
# 一.基础介绍
# 1.什么是 Mybatis
- MyBatis 是一款优秀的持久层框架。
- 它支持定制化 SQL、存储过程以及高级映射。
- MyBatis 避免了几乎所有的 JDBC 代码和手动设置参数以及获取结果集。
- MyBatis 可以使用简单的 XML 或注解来配置和映射原生类型、接口和 Java 的 POJO(Plain Old Java Objects,普通老式 Java 对象)为数据库中的记录。
# 2.mybatis 优缺点?
mybatis 的优点
与 JDBC 相比,减少了 50%以上的代码量。
mybatis 是最简单的持久化框架,小巧并且简单易学。
mybatis 灵活,不会对应用程序或者数据库的限售设计强加任何影响,SQL 写在 XML 里,从程序代码中彻底分离,降低耦合度,便于统一管理和优化,可重用。
提供 XML 标签,支持编写动态 SQL 语句(XML 中使用 if,else)。
提供映射标签,支持对象与数据库的 ORM 字段关系映射(在 XML 中配置映射关系,也可以使用注解)
mybatis 的缺点
SQL 语句的编写工作量较大,对开发人员的 SQL 语句编写有一定的水平要求。
SQL 语句过于依赖数据库,不能随意更换数据库。
拼接复杂 SQL 语句时不灵活。
# 3.map 映射
别名:
<select id="getUserById" parameterType="int" resultType="User">
select name, id ,pwd as password from mybatis.user where id = #{id}
</select>
2
3
resultMap:
<resultMap id="UserMap" type="User">
<constructor><!-- 类再实例化时用来注入结果到构造方法 -->
<idArg/><!-- ID参数,结果为ID -->
<arg/><!-- 注入到构造方法的一个普通结果 -->
</constructor>
<id/><!-- 用于表示哪个列是主键 -->
<result/><!-- 注入到字段或JavaBean属性的普通结果 -->
<association property=""/><!-- 用于一对一关联 -->
<collection property=""/><!-- 用于一对多、多对多关联 -->
<discriminator javaType=""><!-- 使用结果值来决定使用哪个结果映射 -->
<case value=""/><!-- 基于某些值的结果映射 -->
</discriminator>
</resultMap>
2
3
4
5
6
7
8
9
10
11
12
13
# 4.核心组件
我们先来看 MyBatis 的“表面现象”——组件,并且讨论它们的作用,然后讨论它们的实现原理。MyBatis 的核心组件分为 4 个部分。
SqlSessionFactoryBuilder(构造器):它会根据配置或者代码来生成 SqlSessionFactory,采用的是分步构建的 Builder 模式。
SqlSessionFactory(工厂接口):依靠它来生成 SqlSession,使用的是工厂模式。
SqlSession(会话):一个既可以发送 SQL 执行返回结果,也可以获取 Mapper 的接口。在现有的技术中,一般我们会让其在业务逻辑代码中“消失”,而使用的是 MyBatis 提供的 SQL Mapper 接口编程技术,它能提高代码的可读性和可维护性。
SQL Mapper(映射器):MyBatis 新设计存在的组件,它由一个 Java 接口和 XML 文件(或注解)构成,需要给出对应的 SQL 和映射规则。它负责发送 SQL 去执行,并返回结果。
# 5.SqlSessionFactory
使用 MyBatis 首先是使用配置或者代码去生产 SqlSessionFactory,而 MyBatis 提供了构造器SqlSessionFactoryBuilder。
它提供了一个类 org.apache.ibatis.session.Configuration作为引导,采用的是 Builder 模式。具体的分步则是在 Configuration 类里面完成的,当然会有很多内容,包括你很感兴趣的插件。
在 MyBatis 中,既可以通过读取配置的 XML 文件的形式生成 SqlSessionFactory,也可以通过 Java 代码的形式去生成 SqlSessionFactory。
推荐采用 XML 的形式,因为代码的方式在需要修改的时候会比较麻烦。当配置了 XML 或者提供代码后,MyBatis 会读取配置文件,通过 Configuration 类对象构建整个 MyBatis 的上下文。
注意,SqlSessionFactory 是一个接口,在 MyBatis 中它存在两个实现类:SqlSessionManager 和 DefaultSqlSessionFactory。
