
# 六.堆
# 1.堆的定义
heapq 库中的堆默认是最小堆,python 的 heapq 模块提供了对堆的支持
# 2.添加元素
heapq.heappush(heap, item) #往堆添加元素
# 3.列表转换为堆
heapq.heapify(list) #将列表转换为堆
# 4.删除最小值
heapq.heappop(heap) #删除并返回最小值 heap[0]永远是最小的元素
# 5.添加新的元素值
heapq.heapreplace(heap.item) #删除并返回最小元素值,添加新的元素值
# 6.添加比较
# 判断添加元素值与堆的第一个元素值对比;
# 如果大,则删除并返回第一个元素,然后添加新元素值item. 如果小,则返回item. 原堆不变。
heapq.heappushpop(list, item)
2
3
# 7.合并堆
heapq.merge(…) #将多个堆合并
# 8.最大 n 个
heapq.nlargest(n,heap) #查询堆中的最大n个元素
2
# 9.最小 n 个
heapq.nsmallest(n,heap) #查询堆中的最小n个元素
# 10.定义大顶堆
//默认小顶堆,改为大顶堆
heap = [-stone for stone in stones] #相当于数字取反,最后取出的时候要注意转换
heapq.heapify(heap)
2
3
# 11.判断堆
if heap: return -heap[0] #判断堆
# 七.json
# 1.dumps 函数
字典转 json 字符串
# 准备列表,列表内每一个元素都是字典,将其转换为JSON
data = [{"name": "张大山", "age": 11}, {"name": "王大锤", "age": 13}, {"name": "赵小虎", "age": 16}]
json_str = json.dumps(data, ensure_ascii=False)
print(type(json_str))
print(json_str)
# 准备字典,将字典转换为JSON
d = {"name": "周杰轮", "addr": "台北"}
json_str = json.dumps(d, ensure_ascii=False)
print(type(json_str))
print(json_str)
2
3
4
5
6
7
8
9
10
11
# 2.loads
字符串转字典
# 将JSON字符串转换为Python数据类型[{k: v, k: v}, {k: v, k: v}]
s = '[{"name": "张大山", "age": 11}, {"name": "王大锤", "age": 13}, {"name": "赵小虎", "age": 16}]'
l = json.loads(s)
print(type(l))
print(l)
# 将JSON字符串转换为Python数据类型{k: v, k: v}
s = '{"name": "周杰轮", "addr": "台北"}'
d = json.loads(s)
print(type(d))
print(d)
2
3
4
5
6
7
8
9
10
# 八.工具包
# 1.numpy
import numpy as np
class Solution:
def matrixSum(self, nums: List[List[int]]) -> int:
for i in nums:
i[:] = sorted(i)
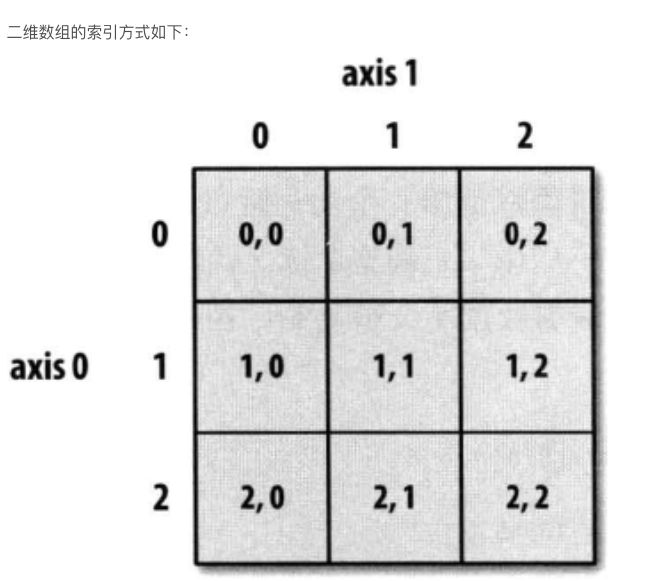
return int(sum(np.max(np.array(nums), axis=0)))
2
3
4
5
6
7
# 2.三元运算符
numOnes - (k - numOnes + numZeros) if k > (numOnes + numZeros) else
在 Python 中,三元运算符是一种用于简化条件表达式的语法结构。它的语法形式如下:
<表达式1> if <条件表达式> else <表达式2>
\其中,条件表达式是一个返回布尔值的表达式,如果条件表达式的值为 True,则返回表达式 1 的值;如果条件表达式的值为 False,则返回表达式 2 的值。
以下是一个使用三元运算符的示例:
x = 5
y = 10
max_value = x if x > y else y
print(max_value) # 输出10
2
3
4
5
在上述示例中,如果 x 大于 y,则 max_value 的值为 x 的值;否则 max_value 的值为 y 的值。
# 3.inf
在 Python 中,inf是一个特殊的浮点数常量,表示正无穷大。它是float类型的一个值,表示比任何实数都大的数。inf可以用于进行数值计算,例如与其他数进行比较、相加或相乘。
下面是一些示例演示如何在 Python 中使用inf:
# 比较
print(10 < float('inf')) # True
print(float('inf') == float('inf')) # True
# 运算
print(1000 + float('inf')) # inf
print(2 * float('inf')) # inf
# 其他操作
print(1 / float('inf')) # 0.0
print(float('inf') + float('-inf')) # nan(不是一个数字)
2
3
4
5
6
7
8
9
10
11
需要注意的是,inf是一个特殊的浮点数值,它不是整数或布尔类型。在进行比较时,inf可以与其他数进行比较,但要小心避免产生意想不到的结果。此外,与inf相关的计算可能会得到inf、-inf或nan(不是一个数字)等结果,这也需要根据具体情况进行处理。
