以是实现了
DisposableBean接口的destroy方法,或者使用 XML 配置中的destroy-method属性。
需要注意的是,Spring 容器对 Bean 的管理是自动的,开发人员不需要显式地调用初始化或销毁方法,除非有特殊需求。
另外,还可以通过编写BeanPostProcessor接口的实现来拦截 Bean 的初始化和销毁过程,以执行一些自定义操作。这允许您在 Bean 初始化之前或销毁之后执行一些额外的逻辑。
# 2.Bean 创建过程
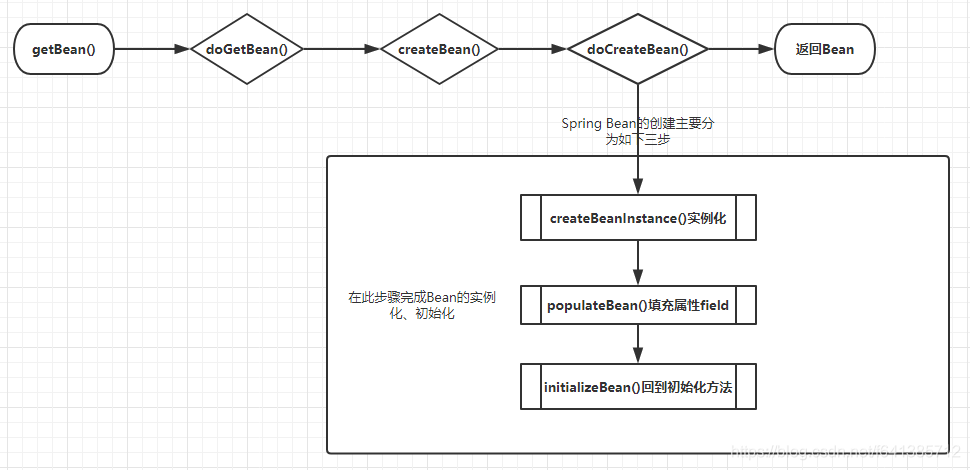
对 Bean 的创建最为核心三个方法解释如下:
createBeanInstance():实例化,其实也就是调用对象的构造方法进行实例化对象。populateBean():填充属性,这一步主要是对 bean 的依赖属性进行注入。initializeBean():执行一些形如 initMethod、InitializingBean 等方法。
# 3.举例 Bean 的生命周期
- 加载 UserService.class 类文件
- 调用无参的构造方法实例化得到普通对象
- 通过依赖注入,跳虫属性
- 初始化前--->初始化--->初始化后(AOP)
- 得到代理对象
- 放入 Map 单例池中
- Bean 对象初始化完毕。

# 4.图解生命周期
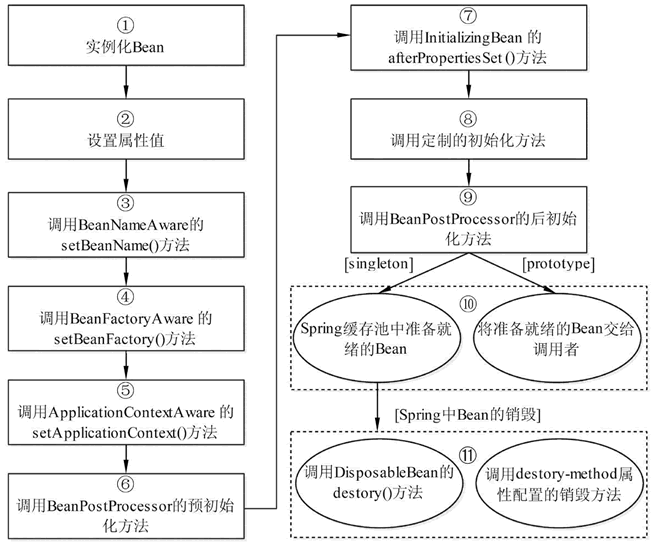
Bean 生命周期有七步 (正常生命周期为五步,而配置后置处理器后为七步)
通过构造器创建
bean实例(无参数构造)为
bean的属性设置值和对其他bean引用(调用 set 方法)把
bean实例传递bean后置处理器的方法 postProcessBeforeInitialization调用
bean的初始化的方法(需要进行配置初始化的方法)把
bean实例传递bean后置处理器的方法 postProcessAfterInitializationbean可以使用了(对象获取到了)当容器关闭时候,调用
bean的销毁的方法(需要进行配置销毁的方法)
# 5.DefaultListableBeanFactory
DefaultListableBeanFactory 是 Spring 注册加载 bean 的默认实现,它是整个 bean 加载的核心部分。
XmlBeanFactory 与它的不同点就是 XmlBeanFactory 使用了自定义的 XML 读取器 XmlBeanDefinitionReader,实现了自己的 BeanDefinitionReader 读取。 XmlBeanFactory 加载 bean 的关键就在于 XmlBeanDefinitionReader。
XmlBeanFactory 继承了 DefaultListableBeanFactory
beanDefinitionMap 是 DefaultListableBeanFactory 的成员
DefaultListableBeanFactory 作为 BeanFactory 默认是维护这一张 beanDefinition 的表。
/** Map of bean definition objects, keyed by bean name. */
private final Map<String, BeanDefinition> beanDefinitionMap = new ConcurrentHashMap<>(256);
2
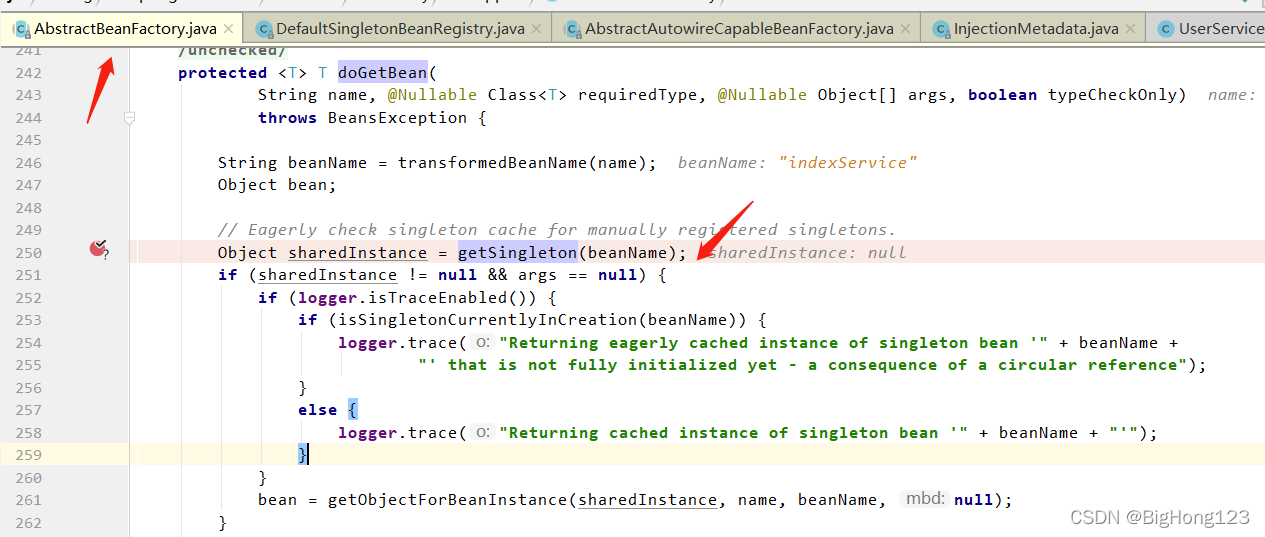
# 6.doGetBean
AbstractBeanFactory#
doGetBeandoGetBean方法被getBean方法调用
该方法刚开始调用 getSingleton(beanName) 方法,该方法内使用三级缓存获取对象,由于该开始并没有对象被创建,所以开始时调用 getSingleton(beanName) 方法返回的值为空
/** Cache of singleton objects: bean name to bean instance. */
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256);
/** Cache of singleton factories: bean name to ObjectFactory. */
private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<>(16);
/** Cache of early singleton objects: bean name to bean instance. */
private final Map<String, Object> earlySingletonObjects = new ConcurrentHashMap<>(16);
2
3
4
5
6
7
8
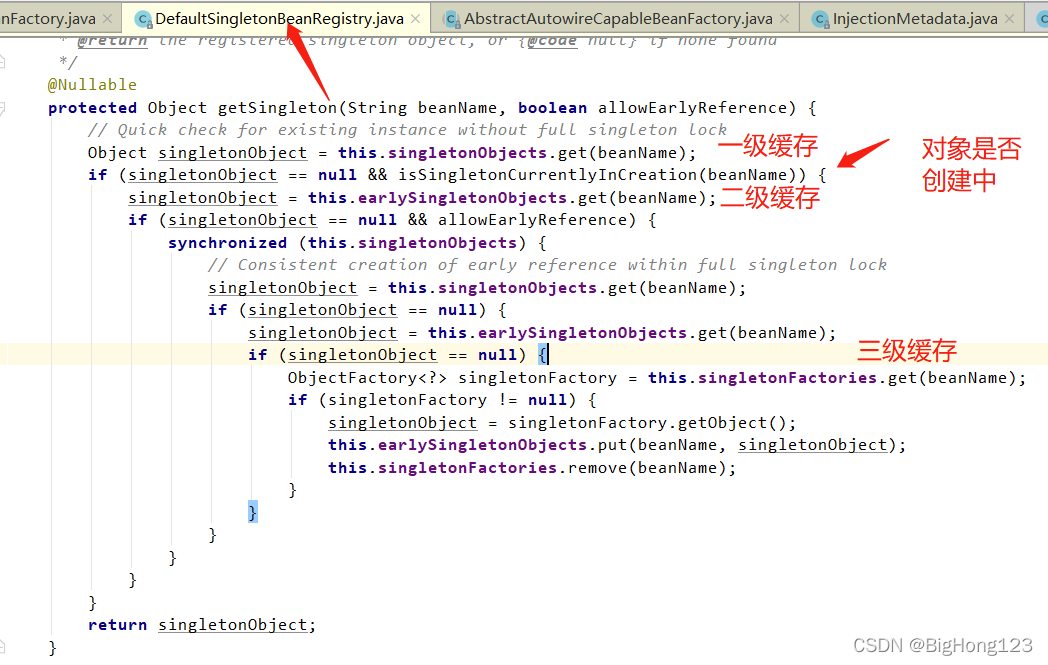
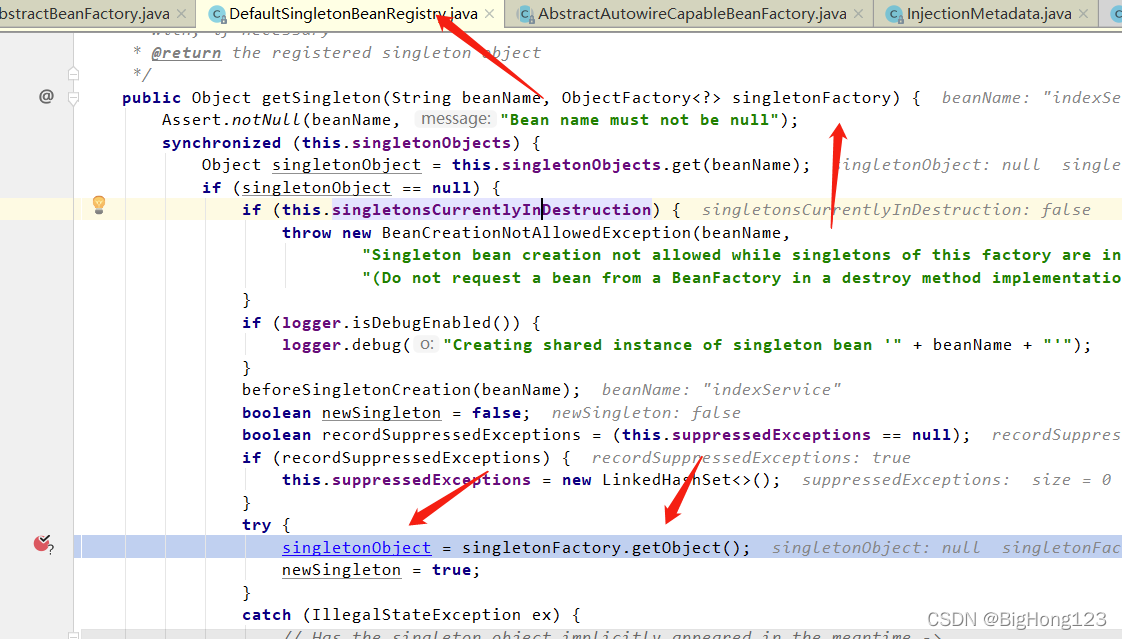
# 7.getSingleton
DefaultSingletonBeanRegistry#getSingleton(beanName, BeanFactory<?>)
该方法在 doGetBean 方法中被调用(开始 getSingleton(beanName) 返回的值为空,会走到这里)
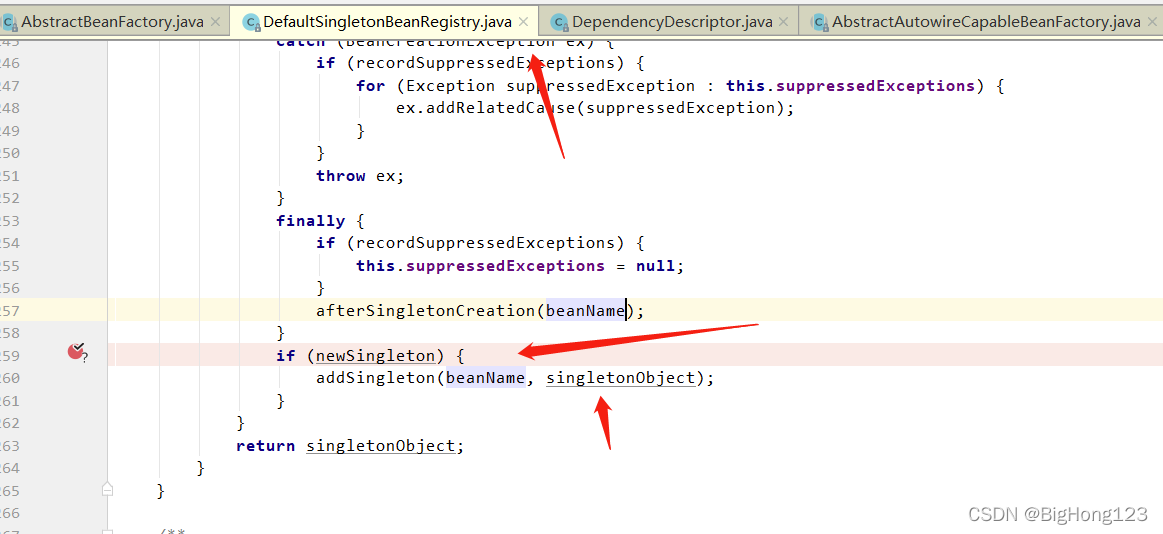
该方法传入两个参数一个为当前的 beanName 令一个参数时 beanFactory,在里面会调用传入 beanFactory 的 getObject 方法返回该 beanName 的对象
最后将创建好的对象通过 addSingleton(beanName, singletonObject);方法将 bean 放入到一级缓存中。
//通过名称返回一个原生的单例对象,查找已经存在的实例化单例,也同时允许一个提早引用,只向一个正在创建的单实例对象 (解决循环引用)
@Nullable
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
// Quick check for existing instance without full singleton lock
Object singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null && allowEarlyReference) {
synchronized (this.singletonObjects) {
//一致性创建一个可提早引用的对象,通过锁
// Consistent creation of early reference within full singleton lock
//1级缓存,singletonObjects (单例对象集)
singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null) {
//2级缓存,earlySingletonObjects (早产单例对象集)
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null) {
//3级缓存,单例对象工厂集
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
//单例对象工厂集,得到对象,放到二级缓存,清空三级缓存
singletonObject = singletonFactory.getObject();
this.earlySingletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName);
}
}
}
}
}
}
return singletonObject;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
protected void addSingleton(String beanName, Object singletonObject) {
synchronized (this.singletonObjects) {
this.singletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName);
this.earlySingletonObjects.remove(beanName);
this.registeredSingletons.add(beanName);
}
}
2
3
4
5
6
7
8

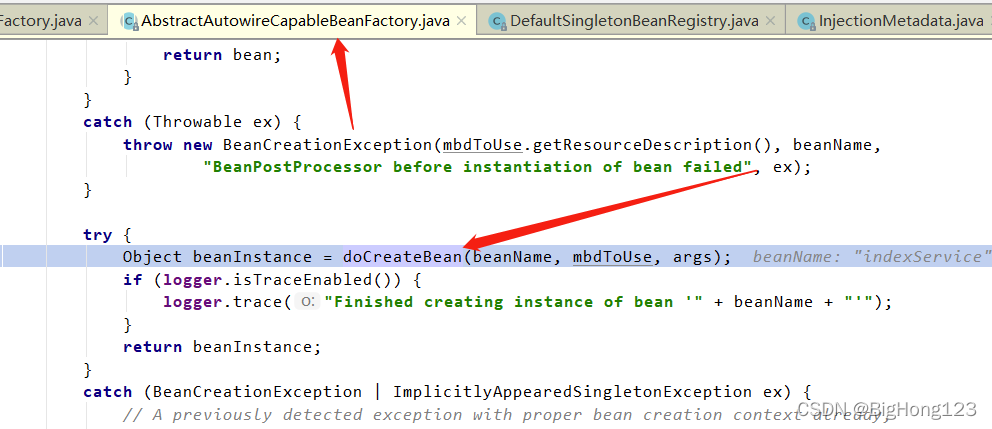
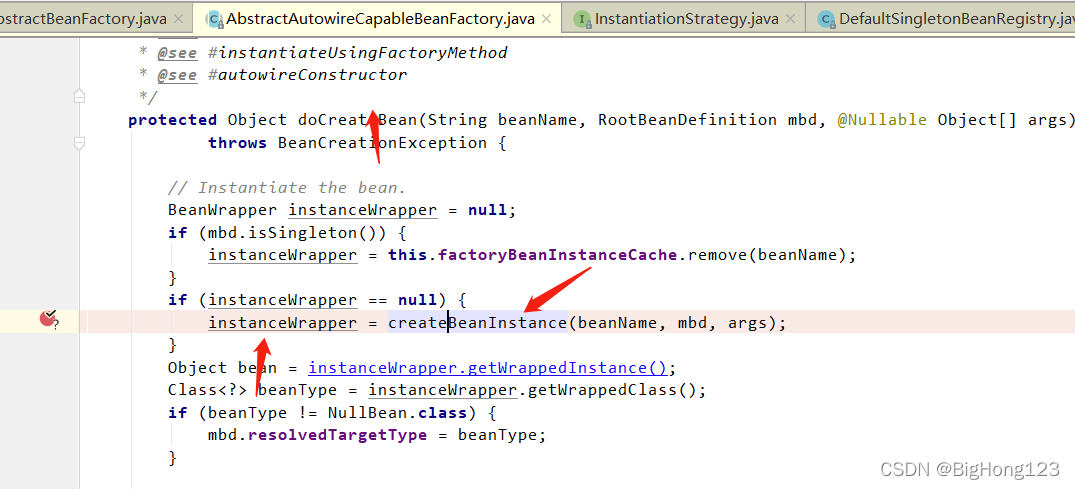
# 8.doCreateBean
AbstractAutowireCapableBeanFactory#doCreateBean(beanName, mbdToUse, args)
该方法被 createBean 方法调用,方法一开始调用 createBeanInstance(beanName, mbd, args)方法,通过反射创建原始对象,并用 BeanWrapper 包装
protected Object doCreateBean(String beanName, RootBeanDefinition mbd, @Nullable Object[] args) throws BeanCreationException {
BeanWrapper instanceWrapper = null;
if (mbd.isSingleton()) {
instanceWrapper = (BeanWrapper)this.factoryBeanInstanceCache.remove(beanName);
}
if (instanceWrapper == null) {
instanceWrapper = this.createBeanInstance(beanName, mbd, args);
}
Object bean = instanceWrapper.getWrappedInstance();
Class<?> beanType = instanceWrapper.getWrappedClass();
if (beanType != NullBean.class) {
mbd.resolvedTargetType = beanType;
}
synchronized(mbd.postProcessingLock) {
if (!mbd.postProcessed) {
try {
this.applyMergedBeanDefinitionPostProcessors(mbd, beanType, beanName);
} catch (Throwable var17) {
throw new BeanCreationException(mbd.getResourceDescription(), beanName, "Post-processing of merged bean definition failed", var17);
}
mbd.postProcessed = true;
}
}
boolean earlySingletonExposure = mbd.isSingleton() && this.allowCircularReferences && this.isSingletonCurrentlyInCreation(beanName);
if (earlySingletonExposure) {
if (this.logger.isTraceEnabled()) {
this.logger.trace("Eagerly caching bean '" + beanName + "' to allow for resolving potential circular references");
}
this.addSingletonFactory(beanName, () -> {
return this.getEarlyBeanReference(beanName, mbd, bean);
});
}
Object exposedObject = bean;
try {
this.populateBean(beanName, mbd, instanceWrapper);
exposedObject = this.initializeBean(beanName, exposedObject, mbd);
} catch (Throwable var18) {
if (var18 instanceof BeanCreationException && beanName.equals(((BeanCreationException)var18).getBeanName())) {
throw (BeanCreationException)var18;
}
throw new BeanCreationException(mbd.getResourceDescription(), beanName, "Initialization of bean failed", var18);
}
if (earlySingletonExposure) {
Object earlySingletonReference = this.getSingleton(beanName, false);
if (earlySingletonReference != null) {
if (exposedObject == bean) {
exposedObject = earlySingletonReference;
} else if (!this.allowRawInjectionDespiteWrapping && this.hasDependentBean(beanName)) {
String[] dependentBeans = this.getDependentBeans(beanName);
Set<String> actualDependentBeans = new LinkedHashSet(dependentBeans.length);
String[] var12 = dependentBeans;
int var13 = dependentBeans.length;
for(int var14 = 0; var14 < var13; ++var14) {
String dependentBean = var12[var14];
if (!this.removeSingletonIfCreatedForTypeCheckOnly(dependentBean)) {
actualDependentBeans.add(dependentBean);
}
}
if (!actualDependentBeans.isEmpty()) {
throw new BeanCurrentlyInCreationException(beanName, "Bean with name '" + beanName + "' has been injected into other beans [" + StringUtils.collectionToCommaDelimitedString(actualDependentBeans) + "] in its raw version as part of a circular reference, but has eventually been wrapped. This means that said other beans do not use the final version of the bean. This is often the result of over-eager type matching - consider using 'getBeanNamesOfType' with the 'allowEagerInit' flag turned off, for example.");