一般而言,具体是由 DefaultSqlSessionFactory 去实现的,而 SqlSessionManager 使用在多线程的环境中,它的具体实现依靠 DefaultSqlSessionFactory
# 6.SqlSession
在 MyBatis 中,SqlSession 是其核心接口。在 MyBatis 中有两个实现类,DefaultSqlSession 和 SqlSessionManager。
DefaultSqlSession 是单线程使用的,而 SqlSessionManager 在多线程环境下使用。SqlSession 的作用类似于一个 JDBC 中的 Connection 对象,代表着一个连接资源的启用。具体而言,它的作用有 3 个:
- 获取 Mapper 接口。
- 发送 SQL 给数据库。
- 控制数据库事务。
# 7.Sql Mapper
映射器是 MyBatis 中最重要、最复杂的组件,它由一个接口和对应的 XML 文件(或注解)组成。
它可以配置以下内容:
- 描述映射规则。
- 提供 SQL 语句,并可以配置 SQL 参数类型、返回类型、缓存刷新等信息。
- 配置缓存。
- 提供动态 SQL。
# 8.主键策略
- AUTO 数据库 ID 自增
- INPUT 用户输入 ID
- ID_WORKER 全局唯一 ID,Long 类型的主键
- ID_WORKER_STR 字符串全局唯一 ID
- UUID 全局唯一 ID,UUID 类型的主键
- NONE 该类型为未设置主键类型
# 9.隔离级别
@Transactional(isolation = Isolation.DEFAULT)
DEFAULT:这是默认值,表示使用底层数据库的默认隔离级别。对大部分数据库而言,通常这值就是:READ_COMMITTED。READ_UNCOMMITTED:该隔离级别表示一个事务可以读取另一个事务修改但还没有提交的数据。该级别不能防止脏读和不可重复读,因此很少使用该隔离级别。READ_COMMITTED:该隔离级别表示一个事务只能读取另一个事务已经提交的数据。该级别可以防止脏读,这也是大多数情况下的推荐值。REPEATABLE_READ:该隔离级别表示一个事务在整个过程中可以多次重复执行某个查询,并且每次返回的记录都相同。即使在多次查询之间有新增的数据满足该查询,这些新增的记录也会被忽略。该级别可以防止脏读和不可重复读。SERIALIZABLE:所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。但是这将严重影响程序的性能。通常情况下也不会用到该级别。
# 10.传播行为
所谓事务的传播行为是指,如果在开始当前事务之前,一个事务上下文已经存在,此时有若干选项可以指定一个事务性方法的执行行为。
我们可以看org.springframework.transaction.annotation.Propagation枚举类中定义了 6 个表示传播行为的枚举值:
public enum Propagation {
REQUIRED(0),
SUPPORTS(1),
MANDATORY(2),
REQUIRES_NEW(3),
NOT_SUPPORTED(4),
NEVER(5),
NESTED(6);
}
2
3
4
5
6
7
8
9
REQUIRED:如果当前存在事务,则加入该事务;如果当前没有事务,则创建一个新的事务。SUPPORTS:如果当前存在事务,则加入该事务;如果当前没有事务,则以非事务的方式继续运行。MANDATORY:如果当前存在事务,则加入该事务;如果当前没有事务,则抛出异常。REQUIRES_NEW:创建一个新的事务,如果当前存在事务,则把当前事务挂起。NOT_SUPPORTED:以非事务方式运行,如果当前存在事务,则把当前事务挂起。NEVER:以非事务方式运行,如果当前存在事务,则抛出异常。NESTED:如果当前存在事务,则创建一个事务作为当前事务的嵌套事务来运行;如果当前没有事务,则该取值等价于 REQUIRED。
指定方法:通过使用 propagation 属性设置,例如:
@Transactional(propagation = Propagation.REQUIRED)
# 11.PreparedStatement
很多情况下,我们的一条 sql 语句可能被反复执行,或每次执行的时候只有个别的值不同,比如 query 的 where 子句值不同,update 的 set 子句值不同,insert 的 value 值不同。
如果每次都需要经过上面的语法语义解析、语句优化、制定执行计划等操作,效率显而易见,很低。
所谓预编译就是将这些语句中的值用占位符替代,可以视为将 sql 语句模板化或者参数化,一般称这类语句叫 PreparedStatement。
预编译语句的优势在于:一次编译、多次执行,省去了解析优化等繁琐过程,此外预编译语句能防止 sql 注入。
select * from student where id=? and name=?