# 4.@cache
在 Python 中,@cache 是一个装饰器函数,用于缓存函数或方法的结果。当将 @cache 应用于方法时,它将缓存方法的返回值,以避免重复计算。这可以提高方法的性能,特别是当方法的计算成本较高或需要频繁调用时。
使用 @cache 装饰器可以有效地在方法中实现缓存机制,以便在相同的输入参数下重复调用方法时,直接返回之前缓存的结果,而不必重新执行方法体内的计算过程。
以下是一个示例,展示了如何使用 @cache 装饰器来缓存方法的结果:
from functools import cache
class MyClass:
@cache
def expensive_method(self, arg1, arg2):
# 执行耗时操作
# ...
# 返回计算结果
return result
2
3
4
5
6
7
8
9
在上述示例中,expensive_method 方法被 @cache 装饰器修饰。当第一次调用 expensive_method 方法时,会执行方法体内的计算过程,并将结果缓存起来。以后每次调用相同的参数调用该方法时,将直接从缓存中获取结果,而不再执行耗时的计算过程。
需要注意的是,@cache 装饰器是在 Python 3.9 中引入的。如果你使用的是较早版本的 Python,你可以使用 functools.lru_cache 装饰器来实现类似的功能。
# 5.平方运算
# next_x的平方
max_result = max(max_result, next_x ** 2 + next_y ** 2)
2
# 6.位移运算
通过>>进行位移运算
class Solution:
def distributeCoins(self, nums: List[int], target: int) -> int:
"""
二分查找基础版
:param nums:
:param target:
:return:
"""
left, right = 0, len(nums) - 1
while left <= right:
mid = (left + right) >> 1
if nums[mid] > target:
right = mid - 1
elif nums[mid] < target:
left = mid + 1
else:
return mid
return -1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 7.二的 n 次方
在 Python 中,可以使用 ** 运算符来计算 2 的 n 次方,其中 n 是一个整数。
# 计算 2 的 3 次方
result = 2 ** 3
print(result) # 输出 8
# 计算 2 的 10 次方
result = 2 ** 10
print(result) # 输出 1024
# 计算 2 的 n 次方,其中 n 是一个变量
n = 5
result = 2 ** n
print(result) # 输出 32
2
3
4
5
6
7
8
9
10
11
12
# 九.总结对比
# 1.数据容器对比

# 2.len 函数
my_list = [1, 2, 3, 4, 5]
my_tuple = (1, 2, 3, 4, 5)
my_str = "abcdefg"
my_set = {1, 2, 3, 4, 5}
my_dict = {"key1": 1, "key2": 2, "key3": 3, "key4": 4, "key5": 5}
# len元素个数
print(f"列表 元素个数有:{len(my_list)}")
print(f"元组 元素个数有:{len(my_tuple)}")
print(f"字符串元素个数有:{len(my_str)}")
print(f"集合 元素个数有:{len(my_set)}")
print(f"字典 元素个数有:{len(my_dict)}")
2
3
4
5
6
7
8
9
10
11
12
# 3.max 函数
my_list = [1, 2, 3, 4, 5]
my_tuple = (1, 2, 3, 4, 5)
my_str = "abcdefg"
my_set = {1, 2, 3, 4, 5}
my_dict = {"key1": 1, "key2": 2, "key3": 3, "key4": 4, "key5": 5}
# max最大元素
print(f"列表 最大的元素是:{max(my_list)}")
print(f"元组 最大的元素是:{max(my_tuple)}")
print(f"字符串最大的元素是:{max(my_str)}")
print(f"集合 最大的元素是:{max(my_set)}")
print(f"字典 最大的元素是:{max(my_dict)}")
2
3
4
5
6
7
8
9
10
11
# 4.min 函数
my_list = [1, 2, 3, 4, 5]
my_tuple = (1, 2, 3, 4, 5)
my_str = "abcdefg"
my_set = {1, 2, 3, 4, 5}
my_dict = {"key1": 1, "key2": 2, "key3": 3, "key4": 4, "key5": 5}
# min最小元素
print(f"列表 最小的元素是:{min(my_list)}")
print(f"元组 最小的元素是:{min(my_tuple)}")
print(f"字符串最小的元素是:{min(my_str)}")
print(f"集合 最小的元素是:{min(my_set)}")
print(f"字典 最小的元素是:{min(my_dict)}")
2
3
4
5
6
7
8
9
10
11
# 5.list 函数
my_list = [1, 2, 3, 4, 5]
my_tuple = (1, 2, 3, 4, 5)
my_str = "abcdefg"