}
}
}
}
try {
this.registerDisposableBeanIfNecessary(beanName, bean, mbd);
return exposedObject;
} catch (BeanDefinitionValidationException var16) {
throw new BeanCreationException(mbd.getResourceDescription(), beanName, "Invalid destruction signature", var16);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
protected void addSingletonFactory(String beanName, ObjectFactory<?> singletonFactory) {
Assert.notNull(singletonFactory, "Singleton factory must not be null");
synchronized (this.singletonObjects) {
if (!this.singletonObjects.containsKey(beanName)) {
this.singletonFactories.put(beanName, singletonFactory);
this.earlySingletonObjects.remove(beanName);
this.registeredSingletons.add(beanName);
}
}
}
2
3
4
5
6
7
8
9
10
protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) {
Object exposedObject = bean;
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
for (BeanPostProcessor bp : getBeanPostProcessors()) {
if (bp instanceof SmartInstantiationAwareBeanPostProcessor) {
SmartInstantiationAwareBeanPostProcessor ibp = (SmartInstantiationAwareBeanPostProcessor) bp;
exposedObject = ibp.getEarlyBeanReference(exposedObject, beanName);
}
}
}
return exposedObject;
}
2
3
4
5
6
7
8
9
10
11
12

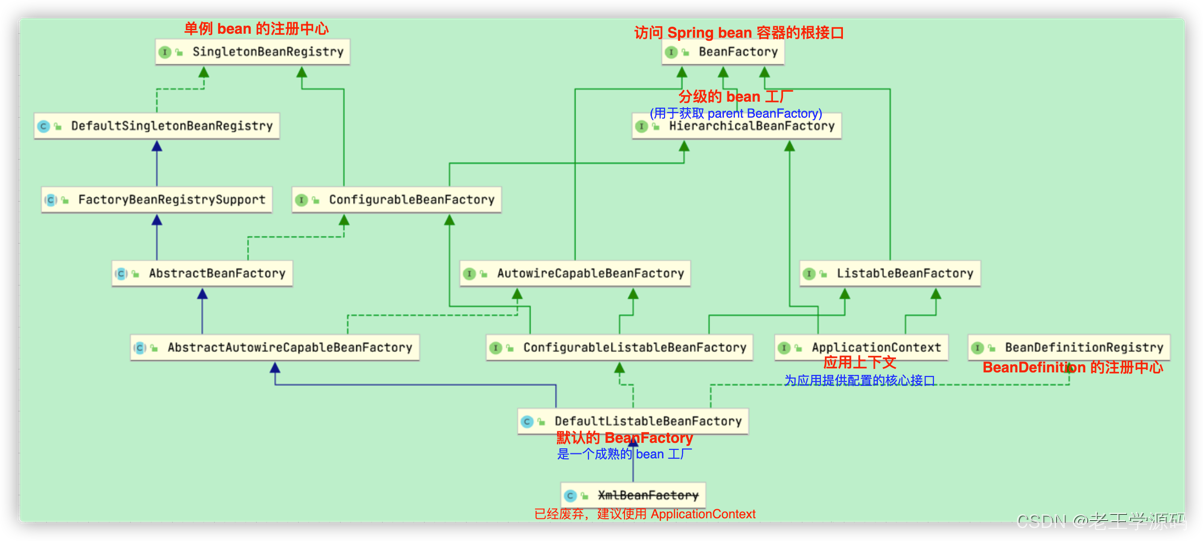
# 9.BeanFactory 整体类图
# 10.什么是 BeanDefinition?
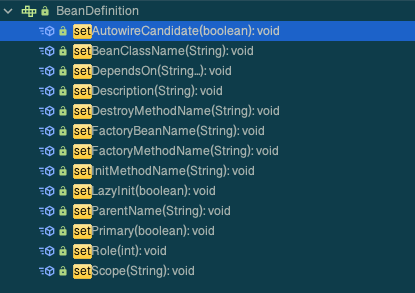
BeanDefinition 是定义 Bean 的配置元信息接口,包含:
- Bean 的类名
- 设置父 bean 名称、是否为 primary、
- Bean 行为配置信息,作用域、自动绑定模式、生命周期回调、延迟加载、初始方法、销毁方法等
- Bean 之间的依赖设置,dependencies
- 构造参数、属性设置
# 11.DefaultSingletonBeanRegistry
类 DefaultSingletonBeanRegistry 实现了接口 SingletonBeanRegistry,是通用注册表的基础实现类:
- 它允许注册 bean 对象实例(这些对象实例都是单例模式)。
- 已经注册的 bean 对象实例是注册表的所有调用者共享的(所以特别需要注意线程安全)。
- 可以通过 bean 名称获得目标 bean 对象实例。
类 DefaultSingletonBeanRegistry 还支持类 DisposableBean 对象实例的注册(在关闭注册表时销毁),该实例可能与已注册的 bean 对象实例相对应。bean 对象实例之间的依赖关系也可以注册,以此控制销毁 bean 对象实例的顺序。
类 DefaultSingletonBeanRegistry 主要作为实现接口 BeanFactory 的基类,它分解了单例 bean 对象实例的常见管理(比如注册,获取等等,但不包含创建)。另一个接口 ConfigurableBeanFactory 扩展了接口 SingletonBeanRegistry。
类 DefaultSingletonBeanRegistry 与类 AbstractBeanFactory 和类 DefaultListableBeanFactory(继承自类 DefaultSingletonBeanRegistry)相比,既不涉及 bean 对象实例概念的定义也不涉及 bean 对象实例的创建过程,还可以用作委托的嵌套助手(涉及 Java 设计模式)。
# 12.Aware 接口
在 Spring 框架中,有一些特定的接口被称为"Aware"接口,它们允许 Bean 在不同的情况下获得与 Spring 容器和应用程序上下文相关的信息。通过实现这些接口,您的 Bean 可以获取对 Spring 框架的特定功能的访问权限。以下是一些常见的 Spring Aware 接口:
ApplicationContextAware:实现这个接口的 Bean 可以获得对应用程序上下文的引用,从而可以在运行时访问 Spring 容器的各种功能。
BeanFactoryAware:实现这个接口的 Bean 可以获得对 Bean 工厂(ApplicationContext 的底层接口)的引用,以便于访问容器的配置和管理功能。
BeanNameAware:实现这个接口的 Bean 可以获得其在 Spring 容器中定义的名称。
MessageSourceAware:实现这个接口的 Bean 可以获得对
MessageSource的引用,从而可以进行国际化和本地化处理。ResourceLoaderAware:实现这个接口的 Bean 可以获得对
ResourceLoader的引用,用于加载资源文件。ServletContextAware:实现这个接口的 Bean 可以获得对
ServletContext的引用,用于在 Web 应用程序中访问 Servlet 上下文信息。
通过实现这些 Aware 接口,您可以在 Spring 容器初始化和配置 Bean 时获取特定的环境信息,从而更好地与 Spring 框架进行集成和交互。
# 13.详解 refresh 方法
public void refresh() throws BeansException, IllegalStateException {
synchronized(this.startupShutdownMonitor) {
//判断系统要求的属性是否存在,不存在抛出异常
this.prepareRefresh();
/**
创建DefaultListableBeanFactory对象,可以理解为就是ApplicationContext
1.实例化了一个DefaultListableBeanFactory对象,即创建bean工厂applicationContext.
2.实例化了一个XmlBeanDefinitionReader对象,解析xml配置文件。将xml中的bean信息解析封装为BeanDefinition对象。
3.通过一个工具类将解析好的BeanDefinition对象注册到BeanFactory中,以key-value的形式保存在BeanFactory中,其中key为beanName.
*/
ConfigurableListableBeanFactory beanFactory = this.obtainFreshBeanFactory();
/**
该方法作用,主要给beanFactory设置相关属性:
1、类加载器、类表达式解析器、属性编辑注册器
2、添加bean后处理器等
3、资源注册
4、注册默认的environment beans
*/
this.prepareBeanFactory(beanFactory);
try {
this.postProcessBeanFactory(beanFactory);
//查询当前在BeanFactory中是否有指定类型的Bean信息。如果有则获取Bean实体并执行相关方法
this.invokeBeanFactoryPostProcessors(beanFactory);
//查询当前在BeanFactory中是否有指定类型的Bean信息。如果有则获取Bean实体注册到beanFactory中
this.registerBeanPostProcessors(beanFactory);
this.initMessageSource();
//判断bean工厂是否包含应用事件广播器,没有的话,创建一个,然后,把它放入bean工厂中。
this.initApplicationEventMulticaster();
this.onRefresh();
this.registerListeners();
this.finishBeanFactoryInitialization(beanFactory);
this.finishRefresh();
} catch (BeansException var9) {
if (this.logger.isWarnEnabled()) {
this.logger.warn("Exception encountered during context initialization - cancelling refresh attempt: " + var9);
}
this.destroyBeans();
this.cancelRefresh(var9);
throw var9;
} finally {
this.resetCommonCaches();
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
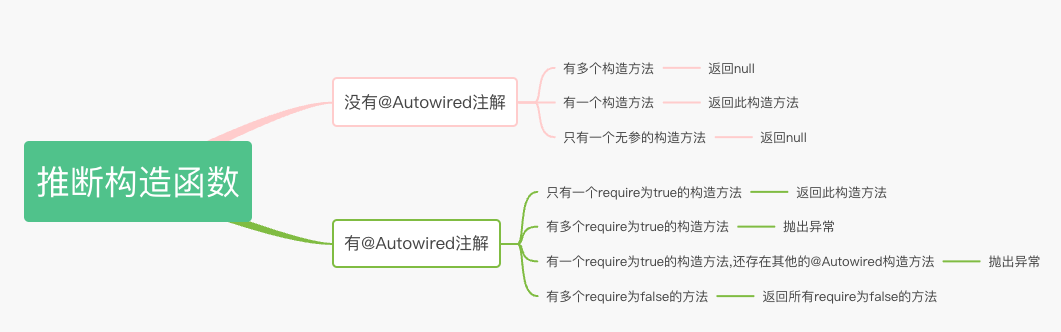
# 14.推断构造方法
在 Spring 框架中,当进行构造方法注入时,Spring 会尝试根据类型(by type)来自动推断构造方法参数,然后根据参数的名称(by name)来匹配对应的 Bean 定义。这种方式可以使构造方法注入更加灵活,并且可以避免参数类型相同但含义不同的歧义。
具体来说,当使用构造方法注入时,Spring 会按照以下步骤进行推断:
根据类型进行推断(by type):Spring 首先根据构造方法参数的类型来寻找合适的 Bean 定义。它会检查容器中是否有与参数类型匹配的 Bean 定义。如果找到一个与参数类型匹配的 Bean 定义,Spring 会选择使用该构造方法,并将匹配的 Bean 注入到构造方法中。
根据名称进行推断(by name):如果根据类型找不到唯一的匹配项,或者存在多个相同类型的 Bean 定义,Spring 会继续检查构造方法的参数名称。它会尝试通过参数名称与容器中的 Bean 定义名称匹配来选择合适的 Bean。如果找到与参数名称匹配的 Bean 定义,Spring 会选择使用该构造方法。
# 15.扩展接口一览
# 三.IOC
# 1.什么是 IOC
控制反转:,把对象创建和对象之间的调用过程,交给 Spring 进行管理。
依赖控制反转:对象的依赖关系交由 spring 来管理
ioc:是实现这个模式的载体
DI:DI 是 IoC 的一种具体实现方式,它是指通过构造函数、方法参数或属性等方式,将一个对象的依赖关系注入到对象本身。
IOC 作用:
通过 spring 提供的 ioc 容器,可以将对象间的依赖关系交给 spring 管理,避免硬编码造成的程序过渡耦合
- 降低耦合度
- 简化开发,方便开发
# 2.IOC 和 DI 区别?
IoC(Inversion of Control)和 DI(Dependency Injection)是两个相关但不同的概念,通常在面向对象编程和框架设计中使用。它们之间的关系可以描述为:
IoC(Inversion of Control,控制反转):
- IoC 是一种软件设计原则,它强调将控制权从应用程序代码中转移到外部容器或框架中。
- 在传统的编程模型中,应用程序代码通常负责创建和管理对象的生命周期,即控制对象的实例化和依赖关系的维护。
- IoC 的思想是反转这种控制关系,即将对象的创建和管理权交给容器或框架,应用程序只需要声明依赖关系,容器负责实例化和注入依赖对象。
- IoC 通过解耦组件之间的依赖关系,提高了代码的可维护性、可测试性和灵活性。
DI(Dependency Injection,依赖注入):
- DI 是 IoC 的一种具体实现方式,它是指通过构造函数、方法参数或属性等方式,将一个对象的依赖关系注入到对象本身。
- 在 DI 中,对象不再负责自己依赖的创建和管理,而是由外部容器或框架负责,然后将依赖对象注入到目标对象中。
- DI 有助于减少类之间的紧耦合,提高了代码的可测试性和可维护性,因为依赖关系更容易替换或模拟。
# 3.IOC 原理
底层实现:
- XML 解析
- 工厂模式
- 反射 IOC 思想基于 IOC 容器完成,IOC 容器底层就是对象工厂。
Spring 提供 IOC 容器实现两种方式: (两个接口) 。
BeanFactory: IOC 容器基本实现,是 Spring 内部的使用接口,不提供开发人员进行使用。ApplicationContext: BeanFactory 接口的子接口,提供更多更强大的功能,一般由开发人员进行使用。
# 4.对象创建的三种方式
- new
- 工厂模式
- ioc 模式
- xml 解析
- 工厂模式
- 反射
实现 FactoryBean,重写 getObject 方法,得到需要的 bean,反射
public interface FactoryBean<T> {
String OBJECT_TYPE_ATTRIBUTE = "factoryBeanObjectType";
@Nullable
T getObject() throws Exception;
@Nullable
Class<?> getObjectType();
default boolean isSingleton() {
return true;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
# 5.为什么不用工厂模式用 ioc
工厂模式和 IoC(控制反转)是两种不同的设计模式,它们都有各自的优点和适用场景。选择使用哪种模式取决于您的需求和设计目标。
工厂模式适用于以下情况:
创建复杂对象:当对象的创建涉及到一些复杂的逻辑、条件判断或者依赖其他对象时,工厂模式可以帮助将对象的创建逻辑封装起来,使客户端代码更加简洁。
隐藏对象创建细节:工厂模式可以将对象的实例化过程与客户端代码隔离,使客户端不需要知道具体的实现细节。
灵活性:通过工厂模式,您可以随时更改对象的实现,而无需更改客户端代码,从而提供更大的灵活性。
IoC(控制反转)适用于以下情况:
解耦:IoC 通过将对象的创建和依赖关系的管理交给容器来实现,从而将组件之间的依赖关系解耦,使得应用程序更加灵活、可维护和可测试。
管理对象生命周期:IoC 容器负责管理对象的生命周期,确保对象在需要时被正确地创建、初始化和销毁,避免了手动管理对象的生命周期带来的复杂性和错误。
依赖注入:IoC 容器可以自动将依赖注入到需要的地方,使对象之间的依赖关系更加清晰可见。
在使用 Spring 框架(一个 IoC 容器)时,您可以获得工厂模式的一些优点,因为 Spring 的 IoC 容器本质上是一个对象工厂,它可以帮助您创建和管理对象,同时还提供了依赖注入、生命周期管理等特性。
选择使用工厂模式还是 IoC 取决于您的具体需求和项目的设计目标。在许多情况下,IoC 能够提供更好的解耦、可维护性和灵活性,因此它在现代应用程序开发中得到了广泛的应用。