该 SQL 语句会在得到用户的输入之前先用数据库进行预编译,这样的话不管用户输入什么 id 和用户名的判断始终都是并的逻辑关系,防止了 SQL 注入。
PreparedStatement的作用:
- 预编译 SQL 语句,效率高
- 安全,避免 SQL 注入
- 可以动态的填充数据,执行多个同结构的 SQL 语句
# 12.PreparedStatement 与 Statment
- 语法不同:PreparedStatement 可以使用预编译的 sql,而 Statment 只能使用静态的 sql
- 效率不同: PreparedStatement 可以使用 sql 缓存区,效率比 Statment 高
- 安全性不同: PreparedStatement 可以有效防止 sql 注入,而 Statment 不能防止 sql 注入。
# 13.预编译语句的作用
提高效率:当需要对数据库进行数据插入、更新或删除的时候,程序会发送整个 sql 语句给数据库处理和执行。数据库处理一个 sql 语句,需要完成解析 sql 语句、检查语法和语义以及生产代码,处理时间要比执行语句所需要的时间长。预编译语句在创建的时候就已经是将指定的 sql 语句发送给了 DBMS,完成了解析、检查、编译等工作。因此,当一个 sql 语句需要执行多次时,使用预编译语句可以减少处理时间,提高执行效率。
提高安全性:例如上面的 sql 注入攻击实例,登录验证,根本不用,直接进,加入又在后面追加上 drop table student;我靠,防不胜防,数据表直接没了,很多数据库是不会成功的,但也有很多数据库可以使用这些语句执行,而如果使用预编译语句,传入的任何内容就不会和原来的语句发生任何匹配的关系。只要全使用预编译语句,就用不着对传入的数据做任何过虑,而如果使用普通的 statement,有可能要对 drop,等做费尽心机的判断和过虑。
# 二.原理解析
# 1.mybatis 工作原理
工作原理分为六个部分:
- 读取核心配置文件并返回
InputStream流对象。 - 根据
InputStream流对象解析出Configuration对象,然后创建SqlSessionFactory工厂对象。 - 根据一系列属性从
SqlSessionFactory工厂中创建SqlSession。 - 从
SqlSession中调用Executor执行数据库操作,并且生成具体 SQL 指令。 - 对执行结果进行二次封装。
- 提交与事务。
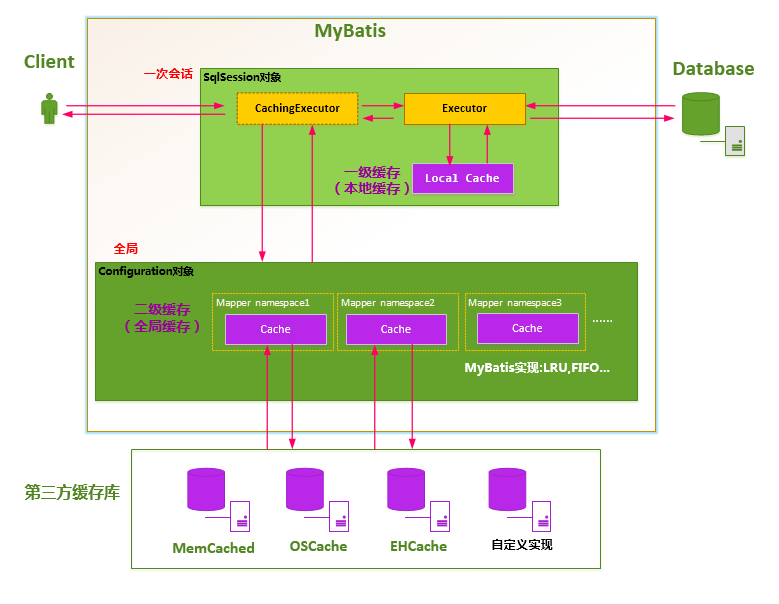
# 2.什么是一级缓存?
MyBatis 执行 SQL 语句之后,这条语句就是被缓存,以后再执行这条语句的时候,会直接从缓存中拿结果,而不是再次执行 SQL,这也就是大家常说的 MyBatis 一级缓存,一级缓存的作用域 scope 是 SqlSession。