my_set = {1, 2, 3, 4, 5}
my_dict = {"key1": 1, "key2": 2, "key3": 3, "key4": 4, "key5": 5}
# 类型转换: 容器转列表
print(f"列表转列表的结果是:{list(my_list)}")
print(f"元组转列表的结果是:{list(my_tuple)}")
print(f"字符串转列表结果是:{list(my_str)}")
print(f"集合转列表的结果是:{list(my_set)}")
print(f"字典转列表的结果是:{list(my_dict)}")
2
3
4
5
6
7
8
9
10
11
12
# 6.tuple 函数
my_list = [1, 2, 3, 4, 5]
my_tuple = (1, 2, 3, 4, 5)
my_str = "abcdefg"
my_set = {1, 2, 3, 4, 5}
my_dict = {"key1": 1, "key2": 2, "key3": 3, "key4": 4, "key5": 5}
# 类型转换: 容器转元组
print(f"列表转元组的结果是:{tuple(my_list)}")
print(f"元组转元组的结果是:{tuple(my_tuple)}")
print(f"字符串转元组结果是:{tuple(my_str)}")
print(f"集合转元组的结果是:{tuple(my_set)}")
print(f"字典转元组的结果是:{tuple(my_dict)}")
2
3
4
5
6
7
8
9
10
11
# 7.str 函数
my_list = [1, 2, 3, 4, 5]
my_tuple = (1, 2, 3, 4, 5)
my_str = "abcdefg"
my_set = {1, 2, 3, 4, 5}
my_dict = {"key1": 1, "key2": 2, "key3": 3, "key4": 4, "key5": 5}
# 类型转换: 容器转字符串
print(f"列表转字符串的结果是:{str(my_list)}")
print(f"元组转字符串的结果是:{str(my_tuple)}")
print(f"字符串转字符串结果是:{str(my_str)}")
print(f"集合转字符串的结果是:{str(my_set)}")
print(f"字典转字符串的结果是:{str(my_dict)}")
2
3
4
5
6
7
8
9
10
11
# 8.set 函数
my_list = [1, 2, 3, 4, 5]
my_tuple = (1, 2, 3, 4, 5)
my_str = "abcdefg"
my_set = {1, 2, 3, 4, 5}
my_dict = {"key1": 1, "key2": 2, "key3": 3, "key4": 4, "key5": 5}
# 类型转换: 容器转集合
print(f"列表转集合的结果是:{set(my_list)}")
print(f"元组转集合的结果是:{set(my_tuple)}")
print(f"字符串转集合结果是:{set(my_str)}")
print(f"集合转集合的结果是:{set(my_set)}")
print(f"字典转集合的结果是:{set(my_dict)}")
2
3
4
5
6
7
8
9
10
11
# 9.排序
my_list = [1, 2, 3, 4, 5]
my_tuple = (1, 2, 3, 4, 5)
my_str = "abcdefg"
my_set = {1, 2, 3, 4, 5}
my_dict = {"key1": 1, "key2": 2, "key3": 3, "key4": 4, "key5": 5}
# 进行容器的排序
my_list = [3, 1, 2, 5, 4]
my_tuple = (3, 1, 2, 5, 4)
my_str = "bdcefga"
my_set = {3, 1, 2, 5, 4}
my_dict = {"key3": 1, "key1": 2, "key2": 3, "key5": 4, "key4": 5}
print(f"列表对象的排序结果:{sorted(my_list)}")
print(f"元组对象的排序结果:{sorted(my_tuple)}")
print(f"字符串对象的排序结果:{sorted(my_str)}")
print(f"集合对象的排序结果:{sorted(my_set)}")
print(f"字典对象的排序结果:{sorted(my_dict)}")
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
基础排序
nums.sort()
切片
for i in nums:
i[:] = sorted(i)
2
基于指定值排序
# 准备列表
my_list = [["a", 33], ["b", 55], ["c", 11]]
# 排序,基于带名函数
def choose_sort_key(element):
return element[1]
my_list.sort(key=choose_sort_key, reverse=True)
# 排序,基于lambda匿名函数
my_list.sort(key=lambda element: element[1], reverse=True)
print(my_list)
2
3
4
5
6
7
8
9
10
11
12
# 10.反序
my_list = [1, 2, 3, 4, 5]
my_tuple = (1, 2, 3, 4, 5)
my_str = "abcdefg"
my_set = {1, 2, 3, 4, 5}
my_dict = {"key1": 1, "key2": 2, "key3": 3, "key4": 4, "key5": 5}