# 6.Spring ioc 创建过程?
Spring 的 IoC(Inversion of Control,控制反转)容器负责管理和控制对象的生命周期、依赖关系以及对象的创建、初始化和销毁等操作。下面是 Spring IoC 容器创建和工作的基本过程:
加载配置文件或注解扫描:Spring IoC 容器首先会加载配置文件(如 XML 配置文件)或通过注解扫描来识别 Bean 定义。配置文件中包含了 Bean 的定义信息,包括 Bean 的类名、属性值、依赖关系等。
创建 Bean 的定义:Spring 将解析配置文件或注解信息,创建 Bean 的定义对象。这些 Bean 定义对象包含了 Bean 的元数据,如类名、属性、构造方法参数等。
创建 Bean 实例:根据 Bean 定义,IoC 容器会实例化 Bean 对象。这通常涉及使用构造方法或工厂方法来创建 Bean 实例。
属性注入:一旦 Bean 实例化,容器会根据配置将属性值、依赖引用等注入到 Bean 中。这可以通过属性注入、构造方法注入或者方法注入来完成。
Bean 的初始化:如果 Bean 定义中配置了初始化方法(例如通过
init-method属性或实现InitializingBean接口),容器会在 Bean 实例化和属性注入之后调用初始化方法。注册 Bean:IoC 容器将创建的 Bean 实例注册到容器中,以便后续的依赖注入和获取操作。
应用上下文准备就绪:一旦所有的 Bean 都被创建、初始化并注册到容器中,IoC 容器就处于"准备就绪"的状态,可以供其他组件和应用程序使用。
Bean 的使用:应用程序或其他组件可以通过从 IoC 容器中获取 Bean 实例来使用它们。IoC 容器会负责处理依赖关系,确保所需的 Bean 在需要时正确地被注入。
Bean 的销毁:如果 Bean 定义中配置了销毁方法(例如通过
destroy-method属性或实现DisposableBean接口),当容器被关闭或应用程序终止时,容器会调用 Bean 的销毁方法来进行清理工作。
需要注意的是,Spring IoC 容器提供了不同类型的容器,如 ApplicationContext 和 BeanFactory。ApplicationContext 是 BeanFactory 的子接口,提供了更多的功能,如国际化、事件传播等。上述过程涵盖了 IoC 容器的基本创建和工作流程,帮助实现了依赖注入、控制反转等核心特性。
# 7.扫描的实现过程
在 spring 中,spring 使用ClassPathBeanDefinitionScanner来实现包扫描,
org.springframework.context.annotation.ClassPathBeanDefinitionScanner#scan就是扫描方法的入口,实际的扫描逻辑是写在 doScan 方法中的
xml方式:
<!--配置扫描com.example.spring.beans下的所有bean-->
<context:component-scan base-package="com.example.spring.beans"/>
2
注解:
@Configuration
@ComponentScan("com.example.spring.beans4")
public class ComponentScanConfig {
}
2
3
4
# 8.@ComponentScan
@ComponentScan 是 Spring 框架中的一个注解,用于指示 Spring 在指定的包或类路径下进行扫描,自动发现并注册被 Spring 管理的 Bean。
在 Spring 应用程序中,通常我们需要创建一些 Bean,并将它们注册到 Spring IoC 容器中,以便在应用程序中进行依赖注入和使用。使用 @ComponentScan 注解,我们可以让 Spring 自动扫描指定的包,找到带有特定注解(如 @Component、@Service、@Repository 等)的类,并将它们实例化成 Bean。
基本用法:
@Configuration @ComponentScan(basePackages = "com.example") public class AppConfig { // ... }1
2
3
4
5在这个例子中,
@ComponentScan注解告诉 Spring 在包com.example下扫描所有带有@Component注解的类,并将它们注册成 Bean。指定多个包路径:
@ComponentScan(basePackages = {"com.example.package1", "com.example.package2"})1您可以通过传递一个包路径的数组来指定多个包路径。
指定包路径前缀和后缀:
@ComponentScan(basePackageClasses = {ComponentA.class}, includeFilters = @ComponentScan.Filter(type = FilterType.REGEX, pattern = ".*Controller"))1通过
basePackageClasses属性指定一个或多个类,然后通过includeFilters属性以正则表达式的方式指定要包含的类。排除指定类或注解:
@ComponentScan(basePackages = "com.example", excludeFilters = @ComponentScan.Filter(type = FilterType.ANNOTATION, value = ExcludeComponent.class))1使用
excludeFilters属性可以排除带有特定注解(如ExcludeComponent)的类。自定义过滤器:
@ComponentScan还允许您使用自定义的过滤器来进行更精细的控制,以满足您的需求。
@ComponentScan 的常用方式如下
- 自定扫描路径下边带有@Controller,@Service,@Repository,@Component 注解加入 spring 容器
- 通过 includeFilters 加入扫描路径下没有以上注解的类加入 spring 容器
- 通过 excludeFilters 过滤出不用加入 spring 容器的类
- 自定义增加了@Component 注解的注解方式
# 9.doScan 的具体流程
protected Set<BeanDefinitionHolder> doScan(String... basePackages) {
//首先,basePackages不能是空的
Assert.notEmpty(basePackages, "At least one base package must be specified");
Set<BeanDefinitionHolder> beanDefinitions = new LinkedHashSet<>();
//遍历所有要扫描的包
for (String basePackage : basePackages) {
//获取到待选的BeanDefinition
Set<BeanDefinition> candidates = findCandidateComponents(basePackage);
//遍历待选的BeanDefinition
for (BeanDefinition candidate : candidates) {
//设置Scope
ScopeMetadata scopeMetadata = this.scopeMetadataResolver.resolveScopeMetadata(candidate);
candidate.setScope(scopeMetadata.getScopeName());
//生成beanName
String beanName = this.beanNameGenerator.generateBeanName(candidate, this.registry);
if (candidate instanceof AbstractBeanDefinition) {
//默认值处理
postProcessBeanDefinition((AbstractBeanDefinition) candidate, beanName);
}
if (candidate instanceof AnnotatedBeanDefinition) {
//@Lazy @Primary @DependsOn @Role @Description这些注解支持
AnnotationConfigUtils.processCommonDefinitionAnnotations((AnnotatedBeanDefinition) candidate);
}
//bean冲突校验
if (checkCandidate(beanName, candidate)) {
BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(candidate, beanName);
definitionHolder =
AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);
beanDefinitions.add(definitionHolder);
//注册bean
registerBeanDefinition(definitionHolder, this.registry);
}
}
}
return beanDefinitions;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
# 10.Spring 如何加载配置文件?
XmlBeanFactory 读取文件,改类已经为@Deprecated 废弃了,XmlBeanFactory 也是一个容器,目前改为 XmlBeanDefinitionReader 进行读取.
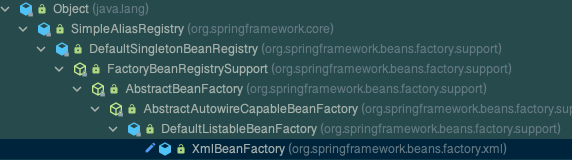
XmlBeanDefinitionReader:
- 首先 XML 文件通过
ResourceLoader加载器加载为 Resource 对象 XmlBeanDefinitionReader将 Resource 对象解析为Document对象DefaultBeanDefinitionDocumentReader将Document对象解析为 BeanDefinition 对象- 将解析出来的
BeanDefinition对象储存在DefaultListableBeanFactory工厂中
# 11.Spring 容器有哪些?
Spring 中的两种容器类型:
- BeanFactory
- ApplicationContext
典型的上下文有如下几个:
- ClassPathXmlApplicationContext
- FileSystemXmlApplicationContext
- XmlWebApplicationContext
- GroovyWebApplicationContext
- AnnocationConfigWebApplicationContext

共同点:
它们都是 Spring 中的两个接口,用来获取 Spring 容器中的 bean。
不同点:
1.bean 的加载方式不同:
- 前者 BeeanFactory 是使用的懒加载的方式,只有在调用 getBean()时才会进行实例化。
- 后者 ApplicationContext 是使用预加载的方式,即在应用启动后就实例化所有的 bean。常用的 API 比如 XmlBeanFactory
2.特性不同:
BeanFactory 接口只提供了 IOC/DI 的支持,常用的 API 是 XMLBeanFactory
ApplicationContext是整个 Spring 应用中的中央接口,翻看源码就会知道,它继承了 BeanFactory 接口,具备 BeanFactory 的所有特性,还有一些其他特性比如:AOP 的功能,事件发布/响应(ApplicationEvent)等。常用的 API 比如ClassPathXmlApplication
3.应用场景不同:
- BeanFactory 适合系统资源(内存)较少的环境中使用延迟实例化,比如运行在移动应用中
- ApplicationContext 适合企业级的大型 web 应用,将耗时的内容在系统启动的时候就完成
# 12.ApplicationContext
为什么建议使用 ApplicationContext,而不是直接使用 BeanFactory?
因为在使用 BeanFactory 时,注解的处理、AOP 代理、BeanPostProcessor 扩展点等容器特性功能是不会自动开启的,需要手动调用方法来实现。而使用 ApplicationContext 时,这些容器特性会自动开启。
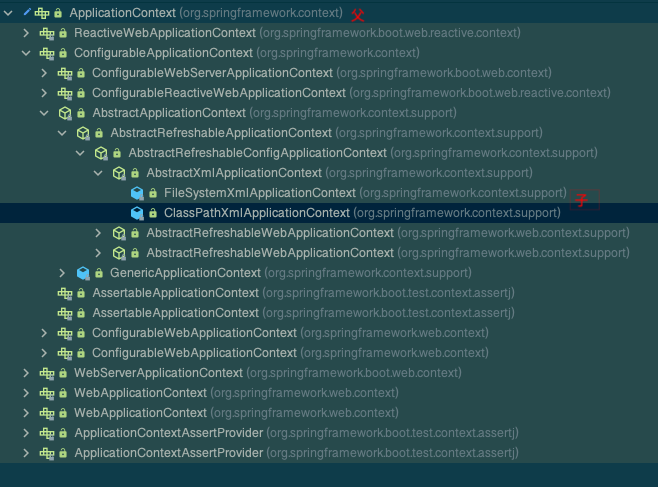
- FileSystemXmlApplicationContext:对应系统盘路径
- ClassPathXmlApplicationContext:对应类路径
目前,我们基本很少直接使用上面这种方式来用 Spring,而是使用 Spring MVC,或者 Spring Boot,但是它们都是基于上面这种方式的,都需要在内部去创建一个 ApplicationContext 的,只不过:
- Spring MVC 创建的是
XmlWebApplicationContext,和ClassPathXmlApplicationContext类似,都是基于 XML 配置的 - Spring Boot 创建的是
AnnotationConfigApplicationContext
ApplicationContext和BeanFactory比较:
相同:
Spring 提供了两种不同的 IOC 容器,一个是
BeanFactory,另外一个是ApplicationContext,它们都是 Javainterface,ApplicationContext 继承于 BeanFactory(ApplicationContext 继承 ListableBeanFactory。
它们都可以用来配置 XML 属性,也支持属性的自动注入。
而 ListableBeanFactory 继承 BeanFactory,BeanFactory 和 ApplicationContext 都提供了一种方式,使用
getBean("bean name")获取 bean。
不同:
当你调用 getBean()方法时,
BeanFactory仅实例化 bean,而ApplicationContext在启动容器的时候实例化单例 bean,不会等待调用 getBean()方法时再实例化。BeanFactory不支持国际化,即 i18n,但ApplicationContext提供了对它的支持。BeanFactory与ApplicationContext之间的另一个区别是能够将事件发布到注册为监听器的 bean。BeanFactory的一个核心实现是 XMLBeanFactory 而ApplicationContext的一个核心实现是ClassPathXmlApplicationContext,Web 容器的环境我们使用 WebApplicationContext 并且增加了
getServletContext 方法。
如果使用自动注入并使用
BeanFactory,则需要使用 API 注册 AutoWiredBeanPostProcessor,如果使用ApplicationContext,则可以使用 XML 进行配置。简而言之,BeanFactory 提供基本的 IOC 和 DI 功能,而 ApplicationContext 提供高级功能,BeanFactory 可用于测试和非生产使用,但 ApplicationContext 是功能更丰富的容器实现,应该优于 BeanFactory
# 13.BeanDefinition
在Spring中对象被叫做 Bean,因为Spring Bean 在 Java 类的基础上增加了很多概念,比如scope(作用域),isLazyInit(是否延迟初始化),isSingleton(是否单例),此时 Java 类不能完整的描述,所以需要新的定义描述类,这个类就是BeanDefinition。

RootBeanDefinition本质上是 Spring BeanFactory 运行时统一的BeanDefinition视图。GenericBeanDefinition是以编程方式注册BeanDefinition的首选类。ChildBeanDefinition它是一种可以继承 parent 配置的BeanDefinition。
# 14.GenericApplicationContext 解析
GenericApplicationContext 通用应用程序上下文实现,该实现内部有一个 DefaultListableBeanFactory 实例。可以采用混合方式处理 bean 的定义,而不是采用特定的 bean 定义方式来创建 bean。
GenericApplicationContext 基本就是对 DefaultListableBeanFactory 做了个简易的封装,几乎所有方法都是使用了 DefaultListableBeanFactory 的方法去实现。
GenericApplicationContext 更多是作为一个通用的上下文(通用的 IOC 容器)而存在,BeanFactory 本质上也就是一个 IOC 容器,一个用来生产和获取 beans 的工厂。几乎可以把 GenericApplicationContext 等价于 DefaultListableBeanFactory+上下文刷新等其他功能
public class GenericApplicationContext extends AbstractApplicationContext implements BeanDefinitionRegistry {
//内部的beanFactory
private final DefaultListableBeanFactory beanFactory;
@Nullable
private ResourceLoader resourceLoader;
private boolean customClassLoader = false;
private final AtomicBoolean refreshed = new AtomicBoolean();
/**
* Create a new GenericApplicationContext.
* @see #registerBeanDefinition
* @see #refresh
*/
public GenericApplicationContext() {
this.beanFactory = new DefaultListableBeanFactory();
}
//......
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 15.bean 的自动装配
在 Spring 中,对象无需自己查找或创建与其关联的其他对象,由容器负责把需要相互协作的对象引用赋予各个对象,使用 Autowire 来配置自动装载模式。
在 Spring 框架的 XML 配置中,有五种自动装配的方式,它们用于自动解析依赖关系并将相应的 Bean 注入到目标 Bean 中。这些自动装配方式通过 <bean> 元素的 autowire 属性来配置。以下是这五种自动装配方式的说明:
no:默认值,不进行自动装配,需要手动配置依赖关系。您需要显式地在 <property> 元素中指定引用的 Bean。
<bean id="beanA" class="com.example.BeanA">
<property name="dependency" ref="beanB" />
</bean>
2
3
byName:根据属性的名称进行自动装配。Spring 将根据属性名查找对应的 Bean,并将它自动注入到目标 Bean 的属性中。
<bean id="beanA" class="com.example.BeanA" autowire="byName" />
byType:根据属性的数据类型进行自动装配。Spring 将根据属性类型查找对应的 Bean,并将它自动注入到目标 Bean 的属性中。如果有多个匹配的 Bean,将抛出异常。
<bean id="beanA" class="com.example.BeanA" autowire="byType" />
constructor:根据构造方法参数的类型进行自动装配。类似于 byType,但是是用于构造方法参数的自动装配。
<bean id="beanA" class="com.example.BeanA" autowire="constructor" />
autodetect:根据属性的数据类型进行自动装配,如果找不到匹配的 Bean,会尝试通过构造方法参数的类型进行自动装配。
<bean id="beanA" class="com.example.BeanA" autowire="autodetect" />
# 16.beanName 生成策略
- DefaultBeanNameGenerator
AnnotationBeanNameGenerator- FullyQualifiedAnnotationBeanNameGenerator
AnnotationBeanNameGenerator 是 Spring 的默认生成策略,buildDefaultBeanName 方法是生成名称的实现。
String shortClassName = ClassUtils.getShortName(definition.getBeanClassName());
return Introspector.decapitalize(shortClassName);
2
这个默认的生成策略其实就是取首字母小写后的类名称,作为 Bean 名称。
这里 definition.getBeanClassName() 是获取全限定名称的,ClassUtils.getShortName() 是获取类名的,下面的 Introspector.decapitalize() 实际上就是把首字母变小写的。
这里要设置为全限定名称,我们可以新写一个类,例如 SherlockyAnnotationBeanNameGenerator ,继承 AnnotationBeanNameGenerator 之后重写buildDefaultBeanName方法,返回 definition.getBeanClassName() ,这样我们这个生成策略就写好了。
public String generateBeanName(BeanDefinition definition, BeanDefinitionRegistry registry) {
if (definition instanceof AnnotatedBeanDefinition) {
// @Component、@Service 如果指定了 value 的话,那么 bean name 就是指定的值
String beanName = determineBeanNameFromAnnotation((AnnotatedBeanDefinition) definition);
if (StringUtils.hasText(beanName)) {
// Explicit bean name found.
return beanName;
}
}
// @Component、@Service 没有指定 value 的话,就使用默认的生成规则来生成 bean name
// Fallback: generate a unique default bean name.
return buildDefaultBeanName(definition, registry);
}
/**
* 默认生成的 bean name 是类名小写:例如“mypackage.MyJdbcDao” -> “myJdbcDao”。
* 请注意:
* 1. 如果是内部类的话,因此将会是 “outerClassName.InnerClassName” 形式的名称
* 2. 类名如果是连续2个首字母大写的话,bean name 就是类名:例如 “mypackage.MYJdbcDao” -> “MYJdbcDao”
*/
protected String buildDefaultBeanName(BeanDefinition definition) {
String beanClassName = definition.getBeanClassName();
Assert.state(beanClassName != null, "No bean class name set");
String shortClassName = ClassUtils.getShortName(beanClassName);
// 根据类名来生成 bean name
return Introspector.decapitalize(shortClassName);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
@Service、@Componet 定义的 bean name 的生成规则如下:
- 优先取注解中的 value 指定的名字做为 bean name。
- 如果注解中没有指定的话,默认情况下是类名小写,例如: “mypackage.MyJdbcDao” -> “myJdbcDao”
- 注意有两种特殊的情况:
- 如果 bean 是内部类的话,因此将会是 “outerClassName.InnerClassName” 形式的名称
- 如果类名是连续 2 个首字母大写的话,bean name 就是类名,例如:“mypackage.MYJdbcDao” -> “MYJdbcDao”
@Bean 定义的 bean name 的生成规则是:
- 优先取注解中 name 指定的名字做为 bean name。
- 如果注解中没有指定的话,就取 methodName 做为 bean name。
# 17.属性注入具体实现
属性注入是一种依赖注入的方式,它允许您将一个 Bean 的属性值注入到另一个 Bean 中。在 Spring 框架中,有几种不同的方式来实现属性注入,包括 XML 配置和基于注解的方式。
- xml 配置方式
- @Autowired 注入
- 构造器注入
- setter 注入
以下是属性注入的具体实现示例:
1. XML 配置方式:
假设有两个类,Student 和 School,我们要将 Student 的 school 属性注入为 School 对象。
public class Student {
private School school;
// Getter and Setter for school
// ...