- 同个 session 进行两次相同查询,MyBatis 只进行 1 次数据库查询
- 同个 session 进行两次不同的查询,MyBatis 进行两次数据库查询
- 不同 session,进行相同查询,MyBatis 进行了两次数据库查询
- 同个 session,查询之后更新数据,再次查询相同的语句,更新操作之后缓存会被清除
- 在同个 SqlSession 中,查询语句相同的 sql 会被缓存,但是一旦执行新增或更新或删除操作,缓存就会被清除
# 3.什么是二级缓存?
MyBatis 同时还提供了一种全局作用域 global scope 的缓存,这也叫做二级缓存,也称作全局缓存。
二级缓存的作用域是全局的,二级缓存在 SqlSession 关闭或提交之后才会生效。
二级缓存跟一级缓存不同,一级缓存不需要配置任何东西,且默认打开。 二级缓存就需要配置一些东西。
在 mapper 文件上加上这句配置即可:
<cache/>
# 4.一级缓存和二级缓存区别
级别不同:生命周期和作用范围不同:一级缓存是 SqlSession 级别,生命周期和作用范围就是一个 session 会话,二级缓存是 Application 级别,生命周期和作用范围就是整个 Application 应用。
实体位置不同:一级缓存是 Excutor 中的 LocalCache,一级缓存是 MyBatis 内部实现的一个特性,用户不能配置,默认情况下自动支持的缓存,用户没有定制它的权利(在 Mybatis 四层架构中的一个查询实例源码解释中就解释过了);二级缓存是 CachingExecutor,它是 Executor 对象的装饰者,默认不开启,需要程序员手动开启。
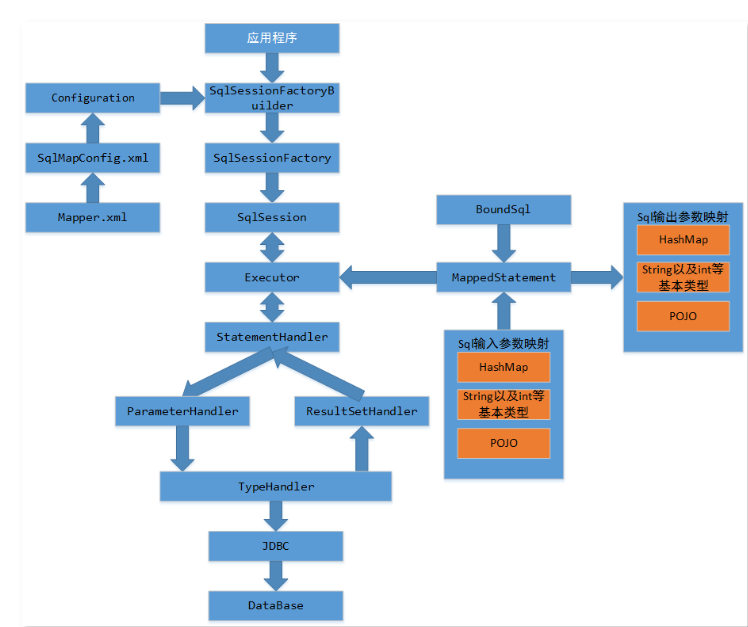
# 5.核心流程
SqlSession:,它是 MyBatis 核心 API,主要用来执行命令,获取映射,管理事务。接收开发人员提供 Statement Id 和参数。并返回操作结果。Executor:执行器,是 MyBatis 调度的核心,负责 SQL 语句的生成以及查询缓存的维护。StatementHandler: 封装了 JDBC Statement 操作,负责对 JDBC Statement 的操作,如设置参数、将 Statement 结果集转换成 List 集合。ParameterHandler: 负责对用户传递的参数转换成 JDBC Statement 所需要的参数。ResultSetHandler: 负责将 JDBC 返回的 ResultSet 结果集对象转换成 List 类型的集合。TypeHandler: 用于 Java 类型和 JDBC 类型之间的转换。MappedStatement: 动态 SQL 的封装SqlSource: 表示从 XML 文件或注释读取的映射语句的内容,它创建将从用户接收的输入参数传递给数据库的 SQL。Configuration: MyBatis 所有的配置信息都维持在 Configuration 对象之中。
# 6.执行 sql 的过程
InputStream inputStream = Resources.getResourceAsStream("mybatis.xml" );
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder(). build(inputStream);
SqlSession sqlSession = sqlSessionFactory.openSession();
// 以下使我们需要关注的重点
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