# 进行容器的排序
my_list = [3, 1, 2, 5, 4]
my_tuple = (3, 1, 2, 5, 4)
my_str = "bdcefga"
my_set = {3, 1, 2, 5, 4}
my_dict = {"key3": 1, "key1": 2, "key2": 3, "key5": 4, "key4": 5}
print(f"列表对象的反向排序结果:{sorted(my_list, reverse=True)}")
print(f"元组对象的反向排序结果:{sorted(my_tuple, reverse=True)}")
print(f"字符串对象反向的排序结果:{sorted(my_str, reverse=True)}")
print(f"集合对象的反向排序结果:{sorted(my_set, reverse=True)}")
print(f"字典对象的反向排序结果:{sorted(my_dict, reverse=True)}")
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 11.总结
Python 中常用的容器包括以下几种:
列表(List):
- 特点: 可以容纳任何数据类型,可变(Mutable)。
- 示例:
my_list = [1, 'two', 3.0]
元组(Tuple):
- 特点: 不可变(Immutable),一旦创建就不能被修改。
- 示例:
my_tuple = (1, 'two', 3.0)
集合(Set):
- 特点: 无序,不重复的元素,用于去重和测试成员资格。
- 示例:
my_set = {1, 2, 3, 3}
字典(Dictionary):
- 特点: 由键值对组成,可变。
- 示例:
my_dict = {'key1': 'value1', 'key2': 2}
字符串(String):
- 特点: 一种不可变的序列类型,也可以被视为容器。
- 示例:
my_string = "Hello, World!"
这些容器在使用中有一些区别:
可变性: 列表和字典是可变的,这意味着你可以在创建后修改它们。而元组和字符串是不可变的,一旦创建就不能被修改。
有序性: 列表是有序的,元组也是有序的,但字典和集合是无序的。无序表示容器中的元素没有明确的位置或顺序。
唯一性: 集合中的元素是唯一的,而列表、元组、字典中的元素可以重复。
索引和键值对: 列表和元组通过索引访问元素,字典通过键值对访问元素。
可哈希性: 集合和字典的键必须是可哈希的,而列表和字典的值可以是不可哈希的。元组在其中的元素可哈希的情况下也是可哈希的。
# 2.Python 多线程的实现方式
Python 提供了几种实现多线程的方式:
使用
threading模块:这是 Python 标准库中用于多线程的模块。它允许开发者创建线程,并通过start()方法启动线程。以下是一个简单的示例,展示了如何使用threading模块创建和启动两个线程:import threading def print_numbers(): for i in range(1, 6): print(i) thread1 = threading.Thread(target=print_numbers) thread2 = threading.Thread(target=print_numbers) thread1.start() thread2.start() thread1.join() thread2.join()1
2
3
4
5
6
7
8
9
10
11
12
13
14使用
concurrent.futures模块:这个模块提供了一个高级的异步执行接口,可以创建和管理线程池或进程池。使用ThreadPoolExecutor可以创建一个线程池,并使用submit方法提交任务:from concurrent.futures import ThreadPoolExecutor def task(n): return n * n with ThreadPoolExecutor(max_workers=5) as executor: results = [executor.submit(task, i) for i in range(10)] for future in concurrent.futures.as_completed(results): print(future.result())1
2
3
4
5
6
7
8
9使用
multiprocessing模块:虽然这个模块主要用于创建多个进程,但它也可以用来创建线程。使用multiprocessing.dummy模块可以创建线程池,它实际上是concurrent.futures.ThreadPoolExecutor的一个别名:from multiprocessing import Pool def task(n): return n * n if __name__ == "__main__": with Pool(5) as p: print(p.map(task, range(10)))1
2
3
4
5
6
7
8使用第三方库:有些第三方库如
gevent或eventlet提供了更高级的多线程功能,它们使用协程来实现并发,可以绕过 GIL 的限制。
# 3.多线程的应用场景
多线程在 Python 中有着广泛的应用场景,尤其是在以下方面:
- I/O 密集型任务:当程序主要受限于 I/O 操作,如文件读写、网络通信等,多线程可以显著提高程序的效率,因为线程可以在等待 I/O 操作完成时让其他线程运行。
- 用户界面编程:在 GUI 编程中,多线程可以用来处理耗时的任务,避免界面冻结,提高用户体验。
- 并行计算:尽管受到 GIL 的限制,但在某些情况下,多线程仍然可以用来实现简单的并行计算。
← 06-切片操作