}
public class School {
// ...
}
2
3
4
5
6
7
8
9
10
11
在 Spring 的 XML 配置文件中,可以这样进行属性注入:
<bean id="studentBean" class="com.example.Student">
<property name="school" ref="schoolBean" />
</bean>
<bean id="schoolBean" class="com.example.School">
<!-- 设置 schoolBean 的属性值 -->
</bean>
2
3
4
5
6
7
2. 使用 @Autowired 注解:
使用 @Autowired 注解可以自动注入依赖对象,前提是目标 Bean 在 Spring 容器中已经被定义为 Bean。
public class Student {
@Autowired
private School school;
// Getter and Setter for school
// ...
}
2
3
4
5
6
7
8
确保在 Spring 配置中启用了自动装配(autowiring):
<context:annotation-config />
3. 使用构造方法注入:
您还可以通过构造方法进行属性注入,这是一种强烈推荐的方式,因为它可以确保对象的依赖关系在创建时就被满足。
public class Student {
private School school;
public Student(School school) {
this.school = school;
}
// Getter and Setter for school
// ...
}
2
3
4
5
6
7
8
9
10
11
在 XML 配置中,可以这样注入依赖:
<bean id="studentBean" class="com.example.Student">
<constructor-arg ref="schoolBean" />
</bean>
<bean id="schoolBean" class="com.example.School">
<!-- 设置 schoolBean 的属性值 -->
</bean>
2
3
4
5
6
7
无论您选择哪种方式,属性注入都可以让您在 Spring 容器中定义 Bean 的依赖关系,从而实现了松耦合和可维护性。选择合适的方式取决于您的项目需求和偏好。
# 18.如何实现一个 IOC 容器?
IOC(Inversion of Control),意思是控制反转,不是什么技术,而是一种设计思想,IOC 意味着将你设计好的对 象交给容器控制,而不是传统的在你的对象内部直接控制。
在传统的程序设计中,我们直接在对象内部通过 new 进行对象创建,是程序主动去创建依赖对象,而 IOC 是有 专门的容器来进行对象的创建,即 IOC 容器来控制对象的创建。
在传统的应用程序中,我们是在对象中主动控制去直接获取依赖对象,这个是正转,反转是由容器来帮忙创 建及注入依赖对象,在这个过程过程中,由容器帮我们查找级注入依赖对象,对象只是被动的接受依赖对象。
先准备一个基本的容器对象,包含一些 map 结构的集合,用来方便后续过程中存储具体的对象
进行配置文件的读取工作或者注解的解析工作,将需要创建的 bean 对象都封装成 BeanDefinition 对象存储
在容器中
容器将封装好的 BeanDefinition 对象通过反射的方式进行实例化,完成对象的实例化工作
进行对象的初始化操作,也就是给类中的对应属性值就行设置,也就是进行依赖注入,完成整个对象的创建,变成一个完整的 bean 对象,存储在容器的某个 map 结构中
通过容器对象来获取对象,进行对象的获取和逻辑处理工作
提供销毁操作,当对象不用或者容器关闭的时候,将无用的对象进行销毁
# 四.AOP
# 1.什么是 AOP?
AOP(Aspect-Oriented Programming,面向切面编程)是一种编程范式,旨在通过将横切关注点(cross-cutting concerns)与主要业务逻辑分离,以提高代码的模块化、可维护性和可重用性。横切关注点通常包括日志记录、事务管理、安全性等方面,它们会横跨多个模块或组件。
在传统的面向对象编程中,一个类通常负责一个主要的功能,而横切关注点的代码则会分散在多个类中,导致代码重复和维护困难。AOP 的目标是通过将横切关注点与主要业务逻辑进行分离,以便更好地管理和维护这些关注点。
AOP 使用一种称为 "切面"(Aspect)的概念,切面是一个模块化单元,它包含了与横切关注点相关的代码。AOP 框架可以将切面织入(weave)到应用程序的主要业务逻辑中,从而实现横切关注点的功能。
# 2.AOP 中的重要概念
切点(Pointcut):用于定义在何处(即何时)应用切面。切点是一个表达式,可以指定要拦截的方法或类。
通知(Advice):切面的具体行为,包括在切点之前、之后或周围执行的代码。通知可以是前置通知(Before)、后置通知(After)、返回通知(AfterReturning)、异常通知(AfterThrowing)和环绕通知(Around)。
连接点(Joinpoint):在应用程序执行过程中,可以被通知拦截的点。连接点可以是方法的调用、方法的执行、字段的访问等。
织入(Weaving):将切面应用到目标对象并创建新的代理对象的过程。
Spring 框架是一个支持 AOP 的框架。它提供了基于代理的 AOP 和基于字节码增强的 AOP 两种方式,让开发者能够方便地使用 AOP 来处理横切关注点。通过 Spring AOP,您可以将日志、事务管理、安全性等功能与业务逻辑分开,提高代码的模块化和可维护性。
# 3.AOP 作用?
提高代码的可重用性
业务代码编码更简洁
业务代码维护更高效
业务功能拓展更便捷
# 4.什么是静态代理?
静态代理是设计模式中的一种,它是在编译期间就已经创建好的代理类,用于代表原始对象,以控制对原始对象的访问。代理类和原始类实现了同样的接口,从而可以在不改变客户端代码的情况下,增加一些额外的功能或控制。
在静态代理中,代理类在编译时已经存在,它对客户端完全透明。客户端通过调用代理类的方法来访问原始对象,代理类可以在调用前后执行一些操作,例如日志记录、安全性检查、性能监控等。
静态代理的一个典型应用场景是对业务逻辑的增强,而不改变原始业务逻辑的情况下添加一些额外的处理。以下是静态代理的基本结构:
// 接口
public interface Subject {
void doSomething();
}
// 原始类
public class RealSubject implements Subject {
@Override
public void doSomething() {
System.out.println("RealSubject is doing something.");
}
}
// 代理类
public class ProxySubject implements Subject {
private Subject realSubject;
public ProxySubject(Subject realSubject) {
this.realSubject = realSubject;
}
@Override
public void doSomething() {
// 额外的处理
System.out.println("ProxySubject is doing something before calling RealSubject.");
// 调用原始对象的方法
realSubject.doSomething();
// 额外的处理
System.out.println("ProxySubject is doing something after calling RealSubject.");
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
在这个例子中,RealSubject 是原始对象,ProxySubject 是代理类。ProxySubject 实现了与 RealSubject 相同的接口 Subject,并在调用 doSomething 方法前后添加了额外的处理。
使用静态代理可以提供更好的代码分离,但也有一些缺点,例如每一个被代理的类都需要对应一个代理类,如果有多个被代理的类,会导致代理类的数量增加。此外,静态代理也无法灵活地在运行时切换代理行为,需要在编译期间确定。
# 5.什么是动态代理?
Spring AOP 是运行期间创建代理对象,使用反射机制,JDK 和 CGLIB 都是动态代理。
动态代理(Dynamic Proxy)是一种设计模式,它允许在运行时创建代理对象,以代替实际对象来控制对目标对象的访问。动态代理通常用于实现横切关注点,如日志记录、性能监控、事务管理等。
在动态代理中,代理对象是在运行时动态生成的,而不是在编译时固定生成。它通过拦截对目标对象的方法调用,并在方法调用前后执行一些额外的操作,从而实现横切关注点的功能。
在 Java 中,动态代理通常通过两种方式实现:
基于接口的动态代理:在运行时,动态生成一个实现指定接口的代理类。Java 提供了
java.lang.reflect.Proxy类来实现基于接口的动态代理。代理类实现了目标接口,并将方法调用转发给一个InvocationHandler接口的实现类,在该实现类中可以定义横切逻辑。基于类的动态代理:这种方式需要使用第三方库,如 CGLib。它会动态生成目标类的子类作为代理类,而不是实现接口。由于 Java 不允许多继承,所以该方法只能代理没有被继承的类。
以下是一个基于接口的动态代理的简单示例:
import java.lang.reflect.InvocationHandler;
import java.lang.reflect.Method;
import java.lang.reflect.Proxy;
public class DynamicProxyExample {
public interface Calculator {
int add(int a, int b);
}
public static class CalculatorImpl implements Calculator {
@Override
public int add(int a, int b) {
return a + b;
}
}
public static class LoggingHandler implements InvocationHandler {
private Object target;
public LoggingHandler(Object target) {
this.target = target;
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
System.out.println("Before method: " + method.getName());
Object result = method.invoke(target, args);
System.out.println("After method: " + method.getName());
return result;
}
}
public static void main(String[] args) {
Calculator target = new CalculatorImpl();
LoggingHandler handler = new LoggingHandler(target);
Calculator proxy = (Calculator) Proxy.newProxyInstance(
target.getClass().getClassLoader(),
target.getClass().getInterfaces(),
handler
);
int result = proxy.add(5, 3); // This will trigger the logging
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
在这个示例中,LoggingHandler 是一个 InvocationHandler 的实现类,它在目标方法调用前后添加了日志记录。通过 Proxy.newProxyInstance 方法创建了一个代理对象,这个代理对象实现了 Calculator 接口,并且在方法调用时会由 LoggingHandler 处理。
# 6.newProxyInstance
newProxyInstance 方法有三个参数:
- loader: 用哪个类加载器去加载代理对象
- interfaces:动态代理类需要实现的接口
- h:动态代理方法在执行时,会调用 h 里面的 invoke 方法去执行
public static Object newProxyInstance(ClassLoader loader,
Class<?>[] interfaces,
InvocationHandler h)
throws IllegalArgumentException
2
3
4
public class VehicalInvacationHandler implements InvocationHandler {
private final IVehical vehical;
public VehicalInvacationHandler(IVehical vehical){
this.vehical = vehical;
}
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
System.out.println("---------before-------");
Object invoke = method.invoke(vehical, args);
System.out.println("---------after-------");
return invoke;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
public class App {
public static void main(String[] args) {
IVehical car = new Car();
IVehical vehical = (IVehical)Proxy.newProxyInstance(car.getClass().getClassLoader(), Car.class.getInterfaces(), new VehicalInvacationHandler(car));
vehical.run();
}
}
2
3
4
5
6
7
# 7.什么是 AspectJ?
AspectJ 是一个强大的面向切面编程(AOP)框架,它提供了一种在 Java 编程中实现横切关注点的方式。与 Spring 的 AOP 相比,AspectJ 提供了更丰富的功能和更直接的支持。
以下是 AspectJ 的一些关键特点和概念:
切面(Aspect):切面是 AspectJ 中的核心概念,它类似于 AOP 中的 "切面"。切面定义了横切关注点和横切逻辑。在 AspectJ 中,您可以使用 Java 类来定义切面,可以包含多个通知(Advice)和切点(Pointcut)。
通知(Advice):通知是切面的行为,定义了在何时和如何应用横切逻辑。AspectJ 提供了五种通知类型:前置通知(Before)、后置通知(After)、返回通知(AfterReturning)、异常通知(AfterThrowing)和环绕通知(Around)。
切点(Pointcut):切点定义了在应用程序中哪些方法应该被拦截,即何时应用切面。AspectJ 使用表达式语言来描述切点,以匹配方法签名、类名等条件。
连接点(Joinpoint):在应用程序执行过程中,可以被切面拦截的点。连接点可以是方法的调用、方法的执行、字段的访问等。
织入(Weaving):织入是将切面的行为应用到目标对象中的过程。AspectJ 在编译期或运行期执行织入,将切面的代码插入到目标代码中。
编译时织入:AspectJ 支持在编译期执行织入,它可以在编译时将切面的代码织入到目标类中,生成织入后的类文件。
运行时织入:AspectJ 也支持在运行时执行织入,通过加载时代理(Load-Time Weaving)来实现。这允许您在应用程序运行时动态地将切面织入到类中。
AspectJ 提供了更丰富的功能和更强大的 AOP 支持,允许您在 Java 代码中直接定义切面,更灵活地实现横切关注点。与 Spring AOP 相比,AspectJ 的学习曲线可能稍高,但它提供了更大的灵活性和控制力。您可以根据项目需求和偏好来选择使用 AspectJ 或其他 AOP 框架。
# 8.AOP 实现原理?
Spring 框架一般都是基于 AspectJ 实现 AOP 操作。
AOP(Aspect-Oriented Programming,面向切面编程)的实现原理涉及到拦截和修改代码执行的机制。AOP 允许您在代码执行过程中插入横切逻辑,而无需显式地修改源代码。以下是 AOP 的一般实现原理:
切点(Pointcut)选择:AOP 根据切点定义来确定在何处(即何时)应用切面。切点通常使用表达式或规则描述了目标方法的选择条件,例如类名、方法名、注解等。
通知(Advice)定义:通知是切面的实际行为,它定义了在切点处执行的代码。AOP 提供了多种通知类型,如前置通知(Before)、后置通知(After)、返回通知(AfterReturning)、异常通知(AfterThrowing)和环绕通知(Around)。
织入(Weaving):织入是将切面的行为应用到目标代码中的过程。织入可以在编译时、类加载时或运行时进行。织入将切面的通知代码插入到目标代码的特定位置,以便在执行时执行额外的逻辑。
编译时织入:在编译期间将切面的代码插入到目标类的字节码中。这要求使用特定的编译器或工具,如 AspectJ 编译器。
类加载时织入:在类被加载到 JVM 之前,通过特定的代理机制来实现切面的织入。这种方式可以实现动态织入,但需要使用支持的类加载器。
运行时织入:在应用程序运行时动态地将切面的代码织入到目标类中。这通常需要使用特定的代理技术,如 Java 动态代理或 CGLib。
代理生成(Proxy Generation):在某些情况下,AOP 使用代理来实现织入。代理类可以包装目标类,然后在方法调用前后执行通知代码。代理可以基于接口或类创建,取决于代理库和目标类是否实现了接口。
运行时调度:在运行时,AOP 框架需要拦截目标方法的调用并决定是否执行通知。这可能涉及使用反射或其他机制来调度通知代码的执行。
总体来说,AOP 的实现原理在于拦截、修改和调度目标代码的执行,从而实现横切关注点的功能。不同的 AOP 框架可能在实现细节上有所不同,但核心思想是相似的:通过织入通知代码来实现切面行为,从而实现代码的模块化和可重用性。
# 9.Aop 的通知类型
在 AOP(Aspect-Oriented Programming,面向切面编程)中,通知(Advice)是切面的实际行为,它定义了在目标代码的不同执行点执行的逻辑。AOP 框架提供了几种不同类型的通知,以便您可以在目标代码的不同位置插入横切逻辑。以下是 AOP 中常见的通知类型:
前置通知(Before Advice):前置通知在目标方法调用之前执行,允许您在目标方法执行之前执行一些逻辑,例如安全性检查、参数验证等。
后置通知(After Advice):后置通知在目标方法执行之后(无论是否发生异常)执行,允许您在目标方法执行后执行一些逻辑,例如清理资源、记录日志等。
返回通知(AfterReturning Advice):返回通知在目标方法成功执行并返回结果后执行,允许您在目标方法成功执行后执行一些逻辑,例如处理返回结果、记录成功日志等。
异常通知(AfterThrowing Advice):异常通知在目标方法抛出异常时执行,允许您在目标方法抛出异常后执行一些逻辑,例如处理异常、记录错误日志等。
环绕通知(Around Advice):环绕通知是最强大的通知类型,它可以在目标方法调用前后执行,并完全控制目标方法的执行。环绕通知可以决定是否继续执行目标方法,以及在何时、如何执行目标方法。
这些通知类型允许您将横切关注点的逻辑从主要业务逻辑中分离出来,从而实现代码的模块化和可维护性。在使用 AOP 框架时,您可以选择适当的通知类型来实现所需的横切功能。通常,通知会与切点(Pointcut)一起使用,切点定义了在何处应用通知。
# 10.没有 AspectJ,如何实现 AOP?
- 使用代理模式:在 Spring 框架中,您可以使用代理模式来实现 AOP 的一些功能。Spring 提供了两种代理方式:JDK 动态代理和 CGLib 动态代理。通过创建代理对象,您可以在方法调用前后插入横切逻辑。
- 编写自定义切面类:您可以编写自定义的切面类,将横切逻辑封装在这些类中,然后在需要的地方手动调用切面类的方法。虽然这种方式没有自动织入的便利,但它可以实现一些 AOP 功能。
# 11.getTarget 和 getThis
getTarget() 和 getThis() 是在 Spring AOP 中用于获取目标对象引用的方法。这两个方法通常在切面中被使用,用于获取当前正在执行的方法所属的目标对象。虽然它们在很多情况下返回相同的对象,但在某些特定情况下,它们可能会返回不同的对象。
getTarget()方法: 这个方法返回正在被代理的目标对象的引用。如果你的切面是织入到目标对象上的,那么调用getTarget()将会返回目标对象本身。getThis()方法: 这个方法返回正在执行的代理对象的引用。代理对象是由 AOP 框架生成的,它包装了目标对象并执行切面逻辑。调用getThis()方法将会返回代理对象。
在大多数情况下,getTarget() 和 getThis() 返回的是相同的对象,因为切面通常是织入到目标对象上的。然而,有些情况下它们可能会有区别:
自我调用的问题: 如果在目标方法内部调用自身(递归调用),那么
getTarget()将会返回正在被代理的目标对象,而getThis()将会返回代理对象。这可能会导致一些意外行为,因为在递归调用时可能会绕过切面逻辑。类内部调用问题: 如果在同一个类中的一个方法调用另一个方法,
getTarget()和getThis()可能会返回不同的对象。这是因为 Spring AOP 通常只对外部调用进行代理,对于类内部的方法调用可能不会触发切面逻辑。