Integer id = 1;
User user = mapper.selectById(id);
2
3
4
5
6
7
8
Mybatis 的目的是:使得程序员能够以调用方法的方式执行某个指定的 sql,将执行 sql 的底层逻辑进行了封装。
这里重点思考以下 mapper 这个对象,当调用 SqlSession 的 getMapper 方法时,会对传入的接口生成一个 代理对象,而程序要真正用到的就是这个代理对象,在调用代理对象的方法时,Mybatis 会取出该方法所对应的 sql 语句,然后利用 JDBC 去执行 sql 语句,最终得到结果。
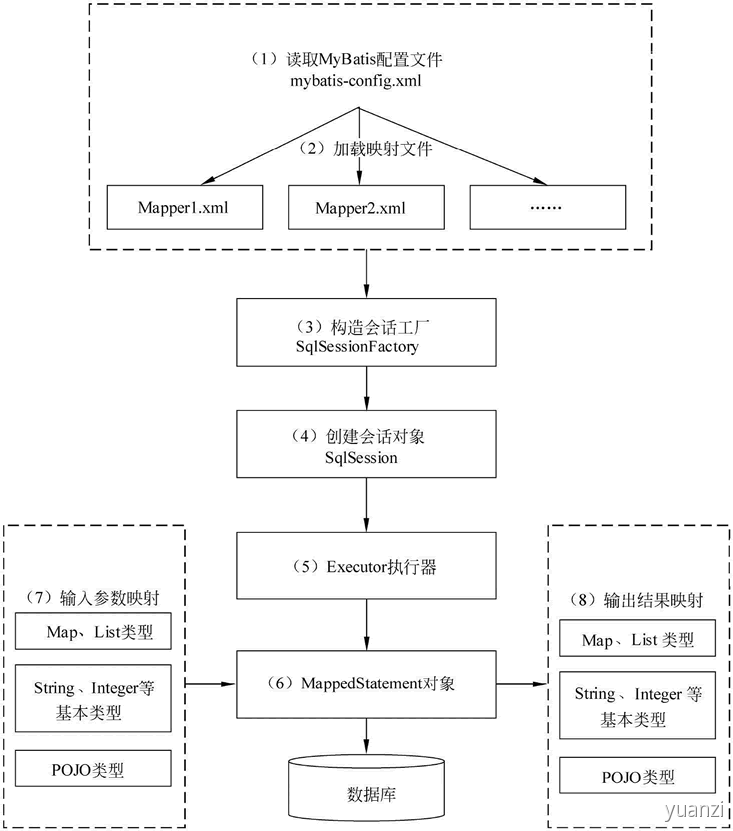
# 7.MyBatis 工作原理
1.读取 MyBatis 配置文件
mybatis-config.xml 为 MyBatis 的全局配置文件,配置了 MyBatis 的运行环境等信息,例如数据库连接信息。
2.加载映射文件
映射文件即 SQL 映射文件,该文件中配置了操作数据库的 SQL 语句,需要在 MyBatis 配置文件 mybatis-config.xml 中加载。mybatis-config.xml 文件可以加载多个映射文件,每个文件对应数据库中的一张表。
3.构造会话工厂
通过 MyBatis 的环境等配置信息构建会话工厂 SqlSessionFactory。
4.创建会话对象
由会话工厂创建 SqlSession 对象,该对象中包含了执行 SQL 语句的所有方法。
5.Executor 执行器
MyBatis 底层定义了一个 Executor 接口来操作数据库,它将根据 SqlSession 传递的参数动态地生成需要执行的 SQL 语句,同时负责查询缓存的维护。
6.MappedStatement 对象
在 Executor 接口的执行方法中有一个 MappedStatement 类型的参数,该参数是对映射信息的封装,用于存储要映射的 SQL 语句的 id、参数等信息。
7.输入参数映射
输入参数类型可以是 Map、List 等集合类型,也可以是基本数据类型和 POJO 类型。输入参数映射过程类似于 JDBC 对 preparedStatement 对象设置参数的过程。
8.输出结果映射
输出结果类型可以是 Map、 List 等集合类型,也可以是基本数据类型和 POJO 类型。输出结果映射过程类似于 JDBC 对结果集的解析过程。
# 三.常见问题
# 1.逻辑分页和物理分页
逻辑分页:全部数据查到内存后再处理物理分页:直接使用 limit 关键字,在获取的时候就分页
# 2.mapper 和 namespace
mapper 和 namespace 的作用和区别
- 在 mybatis 中,映射文件中的 namespace 是用于绑定 Dao 接口的,即面向接口编程。
- 当你的 namespace 绑定接口后,你可以不用写接口实现类,mybatis 会通过该绑定自动,帮你找到对应要执行的 SQL 语句
# 3.#和$的区别
1、#将传入的数据都当成一个字符串,会对自动传入的数据加一个双引号。 如:where id=#{id},如果传入的值是 1,那么解析成 sql 时的值为 where id="1", 如果传入的值是 id,则解析成的 sql 为 where id="id"。
将传入的数据直接显示生成在 sql 中。如:where id={id},如果传入的值是 1,那么解析成 sql 时的值为 where username=1;如果传入的值是;drop table user;则解析成的 sql 为:select * from student where id=1;drop table student;
#方式能够很大程序防止 sql 注入,$方式无法防止 sql 注入。
$方式一般用于传入数据库对象,比如表名。
一般能用#的就不用$,若不得不使用美元符号,则要做好前期校验工作,防止 sql 注入攻击。
在 mybatis 中,涉及到动态表名和列名时,只能使用${xxx}这样的参数形式。
#{}解析传递进来的参数数据。#{}是预编译处理,${}是字符串替换。- 使用
#{}可以有效的防止 SQL 注入,提高系统安全性。 ${}对传递进来的参数原样拼接在 SQL 中
# 4.使用到的设计模式?
工厂模式
SqlSessionFactory,ObjectFactory,MapperProxyFactory,DataSourceFactory单例模式
Configuration建造者模式
ResultMap#Builder代理模式
MapperProxy组合模式
SqlNode模版模式
BaseExecutor策略模式
TypeHandler
# 四.Mapper 文件
# 1.if-else
mybaits 中没有 else 要用 chose when otherwise 代替
<select id="selectSelective" resultMap="xxx" parameterType="xxx">
select
<include refid="Base_Column_List"/>
from xxx
where del_flag=0
<choose>
<when test="xxx !=null and xxx != ''">
and xxx like concat(concat('%', #{xxx}), '%')
</when>
<otherwise>
and xxx like '**%'
</otherwise>
</choose>
</select>
2
3
4
5
6
7
8
9
10
11
12
13
14
# 2.in-for 循环
在 mapper.xml 文件中使用 for 循环当做 in 的条件
<if test="query.storeNameList != null and query.storeNameList.size > 0">
and organ_key in
<foreach item="item" index="index" collection="query.storeNameList"
open="(" separator="," close=")">
#{item}
</foreach>
</if>
2
3
4
5
6
7
# 3.choose-when
注意双引号的位置
<select>
SELECT COUNT(1) FROM TABLE1 WHERE ID_NO = #{idNo}
<choose>
<when test="flag == '0'">
AND CONT_ADDR LILE CONCAT(#{contAddr},'%')
</when>
<when test="flag == '1'">
AND CONT_ADDR NOT LILE CONCAT(#{contAddr},'%')
</when>
<otherwise></otherwise>
</choose>
</select>
<select>
SELECT COUNT(1) FROM TABLE1 WHERE ID_NO = #{idNo}
<choose>
<when test='flag == "0"'>
AND CONT_ADDR LILE CONCAT(#{contAddr},'%')
</when>
<when test='flag == "1"'>
AND CONT_ADDR NOT LILE CONCAT(#{contAddr},'%')
</when>
<otherwise></otherwise>
</choose>
</select>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
<choose>
<when test="status != null">
and ufr.status = #{status}
</when>
<otherwise>
and ufr.status is null
</otherwise>
</choose>
2
3
4
5
6
7
8
# 4.or 多条件
<select id="getUserByOr" resultType="com.kwan.springbootkwan.entity.User">
SELECT *
FROM user
WHERE 1 = 1
<if test="invFlag != null and invFlag.size>0">
<foreach collection="invFlag" item="flag" open="AND (" close=")" separator="or">
<if test="flag==1">
id <= 1
</if>
<if test="flag==2">
id >= 2 and id < 4
</if>
<if test="flag==3">
id >= 5 and id < 6
</if>
<if test="flag==4">
id >= 8 and id < 9
</if>
</foreach>
</if>
</select>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
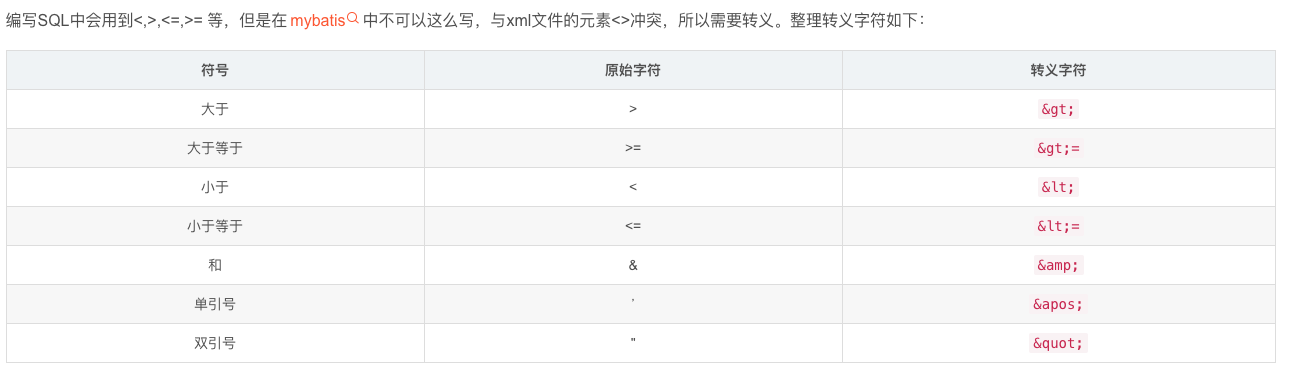
# 5.转义符号
使用 CDATA
< 和 & 这些符号在 xml 文件中有特殊含义,所以要用 CDATA 来定义,如
<![CDATA[ ...]]>
#<=可以
<![CDATA[ <= ]]>
2
3
4
# 6.内存分页
List<AssetsDirectoriesVo> list = service.queryPageList(bo); //获取的数据集合
PageInfo<AssetsDirectoriesVo> pageInfo = new PageInfo<>(); //创建一个分页对象
pageInfo.setTotal(list.size());