# 12.Advice、Advisor、Advised 区别?
在 Spring AOP 中,"Advice"、"Advisor" 和 "Advised" 是关于切面(Aspect)和代理(Proxy)的核心概念。它们分别表示切面逻辑、切面定义和被代理的对象。以下是它们之间的区别:
Advice(切面逻辑): Advice 是切面中实际的逻辑或行为,它是在连接点(Join Point)处执行的代码。Advice 决定了在连接点的何时执行,有不同类型的 Advice,包括:
- Before Advice:在连接点之前执行。
- After Returning Advice:在连接点正常返回后执行。
- After Throwing Advice:在连接点抛出异常后执行。
- After Advice:无论连接点如何结束(包括正常返回或异常),都会执行。
- Around Advice:围绕连接点执行,可以控制连接点执行的流程。
Advisor(切面定义): Advisor 是一个由 Pointcut 和 Advice 组成的对象,它定义了切面在何处执行以及如何执行。Advisor 将 Advice 与 Pointcut 关联起来,决定了切面逻辑在哪些连接点被触发。Spring 框架提供了多种实现 Advisor 的方式,如使用
AspectJExpressionPointcut和DefaultPointcutAdvisor等。Advised(被代理的对象): Advised 表示被代理的对象,即应用了切面逻辑的目标对象。Advised 对象在运行时会被代理,切面逻辑会在其连接点上执行。在 Spring AOP 中,通常 Advised 对象是 Spring 容器中的 Bean,这些 Bean 可以被代理以便在其方法执行时执行切面逻辑。
在 Spring AOP 的使用中,通常步骤如下:
- 创建一个实现了 Advice 接口的切面类,其中包含切面逻辑。
- 创建一个 Advisor 对象,将切面类和 Pointcut 关联起来。
- 在配置文件中配置 Advisor。
- 创建被代理的 Bean,并将切面逻辑应用于它。
例如,以下是一个简单的示例:
import org.springframework.aop.AfterReturningAdvice;
import org.springframework.aop.framework.ProxyFactory;
public class MyAfterReturningAdvice implements AfterReturningAdvice {
@Override
public void afterReturning(Object returnValue, Method method, Object[] args, Object target) throws Throwable {
System.out.println("After returning advice: Method " + method.getName() + " has returned value: " + returnValue);
}
public static void main(String[] args) {
MyAfterReturningAdvice advice = new MyAfterReturningAdvice();
ProxyFactory proxyFactory = new ProxyFactory();
proxyFactory.setTarget(new MyService());
proxyFactory.addAdvice(advice);
MyService proxy = (MyService) proxyFactory.getProxy();
proxy.doSomething();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
在这个例子中,MyAfterReturningAdvice 是一个 After Returning Advice,它会在目标对象方法返回后执行。 ProxyFactory 用于创建代理对象,并将切面逻辑应用于目标对象。
# 五.循环依赖
# 1.循环依赖 Bean 生命周期
**Spring 循环依赖,只支持 setter 方式的依赖注入,不支持构造函数的依赖注入。**只针对单例 bean。
总结:
A 与 B 对象相互依赖。
A 首先创建,并将 A 对象标记为正在创建中,然后将
创建方法放到三级缓存中(factory)。创建过程中,在填充属性时发现需要 B,于是去创建 B(尝试从三级缓存中获取,但是获取不到),并将 B 也标记为正在创建中。B 创建的时候,在填充属性的时候发现需要 A,于是又去创建对象 A,尝试从三级缓存中获取 A,可以获取到,并将 A 放入
二级缓存,于是 B 就成功创建了,并放入一级缓存,同时清空二三级缓存,同时返回 B返回 B 以后,A 也成功赋值创建,就完成了 A 和 B 的创建。
# 2.三级缓存?
/** Cache of singleton objects: bean name to bean instance. */
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256);
/** Cache of singleton factories: bean name to ObjectFactory. */
private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<>(16);
/** Cache of early singleton objects: bean name to bean instance. */
private final Map<String, Object> earlySingletonObjects = new ConcurrentHashMap<>(16);
2
3
4
5
6
7
8
# 3.三级缓存的作用
一级缓存:
- 存放的已经经历了完整生命周期的 bean
- 该缓存是对外使用的,指的就是使用 Spring 框架的程序员。
二级缓存:
- 存放早期暴露的对象,bean 的生命周期还没有完全结束(属性还没填充完整的)
- 该缓存是对内使用的,指的就是 Spring 框架内部逻辑使用该缓存。
- 是一个载体,B 对象在三级缓存获取到创建 A 的方法,创建好 A 后,将 A 放入二级缓存
三级缓存:存放可以生成 bean 的工厂,是一个兰姆达函数
- 通过 ObjectFactory 对象来存储单例模式下提前暴露的 Bean 实例的引用(正在创建中)。
- 该缓存是对内使用的,指的就是 Spring 框架内部逻辑使用该缓存
- 此缓存是解决循环依赖最大的功臣
# 4.详解第三级缓存
第三级缓存在添加时,是通过 addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean)); 添加到 singletonFactories 中的。
当 bean 被循环依赖时,第一级缓存 singletonObjects 中还没有完全创建好的 bean;此时,第二级缓存 singletonFactories 中也没有 bean 的早期引用;
所以,这时只能通过第三级缓存 earlySingletonObjects 来获取 bean 的早期引用。
第三级缓存对应的 ObjectFactory 的实现是通过 lambda 表达式: () -> getEarlyBeanReference(beanName, mbd, bean) 来实现的,具体代码如下:
// AbstractAutowireCapableBeanFactory#getEarlyBeanReference()
/**
* Obtain a reference for early access to the specified bean, typically for the purpose of resolving a circular reference.
* 获取指定 bean 的早期引用,通常用于解析循环引用。
*/
protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) {
Object exposedObject = bean;
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
for (SmartInstantiationAwareBeanPostProcessor bp : getBeanPostProcessorCache().smartInstantiationAware) {
exposedObject = bp.getEarlyBeanReference(exposedObject, beanName);
}
}
return exposedObject;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
可以看到,第三级缓存会将 bean 的原始引用通过 SmartInstantiationAwareBeanPostProcessor#getEarlyBeanReference() 来进行处理。
它只有一个实现,如下:
// AbstractAutoProxyCreator#getEarlyBeanReference()
public Object getEarlyBeanReference(Object bean, String beanName) {
Object cacheKey = getCacheKey(bean.getClass(), beanName);
this.earlyProxyReferences.put(cacheKey, bean);
// 如果有需要的话,对 bean 生成代理
return wrapIfNecessary(bean, beanName, cacheKey);
}
2
3
4
5
6
7
如果 bean 是需要被 AOP 增强的话,getEarlyBeanReference() 就会提前给 bean 的原始引用生成代理。
如果 bean 不需要被 AOP 增强的话,getEarlyBeanReference() 就不会做任何操作,直接返回原始引用。
所以,第三级缓存真正起作用的是针对 AOP 代理 bean 被循环引用的情况,这种 bean 需要提前通过第三级缓存生成 AOP 代理对象,然后放入二级缓存中。
第三级缓存是为了解决 AOP 代理 bean 被循环依赖的场景。

# 5.哪些循环依赖解决不了?
1.prototype 类型的循环依赖:
分析:
- A 实例创建后,populateBean 时,会触发 B 的加载。
- B 实例创建后,populateBean 时,会触发 A 的加载。由于 A 的 scope=prototype,从缓存中获取不到 A,要创建一个全新的 A。
- 这样,就会进入一个死循环。Spring 肯定是解决不了这种情况下的循环依赖的。所以,提前进行了 check,并抛出了异常。
解决方案:在需要循环注入的属性上添加 @Lazy
2.constructor 注入的循环依赖:
分析:
- A 实例在创建时(createBeanInstance),由于是构造注入,这时会触发 B 的加载。
- B 实例在创建时(createBeanInstance),又会触发 A 的加载,此时,A 还没有添加到三级缓存中,所以就会创建一个全新的 A。
- 这样,就会进入一个死循环。Spring 是解决不了这种情况下的循环依赖的。所以,提前进行了 check,并抛出了异常。
解决:
在需要循环注入的属性上添加 @Lazy 例如:public A(@Lazy B b){...}
3.普通的 AOP 代理 Bean 的循环依赖–(默认是可以的):
描述:
A --> B --> A, 且 A,B 都是普通的 AOP Proxy 类型的 bean
普通的 AOP proxy 类型指:通过用户自定义的 @Aspect 切面生成的代理 bean,区别于 @Async 标记的类产生的 AOP 代理
Spring 默认解决了 普通的 AOP 代理 Bean 的循环依赖 问题,这里单独拿出来,是为了与 @Async 增强的代理 Bean 场景 进行对比。
分析:
- 通常情况下, AOP proxy 的创建是在
initializeBean的时候,通过BeanPostProcessor处理的。 - A 在
createBeanInstance之后,添加到三级缓存。populateBean时触发 B 的加载。 - B 在
createBeanInstance之后,添加到三级缓存。populateBean时触发 A 的加载,这时,三级缓存中有 A,那么通过三级缓存 ObjectFactory#get() 可以获取到 bean 的早期引用。
// AbstractAutowireCapableBeanFactory#getEarlyBeanReference()
/**
* Obtain a reference for early access to the specified bean, typically for the purpose of resolving a circular reference.
* 获取指定 bean 的早期引用,通常用于解析循环引用。
*/
protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) {
Object exposedObject = bean;
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
for (SmartInstantiationAwareBeanPostProcessor bp : getBeanPostProcessorCache().smartInstantiationAware) {
exposedObject = bp.getEarlyBeanReference(exposedObject, beanName);
}
}
return exposedObject;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
普通的 AOP 代理都是通过 AbstractAutoProxyCreator 来生成代理类的,而 AbstractAutoProxyCreator 实现了 SmartInstantiationAwareBeanPostProcessor,所以,在通过三级缓存 getEarlyBeanReference() 的时候,就可以提前获取到最终暴露到 Spring 容器中的代理 bean 的早期引用。
public abstract class AbstractAutoProxyCreator extends ProxyProcessorSupport
implements SmartInstantiationAwareBeanPostProcessor, BeanFactoryAware {
......
}
2
3
4
4.@Async 增强的 Bean 的循环依赖:
描述:
A --> B --> A, 且 A 是被 @Async 标记的类
@Service
public class A {
@Autowired
private B b;
@Async
public void m1(){
}
}
@Service
public class B {
@Autowired
private A a;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
@Async 产生的代理和普通的 AOP 代理有什么区别了?
分析:
- proxy 的创建是在
initializeBean的时候,通过BeanPostProcessor处理的。 - A 在
createBeanInstance之后,添加到三级缓存。populateBean时触发 B 的加载。 - B 在
createBeanInstance之后,添加到三级缓存。populateBean时触发 A 的加载,这时,三级缓存中有 A,那么通过三级缓存 ObjectFactory#get() 可以获取到 bean 的早期引用。
普通的 AOP 代理都是通过 AbstractAutoProxyCreator 来生成代理类的,AbstractAutoProxyCreator 实现了 SmartInstantiationAwareBeanPostProcessor。
而 @Async 标记的类是通过 AbstractAdvisingBeanPostProcessor 来生成代理的,AbstractAdvisingBeanPostProcessor 没有实现 SmartInstantiationAwareBeanPostProcessor。
public abstract class AbstractAdvisingBeanPostProcessor extends ProxyProcessorSupport implements BeanPostProcessor {
.......
}
2
3
所以,这时通过 A 的三级缓存来获取 bean 的早期引用时,获取到的是 bean 的原始对象的引用,而不会提前生成代理对象。
这时 B 中注入的 A 对象不是代理对象。最后会导致 B 中持有的 A 对象与 Spring 容器中的 bean A 不是同一个对象。
这种情况显然是有问题的,跟我们的预期是不相符的,所以,Spring 在 initializeBean 之后,做了 check,检验二级缓存中的 bean 与最终暴露到 Spring 容器中的 bean 是否是相同的,如果不同,就会报错。
二级缓存中存放的是 bean 的早期引用,与最终暴露到容器中的 bean 的引用必须是相同的。 如果最终暴露的 AOP 代理 bean 与 三级缓存中获取到的早期引用 不是同一个对象引用的话,那就说明被循环依赖注入的 bean 与最终暴露到 Spring 容器中的 bean 不相同,这样是不被允许的。 Spring 通过检查的机制,check 检验二级缓存中的 bean 与最终暴露到 Spring 容器中的 bean 是否是相同的,如果不同,就会报错。
解决: 在需要循环注入的属性上添加 @Lazy
# 6.@Lazy 注解用来解决循环依赖
@Resource 与@Autowired 的区别在处理@Lazy 注解时,被 @Lazy 标记的属性,在 populateBean 注入依赖时,会直接注入一个 proxy 对象。并且,不会触发注入对象的加载。这样的话,就不会产生 bean 的循环加载问题了。
protected Object buildLazyResourceProxy(final LookupElement element, final @Nullable String requestingBeanName) {
TargetSource ts = new TargetSource() {
@Override
public Class<?> getTargetClass() {
return element.lookupType;
}
@Override
public boolean isStatic() {
return false;
}
@Override
public Object getTarget() {
return getResource(element, requestingBeanName);
}
@Override
public void releaseTarget(Object target) {
}
};
ProxyFactory pf = new ProxyFactory();//代理对象
pf.setTargetSource(ts);
if (element.lookupType.isInterface()) {
pf.addInterface(element.lookupType);
}
ClassLoader classLoader = (this.beanFactory instanceof ConfigurableBeanFactory ?
((ConfigurableBeanFactory) this.beanFactory).getBeanClassLoader() : null);
return pf.getProxy(classLoader);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
假设 A 先加载,在创建 A 的实例时,会触发依赖属性 B 的加载,在加载 B 时发现它是一个被 @Lazy 标记过的属性。那么,就不会去直接加载 B,而是产生了一个代理对象注入到了 A 中,这样 A 就能正常的初始化完成放入一级缓存了。
然后,B 加载时,再去注入 A 就能直接从一级缓存中获取到 A,这样 B 也能正常初始化完成了。所以,循环依赖的问题就解决了。
@Lazy 的本质就是将注入的依赖变成了一个代理对象。使用 @Lazy 时,不会触发依赖 bean 的加载。
通过调试代码,我们会发现 A 中注入的 @Lazy B 是一个代理对象。在 A 中,通过 B 的代理对象去调用 B 的方法时,才会去触发 B 的加载。
@Service
public class A {
private B b;
public A(@Lazy B b) {
this.b = b;
}
}
2
3
4
5
6
7
注意:被 @Lazy 标记的依赖属性比较特殊,实际注入的对象与 Spring 容器中存放的对象不是同一个对象!!!
# 7.ObjectProvider 作用
ObjectProvider 提供的是通过 ObjectProvider#getObject() 或者 ObjectProvider#getIfAvailable() 获取 Object 的能力。
也就是说,在依赖注入时,注入的是一个 ObjectProvider 对象,想要获取到真正的 bean 时,可以通过调用 ObjectProvider#getObject() 或者 ObjectProvider#getIfAvailable()。
所以,它跟 @Lazy 起到的作用是很相似的。

可以看到,如果是 ObjectFactory 和 ObjectProvider 类型的依赖,那么会直接 return new DependencyObjectProvider(descriptor, requestingBeanName);,而不会触发依赖 bean 的加载。
等到真正使用 ObjectProvider#getObject() 获取 bean 的时候,才会触发 bean 的加载。
@Lazy 只能延迟注入,但如果容器中没有这个 bean 的话,在使用时,是会报错的。 所以,ObjectFactory 提供的功能是同 @Lazy 等价的。而 ObjectProvider 可以额外提供 required=false 的能力
# 六.Spring 事务
# 1.什么是事务?
事务就是用户定义的一系列数据库操作,这些操作可以视为一个完成的逻辑处理工作单元,要么全部执行,要么全部不执行,是不可分割的工作单元
begin transaction:表示事务的开启标记,commit:表示事务的提交操作,表示该事务的结束,此时将事务中处理的数据刷到磁盘中物理数据库磁盘中去。rollback:表示事务的回滚操作,表示事务异常结束,此时将事务中已经执行的操作撤销回原来的状态。
# 2.事务的四大特性?
为了保证数据库的正确性与一致性事务具有四个特征:
原子性(Atomicity):事务的原子性保证事务中包含的一组更新操作是原子的,不可分割的,不可分割是事务最小的工作单位,所包含的操作被视为一个整体,执行过程中遵循“要么全部执行,要不都不执行”,不存在一半执行,一半未执行的情况。
一致性(Consistency):事务的一致性要求事务必须满足数据库的完整性约束,且事务执行完毕后会将数据库由一个一致性的状态变为另一个一致性的状态。事务的一致性与原子性是密不可分的,如银行转账的例子 A 账户向 B 账户转 1000 元钱,首先 A 账户减去 1000 元钱,然后 B 账户增加 1000 元钱,这两动作是一个整体,失去任何一个操作数据的一致性状态都会遭到破坏,所以这两个动作是一个整体,要么全部操作,要么都不执行,可见事务的一致性与原子性息息相关。
隔离性(Isolation):事务的隔离性要求事务之间是彼此独立的,隔离的。及一个事务的执行不可以被其他事务干扰。具体到操作是指一个事务的操作必须在一个事务 commit 之后才可以进行操作。多事务并发执行时,相当于将并发事务变成串行事务,顺序执行,如同串行调度般的执行事务。这里可以思考事务如何保证它的可串行化的呢?答案锁,接下来会讲到。
持续性(Durability):事物的持续性也称持久性,是指一个事务一旦提交,它对数据库的改变将是永久性的,因为数据刷进了物理磁盘了,其他操作将不会对它产生任何影响。
# 3.Spring 的事务?
Spring 事务有 2 种用法:编程式事务和声明式事务。
所谓声明式事务,就是通过配置的方式,比如通过配置文件(xml)或者注解的方式,告诉 spring,哪些方法需要 spring 帮忙管理事务,然后开发者只用关注业务代码,而事务的事情 spring 自动帮我们控制。
声明式事务的 2 种实现方式
- 配置文件的方式,即在 spring xml 文件中进行统一配置,开发者基本上就不用关注事务的事情了,代码中无需关心任何和事务相关的代码,一切交给 spring 处理。
- 注解的方式,只需在需要 spring 来帮忙管理事务的方法上加上
@Transaction注解就可以了,注解的方式相对来说更简洁一些,都需要开发者自己去进行配置,可能有些同学对 spring 不是太熟悉,所以配置这个有一定的风险,做好代码 review 就可以了。
如何验证事务生效:
- debug 可以进入事务的拦截器
- 打印日志,会开启一个新的事物
# 4.Spring 事务原理
@EnableTransactionManagement
- 利用 TransactionManagementConfigurationSelector 给容器中会导入组件
- 导入两个组件
AutoProxyRegistrarProxyTransactionManagementConfiguration
AutoProxyRegistrar:
给容器中注册一个
InfrastructureAdvisorAutoProxyCreator组件;InfrastructureAdvisorAutoProxyCreator:利用后置处理器机制在对象创建以后,包装对象,返回一个代理对象(增强器),代理对象执行方法利用拦截器链进行调用;
ProxyTransactionManagementConfiguration 做了什么?