pageInfo.setPages(list.size()/pageBaseReq.getPageSize()+(list.size()%pageBaseReq.getPageSize()==0?0:1)); //pageBaseReq为分页参数对象
pageInfo.setPageNum(pageBaseReq.getPageNum());
pageInfo.setPageSize(pageBaseReq.getPageSize());
List<AssetsDirectoriesVo> res = list.stream()
.skip((pageBaseReq.getPageNum() - 1) *pageBaseReq.getPageSize()).limit(pageBaseReq.getPageSize()).collect(Collectors.toList()); //开始分页
pageInfo.setList(res);
2
3
4
5
6
7
8
9
# 7.xml 等于条件
<when test="query.queryField == 'sal_qty_store_rate'">
,if(sum(size_store_day) is NULL OR SUM(size_store_day) =
0,0,round(sum(sal_qty)/sum(size_store_day),4)) as salQtyStoreRate
</when>
2
3
4
# 8.特殊字符
SELECT * FROM order order by createDate #{sortType} //报错
SELECT * FROM order order by createDate ${sortType} //正常
2
这种情况下,就需要把 sortType 搞成白名单了。不就一个 ASC 和 DESC 了
/**
* 是否含有特殊字符
*
* @param str
* @return
*/
static boolean isSpecialChar(String str) {
String regEx = "[ _`~!@#$%^&*()+=|{}':;',\\[\\].<>/?~!@#¥%……&*()——+|{}【】‘;:”“’。,、?]|\n|\r|\t";
Pattern p = Pattern.compile(regEx);
Matcher m = p.matcher(str);
return m.find();
}
2
3
4
5
6
7
8
9
10
11
12
直接用动态参数生成,不会排序:
<if test="orderColumn!=null and orderColumn !=''">
ORDER BY #{orderColumn} #{orderDir}
</if>
2
3
需要将 #改为 $:
<if test="orderColumn!=null and orderColumn !=''">
ORDER BY ${orderColumn} ${orderDir}
</if>
2
3
# 9.resultType
返回类型处理
<select id="selectAllSkus" resultType="java.lang.String">
# 10.fetchSize
大数据查询较慢,可以使用 fetchSize,加快查询
<select id="selectAssignableDeviceInfo" fetchSize="1000" parameterType="java.lang.String" resultMap="result">
select
i.UUID,
i.FACT_SN,
i.FACT_ID,
i.BRAND_ID,
i.GOODS_ORDER_ID,
o.ORDER_TYPE as DEVICE_TYPE
from TABLE_INFO i
left join ORDER_INFO o on i.GOODS_ORDER_ID = o.GOODS_ORDER_ID
where i.DEVICE_STATUS = '00'
and nvl(i.HAPPY_SEND_ACTIVE_STATUS,'00') = '00'
and i.ASSIGN_FLAG = '00'
and i.USER_ID = #{userId,jdbcType=VARCHAR}
and i.GOODS_ORDER_ID = #{goodsOrderId,jdbcType=VARCHAR}
</select>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 11.逻辑判断
<choose>
<when test="query.dateDimension != null and query.dateDimension != '' and '月'.toString()==query.dateDimension">
financial_year as financial_year
,financial_year_month as financial_year_month
</when>
<when test="query.dateDimension != null and query.dateDimension != '' and '周'.toString()==query.dateDimension">
financial_year as financial_year
,financial_year_week as financial_year_week
</when>
<otherwise>
period_sdate as period_sdate
</otherwise>
</choose>
<choose>
<when test="query.organKey != null and query.organKey != '' and query.organKey != '-1'">
,organ_key as organ_key
,managing_city_no as managing_city_no
,region_no as region_no
,store_name as store_name
,store_level_name as store_level_name
,store_status as store_status
</when>
<when test="query.managingCityNo != null and query.managingCityNo != '' and query.managingCityNo != '-1'">
,managing_city_no as managing_city_no
,region_no as region_no
</when>
<when test="query.regionNo != null and query.regionNo != '' and query.regionNo != '-1'">
,region_no as region_no
</when>
<otherwise>
</otherwise>
</choose>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
# 12.日期转换
SELECT DATE_FORMAT(create_time, '%Y-%m-%d') AS redPackageDate
, SUM(my_amount) AS myAmount
, COUNT(1) AS redPackageCount
FROM csdn_red_package
WHERE 1 = 1
AND DATE_FORMAT(create_time
, '%Y-%m-%d') <![CDATA[>= #{min}]]>
AND DATE_FORMAT(create_time
, '%Y-%m-%d') <![CDATA[<= #{max}
]]>
GROUP BY redPackageDate
ORDER BY redPackageDate
2
3
4
5
6
7
8
9
10
11
12
# 13.空值关联判断
已知 table_1 有 3 个字段 order_no,community_id,post_id
已知 table_2 也有 3 个字段 order_no,community_id,post_id
关联条件
现在需要将 table_1 和 table_2 进行关联,关联条件是 order_no,community_id,post_id 这 3 个字段,但是 order_no 不为 null,不过 community_id,post_id 是可能为 null,也可能不为 null
初步解法
如以下 SQL 所示,发现结果为空,没有查询到数据,实际是有数据,问题在于 community_id 和 post_id 对于空值的处理。
<select id="totalPageInfo" resultType="com.kwan.springbootkwan.entity.dto.CsdnTotalIncomeDTO">
SELECT t1.receiver_nick_name AS nickName
, SUM(t1.received_money) AS amount
FROM table_1 t1 left join table_2 t2
on t1.order_no = t2.order_no
AND t1.community_id=t2.community_id
AND t1.post_id=t2.post_id
WHERE 1 = 1
<if test="query.startDate != null">
AND t1.receive_time <![CDATA[>= #{query.startDate}]]>
AND t2.create_time <![CDATA[>= #{query.startDate}]]>
</if>
<if test="query.endDate != null">
AND t1.receive_time <![CDATA[<= #{query.endDate}]]>
AND t2.create_time <![CDATA[<= #{query.endDate}]]>
</if>
GROUP BY nickName
ORDER BY amount DESC
</select>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
正确SQL 如下
<select id="totalPageInfo" resultType="com.kwan.springbootkwan.entity.dto.CsdnTotalIncomeDTO">
SELECT t1.receiver_nick_name AS nickName
, SUM(t1.received_money) AS amount
FROM table_1 t1 left join table_2 t2
on t1.order_no = t2.order_no
<![CDATA[
AND t1.community_id <=> t2.community_id
AND t1.post_id<=> t2.post_id
]]>
WHERE 1 = 1
<if test="query.startDate != null">
AND t1.receive_time <![CDATA[>= #{query.startDate}]]>
AND t2.create_time <![CDATA[>= #{query.startDate}]]>
</if>
<if test="query.endDate != null">
AND t1.receive_time <![CDATA[<= #{query.endDate}]]>
AND t2.create_time <![CDATA[<= #{query.endDate}]]>
</if>
GROUP BY nickName
ORDER BY amount DESC
</select>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
在这里,使用了 <=> 操作符,它在 MySQL 中用于处理 NULL 值的比较。如果 community_id 或 post_id 的其中一个是 NULL,那么 <=> 操作符会返回 true。
请根据你使用的数据库类型来调整语法。如果是其他数据库,可能会使用 COALESCE 或 IS NULL 等不同的语法。