- 给容器中注册事务增强器;
- 事务增强器要用事务注解的信息,AnnotationTransactionAttributeSource 解析事务注解
- 事务拦截器:
TransactionInterceptor;
- 保存了事务属性信息,事务管理器;
- 他是一个 MethodInterceptor;
- 在目标方法执行的时候;
- 执行拦截器链;
- 事务拦截器:
执行过程:
- 先获取事务相关的属性
- 再获取
PlatformTransactionManager,如果事先没有添加指定任何transactionmanger,最终会从容器中按照类型获取一个PlatformTransactionManager; - 执行目标方法
- 如果异常,获取到事务管理器,利用事务管理回滚操作;
- 如果正常,利用事务管理器,提交事务
# 5.@EnableTransactionManagement
@EnableTransactionManagement配置类,开启 Spring 事务管理功能。
当 Spring 容器启动的时候,发现有@EnableTransactionManagement 注解,此时会拦截所有 bean 的创建,扫描看一下 bean 上是否有@Transaction 注解(类、或者父类、或者接口、或者方法中有这个注解都可以),如果有这个注解,spring 会通过 aop 的方式给 bean 生成代理对象,代理对象中会增加一个拦截器,拦截器会拦截 bean 中 public 方法执行,会在方法执行之前启动事务,方法执行完毕之后提交或者回滚事务。
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Import(TransactionManagementConfigurationSelector.class)
public @interface EnableTransactionManagement {
/**
* spring是通过aop的方式对bean创建代理对象来实现事务管理的
* 创建代理对象有2种方式,jdk动态代理和cglib代理
* proxyTargetClass:为true的时候,就是强制使用cglib来创建代理
* proxyTargetClass
true
目标对象实现了接口 – 使用CGLIB代理机制
目标对象没有接口(只有实现类) – 使用CGLIB代理机制
false
目标对象实现了接口 – 使用JDK动态代理机制(代理所有实现了的接口)
目标对象没有接口(只有实现类) – 使用CGLIB代理机制
*/
boolean proxyTargetClass() default false;
/**
* 用来指定事务拦截器的顺序
* 我们知道一个方法上可以添加很多拦截器,拦截器是可以指定顺序的
* 比如你可以自定义一些拦截器,放在事务拦截器之前或者之后执行,就可以通过order来控制
*/
int order() default Ordered.LOWEST_PRECEDENCE;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
# 6.@Transaction
需使用事务的目标上加@Transaction 注解
@Transaction放在接口上,那么接口的实现类中所有 public 方法都被 Spring 自动加上事务。@Transaction放在类上,那么当前类以及其下无限级子类中所有 pubilc 方法将被 Spring 自动加上事务@Transaction放在 public 方法上,那么该方法将被 Spring 自动加上事务。- 注意:@Transaction 只对 public 方法有效
@Target({ElementType.TYPE, ElementType.METHOD})
@Retention(RetentionPolicy.RUNTIME)
@Inherited
@Documented
public @interface Transactional {
/**
* 指定事务管理器的bean名称,如果容器中有多事务管理器PlatformTransactionManager,
* 那么你得告诉spring,当前配置需要使用哪个事务管理器
*/
@AliasFor("transactionManager")
String value() default "";
/**
* 同value,value和transactionManager选配一个就行,也可以为空,如果为空,默认会从容器中按照类型查找一个事务管理器bean
*/
@AliasFor("value")
String transactionManager() default "";
/**
* 事务的传播属性
*/
Propagation propagation() default Propagation.REQUIRED;
/**
* 事务的隔离级别,就是制定数据库的隔离级别,数据库隔离级别大家知道么?不知道的可以去补一下
*/
Isolation isolation() default Isolation.DEFAULT;
/**
* 事务执行的超时时间(秒),执行一个方法,比如有问题,那我不可能等你一天吧,可能最多我只能等你10秒
* 10秒后,还没有执行完毕,就弹出一个超时异常吧
*/
int timeout() default TransactionDefinition.TIMEOUT_DEFAULT;
/**
* 是否是只读事务,比如某个方法中只有查询操作,我们可以指定事务是只读的
* 设置了这个参数,可能数据库会做一些性能优化,提升查询速度
*/
boolean readOnly() default false;
/**
* 定义零(0)个或更多异常类,这些异常类必须是Throwable的子类,当方法抛出这些异常及其子类异常的时候,spring会让事务回滚
* 如果不配做,那么默认会在 RuntimeException 或者 Error 情况下,事务才会回滚
*/
Class<? extends Throwable>[] rollbackFor() default {};
/**
* 和 rollbackFor 作用一样,只是这个地方使用的是类名
*/
String[] rollbackForClassName() default {};
/**
* 定义零(0)个或更多异常类,这些异常类必须是Throwable的子类,当方法抛出这些异常的时候,事务不会回滚
*/
Class<? extends Throwable>[] noRollbackFor() default {};
/**
* 和 noRollbackFor 作用一样,只是这个地方使用的是类名
*/
String[] noRollbackForClassName() default {};
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
参数介绍
| 参数 | 描述 |
|---|---|
| value | 指定事务管理器的 bean 名称,如果容器中有多事务管理器 PlatformTransactionManager,那么你得告诉 spring,当前配置需要使用哪个事务管理器 |
| transactionManager | 同 value,value 和 transactionManager 选配一个就行,也可以为空,如果为空,默认会从容器中按照类型查找一个事务管理器 bean |
| propagation | 事务的传播属性,下篇文章详细介绍 |
| isolation | 事务的隔离级别,就是制定数据库的隔离级别,数据库隔离级别大家知道么?不知道的可以去补一下 |
| timeout | 事务执行的超时时间(秒),执行一个方法,比如有问题,那我不可能等你一天吧,可能最多我只能等你 10 秒 10 秒后,还没有执行完毕,就弹出一个超时异常吧 |
| readOnly | 是否是只读事务,比如某个方法中只有查询操作,我们可以指定事务是只读的 设置了这个参数,可能数据库会做一些性能优化,提升查询速度 |
| rollbackFor | 定义零(0)个或更多异常类,这些异常类必须是 Throwable 的子类,当方法抛出这些异常及其子类异常的时候,spring 会让事务回滚 如果不配做,那么默认会在 RuntimeException 或者 Error 情况下,事务才会回滚 |
| rollbackForClassName | 同 rollbackFor,只是这个地方使用的是类名 |
| noRollbackFor | 定义零(0)个或更多异常类,这些异常类必须是 Throwable 的子类,当方法抛出这些异常的时候,事务不会回滚 |
| noRollbackForClassName | 同 noRollbackFor,只是这个地方使用的是类名 |
使用举例:
@Transactional(rollbackFor = Exception.class)
@0verride
public void b(BlogEntity blogEntity)throws Exception{
blogRepository.save(blogEntity);
}
2
3
4
5
# 7.事务传播行为?
/**
* 事务的传播属性
*/
Propagation propagation() default Propagation.REQUIRED;
2
3
4
事务传播行为(propagation behavior)指的就是当一个事务方法被另一个事务方法调用时,这个事务方法应该如何运行。默认是 Propagation.REQUIRED。
例如:methodA 方法调用 methodB 方法时,methodB 是继续在调用者 methodA 的事务中运行呢,还是为自己开启一个新事务运行,这就是由 methodB 的事务传播行为决定的。
Spring 在 TransactionDefinition 接口中规定了 7 种类型的事务传播行为。事务传播行为是 Spring 框架独有的事务增强特性。 7 种:(required / supports / mandatory / requires_new / not supported / never / nested)
PROPAGATION_REQUIRED:如果当前没有事务,就创建一个新事务,如果当前存在事务,就加入该事务,这是最常见的选择,也是 Spring 默认的事务传播行为。(required 需要,没有新建,有加入)PROPAGATION_SUPPORTS:支持当前事务,如果当前存在事务,就加入该事务,如果当前不存在事务,就以非事务执行。(supports 支持,有则加入,没有就不管了,非事务运行)PROPAGATION_MANDATORY:支持当前事务,如果当前存在事务,就加入该事务,如果当前不存在事务,就抛出异常。(mandatory 强制性,有则加入,没有异常)PROPAGATION_REQUIRES_NEW:创建新事务,无论当前存不存在事务,都创建新事务。(requires_new 需要新的,不管有没有,直接创建新事务)PROPAGATION_NOT_SUPPORTED:以非事务方式执行操作,如果当前存在事务,就把当前事务挂起。(not supported 不支持事务,存在就挂起)PROPAGATION_NEVER:以非事务方式执行,如果当前存在事务,则抛出异常。(never 不支持事务,存在就异常)PROPAGATION_NESTED:如果当前存在事务,则在嵌套事务内执行。如果当前没有事务,则按 REQUIRED 属性执行。(nested 存在就在嵌套的执行,没有就找是否存在外面的事务,有则加入,没有则新建)
NESTED和REQUIRED_NEW的区别:
REQUIRED_NEW 是新建一个事务并且新开始的这个事务与原有事务无关,而 NESTED 则是当前存在事务时会开启一个嵌套事务,在 NESTED 情况下,父事务回滚时,子事务也会回滚,而 REQUIRED_NEW 情况下,原有事务回滚,不会影响新开启的事务。
NESTED和REQUIRED的区别:
REQUIRED 情况下,调用方存在事务时,则被调用方和调用方使用同一个事务,那么被调用方出现异常时,由
于共用一个事务,所以无论是否 catch 异常,事务都会回滚,而在 NESTED 情况下,被调用方发生异常时,调用方可以 catch 其异常,这样子事务回滚,父事务不会回滚。
# 8.事务注解不生效场景
自身调用、异常被吃、异常抛出类型不对这三种最为常见
1.数据库引擎不支持事务:
以 MySQL 为例,其 MyISAM 引擎是不支持事务操作的,InnoDB 才是支持事务的引擎,一般要支持事务都会使用 InnoDB。从 MySQL 5.5.5 开始的默认存储引擎是:InnoDB,之前默认的都是:MyISAM,所以要注意的是:底层引擎不支持事务的情况下事务也不会生效。
2.没有被 Spring 管理
// @Service
public class OrderServiceImpl implements OrderService {
@Transactional
public void updateOrder(Order order) {
// update order
}
}
2
3
4
5
6
7
3.方法不是 public 的
以下来自 Spring 官方文档: When using proxies, you should apply the @Transactional annotation only to methods with public visibility. If you do annotate protected, private or package-visible methods with the @Transactional annotation, no error is raised, but the annotated method does not exhibit the configured transactional settings. Consider the use of AspectJ (see below) if you need to annotate non-public methods.
意思大概就是 @Transactional 只能用于 public 的方法上,否则事务不会失效,如果要用在非 public 方法上,可以开启 AspectJ 代理模式。
4.自身调用问题
发生自身调用时,就调该类自己的方法,但是没有经过 Spring 的代理类,默认只有在外部调用事务才会生效,这也是经典的事务问题了。
事务注解不生效,一定要考虑是哪个对象在调用?是代理对象还是普通对象?
生效写法
class UserServiceProxy extends UserService {
UserService target;
@Transactional
public void test(){
//开启事务
// 1、事务管理器新建一个数据库连接conn
// 2.conn.autocommit = false
target.test(); // 普通对象.test()
conn.commit conn.rollback();
}
}
2
3
4
5
6
7
8
9
10
11
12
可以看到只创建了一个事物 ServiceA.test 方法的事务,但是 a 方法却没有被事务增强;
分析原因:Spring 事务生成的对象也是被 Cglib 或 JDK 代理的对象,就区别于该对象本身了,代理的对象执行方法之前会走拦截器链,就不能同 this 方法.
之前 Aop 可以将代理对象暴露到当前线程局部变量中;
<aop:aspectj-autoproxy expose-proxy="true"/>
通过尝试发现,SpringTx 也可以使用该配置,将创建的对象加入到当前线程局部变量;
也许觉得 SpringAop 和 SpringTx 不一样啊,但其实两者都实现了 AbstractAutoProxyCreator 类,同样设置 expose-proxy 也能生效,绑定到线程局部变量上;
不生效写法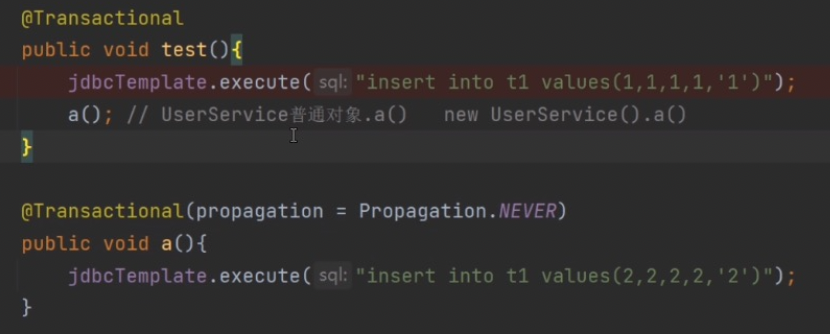
生效写法
确实初始化了 a 方法的事务;
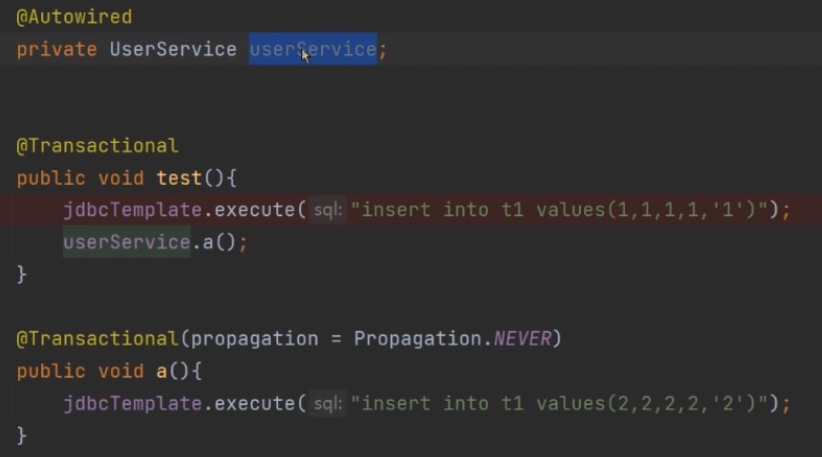
5.没有事务管理器
数据源没有配置事务管理器
@Bean
public PlatformTransactionManager transactionManager(DataSource dataSource) {
return new DataSourceTransactionManager(dataSource);
}
2
3
4
6.不支持事务
@Service
public class OrderServiceImpl implements OrderService {
@Transactional
public void update(Order order) {
updateOrder(order);
}
@Transactional(propagation = Propagation.NOT_SUPPORTED)
public void updateOrder(Order order) {
// update order
}
}
2
3
4
5
6
7
8
9
10
11
Propagation.NOT_SUPPORTED: 表示不以事务运行,当前若存在事务则挂起
7.异常被吃
// @Service
public class OrderServiceImpl implements OrderService {
@Transactional
public void updateOrder(Order order) {
try {
// update order
} catch {
}
}
}
2
3
4
5
6
7
8
9
10
8.抛出异常
这样事务也是不生效的,因为默认回滚的是:RuntimeException,如果你想触发其他异常的回滚,需要在注解上配置一下,如:@Transactional(rollbackFor = Exception.class)这个配置仅限于 Throwable 异常类及其子类。
@Service
public class OrderServiceImpl implements OrderService {
@Transactional
public void updateOrder(Order order) {
try {
// update order
} catch {
throw new Exception("更新错误");
}
}
}
2
3
4
5
6
7
8
9
10
11
# 9.自身调用详解
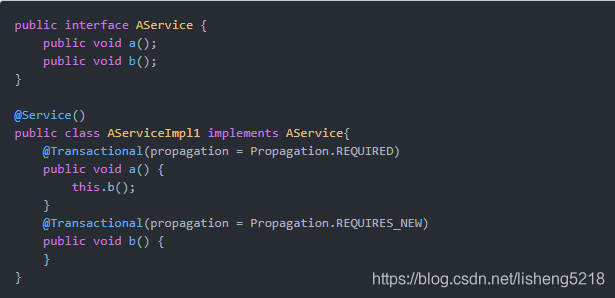
此处的 this 指向目标对象,因此调用 this.b()将不会执行 b 事务切面,即不会执行事务增强,因此 b 方法的事务定义@Transactional(propagation = Propagation.REQUIRES_NEW)将不会实施.
在一个 Service 内部,事务方法之间的嵌套调用,普通方法和事务方法之间的嵌套调用,都不会开启新的事务.是因为 spring 采用动态代理机制来实现事务控制,而动态代理最终都是要调用原始对象的,而原始对象在去调用方法时,是不会再触发代理了!
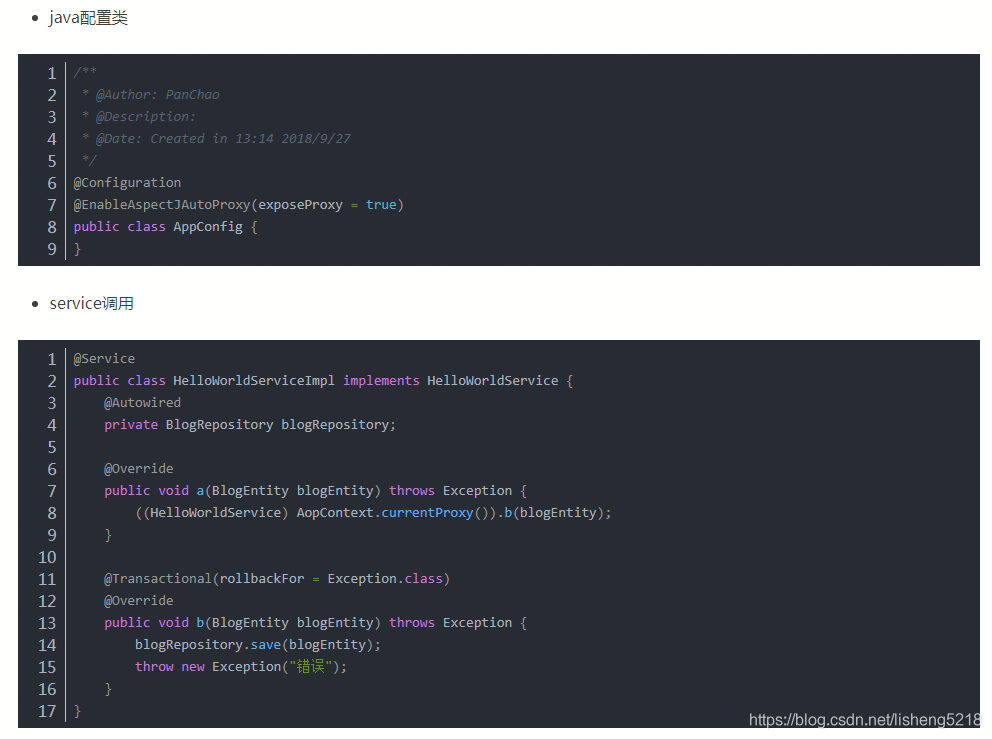
解决方法:
- 可以把方法 B 放到另外一个 service 或者 dao,然后把这个 server 或者 dao 通过@Autowired 注入到方法 A 的 bean 里面,这样即使方法 A 没用事务,方法 B 也可以执行自己的事务了。
- 在 java 配置类上添加注解@EnableAspectJAutoProxy(exposeProxy = true)方式暴漏代理对象,然后在 service 中通过代理对象 AopContext.currentProxy()去调用方法。
# 10.Spring 的事务隔离级别?
/**
* 事务的隔离级别,默认就是数据库的隔离级别
*/
Isolation isolation() default Isolation.DEFAULT;
2
3
4
Spring 有五大隔离级别,默认值为 ISOLATION_DEFAULT(使用数据库的设置),其他四个隔离级别和数据库的隔离级别一致:
ISOLATION_DEFAULT:用底层数据库的设置隔离级别,数据库设置的是什么 Spring 就用什么;ISOLATION_READ_UNCOMMITTED:未提交读,最低隔离级别、事务未提交前,就可被其他事务读取(会出现幻读、脏读、不可重复读);ISOLATION_READ_COMMITTED:提交读,一个事务提交后才能被其他事务读取到(会造成幻读、不可重复读),SQL server 的默认级别;ISOLATION_REPEATABLE_READ:可重复读,保证多次读取同一个数据时,其值都和事务开始时候的内容是一致,禁止读取到别的事务未提交的数据(会造成幻读),MySQL 的默认级别;ISOLATION_SERIALIZABLE:序列化,代价最高最可靠的隔离级别,该隔离级别能防止脏读、不可重复读、幻读。
脏读:表示一个事务能够读取另一个事务中还未提交的数据。比如,某个事务尝试插入记录 A,此时该事务还未提交,然后另一个事务尝试读取到了记录 A。
不可重复读 :是指在一个事务内,多次读同一数据,读取到的结果不一致。
幻读 :指同一个事务内多次查询返回的结果集不一样。比如同一个事务 A 第一次查询时候有 n 条记录,但是第二次同等条件下查询却有 n+1 条记录,这就好像产生了幻觉。发生幻读的原因也是另外一个事务新增或者删除或者修改了第一个事务结果集里面的数据,同一个记录的数据内容被修改了,所有数据行的记录就变多或者变少了。
# 11.事务注解实战
事务 A 调用事务 B 时,它们的事务性行为取决于事务注解的使用和配置。
A 和 B 都有事务注解:如果事务 A 和事务 B 都被注解为使用相同的
事务管理器和相同的事务属性(如隔离级别、传播行为等),那么它们将在同一个事务中运行。这意味着如果事务 A 成功提交,但事务 B 失败回滚,那么整个事务(A 和 B)都将回滚。@Transactional public void methodA() { // ... methodB(); // 调用事务B // ... } @Transactional public void methodB() { // ... }1
2
3
4
5
6
7
8
9
10
11A 有事务注解,B 没有:如果事务 A 有事务注解,但事务 B 没有,那么事务 A 将在自己的事务中运行,而事务 B 将在没有事务的情况下执行。这意味着如果事务 A 成功提交,但事务 B 失败,只有事务 B 会回滚,而事务 A 的提交不受影响。
@Transactional public void methodA() { // ... methodB(); // 调用事务B,但B没有事务注解 // ... } public void methodB() { // ... }1
2
3
4
5
6
7
8
9
10A 没有事务注解,B 有:如果事务 A 没有事务注解,而事务 B 有事务注解,那么事务 A 将在没有事务的情况下执行,而事务 B 将在自己的事务中运行。这样,事务 B 的事务属性会覆盖事务 A 的事务属性。
public void methodA() { // ... methodB(); // 调用事务B,但B有事务注解 // ... } @Transactional public void methodB() { // ... }1
2
3
4
5
6
7
8
9
10
请注意,事务 A 和事务 B 的事务管理器和属性可以根据具体的配置而有所不同,因此在实际情况中,您需要仔细考虑事务的传播行为、隔离级别以及是否使用相同的事务管理器,以确保您的事务行为符合预期。
# 七.注解说明
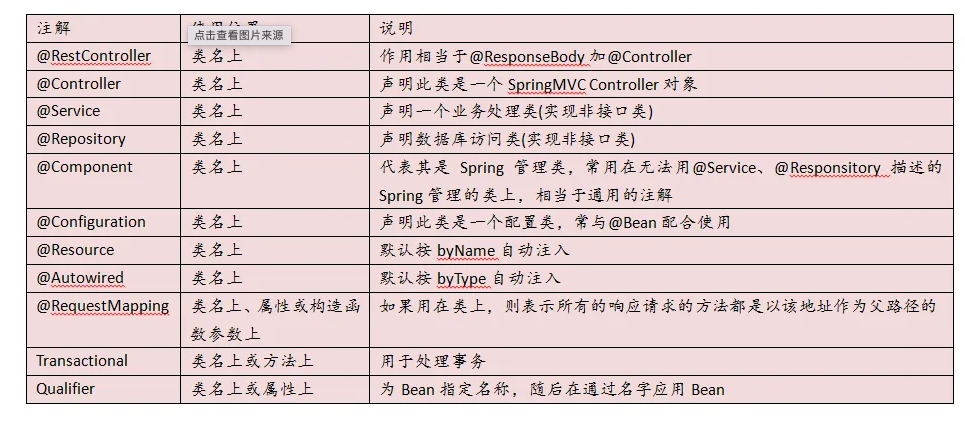
# 1.spring 常用注解
# 2.依赖注入注解
@Autowired 和 @Resource 和 @Qualifier对比。
@Autowired:可以单独使用。如果单独使用,它将按类型装配。
@Target({ElementType.CONSTRUCTOR, ElementType.METHOD, ElementType.PARAMETER, ElementType.FIELD, ElementType.ANNOTATION_TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface Autowired {
boolean required() default true;
}
2
3
4
5
6
@Qualifier:@Qualifier 与 @Autowired 一起,通过指定bean 名称来阐明实际装配的 bean (按姓名连线)
@Target({ElementType.FIELD, ElementType.METHOD, ElementType.PARAMETER, ElementType.TYPE, ElementType.ANNOTATION_TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Inherited
@Documented
public @interface Qualifier {
String value() default "";
}
2
3
4
5
6
7
@Resource:@Resource(这个注解属于 J2EE 的),默认按照名称进行装配,名称可以通过 name 属性进行指定, 如果没有指定 name 属性,当注解写在字段上时,默认取字段名进行按照名称查找,如果注解写在 setter 方法上默认取属性名进行装配。 当找不到与名称匹配的 bean 时才按照类型进行装配。但是需要注意的是,如果 name 属性一旦指定,就只会按照名称进行装配。
package javax.annotation;
@Target({TYPE, FIELD, METHOD})
@Retention(RUNTIME)
public @interface Resource {
String name() default "";
String lookup() default "";
Class<?> type() default java.lang.Object.class;
enum AuthenticationType {
CONTAINER,
APPLICATION
}
AuthenticationType authenticationType() default AuthenticationType.CONTAINER;
boolean shareable() default true;
String mappedName() default "";
String description() default "";
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 3.注解的底层原理是什么?

通过键值对的方式为注解的属性赋值
编译器会检查注解的使用范围. 将注解的信息, 写入元素的属性表
程序运行时, JVM 将 RUNTIME 的所有注解属性都取出最终存入 map 里
JVM 会创建 AnnotationInvocationHandler 实例, 并传递上一步的 map
JVM 会使用 JDK 动态代理为注解生成代理类, 并初始化 AnnotationInvocationHandler
调用 invoke 方法, 通过传入方法名, 返回注解对应的属性值.
# 4.@Conditional 注解
@Conditional (ZhouyuCondition.class)该注解是 Spring4.0 之后才有的,该注解可以放在任意类型或者方法上。通过@Conditional 可以配置一些条件判断,当所有条件都满足时,被该@Conditional 注解标注的目标才会被 Spring 处理。
@Target({ElementType.TYPE,ElementType.METHOD})
@Retention(RetentionPolicy.RUNTIME)
@Document
public @interface Confitional{
Class<? extend Condition> [] value();
}
2
3
4
5
6
value:Condition 类型的数组,Condition 是一个接口,表示一个条件判断,内部有个方法返回 true 或 false,当所有 Condition 都成立的时候,@Conditional 的结果才成立
Condition 接口: 内部有个 match 方法,判断条件是否成立的。
@FunctionalInterface
public interface Condition {
//判断条件是否匹配 context:条件判断上下文
boolean matches(ConditionContext context, AnnotatedTypeMetadata metadata);
}
2
3
4
5
有两个参数:context和metadata
- context:ConditionContext 接口类型的,用来获取容器中的 bean 的信息
- metadata:用来获取被@Conditional 标注的对象上的所有注解信息。
ConditionContext 接口:
public interface ConditionContext {
//返回bean定义注册器,可以通过注册器获取bean定义的各种配置信息
BeanDefinitionRegistry getRegistry();
//返回ConfigurableListableBeanFactory类型的bean工厂,相当于一个ioc容器对象
@Nullable
ConfigurableListableBeanFactory getBeanFactory();
//返回当前spring容器的环境配置信息对象
Environment getEnvironment();
//返回资源加载器
ResourceLoader getResourceLoader();
//返回类加载器
@Nullable
ClassLoader getClassLoader();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
@Conditional 使用的步骤
- 自定义一个类,实现 Condition 或 ConfigurationCondition 接口,实现 matches 方法
- 在目标对象上使用@Conditional 注解,并指定 value 的指为自定义的 Condition 类型
- 启动 spring 容器加载资源,此时@Conditional 就会起作用了
总结
@Conditional注解可以标注在 Spring 需要处理的对象上(配置类、@Bean 方法),相当于加了个条件判断,通过判断的结果,让 spring 觉得是否要继续处理被这个注解标注的对象Spring处理配置类大致有 2 个过程:解析配置类、注册 bean,这两个过程中都可以使用@Conditional 来进行控制 spring 是否需要处理这个过程Condition默认会对 2 个过程都有效ConfigurationCondition控制得更细一些,可以控制到具体那个阶段使用条件判断
# 5.什么是配置类?
类上面有如下注解时,标注的类就是配置类。
- @Configuration
- @Component
- @ComponentScan
- @Import
- @Bean
- @ImportResource
# 6.@Lookup("orderService")
@Lookup 用于单例组件引用 prototype 组件。单例组件使用@Autowired 方式注入 prototype 组件时,被引入 prototype 组件也会变成单例的。@Lookup 可以保证被引入的组件保持 prototype 模式。
@Bean 与@Lookup 不能一起使用的原因:
@Bean 和 @Lookup 是 Spring Framework 中用于配置和管理 Bean 的注解,它们有不同的用途和工作方式,因此不能直接一起使用。以下是原因:
作用不同:
@Bean注解通常用于在配置类中声明方法,这些方法负责创建和初始化 Bean 实例。Spring 容器会在启动时调用这些方法,将返回的对象注册为 Spring 容器中的 Bean。@Lookup注解用于标记抽象方法,这些方法应该在运行时由 Spring 容器生成具体的实现。使用@Lookup注解的目的是实现原型作用域的 Bean 获取,每次请求时都会返回一个新的实例。
生命周期差异:
@Bean方法在容器启动时就会被调用,创建 Bean 实例并注册到容器中,其生命周期与容器生命周期紧密相连。@Lookup方法在运行时被动态实现,每次调用方法时都会创建一个新的 Bean 实例,其生命周期与调用方法的作用域相关。
由于 @Bean 和 @Lookup 的用途和生命周期不同,将它们一起使用可能会导致不明确的行为和冲突。如果你需要通过 @Lookup 获取原型作用域的 Bean,你应该避免在 @Lookup 方法上同时使用 @Bean 注解,而是将 @Lookup 方法放在专门的抽象类或接口中,然后由 Spring 动态生成实现类。
例子:
import org.springframework.beans.factory.annotation.Lookup;
import org.springframework.stereotype.Component;
@Component
public abstract class PrototypeBeanContainer {
@Lookup
public abstract PrototypeBean createPrototypeBean();
}
@Component
public class PrototypeBeanContainerImpl extends PrototypeBeanContainer {
@Override
public PrototypeBean createPrototypeBean() {
return new PrototypeBean();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
在上面的例子中,PrototypeBeanContainer 是一个抽象类,其中的 createPrototypeBean() 方法使用了 @Lookup 注解。PrototypeBeanContainerImpl 是其子类,实现了具体的 createPrototypeBean() 方法。这样,在运行时,Spring 会动态生成 PrototypeBeanContainerImpl 的代理类,实现了原型作用域的 Bean 获取。同时,不需要使用 @Bean 注解。
# 7.ScopedProxyMode 原理
@Target({ElementType.TYPE, ElementType.METHOD})
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface Scope {
@AliasFor("scopeName")
String value() default "";
@AliasFor("value")
String scopeName() default "";
ScopedProxyMode proxyMode() default ScopedProxyMode.DEFAULT;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
ScopedProxyMode 是一个枚举类,该类共定义了四个枚举值,分别为 NO、DEFAULT、INTERFACE、TARGET_CLASS,其中 DEFAULT 和 NO 的作用是一样的。INTERFACES 代表要使用 JDK 的动态代理来创建代理对象,TARGET_CLASS 代表要使用 CGLIB 来创建代理对象。
# 8.BeanFactoryPostProcessor
BeanFactoryPostProcessor 是 Spring 框架中的一个扩展接口,用于在 Spring 容器实例化 Bean 之前对 BeanFactory 进行自定义修改。通过实现这个接口,你可以在 Spring 容器加载 Bean 定义但尚未实例化 Bean 之前,对 Bean 的定义进行修改、添加或替换。
BeanFactoryPostProcessor 接口有一个方法:
void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) throws BeansException;
在这个方法中,你可以访问到 ConfigurableListableBeanFactory,它是 Spring Bean 工厂的一个子接口,提供了修改 Bean 定义的能力。通过实现该接口,你可以执行以下操作:
修改 Bean 定义: 可以在这个方法中通过获取
BeanDefinition对象,修改 Bean 的配置属性,如修改属性值、作用域、构造函数参数等。添加 Bean 定义: 可以通过调用
registerBeanDefinition()方法,向容器中动态地注册新的 Bean 定义。移除 Bean 定义: 可以通过调用
removeBeanDefinition()方法,从容器中移除不需要的 Bean 定义。对属性占位符进行解析: 可以在这个方法中对属性占位符(
${...})进行解析,替换成实际的属性值。执行其他自定义逻辑: 可以执行一些自定义逻辑,例如动态生成 Bean 的名称、初始化配置信息等。
使用 BeanFactoryPostProcessor 时需要注意以下几点:
BeanFactoryPostProcessor的实现类在 Spring 容器启动时会被自动调用,所以它的操作在 Bean 实例化之前执行。- 实现类需要被注册到 Spring 容器中,可以通过 XML 配置或
@Component注解进行注册。 - 由于
BeanFactoryPostProcessor的操作是在 Spring 容器启动过程中执行的,所以它适合用于一些全局性的配置和处理,而不是针对具体 Bean 的个性化处理。
常见的使用场景包括:
- 解析属性占位符,替换成实际的属性值。
- 动态地注册 Bean 定义,例如基于条件注册不同的 Bean。
- 修改默认的 Bean 定义,如设置属性默认值、作用域等。
- 执行一些全局性的初始化和配置。
BeanFactoryPostProcessor 提供了在 Spring 容器启动过程中对 BeanFactory 进行自定义修改的能力,为应用程序的灵活性和可扩展性提供了支持。
# 9.@PostConstruct
@Documented
@Retention (RUNTIME)
@Target(METHOD)
public @interface PostConstruct {
}
2
3
4
5
@PostConstruct和@PreDestroy,这两个注解被用来修饰一个非静态的 void 方法。
@PostConstruct注解的方法在项目启动的时候执行这个方法,也可以理解为在 Spring 容器启动的时候执行,可作为一些数据的常规化加载,比如数据字典之类的。
其作用是在 bean 的初始化阶段,如果对一个方法标注了@PostConstruct,会先调用这个方法。
触发时机是在postProcessBeforeInitialization之后InitializingBean.afterPropertiesSet之前。
# 10.afterPropertiesSet
在 Spring 的 bean 的生命周期中,实例化 -> 生成对象 -> 属性填充后会进行 afterPropertiesSet 方法,这个方法可以用在一些特殊情况中,也就是某个对象的某个属性需要经过外界得到,比如说查询数据库等方式,这时候可以用到 spring 的该特性,只需要实现 InitializingBean 即可:
@Component("a")
public class A implements InitializingBean {
private B b;
public A(B b) {
this.b = b;
}
@Override
public void afterPropertiesSet() throws Exception {
}
}
2
3
4
5
6
7
8
9
10
11
12
13
# 11.@ConditionalOnProperty
@ConditionalOnProperty(prefix = "file", value = "model", havingValue = "local", matchIfMissing = true)
在 spring boot 中有时候需要控制配置类是否生效,可以使用@ConditionalOnProperty 注解来控制@Configuration 是否生效.
@Configuration
@ConditionalOnProperty(prefix = "filter",name = "loginFilter",havingValue = "true")
public class FilterConfig {
//prefix为配置文件中的前缀,
//name为配置的名字
//havingValue是与配置的值对比值,当两个值相同返回true,配置类生效.
@Bean
public FilterRegistrationBean getFilterRegistration() {
FilterRegistrationBean filterRegistration = new FilterRegistrationBean(new LoginFilter());
filterRegistration.addUrlPatterns("/*");
return filterRegistration;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
总结:
通过@ConditionalOnProperty 控制配置类是否生效,可以将配置与代码进行分离,实现了更好的控制配置.
@ConditionalOnProperty 实现是通过 havingValue 与配置文件中的值对比,返回为 true 则配置类生效,反之失效.
@ConditionalOnProperty 注解结合@Configuration 使用来控制配置类是否生效
@Configuration
@ConditionalOnProperty(prefix = "filter",name = "loginFilter",havingValue = "true")
public class FilterConfig {
//prefix为配置文件中的前缀,
//name为配置的名字
//havingValue是与配置的值对比值,当两个值相同返回true,配置类生效.
@Bean
public FilterRegistrationBean getFilterRegistration() {
FilterRegistrationBean filterRegistration = new FilterRegistrationBean(new LoginFilter());
filterRegistration.addUrlPatterns("/*");
return filterRegistration;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
配置文件中的代码:
filter.loginFilter=true
总结:通过@ConditionalOnProperty 控制配置类是否生效,可以将配置与代码进行分离,实现了更好的控制配置.
@ConditionalOnProperty 实现是通过 havingValue 与配置文件中的值对比,返回为 true 则配置类生效,反之失效.
# 12.@Configuration
- 底层代码就两个属性,一个用于声明配置类的名称,一个用于声明是否是代理对象方法(重点)。
- 由于有@Component 注解的加持,那么被声明的配置类本身也是一个组件!
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Component
public @interface Configuration {
@AliasFor(annotation = Component.class)
String value() default "";
boolean proxyBeanMethods() default true;
}
2
3
4
5
6
7
8
9
10
11
基础使用
@Configuration 注解常常一起搭配使用的注解有@Bean、@Scope、@Lazy 三个比较常见:
@Bean:等价于 Spring 中的 bean 标签用于注册 bean 对象的,内部有一些初始化、销毁的属性@Scope:用于声明该 bean 的作用域,作用域有 singleton、prototype、request、session、global-session。@Lazy:标记该 bean 是否开启懒加载。
# 13.proxyBeanMethods
@EnableConfigurationProperties 注解的 proxyBeanMethods 参数是 Spring Boot 特定的配置属性,用于控制是否启用代理模式来处理 @ConfigurationProperties 注解的配置类方法。这个参数的默认值是 true。
在 Spring Boot 中,@ConfigurationProperties 注解通常用于将属性绑定到配置类的方法,从而实现属性的类型安全绑定。当使用 @EnableConfigurationProperties 注解启用配置属性绑定时,Spring Boot 会创建一个代理以管理被注解的配置类的实例。
这个参数的含义是:
- 当
proxyBeanMethods设置为true时(默认情况),Spring Boot 会使用 CGLIB 代理机制为配置属性的绑定方法生成代理。这样,每次调用绑定方法时,都会返回同一个代理实例,从而实现属性的缓存和复用。 - 当
proxyBeanMethods设置为false时,Spring Boot 将不会为配置属性的绑定方法生成代理。每次调用绑定方法时,都会创建一个新的实例。
选择是否启用代理模式取决于你的应用程序需求:
- 当你的配置属性绑定方法不需要在不同组件之间共享状态时,可以将
proxyBeanMethods设置为false,以避免不必要的代理生成。 - 当你的配置属性绑定方法需要在不同组件之间共享状态或进行缓存时,保持默认的
proxyBeanMethods设置为true。
举例来说,假设你有一个配置类 MyProperties:
@ConfigurationProperties("myapp")
public class MyProperties {
// ...
}
2
3
4
如果 proxyBeanMethods 设置为 true,那么在使用 @EnableConfigurationProperties(MyProperties.class) 注解时,Spring Boot 会为 MyProperties 生成一个代理,使得多个组件共享同一个实例。如果设置为 false,则每个组件将获得独立的实例。
示例用法:
@Configuration
@EnableConfigurationProperties(MyProperties.class)
public class MyConfiguration {
// ...
}
2
3
4
5
proxyBeanMethods 参数影响了 Spring Boot 在启用配置属性绑定时生成代理的行为,它允许你根据应用程序的需求来控制代理模式的使用。
# 14.@Scope 注解
@Scope 生效的地方是在 bean 加载的时候,调用 AbstractBeanFactory#doGetBean() 时生效的。
@Scope的值不止这两种,还包括了 request、session 等。但用的最多的还是 singleton 单态与 prototype 多态。
<bean id="testManager" class="com.sw.TestManagerImpl" scope="singleton" />
<bean id="testManager" class="com.sw.TestManagerImpl" scope="prototype" />
2
scope=singleton是单独的处理逻辑,产生的 bean 会放入一级缓存scope=prototype是单独的处理逻辑,产生的 bean 不会放入缓存
其他 scope 是另一套单独的处理逻辑,而且它使用了 prototype 的方式在处理,产生的 bean 不会放入缓存。
# 15.@ControllerAdvice
@ControllerAdvice 是一个用于处理 Spring MVC 应用程序中全局异常处理和全局数据绑定的注解。它通常用于在多个控制器中共享相同的异常处理逻辑或数据绑定逻辑。使用 @ControllerAdvice 注解,您可以创建一个全局的异常处理类,以集中处理不同控制器中的异常,从而提高代码的复用性和可维护性。
以下是如何使用 @ControllerAdvice 的一般步骤:
创建一个类并添加
@ControllerAdvice注解:@ControllerAdvice public class GlobalExceptionHandler { // 异常处理逻辑和其他全局操作 }1
2
3
4在该类中定义异常处理方法,可以使用
@ExceptionHandler注解来标识异常处理方法。这些方法将处理特定类型的异常,您可以根据需要处理不同的异常情况。@ExceptionHandler(Exception.class) public ResponseEntity<String> handleGlobalException(Exception ex) { // 处理异常逻辑,可以返回适当的响应 }1
2
3
4如果需要全局数据绑定,您可以使用
@ModelAttribute注解定义方法来提供全局数据,这些数据将在每个请求中都可用。@ModelAttribute("globalData") public Map<String, Object> globalData() { // 返回全局数据 }1
2
3
4您还可以使用其他注解来进一步自定义
@ControllerAdvice类的行为,例如@InitBinder用于配置数据绑定设置,或者@ResponseBody用于返回 JSON 格式的响应。在
@ControllerAdvice类中可以处理多种类型的异常,或者根据不同的控制器进行细分处理。最后,确保在 Spring 配置中启用了组件扫描,以便自动检测和加载
@ControllerAdvice类。
通过使用 @ControllerAdvice,您可以将全局异常处理和全局数据绑定逻辑集中管理,从而避免在每个控制器中重复编写相同的代码。这有助于提高代码的可读性和可维护性,并提供一种一致的方式来处理应用程序中的异常情况。
# 16.@Component 和@Bean
在 Spring 框架中,@Component 和 @Bean 都用于定义和配置 Bean,但它们有不同的使用场景和特点。
Spring 版本 5.0.7.RELEASE 和 5.1.2.RELEASE 之间的行为差异涉及到 Bean 定义的覆盖问题。
@Component:
@Component是 Spring 的一个通用注解,用于将类标记为 Spring 管理的组件,会由 Spring 自动扫描并将其实例化为 Bean。- 使用
@Component可以轻松地将普通的 Java 类转换为 Spring 管理的 Bean,适用于各种情况,无需显式指定 Bean 的创建方式和配置信息。
@Bean:
@Bean是用于配置方法级别的注解,用于告诉 Spring 容器在运行时调用标记的方法,以获取一个实例化的 Bean。- 使用
@Bean注解时,你需要在配置类中定义方法,并在方法内部创建 Bean 实例并返回。通过这种方式,你可以更精细地控制 Bean 的创建过程,甚至可以实现复杂的逻辑。
关于 Spring 5.0.7.RELEASE 和 5.1.2.RELEASE 之间的变化:
在 Spring 5.0.7.RELEASE 中,如果一个类同时标记有 @Component 和 @Configuration 注解,并且在 @Configuration 类中使用 @Bean 方法定义了同名的 Bean,那么默认情况下,@Component 标记的 Bean 会被 @Bean 标记的 Bean 覆盖。
然而,在 Spring 5.1.2.RELEASE 中,引入了 allowBeanDefinitionOverriding 配置项,这样的配置项允许开发者自己决定是否允许 Bean 定义的覆盖。这个配置项的引入是为了更好地控制 Bean 的定义和覆盖行为。
开发者可以在 Spring 配置中进行如下设置,以决定是否允许 Bean 定义的覆盖:
<bean class="org.springframework.context.annotation.ConfigurationClassPostProcessor">
<property name="allowBeanDefinitionOverriding" value="false"/>
</bean>
2
3
或者在 Java 配置类中使用:
@Bean
public static ConfigurationClassPostProcessor configurationClassPostProcessor() {
ConfigurationClassPostProcessor postProcessor = new ConfigurationClassPostProcessor();
postProcessor.setAllowBeanDefinitionOverriding(false);
return postProcessor;
}
2
3
4
5
6
@Component 和 @Bean 都是定义和配置 Spring Bean 的方式,但在特定情况下可能会出现 Bean 定义的覆盖问题,而 Spring 5.1.2.RELEASE 引入的 allowBeanDefinitionOverriding 配置项允许开发者控制这种覆盖行为。
# 17.bf 和 fb 的区别?
在 Spring 框架中,BeanFactory 和 FactoryBean 都涉及到 Bean 的创建和管理,但它们有不同的作用和使用方式。
BeanFactory:
BeanFactory 是 Spring 框架的核心接口之一,用于管理和维护应用程序中的 Bean 实例。它是 Spring IoC(控制反转)容器的基础,负责实例化、配置和管理 Bean 对象。BeanFactory 定义了获取和管理 Bean 的核心方法,包括:
getBean(String name): 根据名称获取指定的 Bean 实例。getBean(Class<T> requiredType): 根据类型获取指定的 Bean 实例。containsBean(String name): 判断是否包含指定名称的 Bean。isSingleton(String name): 判断指定名称的 Bean 是否是单例。- 等等...
常见的 BeanFactory 实现包括 DefaultListableBeanFactory 和 XmlBeanFactory,其中 DefaultListableBeanFactory 是最常用的实现之一。
FactoryBean:
FactoryBean 是 Spring 框架中的另一个接口,用于自定义 Bean 的创建和实例化过程。通过实现 FactoryBean 接口,你可以定义自己的工厂类,用于创建特定类型的 Bean 对象。FactoryBean 接口定义了以下方法:
T getObject() throws Exception: 创建并返回一个特定类型的 Bean 实例。Class<T> getObjectType(): 返回工厂所创建的 Bean 的类型。boolean isSingleton(): 返回工厂创建的 Bean 是否为单例。
通过实现 FactoryBean 接口,你可以实现自定义的实例化逻辑、配置属性,以及根据需要进行一些特殊处理。
例如,你可以创建一个实现了 FactoryBean 接口的类,用于返回自定义的数据源 Bean:
import org.springframework.beans.factory.FactoryBean;
public class DataSourceFactoryBean implements FactoryBean<DataSource> {
@Override
public DataSource getObject() throws Exception {
// 创建并返回自定义的 DataSource 实例
return new CustomDataSource();
}
@Override
public Class<DataSource> getObjectType() {
return DataSource.class;
}
@Override
public boolean isSingleton() {
return true; // 返回 true 表示该 Bean 是单例
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
在配置文件中,你可以使用 & 前缀来获取 FactoryBean 对象,以及正常的 Bean 对象。例如:
<bean id="dataSourceFactory" class="com.example.DataSourceFactoryBean"/>
<bean id="customDataSource" factory-bean="dataSourceFactory" factory-method="getObject"/>
2
BeanFactory 是 Spring 框架中用于管理 Bean 的核心接口,而 FactoryBean 则是一个接口,允许你实现自定义的 Bean 工厂,用于创建特定类型的 Bean 实例。
# 八.Spring 其他特性
# 1.什么是响应式
目的,响应式编程的目是帮助应用在不同的环境条件和负载下仍保持响应性。
响应式系统需要具备这些特征:
- 及时响应性(Responsive)
- 恢复性(Resilient)
- 有弹性(Elastic)以及
- 消息驱动(Message Driven)
我们把具有上面四个特性的系统就叫做响应式系统。
上面的四个特性中,及时响应性(Responsive)是系统最终要达到的目标,恢复性(Resilient)和有弹性(Elastic)是系统的表现形式,而消息驱动(Message Driven)则是系统构建的手段。
# 2.Webflux 核心与原理
Spring5添加的新模块,用于 web 开发的,功能SpringMvc类似,Webflux使用当前流行的响应式编程出现的框架。- 传统的 web 框架,比如 SpringMVC,这些都是基于 Servlet 容器来实现的,
Webflux是一种异步非阻塞的框架,异步非阻塞的框架在 Servlet3.1 以后才支持,核心是基于Reactor的相关 API 实现的,但是同时它也支持Servlet。 什么是异步:同步异步其实就是针对的是调用者,你在吃饭,然后准备去打球,要给辅导员请假,同步就是你必须等到它同意,而且异步就是可以说了就去打球了,其他的不管。什么是非阻塞:是针对对象的,A 是调用者,B 是被调用者,B 得到一个被调用,直接给他反馈,这就是非阻塞,不反馈就是阻塞。WebFlux 的优势:第一步非阻塞(有限的资源下可以提高吞吐量和伸缩性,以 Reactor 实现的响应式编程),Spring5 框架基于 Java8,WebFlux 使用 Java8 函数式编程方式实现路由请求。
# 3.SpringWebFlux
Mono 和 Flux 是 SpringWebFlux 用来处理响应式工作流的核心 api。
Mono表示 0 或 1 个元素Flux表示 0 至 N 个元素新的
spring-webflux模块,一个基于reactive的 spring-webmvc,完全的异步非阻塞,旨在使用event-loop执行模型和传统的线程池模型。Reactive说明在Spring-Core比如编码和解码Spring-Core相关的基础设施,比如Encode和Decoder可以用来编码和解码数据流;DataBuffer可以使用 java ByteBuffer 或者 Netty ByteBuf;ReactiveAdapterRegistry 可以对相关的库提供传输层支持。在 Spring-web 包里包含 HttpMessageReade 和 HttpMessageWrite
# 4.SpringWebflux 处理器
WebSpringFlux 基于 Reactor 默认容器为 Netty, Netty 是高性能的 NIO 框架,异步非阻塞框架。
SpringWebflux 核心控制器 DispatchHandler,实现接口 WebHandler。
HandlerMapping:请求查询到处理的方法
HandlerAdapter:真正负责请求处理HandlerResultHandler:响应结果处理
SpringWebflux 实现函数式编程 :
两个接口 :
RouterFunction(路由处理)HandlerFunction(函数处理)
# 5.SpringMVC 和 SpringWebFlux?

# 6.存在 2 个 bean 名称相同?
xml方式:如果是xml的形式获取bean,则会直接报错,xml不允许定义 2 个名称相同的 bean。注解方式:如果是注解的方式,不会报错,但是第二个bean不会继续创建,单例bean里面的多例bean只会有一个值
# 7.什么是 Aot?
JIT(Just-in-Time,实时编译)一直是 Java 语言的灵魂特性之一,与之相对的 AOT(Ahead-of-Time,预编译)方式,似乎长久以来和 Java 语言都没有什么太大的关系。但是近年来随着 Serverless、云原生等概念和技术的火爆,Java JVM 和 JIT 的性能问题越来越多地被诟病,使用 Aot 可以很大程度上提高编译速度,jar 启动更快.
AOT 的优点
在程序运行前编译,可以避免在运行时的编译性能消耗和内存消耗
可以在程序运行初期就达到最高性能,程序启动速度快
运行产物只有机器码,打包体积小
AOT 的缺点
- 由于是静态提前编译,不能根据硬件情况或程序运行情况择优选择机器指令序列,理论峰值性能不如 JIT
- 没有动态能力
- 同一份产物不能跨平台运行
# 8.Spring Security
Spring Security 实现多重角色鉴权,URL 级别权限管理
基于 RBAC,五表
RBAC 是基于角色访问控制
五表 user user_role role role_resource resource
资源表就是存储 url
# 9.什么是 ASM 技术?
ASM 是一个 Java 字节码操控框架。它能被用来动态生成类或者增强既有类的功能。ASM 可以直接产生二进制 class 文件,也可以在类被加载入 Java 虚拟机之前动态改变类行为。Java class 被存储在严格格式定义的 .class 文件里,这些类文件拥有足够的元数据来解析类中的所有元素:类名称、方法、属性以及 Java 字节码(指令)。ASM 从类文件中读入信息后,能够改变类行为,分析类信息,甚至能够根据用户要求生成新类。
ASM 能够通过改造既有类,直接生成需要的代码。增强的代码是硬编码在新生成的类文件内部的,没有反射带来性能上的付出。同时,ASM 与 Proxy 编程不同,不需要为增强代码而新定义一个接口,生成的代码可以覆盖原来的类,或者是原始类的子类。它是一个普通的 Java 类而不是 proxy 类,甚至可以在应用程序的类框架中拥有自己的位置,派生自己的子类。
相比于其他流行的 Java 字节码操纵工具,ASM 更小更快。ASM 具有类似于 BCEL 或者 SERP 的功能,而只有 33k 大小,而后者分别有 350k 和 150k。同时,同样类转换的负载,如果 ASM 是 60% 的话,BCEL 需要 700%,而 SERP 需要 1100% 或者更多。
# 10.ApplicationEvent
public abstract class ApplicationEvent extends EventObject {
private static final long serialVersionUID = 7099057708183571937L;
private final long timestamp = System.currentTimeMillis();
public ApplicationEvent(Object source) {
super(source);
}
public final long getTimestamp() {
return this.timestamp;
}
}
2
3
4
5
6
7
8
9
10
11
12
类的注释是,被应用事件继承的类,抽象的不能初始化;
作用
- 事件携带一个 Objecgt 对象,可以被发布;
- 事件监听者,监听到这个事件后,触发自定义逻辑 ( 操作 Object 对象)
- 发布事件的时候,不仅会被 MyEventListener 监听,其他只要监听了 MyApplicationEvent 的监听器 都会收到事件
定义事件
public class MyApplicationEvent extends ApplicationEvent {
public MyApplicationEvent(Object source) {
super(source);
System.out.println("MyApplicationEvent create");
}
}
2
3
4
5
6
7
定义时间监听器
public class MyEventListener implements ApplicationListener<MyApplicationEvent> {
@Override
public void onApplicationEvent(MyApplicationEvent myApplicationEvent) {
int[] source = (int[]) myApplicationEvent.getSource();
System.out.println(Arrays.toString(source));
}
}
2
3
4
5
6
7
发布事件
@SpringBootApplication
public class AntServiceApplication {
public static void main(String[] args) {
//启动SpringBoot 并拿到配置信息
ConfigurableApplicationContext context =
SpringApplication.run(AntServiceApplication.class, args);
JdbcTemplate jdbcTemplate = context.getBean(JdbcTemplate.class);
List<Map<String, Object>> result = jdbcTemplate.queryForList("SELECT * FROM t_class_table");
// jdbcTemplate.execute();
System.out.println(result);
// 启动SpringBoot
ConfigurableApplicationContext run = SpringApplication.run(AntServiceApplication.class, args);
int[] array = {1, 2, 3, 4};
run.publishEvent(new MyApplicationEvent(array))
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 11.ApplicationContext 延迟加载?
两种方式:
- bean 元素配置
lazy-init=true - beans 元素中配置
default-lazy-init=true让这个 beans 中的所有 bean 延迟实例化
# 12.有状态的 bean 与无状态的 bean
有状态 bean:每个用户有自己特有的一个实例,在用户的生存期内,bean 保存了用户的信息,即有状态;一旦用户灭亡(调用结束或实例结束),bean 的生命期也告结束。即每个用户最初都会得到一个初始的 bean。
无状态 bean:bean 一旦实例化就被加进会话池中,各个用户都可以共用。即使用户已经消亡,bean 的生命期也不一定结束,它可能依然存在于会话池中,供其他用户调用。由于没有特定的用户,那么也就不能保持某一用户的状态,所以叫无状态 bean。但无状态会话 bean 并非没有状态,如果它有自己的属性(变量)。
有状态就是有数据存储功能。有状态对象(Stateful Bean),就是有实例变量的对象 ,可以保存数据,是非线程安全的。在不同方法调用间不保留任何状态。
无状态就是一次操作不能保存数据。无状态对象(Stateless Bean),就是没有实例变量的对象 ,不能保存数据是不变类,是线程安全的。
# 13.如何保证线程安全?
Spring 的单例不是线程安全的话,那它怎么保证线程安全的呢?
将有状态的 bean 配置成 singleton 会造成资源混乱问题(线程安全问题),而如果是 prototype 的话,就不会出现资源共享的问题,即不会出现线程安全的问题。
如果你的代码所在的进程中有多个线程在同时运行,而这些线程可能会同时运行这段代码。如果每次运行结果和单线程运行的结果是一样的,而且其他的变量的值也和预期的是一样的,那么代码就是线程安全的。
无状态的 Bean 适合用不变模式,使用的技术就是单例模式,这样可以共享实例,提高性能。有状态的 Bean,多线程环境下不安全,那么适合用 Prototype 原型模式(解决多线程问题),每次对 bean 的请求都会创建一个新的 bean 实例。
bean 只会实例化一次,无状态 Bean 共享,Spring 是用了 threadlocal 来解决了这个问题。
ThreadLocal 的机制:
- 每个 Thread 线程内部都有一个 Map。
- Map 里面存储线程本地对象(key)和线程的变量副本(value)
- 但是,Thread 内部的 Map 是由 ThreadLocal 维护的,由 ThreadLocal 负责向 map 获取和设置线程的变量值。
- 所以对于不同的线程,每次获取副本值时,别的线程并不能获取到当前线程的副本值,形成了副本的隔离,互不干扰。
- 每个线程中都有一个自己的 ThreadLocalMap 类对象,可以将线程自己的对象保持到其中,各管各的,线程可以正确的访问到自己的对象。
- 将一个共用的 ThreadLocal 静态实例作为 key,将不同对象的引用保存到不同线程的 ThreadLocalMap 中,然后在线程执行的各处通过这个静态 ThreadLocal 实例的 get()方法取得自己线程保存的那个对象,避免了将这个对象作为参数传递的麻烦。